The MMM Data Model -- A Normative Specification for Knowledge Interoperability in a Decentralisable Knowledge Commons
Pith reviewed 2026-07-03 23:01 UTC · model grok-4.3
The pith
MMM is a data model that pairs a small set of normative constraints with free-text labels to enable knowledge interoperability across disciplines without requiring semantic convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MMM is a data model for knowledge documentation that combines a small set of normative constraints with the expressive freedom of free-text labels. It supports structuring, updating, sharing and reuse of knowledge in ways that move beyond self-contained documents while remaining portable across disciplines, applications and deployments without mandating semantic convergence.
What carries the argument
The MMM data model, which applies a minimal normative core to knowledge elements while permitting unrestricted free-text labels for content and relations.
If this is right
- Knowledge structures can be updated and reused more flexibly than in linear documents.
- Interoperability becomes possible across disciplines without requiring agreement on meanings.
- The model supports decentralisable knowledge commons by remaining portable across deployments.
- A reference implementation confirms that the minimal constraints are sufficient for basic functionality.
Where Pith is reading between the lines
- MMM could serve as a bridge layer allowing AI-generated content to integrate with human-maintained knowledge records.
- The approach might extend to domains like collaborative science platforms where participants resist formal ontologies.
- Pilot data could be used to test whether label diversity scales without creating fragmentation in larger user groups.
Load-bearing premise
A small normative core plus free-text labels is sufficient to deliver practical interoperability and adoption where formal and document-centric systems have not.
What would settle it
A multi-disciplinary deployment in which participants using MMM fail to share or reuse knowledge across groups without adding further semantic agreements or external mappings.
Figures


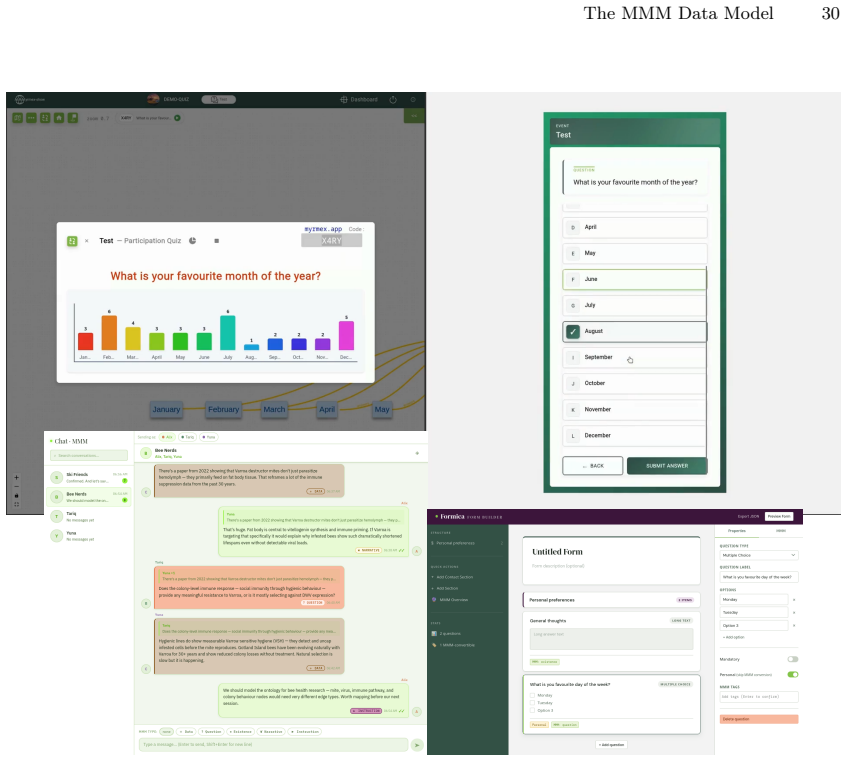


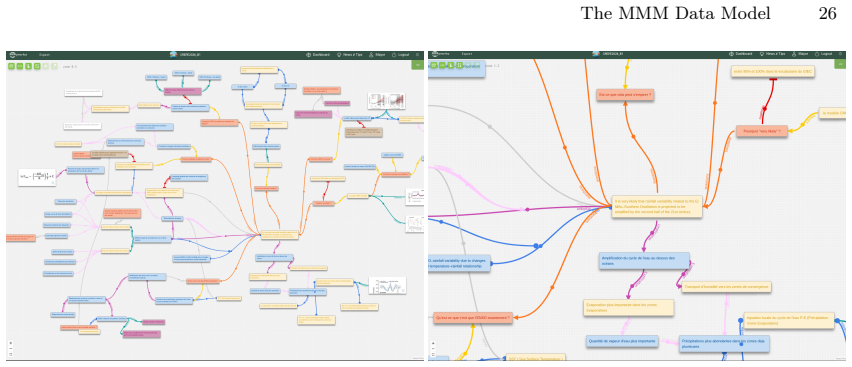


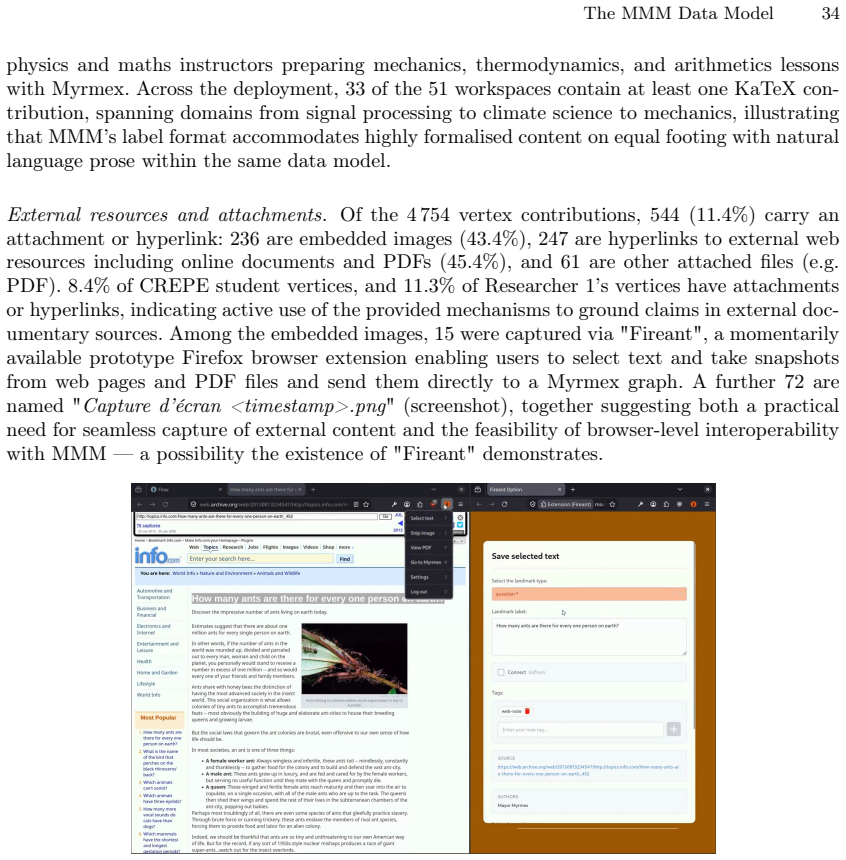




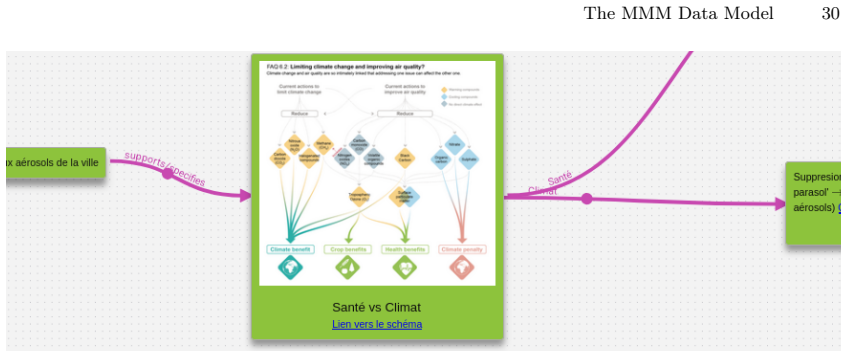

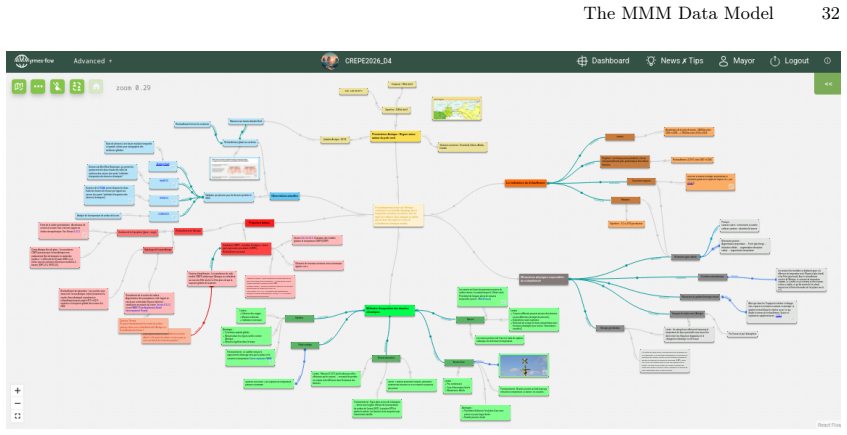

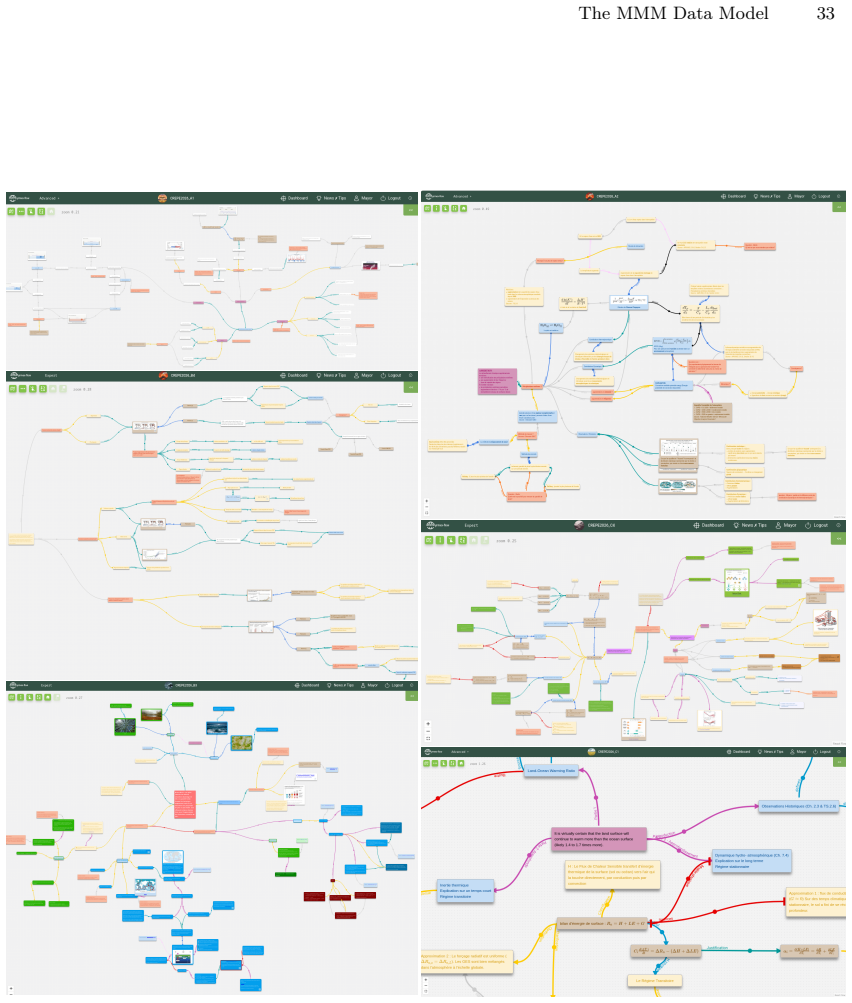


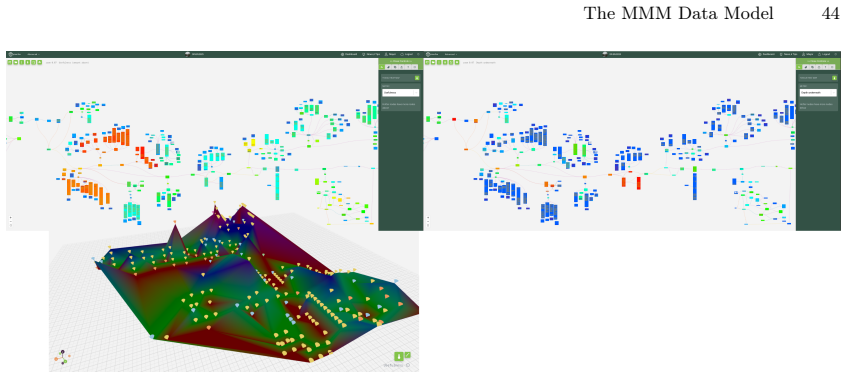
read the original abstract
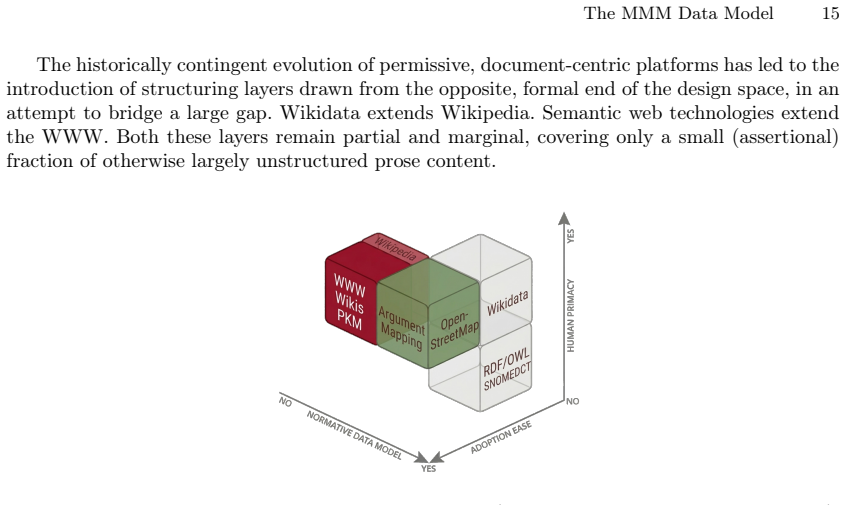
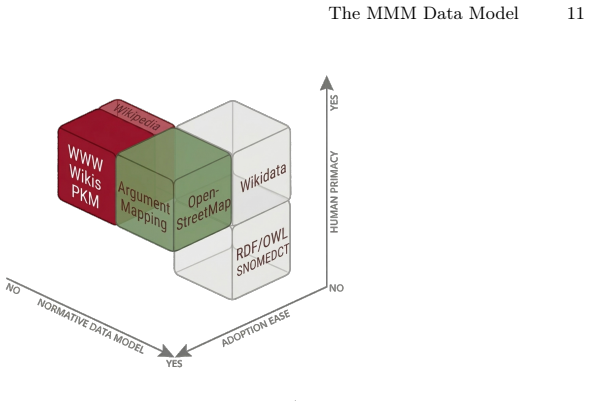
Many information systems are built around documents: self-contained units optimised for print production and linear reading. While effective for large-scale dissemination, the document-centric organisation constrains how knowledge can be structured, updated, shared, and reused. Formal approaches address some of these limitations but struggle to achieve widespread contribution and adoption due to their prioritisation of formal structure over other system properties such as human usability and scope. AI systems are reshaping document production, but without providing a unified portable alternative to traditional documents for humans' expression and exchange of knowledge. This paper presents MMM, a data model for knowledge documentation that emerged from the practical needs of interdisciplinary collaborative research, and positioned here within a comparative analysis of the design space of information systems. MMM combines a small set of normative constraints with the expressive freedom of free-text labels. It is designed for interoperability across disciplines, applications and deployments without requiring semantic convergence. A reference implementation and pilot deployment data demonstrate implementability and early usability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MMM, a data model for knowledge documentation that emerged from interdisciplinary collaborative research needs. It positions MMM in the design space of information systems by combining a small set of normative constraints with the expressive freedom of free-text labels, claiming this enables interoperability across disciplines, applications, and deployments without requiring semantic convergence. A reference implementation and pilot deployment data are cited to demonstrate implementability and early usability, contrasting with limitations of document-centric and formal approaches as well as AI-driven document production.
Significance. If the design and supporting evidence hold, MMM could provide a practical middle ground for knowledge representation that prioritizes both structure and human usability, potentially lowering barriers to contribution and reuse in decentralized, cross-disciplinary settings compared to existing formal or document-based systems.
major comments (1)
- [Abstract] Abstract: the central claim that a small normative core plus unrestricted free-text labels is sufficient to achieve practical interoperability across disciplines and deployments without semantic convergence is asserted but not supported by mechanism details, metrics of successful data exchange between independent parties, or comparisons showing reduced adoption barriers; the reference implementation and pilot data are mentioned without quantitative results or constraints list.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of MMM's potential. We respond to the single major comment below, acknowledging where the abstract requires strengthening while clarifying the support present in the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that a small normative core plus unrestricted free-text labels is sufficient to achieve practical interoperability across disciplines and deployments without semantic convergence is asserted but not supported by mechanism details, metrics of successful data exchange between independent parties, or comparisons showing reduced adoption barriers; the reference implementation and pilot data are mentioned without quantitative results or constraints list.
Authors: The full manuscript provides the mechanism details via the explicit list of normative constraints in Section 3, which define the minimal core while permitting free-text labels for cross-disciplinary use without enforced semantic convergence. Section 2 contains the comparative analysis positioning MMM against document-centric and formal systems with respect to adoption barriers. Sections 5 and 6 describe the reference implementation and pilot deployment, respectively. We agree the abstract is too concise to convey these elements and will revise it to include a brief enumeration of the core constraints and to clarify that the pilot evidence is qualitative (usability and implementability) rather than quantitative. The manuscript does not report quantitative metrics of successful data exchange between independent parties, as the contribution is a normative specification supported by an initial pilot rather than a large-scale empirical study of exchanges. revision: yes
Circularity Check
No circularity: normative specification without derivations or self-referential reductions
full rationale
The paper is a normative specification for a data model (MMM) that combines minimal constraints with free-text labels. No equations, fitted parameters, predictions of derived quantities, or load-bearing self-citations appear in the abstract or described structure. The positioning within the design space and claims of interoperability are presented as design choices justified by practical needs and a reference implementation, not as outputs derived from prior inputs by construction. No steps match any enumerated circularity pattern; the work is self-contained as a proposal rather than a derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Interoperability across disciplines can be achieved without requiring semantic convergence on term meanings.
invented entities (1)
-
MMM data model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Bernstein, A., Karger, D.R., Heath, T., Feigenbaum, L., Maynard, D., Motta, E., Thirunarayan, K
Auer, S., Lehmann, J., Hellmann, S.: Linkedgeodata: Adding a spatial dimension to the web of data. In: Bernstein, A., Karger, D.R., Heath, T., Feigenbaum, L., Maynard, D., Motta, E., Thirunarayan, K. (eds.) The Semantic Web - ISWC. pp. 731–746. Springer Berlin Heidelberg (2009)
2009
-
[2]
Baader, F., Calvanese, D., McGuinness, D., Nardi, D., Patel-Schneider, P.: The Description Logic Handbook: Theory, Implementation and Applications. 2nd ed. Cambridge University Press, 2 edn. (2007)
2007
-
[3]
PLOS ONE12(8), 1–20 (2017)
Barrington-Leigh, C., Millard-Ball, A.: The world’s user-generated road map is more than 80% complete. PLOS ONE12(8), 1–20 (2017)
2017
-
[4]
Yale University Press (2006)
Benkler, Y.: The wealth of networks: How social production transforms markets and freedom. Yale University Press (2006)
2006
-
[5]
Scientific American284(5), 34–43 (2001)
Berners-Lee, T., Hendler, J., Lassila, O.: The semantic web. Scientific American284(5), 34–43 (2001)
2001
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence 38(16), 17682–17690 (2024)
Besta, M., Blach, N., Kubicek, A., Gerstenberger, R., Podstawski, M., Gianinazzi, L., Gajda, J., Lehmann, T., Niewiadomski, H., Nyczyk, P., Hoefler, T.: Graph of thoughts: Solving elaborate problems with large language models. Proceedings of the AAAI Conference on Artificial Intelligence 38(16), 17682–17690 (2024)
2024
-
[7]
IEEE Transactions on Pattern Analysis and Machine Intelligence47(12), 10967–10989 (2025)
Besta, M., Memedi, F., Zhang, Z., Gerstenberger, R., Piao, G., Blach, N., Nyczyk, P., Copik, M., Kwaśniewski, G., Müller, J., Gianinazzi, L., Kubicek, A., Niewiadomski, H., O’Mahony, A., Mutlu, O., Hoefler, T.: Demystifying chains, trees, and graphs of thoughts. IEEE Transactions on Pattern Analysis and Machine Intelligence47(12), 10967–10989 (2025)
2025
-
[8]
International Journal on Semantic Web and Information Systems5(3), 1–22 (2009)
Bizer, C., Heath, T., Berners-Lee, T.: Linked data-the story so far. International Journal on Semantic Web and Information Systems5(3), 1–22 (2009)
2009
-
[9]
In: Proceedings of the 2008 ACM SIGMOD international conference on Management of data
Bollacker, K., Evans, C., Paritosh, P., Sturge, T., Taylor, J.: Freebase: a collaboratively created graph database for structuring human knowledge. In: Proceedings of the 2008 ACM SIGMOD international conference on Management of data. pp. 1247–1250. SIGMOD ’08 (2008)
2008
-
[10]
Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M.S., Bohg, J., Bosselut, A., Brunskill, E., Brynjolfsson, E., Buch, S., Card, D., Castellon, R., Chatterji, N., Chen, A., Creel, K., Davis, J.Q., Demszky, D., Donahue, C., Doumbouya, M., Durmus, E., Ermon, S., Etchemendy, J., Ethayarajh, K., Fei-Fei, L., Finn, C., Gale...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Brereton, D.: The next Google (2022), https://dkb.blog/p/the-next-google, dKB Blog
2022
-
[12]
The atlantic monthly176(1), 101–108 (1945)
Bush, V.: As we may think. The atlantic monthly176(1), 101–108 (1945)
1945
-
[13]
Chen, L., Zaharia, M., Zou, J.: Frugalgpt: How to use large language models while reducing cost and improving performance (2023), https://arxiv.org/abs/2305.05176
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
The Knowledge Engineering Review 21(4), 293–316 (2006)
Chesnevar, C.I., McGinnis, J., Modgil, S., Rahwan, I., Reed, C., Simari, G., South, M., Vreeswijk, G., Willmott, S.: Towards an argument interchange format. The Knowledge Engineering Review 21(4), 293–316 (2006)
2006
-
[15]
W3C Recommen- dation (2014), http://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/
Cyganiak, R., Wood, D., Lanthaler, M.: RDF 1.1 Concepts and Abstract Syntax. W3C Recommen- dation (2014), http://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/
2014
-
[16]
Communications of the ACM58(9), 92–103 (2015) The MMM Data Model 43
Davis, E., Marcus, G.: Commonsense reasoning and commonsense knowledge in artificial intelligence. Communications of the ACM58(9), 92–103 (2015) The MMM Data Model 43
2015
-
[17]
In: SGML/XML (1997)
DeRose, S.J., Maden, C.R.: Problems with dynamically assembled document portions, and some solutions. In: SGML/XML (1997)
1997
-
[18]
In: ACM SIGMOD International Conference on Management of Data
Ellis, C.A., Gibbs, S.J.: Concurrency control in groupware systems. In: ACM SIGMOD International Conference on Management of Data. pp. 399–407. SIGMOD ’89 (1989)
1989
-
[19]
University of Chicago Press (1981), originally published in German, 1935
Fleck, L.: Genesis and development of a scientific fact. University of Chicago Press (1981), originally published in German, 1935. Translated by F. Bradley and T. J. Trenn
1981
-
[20]
Foucault, M.: What is an author? In: Reading architectural history, pp. 71–81. Routledge (2003)
2003
-
[21]
IEEE Pervasive Computing 7(4), 12–18 (2008)
Haklay, M., Weber, P.: Openstreetmap: User-generated street maps. IEEE Pervasive Computing 7(4), 12–18 (2008)
2008
-
[22]
Haller, A., Polleres, A.: Are we better off with just one ontology on the web? Semantic Web11(1), 87–99 (2020)
2020
-
[23]
W3C Recommendation (2014), https://www
Hayes, P., Patel-Schneider, P.F.: RDF 1.1 semantics. W3C Recommendation (2014), https://www. w3.org/TR/rdf11-mt/
2014
-
[24]
Hillis, D., Klein, S., Rich, T.: Underlay: A First Description (2018)
2018
-
[25]
Communications of the ACM64(2), 76–83 (2021)
Hitzler, P.: A review of the semantic web field. Communications of the ACM64(2), 76–83 (2021)
2021
-
[26]
W3C Recommendation (2012), https://www.w3.org/TR/owl2-primer/
Hitzler,P.,Krötzsch,M.,Parsia,B.,Patel-Schneider,P.F.,Rudolph,S.:Owl2webontologylanguage primer (second edition). W3C Recommendation (2012), https://www.w3.org/TR/owl2-primer/
2012
-
[27]
ACM Comput
Hogan, A., Blomqvist, E., Cochez, M., D’amato, C., Melo, G.D., Gutierrez, C., Kirrane, S., Gayo, J.E.L., Navigli, R., Neumaier, S., Ngomo, A.C.N., Polleres, A., Rashid, S.M., Rula, A., Schmelzeisen, L., Sequeda, J., Staab, S., Zimmermann, A.: Knowledge graphs. ACM Comput. Surv.54(4) (2021)
2021
-
[28]
In: International AAAI Conference on Web and Social Media (ICWSM)
Hristova, D., Quattrone, G., Mashhadi, A., Capra, L.: The life of the party: Impact of social mapping in OpenStreetMap. In: International AAAI Conference on Web and Social Media (ICWSM). vol. 7, pp. 234–243 (2013)
2013
-
[29]
Huang, S., Siddarth, D.: Generative ai and the digital commons (2023), https://arxiv.org/abs/2303. 11074
2023
-
[30]
The information society16(3), 169–185 (2000)
Introna, L.D., Nissenbaum, H.: Shaping the web: Why the politics of search engines matters. The information society16(3), 169–185 (2000)
2000
-
[31]
IPCC: Summary for Policymakers, pp. 3–32. Cambridge University Press (2021)
2021
- [32]
-
[33]
In: Proc
Kiermer, V., Adams, S., Bibbins-Domingo, K., Flores Bueso, Y., Jamieson, K.H., Heber, J., Hos- seini, M., Marušić, A., Nielsen, B., Skipper, M., Swamy, G.K., Wolf, S.M.: Creating a responsible authorship culture in science: Anchoring authorship practices in principles of transparency, credit, and accountability. In: Proc. Natl. Acad. Sci. U.S.A. vol. 123 (2026)
2026
-
[34]
IEEE Transactions on Parallel and Distributed Systems28(10), 2733–2746 (2017)
Kleppmann, M., Beresford, A.R.: A conflict-free replicated JSON datatype. IEEE Transactions on Parallel and Distributed Systems28(10), 2733–2746 (2017)
2017
-
[35]
https://doi.org/10.48550/arXiv.2506.11135
Krakauer, D.C., Krakauer, J.W., Mitchell, M.: Large language models and emergence: A complex systems perspective (2025). https://doi.org/10.48550/arXiv.2506.11135
-
[36]
University of Chicago Press (1962)
Kuhn, T.S.: The Structure of Scientific Revolutions. University of Chicago Press (1962)
1962
-
[37]
Kunz, W., Rittel, H.W.: Issues as elements of information systems (working paper). Tech. rep., Berkeley: Institute of Urban and Regional Development (1970)
1970
-
[38]
Harvard uni- versity press (1987)
Latour, B.: Science in action: How to follow scientists and engineers through society. Harvard uni- versity press (1987)
1987
-
[39]
Princeton University Press (1986)
Latour, B., Woolgar, S.: Laboratory Life: The Construction of Scientific Facts. Princeton University Press (1986)
1986
-
[40]
AI & Society40(6), 5063–5076 (2025)
Lindemann, N.F.: Chatbots, search engines, and the sealing of knowledges. AI & Society40(6), 5063–5076 (2025)
2025
-
[41]
In: Öffentliche Meinung und sozialer Wandel/Public Opinion and Social Change, pp
Luhmann, N.: Kommunikation mit zettelkästen: Ein erfahrungsbericht. In: Öffentliche Meinung und sozialer Wandel/Public Opinion and Social Change, pp. 222–228. Springer (1981)
1981
-
[42]
Journal of the Association for Information Science & Technology66(2), 219–245 (2015)
Mesgari, M., Okoli, C., Mehdi, M., Nielsen, F.A., Lanamäki, A.: The sum of all human knowledge: A systematic review of scholarly research on the content of wikipedia. Journal of the Association for Information Science & Technology66(2), 219–245 (2015)
2015
-
[43]
Future Inter- net4(1), 285–305 (2012)
Mooney, P., Corcoran, P.: Characteristics of heavily edited objects in OpenStreetMap. Future Inter- net4(1), 285–305 (2012)
2012
-
[44]
ISPRS International Journal of Geo-Information1(2), 146–165 (2012)
Neis,P.,Zipf, A.: Analyzing the contributor activity of avolunteered geographic informationproject– the case of openstreetmap. ISPRS International Journal of Geo-Information1(2), 146–165 (2012)
2012
-
[45]
Mindful Press, Sausalito, CA (1981) The MMM Data Model 44
Nelson, T.H.: Literary Machines. Mindful Press, Sausalito, CA (1981) The MMM Data Model 44
1981
-
[46]
arXiv preprint arXiv:2508.06470 (2025)
Noroozian, A., Aldana, L., Arisi, M., Asghari, H., Avila, R., Bizzaro, P.G., Chandrasekhar, R., Consonni, C., De Angelis, D., De Chiara, F., et al.: Generative ai and the future of the digital commons: Five open questions and knowledge gaps. arXiv preprint arXiv:2508.06470 (2025)
-
[47]
Noual, M.: Perspectives and networks (2016), http://arxiv.org/abs/1610.08765
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Theoretical Computer Science504, 12–25 (2013)
Noual, M., Regnault, D., Sené, S.: About non-monotony in boolean automata networks. Theoretical Computer Science504, 12–25 (2013)
2013
-
[49]
Human–computer interaction15(2-3), 139–178 (2000)
Olson, G.M., Olson, J.S.: Distance matters. Human–computer interaction15(2-3), 139–178 (2000)
2000
-
[50]
openstreetmap.org/wiki/API
OpenStreetMap Contributors: OpenStreetMap API Usage Policy (2024), https://wiki. openstreetmap.org/wiki/API
2024
-
[51]
Cambridge University Press, Cambridge (1990)
Ostrom, E.: Governing the Commons: The Evolution of Institutions for Collective Action. Cambridge University Press, Cambridge (1990)
1990
-
[52]
EPJ Web Conf.366, 01009 (2026)
Pastor, Dominique, Fernandez, Jonas, Thomas-Vaslin, Véronique: The generic sensory automaton (gensa) for modeling affinity-based dynamics and interactions in biology. EPJ Web Conf.366, 01009 (2026). https://doi.org/10.1051/epjconf/202636601009
-
[53]
Knowledge, Technology & Policy12(3), 23–49 (1999)
Raymond, E.S.: The cathedral and the bazaar: Musings on Linux and open source by an accidental revolutionary. Knowledge, Technology & Policy12(3), 23–49 (1999)
1999
-
[54]
The MIT Press (08 2010)
Reagle, J.: Good Faith Collaboration: The Culture of Wikipedia. The MIT Press (08 2010)
2010
-
[55]
PNAS nexus3(9), pgae400 (2024)
delRio-Chanona,R.M.,Laurentsyeva,N.,Wachs,J.:Largelanguagemodelsreducepublicknowledge sharing on online q&a platforms. PNAS nexus3(9), pgae400 (2024)
2024
-
[56]
Computer Supported Learning5, 43–102 (2010)
Scheuer, O., Loll, F., Pinkwart, N., McLaren, B.M.: Computer-supported argumentation: A review of the state of the art. Computer Supported Learning5, 43–102 (2010)
2010
-
[57]
Journal of Cultural Economy12(4), 265– 285 (2019)
Schneider, N.: Decentralization: an incomplete ambition. Journal of Cultural Economy12(4), 265– 285 (2019)
2019
-
[58]
IEEE Intelligent Systems21(3), 96–101 (2006)
Shadbolt, N., Berners-Lee, T., Hall, W.: The semantic web revisited. IEEE Intelligent Systems21(3), 96–101 (2006)
2006
-
[59]
Shapiro, M., Preguiça, N., Baquero, C., Zawirski, M.: A comprehensive study of Convergent and Commutative Replicated Data Types. Tech. Rep. RR-7506, INRIA (2011)
2011
-
[60]
Story, H.: contradiction and controversy - was: Is it necessary for the semantic web to be self con- tradictory? W3C Public Mailing List Archive (public-philoweb) (May 2015), https://lists.w3.org/ Archives/Public/public-philoweb/2015May/0004.html, message-Id: <9F05F606-8D4F-4C63-86E3- F7765C83D8C1@bblfish.net>
2015
- [61]
-
[62]
the rise and decline
TeBlunthuis, N., Shaw, A., Hill, B.M.: Revisiting "the rise and decline" in a population of peer production projects. In: CHI Conference on Human Factors in Computing Systems. pp. 1–7 (2018)
2018
-
[63]
Trace Labs – OriginTrail Core developers: Verifiable Internet for Artificial Intelligence: The Conver- gence of Crypto, Internet and AI (2024)
2024
-
[64]
Communications of the ACM57(10), 78–85 (2014)
Vrandečić, D., Krötzsch, M.: Wikidata: a free collaborative knowledgebase. Communications of the ACM57(10), 78–85 (2014)
2014
-
[65]
Emergent Abilities of Large Language Models
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., et al.: Emergent abilities of large language models. arXiv preprint arXiv:2206.07682 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[66]
php?title=Mapping_parties&oldid=2615609
Wiki, O.: Mapping parties — openstreetmap wiki, (2023), https://wiki.openstreetmap.org/w/index. php?title=Mapping_parties&oldid=2615609
2023
-
[67]
Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z., Liu, P., Nie, J.Y., Wen, J.R.: A survey of large language models (2026)
2026
-
[68]
Phd dissertation, University of Michigan (2025)
Zhu, J.: Solutions for Link Rot on the Modern Web. Phd dissertation, University of Michigan (2025)
2025
-
[69]
World Wide Web27(5), 58 (2024)
Zhu, Y., Wang, X., Chen, J., Qiao, S., Ou, Y., Yao, Y., Deng, S., Chen, H., Zhang, N.: Llms for knowledge graph construction and reasoning: Recent capabilities and future opportunities. World Wide Web27(5), 58 (2024)
2024
-
[70]
Zittrain, J., Bowers, J., Stanton, C.: The paper of record meets an ephemeral web: An examination of linkrot and content drift within The New York Times. Tech. rep., Library Innovation Lab, Harvard Law School (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.