Can BEV Perception Gracefully Degrade under Sensor Failures?
Pith reviewed 2026-06-28 22:54 UTC · model grok-4.3
The pith
Grace-BEV restores up to 34.7% mAP under catastrophic LiDAR failures in multi-modal BEV perception by actively assessing modality reliability instead of static fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
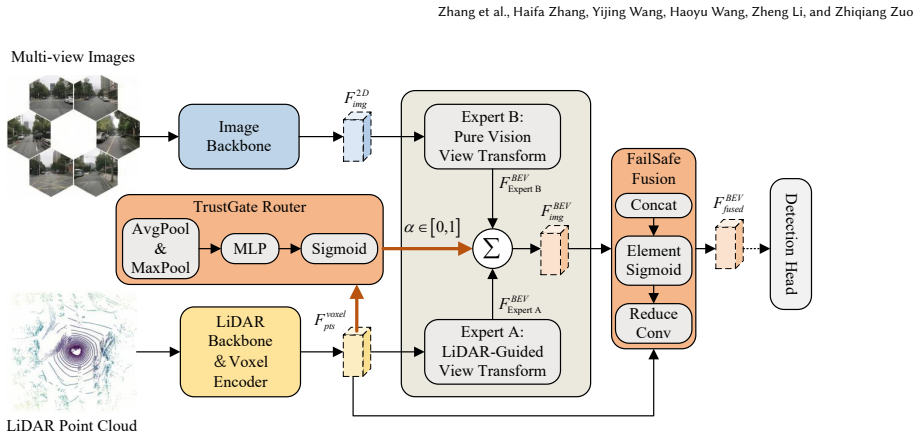
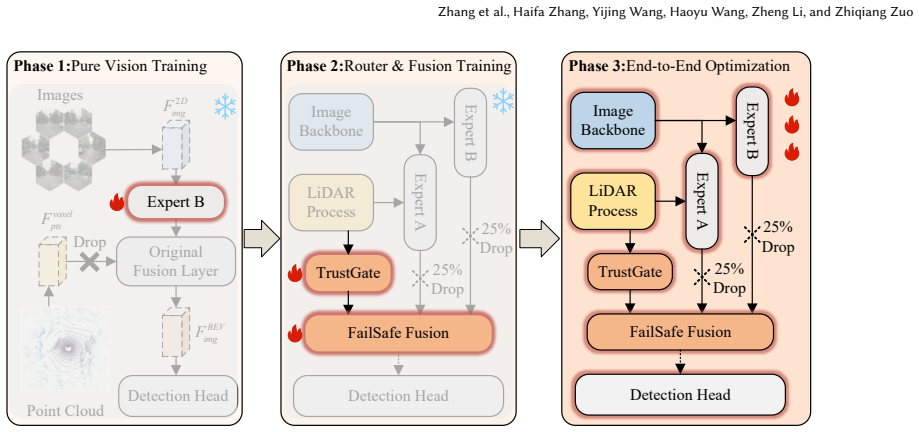
Graceful degradation is achievable through active modality reliability assessment: Grace-BEV uses the aligned BEV space to explicitly assess modality trustworthiness via a TrustGate Router and dynamically recalibrate feature integration using the FailSafe Fusion Block, with a Three-Phase Training strategy and Modality Dropout preventing dominance; this restores performance to as high as 34.7% mAP under catastrophic LiDAR failures where baselines reach 0.0% mAP while also improving clean accuracy by up to 1.4%.
What carries the argument
The TrustGate Router, which explicitly scores modality trustworthiness inside the aligned BEV feature space and feeds those scores to the FailSafe Fusion Block for dynamic recalibration of multi-modal integration.
If this is right
- The system maintains usable detection performance across a range of sensor corruptions on both nuScenes-R and nuScenes-C benchmarks.
- Clean-data accuracy rises by as much as 1.4% while adding only lightweight modules.
- The plug-and-play design allows existing BEV pipelines to adopt the reliability router and fusion block without full retraining.
- Balanced learning under modality dropout produces models that remain functional even when inputs become unreliable at inference time.
Where Pith is reading between the lines
- If the router's reliability scores prove stable across different sensor suites, the same mechanism could be reused for camera-radar or camera-thermal fusion without new architectural changes.
- The three-phase training schedule might generalize to other multi-modal tasks where one input is intermittently missing, such as audio-visual speech recognition.
- Real-world deployment would still require verifying that the BEV-space trustworthiness scores remain accurate when the underlying perception backbone itself is trained on different data distributions.
Load-bearing premise
The aligned BEV space lets the model judge each sensor's trustworthiness directly without needing heavy cross-modal attention, and the training schedule keeps no single modality from dominating the learned features.
What would settle it
Measure 3D object detection mAP on nuScenes under complete LiDAR dropout; if Grace-BEV stays at or near 0.0% while the paper reports 34.7%, the claim of graceful degradation via the router and fusion block is falsified.
Figures


read the original abstract
Despite the remarkable success of multi-modal bird's-eye view (BEV) perception in autonomous driving, current systems exhibit a critical vulnerability: existing fusion mechanisms are highly brittle to sensor corruptions, often causing catastrophic performance degradation. This vulnerability largely stems from the fact that standard fusion frameworks typically integrate multi-modal representations in a static manner, leading to a precipitous performance collapse under missing or corrupted modalities. In contrast, we show that graceful degradation is achievable through active modality reliability assessment. To this end, we present Grace-BEV, a lightweight and plug-and-play framework that enforces active reliability awareness during multi-modal fusion. Instead of relying on computationally expensive cross-modal interactions, Grace-BEV leverages the aligned BEV space to explicitly assess modality trustworthiness via a TrustGate Router and dynamically recalibrate feature integration using the FailSafe Fusion Block. Furthermore, we devise a Three-Phase Training strategy with Modality Dropout to prevent modality dominance and encourage balanced cross-modal learning under unreliable inputs. Extensive experiments on nuScenes-R and nuScenes-C show that Grace-BEV maintains robust performance across diverse corruption settings. Notably, under catastrophic LiDAR failures where standard baselines collapse to 0.0% mean Average Precision (mAP), Grace-BEV restores performance to as high as 34.7% mAP. Moreover, it improves clean accuracy by up to 1.4%, achieving a strong trade-off between robustness and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Grace-BEV, a lightweight plug-and-play framework for multi-modal bird's-eye-view (BEV) perception. It addresses brittleness of static fusion under sensor corruptions via a TrustGate Router that assesses modality trustworthiness in aligned BEV space, a FailSafe Fusion Block for dynamic recalibration, and a Three-Phase Training strategy incorporating Modality Dropout to avoid dominance. Experiments on nuScenes-R and nuScenes-C report recovery to 34.7% mAP under catastrophic LiDAR failure (versus 0.0% for baselines) and up to 1.4% gains on clean data.
Significance. If the reported metrics hold under the stated controls, the work is significant for safety-critical autonomous driving perception by demonstrating a concrete mechanism for graceful degradation. The plug-and-play design, avoidance of expensive cross-modal interactions, and explicit quantitative recovery under extreme failure (with accompanying clean-data improvement) constitute falsifiable, testable claims that strengthen the contribution.
minor comments (2)
- [Abstract] Abstract: the claim of 'extensive experiments' and the 1.4% clean-accuracy gain would benefit from explicit mention of the number of corruption settings tested, the precise baselines compared, and whether the improvement is statistically significant (e.g., over multiple seeds).
- The description of the Three-Phase Training strategy would be clearer if the exact loss weighting or dropout schedule were stated in a single location rather than distributed across sections.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work on Grace-BEV and the recommendation for minor revision. The assessment correctly identifies the core contribution regarding graceful degradation under sensor failures. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper presents Grace-BEV as a novel plug-and-play framework relying on the TrustGate Router in aligned BEV space, FailSafe Fusion Block, and Three-Phase Training with Modality Dropout. These are introduced as independent design choices, with performance claims (e.g., 34.7% mAP recovery under LiDAR failure) grounded in empirical results on nuScenes-R and nuScenes-C rather than any derivation that reduces to fitted parameters, self-definitions, or self-citation chains. No equations or load-bearing steps equate outputs to inputs by construction; the method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cardoso, Avelino Forechi, Luan Jesus, Rodrigo Berriel, Thiago M
Claudine Badue, Rânik Guidolini, Raphael Vivacqua Carneiro, Pedro Azevedo, Vinicius B. Cardoso, Avelino Forechi, Luan Jesus, Rodrigo Berriel, Thiago M. Paixão, Filipe Mutz, Lucas de Paula Veronese, Thiago Oliveira-Santos, and Al- berto F. De Souza. 2021. Self-driving cars: A survey.Expert Systems with Appli- cations165 (2021), 113816
2021
-
[2]
Xuyang Bai, Zeyu Hu, Xinge Zhu, Qingqiu Huang, Yilun Chen, Hongbo Fu, and Chiew-Lan Tai. 2022. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. InCVPR. 1090–1099
2022
-
[3]
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. 2020. Nuscenes: A multimodal dataset for autonomous driving. InCVPR. 11621–11631
2020
-
[4]
Qi Cai, Yingwei Pan, Ting Yao, Chong-Wah Ngo, and Tao Mei. 2023. ObjectFusion: Multi-modal 3D Object Detection with Object-Centric Fusion. InICCV. 18067– 18076
2023
- [5]
-
[6]
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. 2024. End-to-End Autonomous Driving: Challenges and Frontiers. IEEE TPAMI46, 12 (2024), 10164–10183
2024
-
[7]
Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. 2017. Multi-view 3d object detection network for autonomous driving. InCVPR
2017
-
[8]
Yilun Chen, Zhiding Yu, Yukang Chen, Shiyi Lan, Animashree Anandkumar, Jiaya Jia, and Jose Alvarez. 2023. FocalFormer3D: Focusing on Hard Instance for 3D Object Detection. InICCV. 8360–8371
2023
- [9]
-
[10]
Yinpeng Dong, Caixin Kang, Jinlai Zhang, Zijian Zhu, Yikai Wang, Xiao Yang, Hang Su, Xingxing Wei, and Jun Zhu. 2023. Benchmarking robustness of 3d object detection to common corruptions. InIEEE TPAMI. 1022–1032
2023
-
[11]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
2022
-
[12]
Chongjian Ge, Junsong Chen, Enze Xie, Zhongdao Wang, Lanqing Hong, Huchuan Lu, Zhenguo Li, and Ping Luo. 2023. Metabev: Solving sensor failures for 3d detection and map segmentation. InICCV. 8721–8731
2023
-
[13]
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, and Hongyang Li. 2023. Planning-oriented Autonomous Driving. InCVPR. 17853–17862
2023
-
[14]
Lingdong Kong, Youquan Liu, Xin Li, Runnan Chen, Wenwei Zhang, Jiawei Ren, Liang Pan, Kai Chen, and Ziwei Liu. 2023. Robo3d: Towards robust and reliable 3d perception against corruptions. InProceedings of the IEEE/CVF International Conference on Computer Vision. 19994–20006
2023
-
[15]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Simple and scalable predictive uncertainty estimation using deep ensembles.NeurIPS 30 (2017)
2017
-
[16]
Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. 2019. Pointpillars: Fast encoders for object detection from point clouds. InCVPR. 12697–12705
2019
-
[17]
Xin Li, Tao Ma, Yuenan Hou, Botian Shi, Yuchen Yang, Youquan Liu, Xingjiao Wu, Qin Chen, Yikang Li, Yu Qiao, et al. 2023. Logonet: Towards accurate 3d object detection with local-to-global cross-modal fusion. InCVPR. 17524–17534
2023
-
[18]
Yinhao Li, Han Bao, Zheng Ge, Jinrong Yang, Jianjian Sun, and Zeming Li. 2023. Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 1486–1494
2023
-
[19]
Yanwei Li, Yilun Chen, Xiaojuan Qi, Zeming Li, Jian Sun, and Jiaya Jia. 2022. Unifying voxel-based representation with transformer for 3d object detection. In NeurIPS. 18442–18455
2022
-
[20]
Yingyan Li, Lue Fan, Yang Liu, Zehao Huang, Yuntao Chen, Naiyan Wang, and Zhaoxiang Zhang. 2024. Fully sparse fusion for 3d object detection.IEEE TPAMI 46, 11 (2024), 7217–7231
2024
-
[21]
Yinhao Li, Zheng Ge, Guanyi Yu, Jinrong Yang, Zengran Wang, Yukang Shi, Jianjian Sun, and Zeming Li. 2023. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. InAAAI. 1477–1485
2023
-
[22]
Yingwei Li, Adams Wei Yu, Tianjian Meng, Ben Caine, Jiquan Ngiam, Daiyi Peng, Junyang Shen, Yifeng Lu, Denny Zhou, Quoc V Le, et al. 2022. Deepfusion: Lidar- camera deep fusion for multi-modal 3d object detection. InCVPR. 17182–17191
2022
-
[23]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. 2025. BEVFormer: Learning Bird’s-Eye-View Representation From LiDAR-Camera via Spatiotemporal Transformers.IEEE TPAMI47, 3 (2025), 2020–2036
2025
-
[24]
Tingting Liang, Hongwei Xie, Kaicheng Yu, Zhongyu Xia, Zhiwei Lin, Yongtao Wang, Tao Tang, Bing Wang, and Zhi Tang. 2022. Bevfusion: A simple and robust lidar-camera fusion framework. InNeurIPS. 10421–10434
2022
-
[25]
Hezheng Lin, Xing Cheng, Xiangyu Wu, and Dong Shen. 2022. Cat: Cross attention in vision transformer. InICME. 1–6
2022
-
[26]
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2017. Focal Loss for Dense Object Detection. InICCV. 2999–3007
2017
- [27]
-
[28]
Yingfei Liu, Tiancai Wang, Xiangyu Zhang, and Jian Sun. 2022. Petr: Position embedding transformation for multi-view 3d object detection. InECCV. 531–548
2022
-
[29]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. InICCV. 10012–10022
2021
-
[30]
Zhijian Liu, Haotian Tang, Alexander Amini, Xingyu Yang, Huizi Mao, Daniela Rus, and Song Han. 2023. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. InICRA. 2774–2781
2023
-
[31]
Konyul Park, Yecheol Kim, Daehun Kim, and Jun Won Choi. 2025. Resilient Sensor Fusion under Adverse Sensor Failures via Multi-Modal Expert Fusion. In CVPR. 6720–6729
2025
-
[32]
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. 2022. Balanced multimodal learning via on-the-fly gradient modulation. InCVPR. 8238–8247
2022
-
[33]
Jonah Philion and Sanja Fidler. 2020. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. InECCV. 194–210
2020
-
[34]
Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, and Neil Houlsby. 2021. Scaling vision with sparse mixture of experts.NeurIPS34 (2021), 8583–8595
2021
-
[35]
Murat Sensoy, Lance Kaplan, and Melih Kandemir. 2018. Evidential deep learning to quantify classification uncertainty.NeurIPS31 (2018)
2018
-
[36]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Ziying Song, Lei Yang, Shaoqing Xu, Lin Liu, Dongyang Xu, Caiyan Jia, Feiyang Jia, and Li Wang. 2024. Graphbev: Towards robust bev feature alignment for multi-modal 3d object detection. InECCV. 347–366
2024
-
[38]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InNeurIPS. 5998–6008
2017
-
[39]
Sourabh Vora, Alex H Lang, Bassam Helou, and Oscar Beijbom. 2020. Pointpaint- ing: Sequential fusion for 3d object detection. InCVPR. 4604–4612
2020
-
[40]
Chunwei Wang, Chao Ma, Ming Zhu, and Xiaokang Yang. 2021. Pointaugmenting: Cross-modal augmentation for 3d object detection. InCVPR
2021
-
[41]
Haiyang Wang, Hao Tang, Shaoshuai Shi, Aoxue Li, Zhenguo Li, Bernt Schiele, and Liwei Wang. 2023. Unitr: A unified and efficient multi-modal transformer for bird’s-eye-view representation. InICCV. 6792–6802
2023
-
[42]
Haoyu Wang, Zhiqiang Zuo, Yijing Wang, Hongjiu Yang, and Chuan Hu. 2023. Longitudinal Velocity Regulation of UGVs: A Composite Control Approach for Acceleration and Deceleration.IEEE Transactions on Intelligent Transportation Systems24, 10 (2023), 11096–11106
2023
-
[43]
Shiming Wang, Holger Caesar, Liangliang Nan, and Julian FP Kooij. 2024. Unibev: Multi-modal 3d object detection with uniform bev encoders for robustness against missing sensor modalities. In2024 IEEE Intelligent Vehicles Symposium. 2776–2783
2024
-
[44]
Wenjie Wang, Yehao Lu, Guangcong Zheng, Shuigen Zhan, Xiaoqing Ye, Zichang Tan, Jingdong Wang, Gaoang Wang, and Xi Li. 2024. BEVSpread: Spread Voxel Pooling for Bird’s-Eye-View Representation in Vision-Based Roadside 3D Object Detection. InCVPR. 14718–14727
2024
-
[45]
Yue Wang, Vitor Campagnolo Guizilini, Tianyuan Zhang, Yilun Wang, Hang Zhao, and Justin Solomon. 2022. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. InConference on robot learning. 180–191
2022
-
[46]
Nan Wu, Stanislaw Jastrzebski, Kyunghyun Cho, and Krzysztof J Geras. 2022. Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks. InICML. 24043–24055
2022
-
[47]
Yichen Xie, Chenfeng Xu, Marie-Julie Rakotosaona, Patrick Rim, Federico Tombari, Kurt Keutzer, Masayoshi Tomizuka, and Wei Zhan. 2023. SparseFu- sion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection. InICCV. 17545–17556
2023
-
[48]
Junjie Yan, Yingfei Liu, Jianjian Sun, Fan Jia, Shuailin Li, Tiancai Wang, and Xiangyu Zhang. 2023. Cross Modal Transformer: Towards Fast and Robust 3D Object Detection. InICCV. 18222–18232
2023
-
[49]
Yan Yan, Yuxing Mao, and Bo Li. 2018. Second: Sparsely embedded convolutional detection.Sensors18, 10 (2018), 3337. 9 Zhang et al., Haifa Zhang, Yijing Wang, Haoyu Wang, Zheng Li, and Zhiqiang Zuo
2018
-
[50]
Zeyu Yang, Jiaqi Chen, Zhenwei Miao, Wei Li, Xiatian Zhu, and Li Zhang. 2022. Deepinteraction: 3d object detection via modality interaction. InNeurIPS
2022
-
[51]
Zeyu Yang, Nan Song, Wei Li, Xiatian Zhu, Li Zhang, and Philip H.S. Torr. 2025. DeepInteraction++: Multi-Modality Interaction for Autonomous Driving.IEEE TPAMI47, 8 (2025), 6749–6763
2025
-
[52]
Tianwei Yin, Xingyi Zhou, and Philipp Krahenbuhl. 2021. Center-based 3d object detection and tracking. InCVPR
2021
-
[53]
Kaicheng Yu, Tang Tao, Hongwei Xie, Zhiwei Lin, Tingting Liang, Bing Wang, Peng Chen, Dayang Hao, Yongtao Wang, and Xiaodan Liang. 2023. Benchmarking the robustness of lidar-camera fusion for 3d object detection. InCVPRW. 3188– 3198
2023
- [54]
-
[55]
Yin Zhou and Oncel Tuzel. 2018. Voxelnet: End-to-end learning for point cloud based 3d object detection. InCVPR. 4490–4499
2018
- [56]
-
[57]
Zhuofan Zong, Dongzhi Jiang, Guanglu Song, Zeyue Xue, Jingyong Su, Hong- sheng Li, and Yu Liu. 2023. Temporal Enhanced Training of Multi-view 3D Object Detector via Historical Object Prediction. InICCV. 3758–3767. 10
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.