CurveRL: Principled Distribution-Aware Context Reweighting for LLM Reasoning
Pith reviewed 2026-06-30 13:51 UTC · model grok-4.3
The pith
Reweighting prompts by their rank and density in the pass-rate distribution improves LLM reasoning over standard RLVR methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
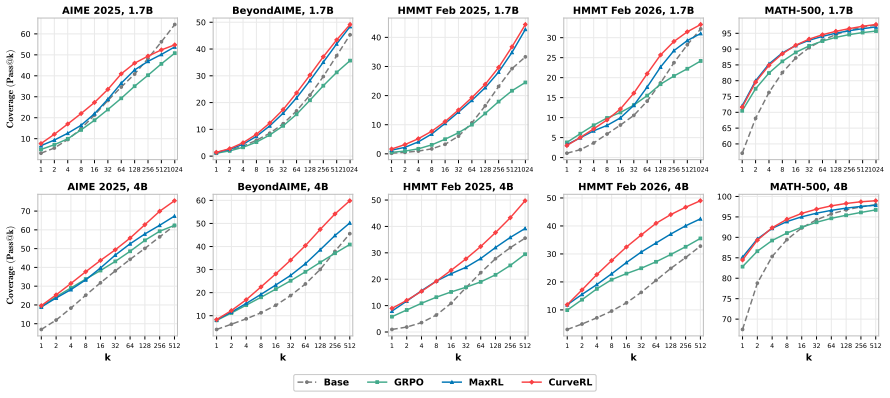
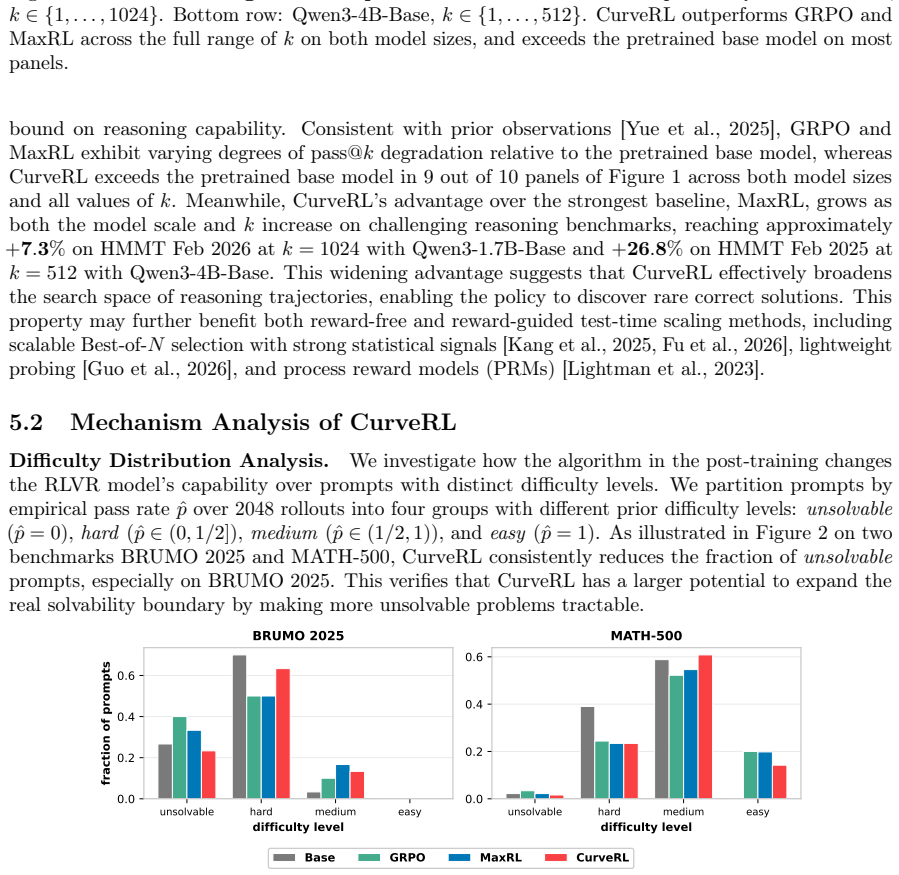
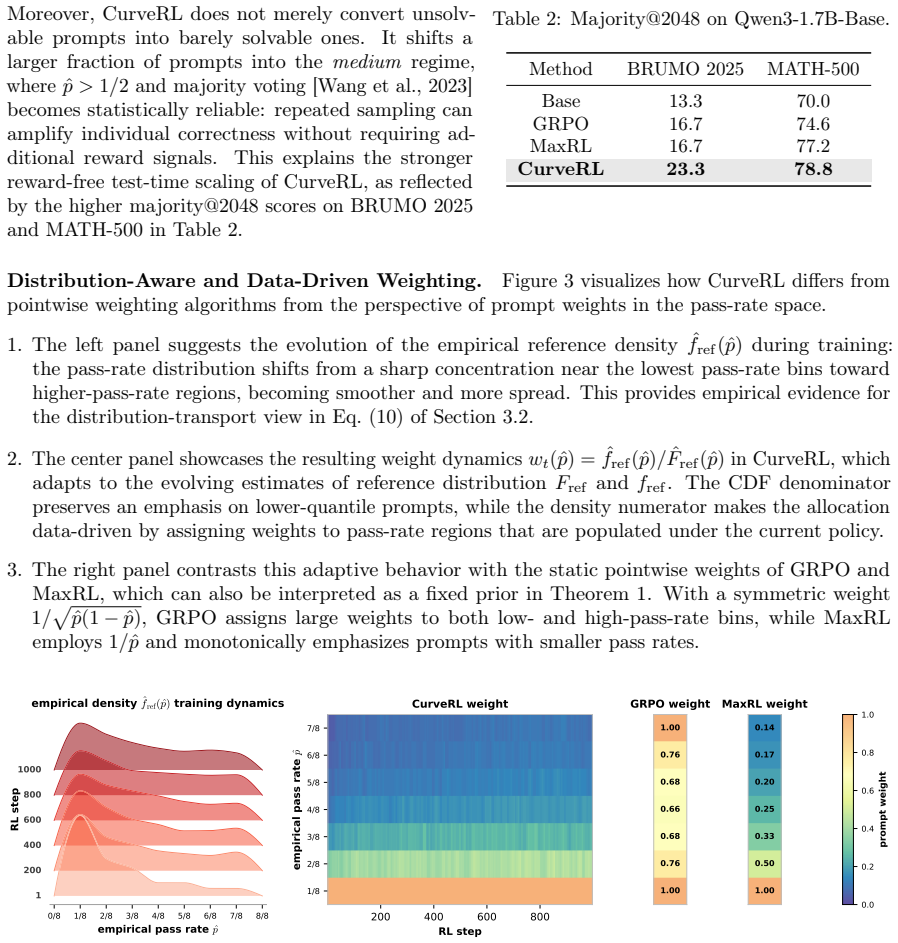
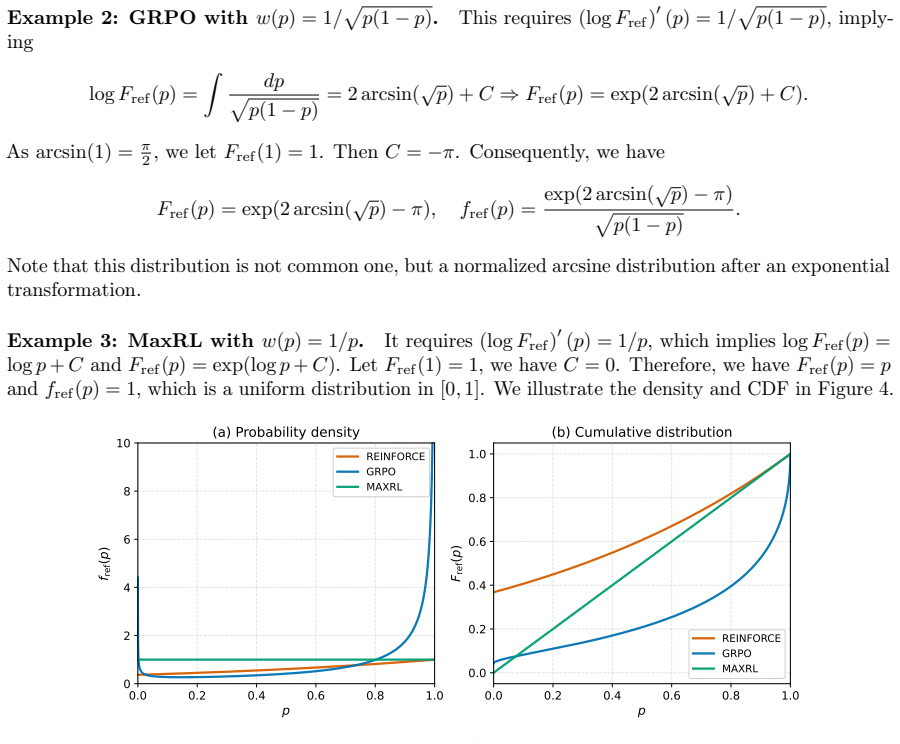
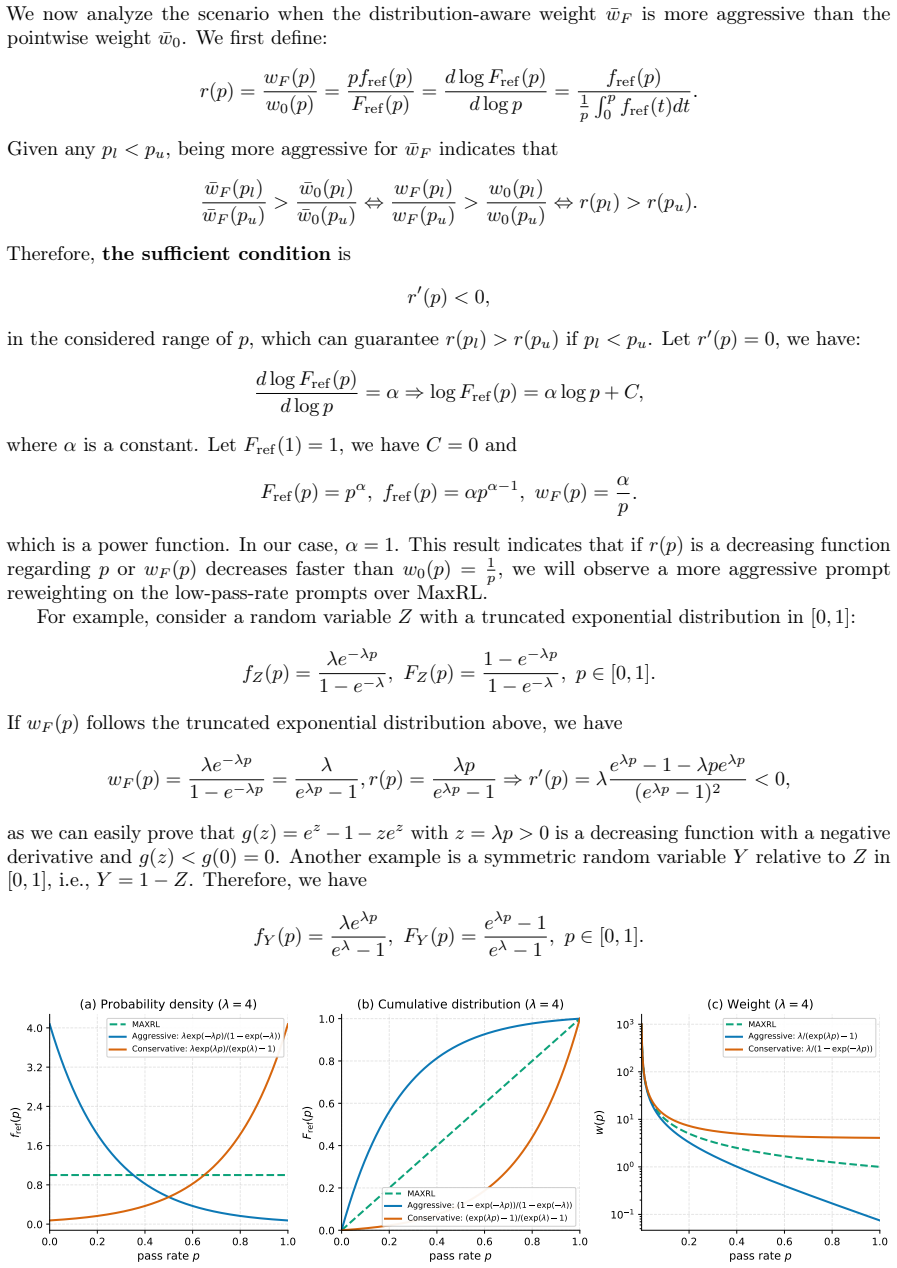
Formulating prompt reweighting as the functional derivative of a utility functional over the pass-rate function space yields a unified optimality framework. CurveRL realizes this framework with a quantile coordinate transform whose weights depend on rank and density in the empirical pass-rate distribution, producing higher reasoning performance than GRPO and other RLVR baselines on multiple benchmarks.
What carries the argument
quantile coordinate transform that converts pass rates into weights via their cumulative rank and local density in the observed distribution
If this is right
- REINFORCE and GRPO emerge as particular choices of utility functional within the same framework.
- Weights that depend only on absolute pass rates can be suboptimal when the distribution of pass rates is skewed or changing.
- Context-distribution control supplies an explicit axis for analyzing and improving RLVR algorithms beyond simple thresholding.
- Alternative utility functionals on the same pass-rate space can generate new reweighting rules with potentially different performance profiles.
Where Pith is reading between the lines
- The quantile approach might transfer to other verified-reward settings where the distribution of success signals varies during training.
- The framework offers a way to diagnose when certain prompts dominate learning and to adjust the distribution explicitly.
- Extending the same functional-derivative view to multi-step reasoning traces or to non-verified rewards could reveal further structure.
Load-bearing premise
The chosen utility functional over pass-rate functions, together with the quantile transform, selects weights that genuinely raise downstream reasoning accuracy rather than merely reordering the same training examples.
What would settle it
Training the identical model and data with uniform or absolute-value reweighting and observing equal or higher benchmark scores would indicate that the distributional weighting is not required for the reported gains.
Figures

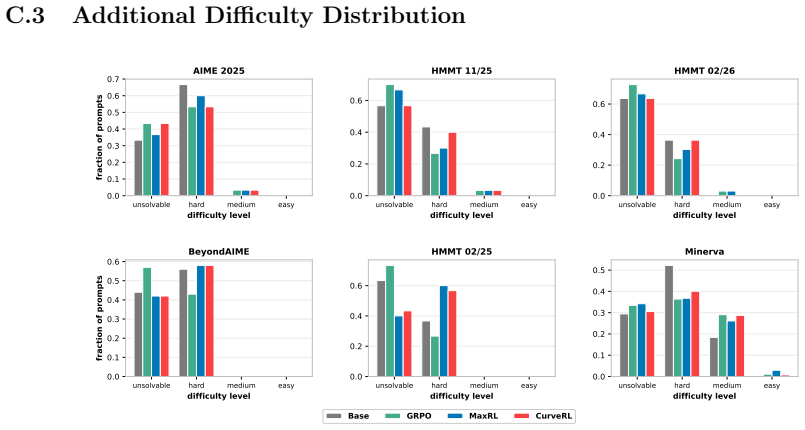
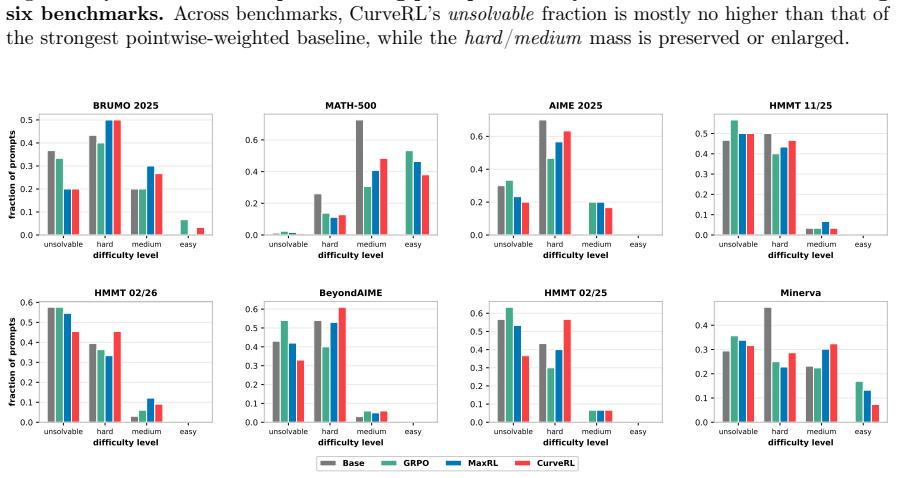
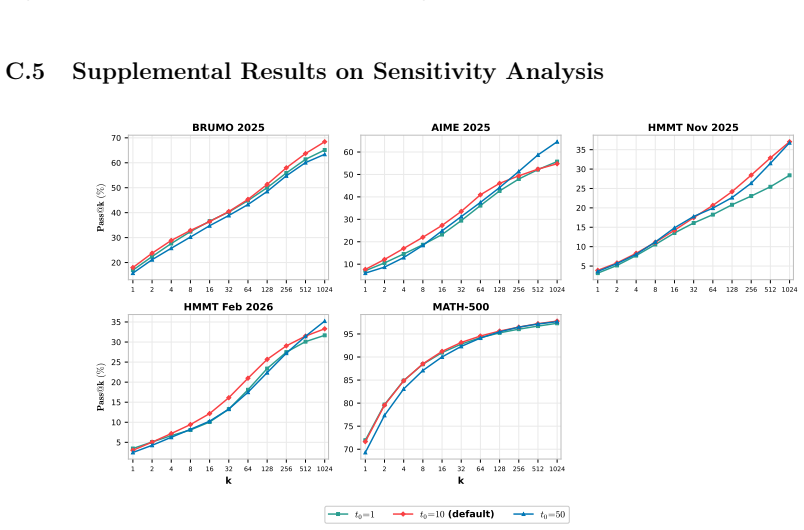
read the original abstract
Context or prompt-level reweighting has emerged as a central algorithmic lever in Reinforcement Learning with Verified Rewards (RLVR) for improving the reasoning capability of large language models, yet the principle determining what constitutes an optimal weighting remains poorly understood. We address this gap by formulating prompt reweighting as a functional derivative of a utility functional defined in the pass-rate function space, yielding a unified optimality framework that accommodates existing schemes, including REINFORCE and GRPO. Building on this optimality framework, we propose a distribution-aware prompt reweighting approach, called CurveRL, based on a quantile coordinate transform, in which the weight assigned to each prompt depends not on the absolute value of pass rates but on its rank and density to reflect the distributional structure of the pass rates in the learning dynamics. Extensive experiments across multiple benchmarks demonstrate that our proposed CurveRL consistently outperforms GRPO and other RLVR baselines. Our study identifies context-distribution control as a principled axis for analyzing and designing prompt-reweighted RLVR algorithms. The code is released in https://github.com/zhyzmath/CurveRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates prompt reweighting in RLVR as the functional derivative of a utility functional over the pass-rate function space, yielding a unified optimality framework that includes REINFORCE and GRPO. It introduces CurveRL, which applies a quantile coordinate transform so that weights depend on rank and density rather than absolute pass rates, and reports that this approach consistently outperforms GRPO and other RLVR baselines across multiple benchmarks. Code is released.
Significance. If the derivation of the optimality framework is made explicit and the empirical gains prove robust to ablations and statistical controls, the work would supply a principled axis (context-distribution control) for analyzing and designing prompt-reweighted RLVR algorithms. The public code release supports reproducibility and is a clear strength.
major comments (3)
- [Abstract] Abstract: the claim that 'a functional derivative yields the optimality framework' is presented without any derivation steps, explicit statement of the utility functional, or the resulting optimality condition. This information is load-bearing for the central unified-framework claim and must be supplied (with equation numbers) before the framework can be evaluated.
- [Experiments] Experiments (and abstract): no error bars, ablation studies, or statistical significance tests are described for the reported outperformance over GRPO. Without these, it is impossible to determine whether the quantile transform produces gains beyond what simpler monotonic reweightings would achieve.
- [Optimality framework] Optimality framework section: the manuscript does not demonstrate that the chosen utility functional together with the quantile transform selects weights whose effect on downstream reasoning is non-equivalent to simpler reweighting schemes that ignore the functional-derivative construction. This directly addresses the weakest assumption and must be addressed with a concrete comparison or proof.
minor comments (2)
- [Abstract] The abstract mentions 'extensive experiments across multiple benchmarks' but does not name the benchmarks or report the number of runs; this should be stated explicitly.
- Notation for the pass-rate function space and the quantile coordinate transform should be introduced with a clear definition before being used in the optimality derivation.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the presentation of the optimality framework and the empirical results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'a functional derivative yields the optimality framework' is presented without any derivation steps, explicit statement of the utility functional, or the resulting optimality condition. This information is load-bearing for the central unified-framework claim and must be supplied (with equation numbers) before the framework can be evaluated.
Authors: We agree that the abstract would benefit from greater explicitness. In the revised manuscript, we will update the abstract to briefly state the utility functional and the optimality condition, cross-referencing the equation numbers from Section 3 where the full derivation is provided. This will make the central claim more self-contained while preserving the abstract's length constraints. revision: yes
-
Referee: [Experiments] Experiments (and abstract): no error bars, ablation studies, or statistical significance tests are described for the reported outperformance over GRPO. Without these, it is impossible to determine whether the quantile transform produces gains beyond what simpler monotonic reweightings would achieve.
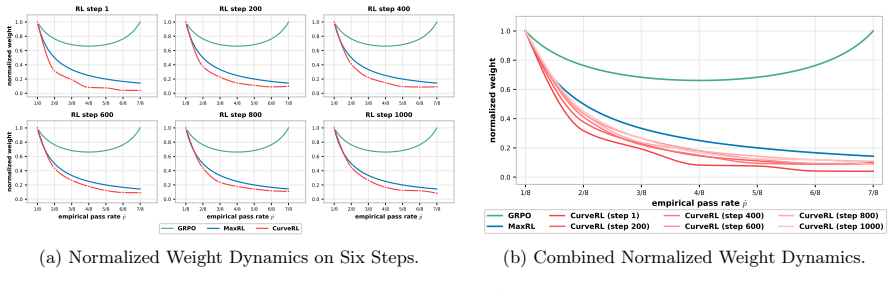
Authors: We acknowledge the absence of these statistical controls in the current version. We will incorporate error bars (standard deviations across multiple random seeds), ablation studies comparing the quantile transform to simpler reweighting functions, and statistical significance tests (e.g., paired t-tests) in the revised experiments section. These additions will help isolate the contribution of the distribution-aware component. revision: yes
-
Referee: [Optimality framework] Optimality framework section: the manuscript does not demonstrate that the chosen utility functional together with the quantile transform selects weights whose effect on downstream reasoning is non-equivalent to simpler reweighting schemes that ignore the functional-derivative construction. This directly addresses the weakest assumption and must be addressed with a concrete comparison or proof.
Authors: To demonstrate non-equivalence, we will add a dedicated comparison in the revised manuscript. This will include both a theoretical argument showing how the quantile coordinate transform (incorporating density) differs from absolute pass-rate or rank-only reweighting in the context of the utility functional, and empirical results contrasting the learning trajectories and final performance when using weights derived from the full construction versus simplified alternatives. We believe this will substantiate that the functional-derivative approach yields distinct and beneficial weighting behavior. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation formulates prompt reweighting via functional derivative of a utility functional over the pass-rate function space and introduces a quantile coordinate transform based on rank and density. These steps are presented as mathematical constructions independent of the target benchmark scores. No equations or self-citations are shown that reduce the central optimality claim or the proposed CurveRL weights to a fit or renaming of the input data by construction. The framework is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A utility functional exists on the space of pass-rate functions such that its functional derivative yields the optimal prompt weights.
Reference graph
Works this paper leans on
-
[1]
Polaris: A post-training recipe for scaling reinforcement learning on advanced reasoning models.https://hkunlp.github.io/blog/2025/Polaris,
ChenxinAn, ZhihuiXie, XiaonanLi, LeiLi, JunZhang, ShansanGong, MingZhong, JingjingXu, Xipeng Qiu, Mingxuan Wang, and Lingpeng Kong. Polaris: A post-training recipe for scaling reinforcement learning on advanced reasoning models.https://hkunlp.github.io/blog/2025/Polaris,
2025
-
[2]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
Mislav Balunović, Jasper Dekoninck, Ivo Petrov, Nikola Jovanović, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions.arXiv preprint arXiv:2505.23281,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Anas Barakat, Souradip Chakraborty, Khushbu Pahwa, and Amrit Singh Bedi. Why pass@ k optimiza- tion can degrade pass@ 1: Prompt interference in llm post-training.arXiv preprint arXiv:2602.21189,
-
[4]
Eric Brochu, Vlad M Cora, and Nando De Freitas. A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning.arXiv preprint arXiv:1012.2599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Self-evolving curriculum for llm reasoning.arXiv preprint arXiv:2505.14970, 2025a
Xiaoyin Chen, Jiarui Lu, Minsu Kim, Dinghuai Zhang, Jian Tang, Alexandre Piché, Nicolas Gontier, Yoshua Bengio, and Ehsan Kamalloo. Self-evolving curriculum for llm reasoning.arXiv preprint arXiv:2505.14970, 2025a. Xinzhu Chen, Xuesheng Li, Zhongxiang Sun, and Weijie Yu. Beyond high-entropy exploration: Correctness-aware low-entropy segment-based advantag...
-
[7]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
What is the objective of reasoning with reinforcement learning? arXiv preprint arXiv:2510.13651,
Damek Davis and Benjamin Recht. What is the objective of reasoning with reinforcement learning? arXiv preprint arXiv:2510.13651,
-
[9]
Simple regret minimization for contextual bandits.arXiv preprint arXiv:1810.07371,
Aniket Anand Deshmukh, Srinagesh Sharma, James W Cutler, Mark Moldwin, and Clayton Scott. Simple regret minimization for contextual bandits.arXiv preprint arXiv:1810.07371,
-
[10]
A Tutorial on Bayesian Optimization
Peter I Frazier. A tutorial on bayesian optimization.arXiv preprint arXiv:1807.02811,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Cheng Ge, Caitlyn Heqi Yin, Hao Liang, and Jiawei Zhang
URLhttps:// openreview.net/forum?id=8LqHs0KIM7. Cheng Ge, Caitlyn Heqi Yin, Hao Liang, and Jiawei Zhang. Why grpo needs normalization: A local-curvature perspective on adaptive gradients.arXiv preprint arXiv:2601.23135,
-
[12]
Roger Grosse, Juhan Bae, Cem Anil, Nelson Elhage, Alex Tamkin, Amirhossein Tajdini, Benoit Steiner, Dustin Li, Esin Durmus, Ethan Perez, et al. Studying large language model generalization with influence functions.arXiv preprint arXiv:2308.03296,
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
On the Emergence of Implicit Curriculum in RLVR Learning Dynamics
Yu Huang, Zixin Wen, Yuejie Chi, Yuting Wei, Aarti Singh, Yingbin Liang, and Yuxin Chen. On the learning dynamics of rlvr at the edge of competence.arXiv preprint arXiv:2602.14872,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Continuous control with deep reinforcement learning
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Goal-conditioned reinforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299,
Minghuan Liu, Menghui Zhu, and Weinan Zhang. Goal-conditioned reinforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299,
-
[19]
Dual active learning for reinforcement learning from human feedback.arXiv preprint arXiv:2410.02504,
Pangpang Liu, Chengchun Shi, and Will Wei Sun. Dual active learning for reinforcement learning from human feedback.arXiv preprint arXiv:2410.02504,
-
[20]
Emphatic Temporal-Difference Learning
A Rupam Mahmood, Huizhen Yu, Martha White, and Richard S Sutton. Emphatic temporal-difference learning.arXiv preprint arXiv:1507.01569,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Youssef Mroueh. Reinforcement learning with verifiable rewards: Grpo’s effective loss, dynamics, and success amplification.arXiv preprint arXiv:2503.06639,
-
[22]
18 Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, et al. Olmo 3.arXiv preprint arXiv:2512.13961,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Shubham Parashar, Shurui Gui, Xiner Li, Hongyi Ling, Sushil Vemuri, Blake Olson, Eric Li, Yu Zhang, James Caverlee, Dileep Kalathil, et al. Curriculum reinforcement learning from easy to hard tasks improves llm reasoning.arXiv preprint arXiv:2506.06632,
-
[24]
Nived Rajaraman, Audrey Huang, Miro Dudik, Robert Schapire, Dylan J Foster, and Akshay Krishna- murthy. Learning to reason with curriculum i: Provable benefits of autocurriculum.arXiv preprint arXiv:2603.18325,
-
[25]
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay.arXiv preprint arXiv:1511.05952,
work page internal anchor Pith review Pith/arXiv arXiv
- [26]
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Maximum likelihood reinforcement learning.arXiv preprint arXiv:2602.02710,
Fahim Tajwar, Guanning Zeng, Yueer Zhou, Yuda Song, Daman Arora, Yiding Jiang, Jeff Schneider, Ruslan Salakhutdinov, Haiwen Feng, and Andrea Zanette. Maximum likelihood reinforcement learning.arXiv preprint arXiv:2602.02710,
-
[29]
Multiplex thinking: Reasoning via token-wise branch-and-merge.arXiv preprint arXiv:2601.08808,
19 Yao Tang, Li Dong, Yaru Hao, Qingxiu Dong, Furu Wei, and Jiatao Gu. Multiplex thinking: Reasoning via token-wise branch-and-merge.arXiv preprint arXiv:2601.08808,
-
[30]
The invisible leash: Why rlvr may or may not escape its origin.arXiv preprint arXiv:2507.14843,
Fang Wu, Weihao Xuan, Ximing Lu, Mingjie Liu, Yi Dong, Zaid Harchaoui, and Yejin Choi. The invisible leash: Why rlvr may or may not escape its origin.arXiv preprint arXiv:2507.14843,
-
[31]
URLhttps://openreview.net/forum?id=WDP5b3mtFV. Wei Xiong, Chenlu Ye, Baohao Liao, Hanze Dong, Xinxing Xu, Christof Monz, Jiang Bian, Nan Jiang, and Tong Zhang. Reinforce-ada: An adaptive sampling framework under non-linear rl objectives. arXiv preprint arXiv:2510.04996,
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Your group-relative advantage is biased.arXiv preprint arXiv:2601.08521,
Fengkai Yang, Zherui Chen, Xiaohan Wang, Xiaodong Lu, Jiajun Chai, Guojun Yin, Wei Lin, Shuai Ma, Fuzhen Zhuang, Deqing Wang, et al. Your group-relative advantage is biased.arXiv preprint arXiv:2601.08521,
-
[34]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Charlie Zhang, Graham Neubig, and Xiang Yue. On the interplay of pre-training, mid-training, and rl on reasoning language models.arXiv preprint arXiv:2512.07783, 2025a. Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan. Theoretically principled trade-off between robustness and accuracy. InInternational conference o...
-
[36]
20 Kaichen Zhang, Yuzhong Hong, Junwei Bao, Hongfei Jiang, Yang Song, Dingqian Hong, and Hui Xiong. Gvpo: Group variance policy optimization for large language model post-training.Advances in neural information processing systems, 2025b. Xiaoyun Zhang, Xiaojian Yuan, Di Huang, Wang You, Chen Hu, Jingqing Ruan, An Jian, Kejiang Chen, and Xing Hu. Revisitin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Hongyi Zhou, Kai Ye, Erhan Xu, Jin Zhu, Shijin Gong, and Chengchun Shi. Demystifying group relative policy optimization: Its policy gradient is a u-statistic.arXiv preprint arXiv:2603.01162,
-
[38]
23 A.2 Proof of Proposition 1
21 Appendix Table of Contents A Theoretical Results 23 A.1 Functional derivative under Pointwise Utility Reduces to Partial Derivative . . . . 23 A.2 Proof of Proposition 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 A.3 Proof of Proposition 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 A.4 Proof of Th...
2000
-
[39]
Firstly, given each promptx, we have the pointwise limit: ηwη θ(x) = eη −1 1 + (eη −1)p θ(x) = 1 1 eη−1 +p θ(x) → 1 pθ(x) .(η→+∞) This implies wη θ(x) ∼ 1 ηpθ(x) as η→ +∞. However, the pointwise convergence does not directly ensure the limit of the integral is the integral of the limit, i.e.,limE = Elim, which additionally requires some mild conditions (i...
2025
-
[40]
Let’s think step by step and put the final answer within \boxed{}
Therefore, Fref is a valid CDF. Given the fact thatd dp − R 1 p w(t)dt = w(p), by the chain rule, we can derive fref(p) = d dp exp − Z 1 p w(t)dt =F ref(p)w(p), which is the exact goal we want to prove in the beginning. Uniqueness.Assume ˜Falso satisfies ˜f(p) ˜F(p) =w(p). This implies that d dp log ˜F(p) =w(p). 26 By taking the integral between[p,1]on bo...
2026
-
[41]
We do not employ adaptive sampling and do not apply any logit correction for the mismatch between inference and training runtimes
Evaluation Decoding.Following [Tajwar et al., 2026], evaluation generations are sampled at temperature0 .6with top- p 0.95, and both top-k and min-p truncation are disabled. We do not employ adaptive sampling and do not apply any logit correction for the mismatch between inference and training runtimes. Reported metrics are computed on the final checkpoin...
2026
-
[42]
Method BRUMO 2025 HMMT 11/25 Minerva A vg
C.1 Pass@1 and Pass@64on Three Additional Benchmarks Table 5:Supplemental results on three additional math reasoning benchmarks.pass@1 and pass@64 (%), best per column in bold. Method BRUMO 2025 HMMT 11/25 Minerva A vg. pass@1 pass@64 pass@1 pass@64 pass@1 pass@64 pass@1 pass@64 Qwen3-1.7B-Base Base 8.0 40.1 2.4 18.7 20.8 56.9 10.4 38.6 GRPO 14.2 40.2 3.0...
2025
-
[43]
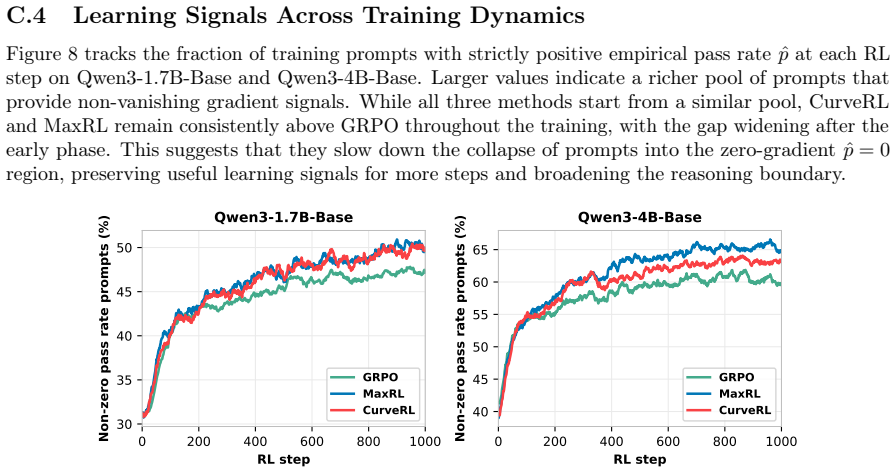
Larger values indicate a richer pool of prompts that provide non-vanishing gradient signals
31 C.4 Learning Signals Across Training Dynamics Figure 8 tracks the fraction of training prompts with strictly positive empirical pass rateˆpat each RL step on Qwen3-1.7B-Base and Qwen3-4B-Base. Larger values indicate a richer pool of prompts that provide non-vanishing gradient signals. While all three methods start from a similar pool, CurveRL and MaxRL...
2025
-
[44]
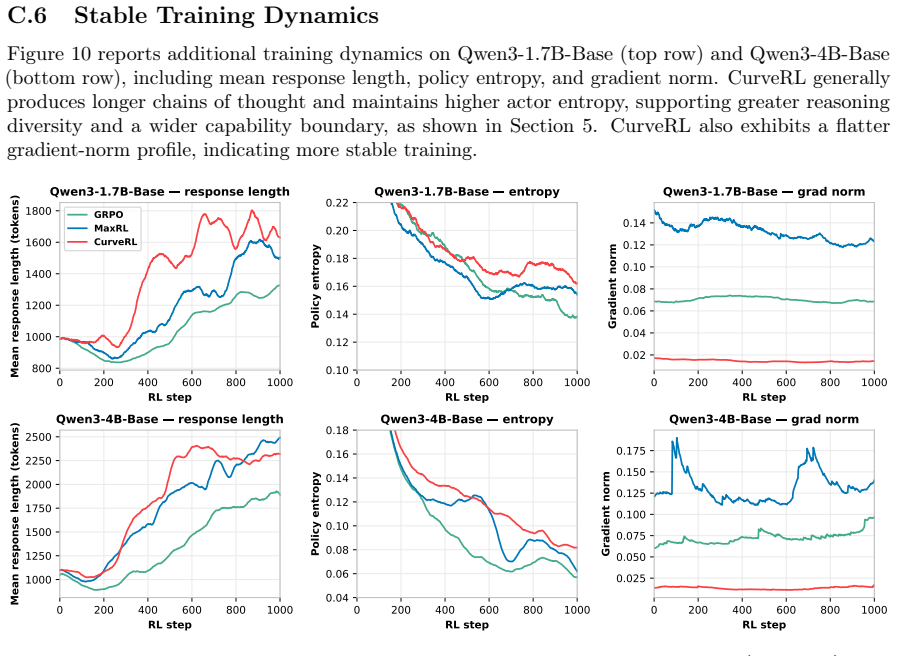
CurveRL also exhibits a flatter gradient-norm profile, indicating more stable training. 0 200 400 600 800 1000 RL step 800 1000 1200 1400 1600 1800Mean response length (tokens) Qwen3-1.7B-Base response length GRPO MaxRL CurveRL 0 200 400 600 800 1000 RL step 0.10 0.12 0.14 0.16 0.18 0.20 0.22Policy entropy Qwen3-1.7B-Base entropy 0 200 400 600 800 1000 RL...
2000
-
[45]
Only CurveRL’s panels (left two) reflect 1.7B training, since the GRPO and MaxRL weights are static. 34 D More Discussions D.1 Curriculum Learning under Our Framework Curriculum Learning is a Time-Varying Pointwise Prompt Reweighting Method.The curriculum learning strategy in RLVR, such as [Parashar et al., 2025], develops different data scheduling from e...
2025
discussion (0)
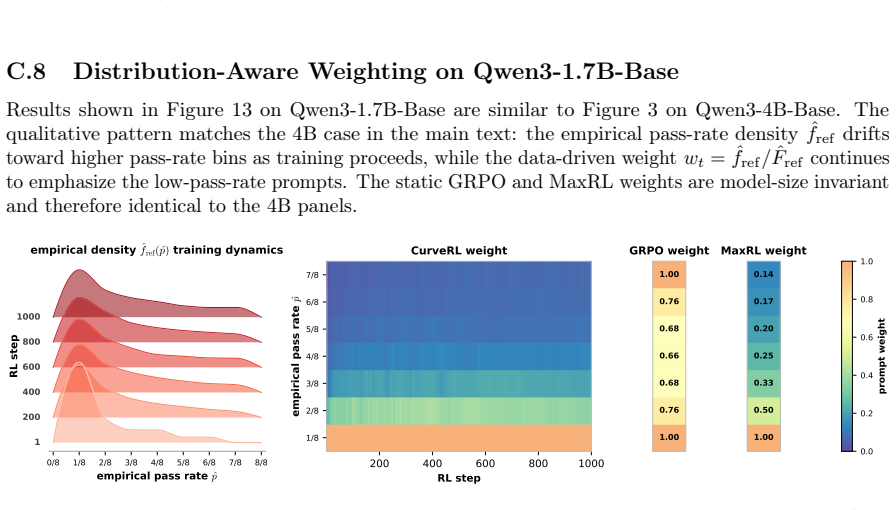
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.