FUSE: Frequency-domain Unification and Spectral Energy Alignment for Multi-modal Object Re-Identification
Pith reviewed 2026-06-26 18:16 UTC · model grok-4.3
The pith
FUSE reformulates multi-modal ReID as spectral disentanglement followed by energy alignment across frequency subspaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
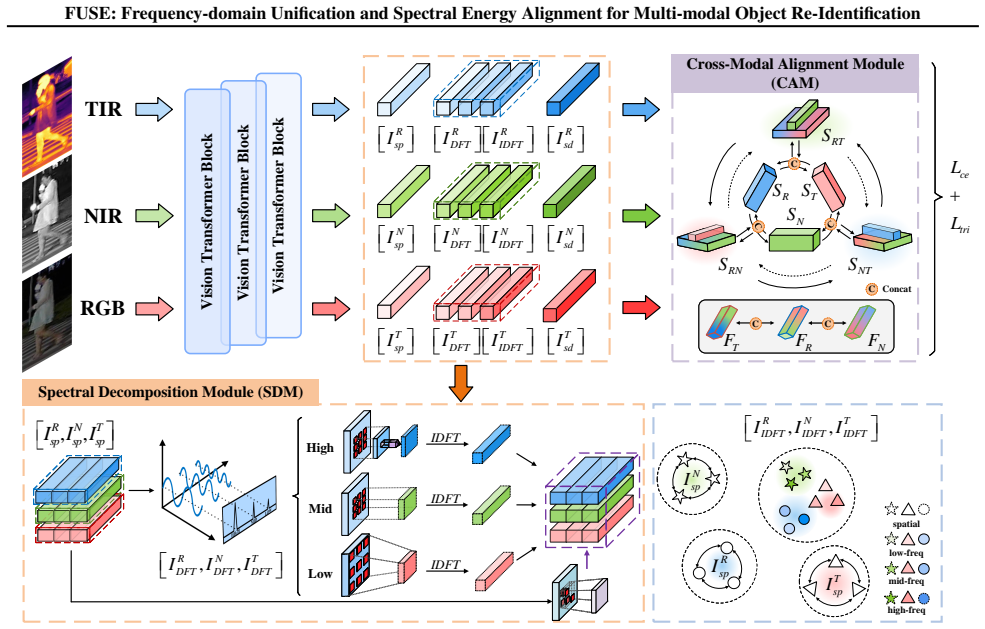
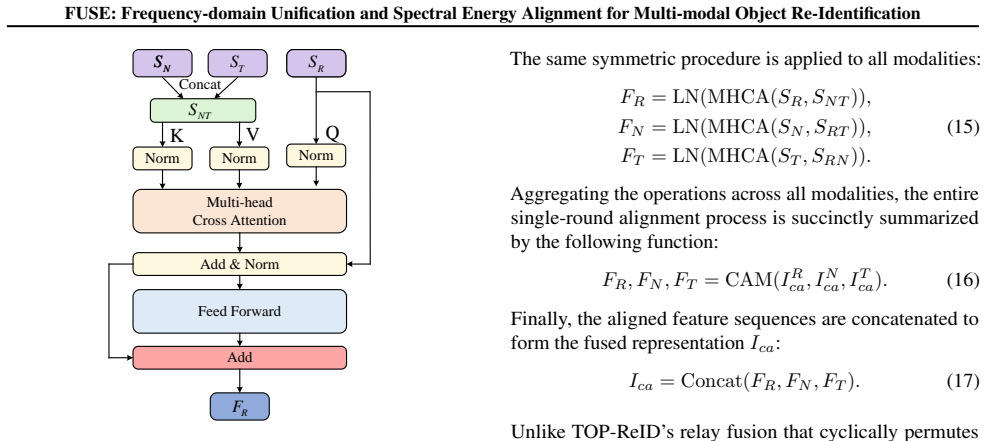
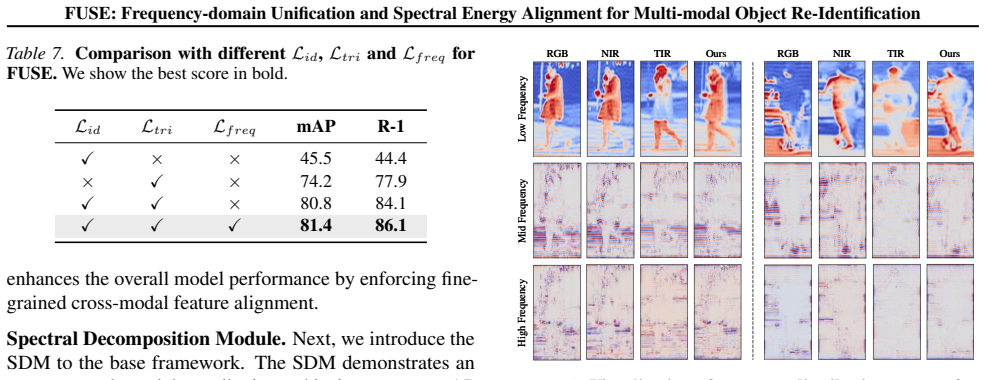
FUSE reformulates multi-modal ReID as a two-stage process of spectral disentanglement and energy alignment. The Spectral Decomposition Module adaptively partitions features into low, mid, and high-frequency subspaces, enabling hierarchical spectral modeling. The Cross-Modal Alignment Module enforces energy alignment and subspace complementarity across modalities via frequency-consistency regularization. In addition, FUSE incorporates learnable frequency modulation to enhance robustness under varying illumination and heterogeneous sensor conditions.
What carries the argument
Spectral Decomposition Module (SDM) that adaptively partitions features into low-, mid-, and high-frequency subspaces, paired with Cross-Modal Alignment Module (CAM) that enforces energy alignment via frequency-consistency regularization.
If this is right
- Hierarchical spectral modeling captures geometric and textural details previously overlooked.
- Frequency-consistency regularization improves stability of cross-modal alignment.
- Learnable frequency modulation increases robustness to illumination changes and sensor differences.
- Reported gains reach 9.1 percent mAP and 9.5 percent Rank-1 on RGBNT201, RGBNT100, and MSVR310.
Where Pith is reading between the lines
- The same frequency partitioning could be tested on single-modal ReID by treating different augmentations as pseudo-modalities.
- Subspace complementarity might allow selective masking of less informative frequency bands to reduce compute.
- The approach raises the question of whether fixed or learned band boundaries work best for particular sensor pairs.
- Frequency energy alignment might transfer to multi-modal tasks beyond ReID such as tracking or detection.
- pith_inferences
Load-bearing premise
The assumption that adaptive partitioning into three frequency subspaces plus energy alignment will succeed without instabilities or extra tuning across heterogeneous sensors.
What would settle it
A test on a fresh multi-modal ReID dataset with strong sensor mismatch where the frequency modules produce no accuracy gain over a baseline that uses only low-frequency features.
Figures

read the original abstract
Despite significant progress in multi-modal Re-Identification (ReID), existing methods tend to emphasize low-frequency cues. Consequently, they focus on attributes such as color, illumination, and coarse appearance, while overlooking mid and high-frequency structures that encode geometric, textural, and identity-discriminative details. This imbalance leads to incomplete spectral representations and unstable cross-modal alignment. To overcome these limitations, we introduce FUSE, a frequency-domain framework that reformulates multi-modal ReID as a two-stage process of spectral disentanglement and energy alignment. The proposed Spectral Decomposition Module (SDM) adaptively partitions features into low, mid, and high-frequency subspaces, enabling hierarchical spectral modeling. The Cross-Modal Alignment Module (CAM) further enforces energy alignment and subspace complementarity across modalities via frequency-consistency regularization. In addition, FUSE incorporates learnable frequency modulation to enhance robustness under varying illumination and heterogeneous sensor conditions. Extensive experiments on RGBNT201, RGBNT100, and MSVR310 show that FUSE achieves 9.1\% mAP and 9.5\% Rank-1 improvements, establishing an interpretable frequency-domain paradigm for multi-modal representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FUSE, a frequency-domain framework for multi-modal object Re-Identification. It reformulates the task as a two-stage process of spectral disentanglement and energy alignment. The Spectral Decomposition Module (SDM) adaptively partitions features into low-, mid-, and high-frequency subspaces for hierarchical modeling. The Cross-Modal Alignment Module (CAM) enforces energy alignment and subspace complementarity across modalities via frequency-consistency regularization, with additional learnable frequency modulation for robustness under varying illumination and heterogeneous sensors. Experiments on RGBNT201, RGBNT100, and MSVR310 report 9.1% mAP and 9.5% Rank-1 gains.
Significance. If the reported gains are substantiated by complete baselines, ablations, and controls, the work could introduce an interpretable frequency-domain paradigm for multi-modal ReID by explicitly addressing spectral imbalance. The modular separation of disentanglement and alignment offers a structured alternative to existing methods that over-rely on low-frequency cues.
Simulated Author's Rebuttal
We thank the referee for their summary of our manuscript and for acknowledging the potential of FUSE to introduce an interpretable frequency-domain paradigm for multi-modal ReID through explicit spectral disentanglement and alignment. We note the recommendation of 'uncertain' and the emphasis on experimental substantiation; our full manuscript includes extensive baselines, ablations, and controls across the three datasets to support the reported gains.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces FUSE as a frequency-domain framework with two new modules (SDM for adaptive partitioning into frequency subspaces and CAM for energy alignment via frequency-consistency regularization). No equations, fitting procedures, or self-citations are present in the provided text that would reduce any claimed prediction or result to a quantity defined by the method's own inputs or parameters. The central reformulation and reported improvements rest on the proposed architecture and experimental outcomes rather than any self-definitional or fitted-input reduction. This is the most common honest finding for a methods paper whose derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Frequency decomposition (e.g., via Fourier or wavelet transforms) can be meaningfully applied to intermediate feature maps of convolutional networks
invented entities (2)
-
Spectral Decomposition Module (SDM)
no independent evidence
-
Cross-Modal Alignment Module (CAM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
IEEE Transactions on Circuits and Systems for Video Technology , volume=
A survey of open-world person re-identification , author=. IEEE Transactions on Circuits and Systems for Video Technology , volume=. 2019 , publisher=
2019
-
[10]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
Bag of tricks and a strong baseline for deep person re-identification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
-
[11]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Transreid: Transformer-based object re-identification , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Sjdl-vehicle: Semi-supervised joint defogging learning for foggy vehicle re-identification , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[13]
IEEE Transactions on Neural Networks and Learning Systems , year=
Tienet: A tri-interaction enhancement network for multimodal person reidentification , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
RLE: A unified perspective of data augmentation for cross-spectral re-identification , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv preprint arXiv:2408.16684 , year=
Partformer: Awakening latent diverse representation from vision transformer for object re-identification , author=. arXiv preprint arXiv:2408.16684 , year=
-
[16]
International Conference on Machine Learning , pages=
FlexiReID: Adaptive Mixture of Expert for Multi-Modal Person Re-Identification , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[17]
International Journal of Computer Vision , volume=
Adaptive middle modality alignment learning for visible-infrared person re-identification , author=. International Journal of Computer Vision , volume=. 2025 , publisher=
2025
-
[18]
Proceedings of the AAAI conference on artificial intelligence , volume=
Occluded person re-identification via saliency-guided patch transfer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
White-Balance First, Adjust Later: Cross-Camera Color Constancy via Vision-Language Evaluation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Bridging day and night: Target-class hallucination suppression in unpaired image translation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[21]
Tan et al
Knowing Where to Focus: Attention-Guided Alignment for Text-based Person Search: L. Tan et al. , author=. International Journal of Computer Vision , volume=. 2026 , publisher=
2026
-
[22]
Advances in Neural Information Processing Systems , volume=
GSAlign: Geometric and Semantic Alignment Network for Aerial-Ground Person Re-Identification , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
MDReID: Modality-Decoupled Learning for Any-to-Any Multi-Modal Object Re-Identification , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
International Conference on Machine Learning , pages=
Multi-Modal Object Re-identification via Sparse Mixture-of-Experts , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[25]
IEEE Transactions on Information Forensics and Security , year=
Frequency domain nuances mining for visible-infrared person re-identification , author=. IEEE Transactions on Information Forensics and Security , year=
-
[26]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Famnet: Frequency-aware matching network for cross-domain few-shot medical image segmentation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-frequency component helps explain the generalization of convolutional neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
arXiv preprint arXiv:2202.06709 , year=
How do vision transformers work? , author=. arXiv preprint arXiv:2202.06709 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Vtc-lfc: Vision transformer compression with low-frequency components , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
arXiv preprint arXiv:2505.20001 , year=
NEXT: Multi-Grained Mixture of Experts via Text-Modulation for Multi-Modal Object Re-ID , author=. arXiv preprint arXiv:2505.20001 , year=
-
[31]
Proceedings of the AAAI conference on artificial intelligence , volume=
Interact, embed, and enlarge: Boosting modality-specific representations for multi-modal person re-identification , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[32]
IEEE Transactions on Intelligent Transportation Systems , volume=
Graph-based progressive fusion network for multi-modality vehicle re-identification , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2023 , publisher=
2023
-
[33]
CAAI international conference on artificial intelligence , pages=
H-vit: Hybrid vision transformer for multi-modal vehicle re-identification , author=. CAAI international conference on artificial intelligence , pages=. 2022 , organization=
2022
-
[34]
IEEE Transactions on Circuits and Systems for Video Technology , year=
Discovering Multi-Frequency Embedding for Visible-Infrared Person Re-identification , author=. IEEE Transactions on Circuits and Systems for Video Technology , year=
-
[35]
arXiv preprint arXiv:2305.15762 , year=
Dynamic enhancement network for partial multi-modality person re-identification , author=. arXiv preprint arXiv:2305.15762 , year=
-
[36]
Expert Systems with Applications , volume=
LRMM: Low rank multi-scale multi-modal fusion for person re-identification based on RGB-NI-TI , author=. Expert Systems with Applications , volume=. 2025 , publisher=
2025
-
[37]
arXiv preprint arXiv:2310.18812 , year=
Unicat: Crafting a stronger fusion baseline for multimodal re-identification , author=. arXiv preprint arXiv:2310.18812 , year=
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Heterogeneous test-time training for multi-modal person re-identification , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
Proceedings of the AAAI conference on artificial intelligence , volume=
Top-reid: Multi-spectral object re-identification with token permutation , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Magic tokens: Select diverse tokens for multi-modal object re-identification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
IEEE Transactions on Circuits and Systems for Video Technology , year=
Representation selective coupling via token sparsification for multi-spectral object re-identification , author=. IEEE Transactions on Circuits and Systems for Video Technology , year=
-
[42]
Expert Systems with Applications , volume=
WTSF-ReID: Depth-driven Window-oriented Token Selection and Fusion for multi-modality vehicle re-identification with knowledge consistency constraint , author=. Expert Systems with Applications , volume=. 2025 , publisher=
2025
-
[43]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Idea: Inverted text with cooperative deformable aggregation for multi-modal object re-identification , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Decoupled feature-based mixture of experts for multi-modal object re-identification , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[45]
IEEE Transactions on Image Processing , year=
Escaping Modal Interactions: An Efficient DESANet for Multi-Modal Object Re-Identification , author=. IEEE Transactions on Image Processing , year=
-
[46]
Proceedings of the IEEE international conference on computer vision , pages=
Multi-scale deep learning architectures for person re-identification , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[47]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Harmonious attention network for person re-identification , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[48]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Multi-level factorisation net for person re-identification , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[49]
Proceedings of the European conference on computer vision (ECCV) , pages=
Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline) , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[50]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Omni-scale feature learning for person re-identification , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[51]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Counterfactual attention learning for fine-grained visual categorization and re-identification , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[52]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Mambapro: Multi-modal object re-identification with mamba aggregation and synergistic prompt , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[53]
2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP) , pages=
Generative and attentive fusion for multi-spectral vehicle re-identification , author=. 2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP) , pages=. 2022 , organization=
2022
-
[54]
Information Fusion , volume=
Cross-directional consistency network with adaptive layer normalization for multi-spectral vehicle re-identification and a high-quality benchmark , author=. Information Fusion , volume=. 2023 , publisher=
2023
-
[55]
Sensors , volume=
Progressively hybrid transformer for multi-modal vehicle re-identification , author=. Sensors , volume=. 2023 , publisher=
2023
-
[56]
Information Fusion , volume=
Flare-aware cross-modal enhancement network for multi-spectral vehicle Re-identification , author=. Information Fusion , volume=. 2025 , publisher=
2025
-
[57]
arXiv preprint arXiv:2310.16856 , year=
Graft: Gradual fusion transformer for multimodal re-identification , author=. arXiv preprint arXiv:2310.16856 , year=
-
[58]
arXiv preprint arXiv:2602.10825 , year=
Flow caching for autoregressive video generation , author=. arXiv preprint arXiv:2602.10825 , year=
-
[59]
IEEE transactions on pattern analysis and machine intelligence , volume=
Deep learning for person re-identification: A survey and outlook , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
2021
-
[60]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Heterogeneous relational complement for vehicle re-identification , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[61]
Proceedings of the AAAI conference on artificial intelligence , volume=
Ompq: Orthogonal mixed precision quantization , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[62]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Circle loss: A unified perspective of pair similarity optimization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[63]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Deep meta metric learning , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[64]
Proceedings of the 26th ACM international conference on Multimedia , pages=
Learning discriminative features with multiple granularities for person re-identification , author=. Proceedings of the 26th ACM international conference on Multimedia , pages=
-
[65]
Proceedings of the AAAI conference on artificial intelligence , volume=
Robust multi-modality person re-identification , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[66]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multi-spectral vehicle re-identification: A challenge , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[67]
arXiv preprint arXiv:2208.00632 , year=
Multi-spectral vehicle re-identification with cross-directional consistency network and a high-quality benchmark , author=. arXiv preprint arXiv:2208.00632 , year=
-
[68]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[69]
IEEE Transactions on Image Processing , year=
Prompt-based modality alignment for effective multi-modal object re-identification , author=. IEEE Transactions on Image Processing , year=
-
[70]
Proceedings of the AAAI conference on artificial intelligence , volume=
Decoupled contrastive multi-view clustering with high-order random walks , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[71]
arXiv preprint arXiv:2504.10174 , year=
LLaVA-ReID: Selective multi-image questioner for interactive person re-identification , author=. arXiv preprint arXiv:2504.10174 , year=
-
[72]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Chatreid: Open-ended interactive person retrieval via hierarchical progressive tuning for vision language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[73]
Machine Learning , volume=
FDGReID: Federated Domain Generalization for Person Re-identification , author=. Machine Learning , volume=. 2026 , publisher=
2026
-
[74]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning with twin noisy labels for visible-infrared person re-identification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[75]
International Journal of Computer Vision , volume=
An information theory-inspired strategy for automated network pruning , author=. International Journal of Computer Vision , volume=. 2025 , publisher=
2025
-
[76]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Solving oscillation problem in post-training quantization through a theoretical perspective , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[77]
Forty-first International Conference on Machine Learning , year=
Outlier-aware slicing for post-training quantization in vision transformer , author=. Forty-first International Conference on Machine Learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.