Statistical Tapers for Correlation-Based Localization in Ensemble Data Assimilation
Pith reviewed 2026-06-29 06:07 UTC · model grok-4.3
The pith
Correlation-based tapers derived from model-data reliability can replace distance-based localization in ensemble data assimilation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
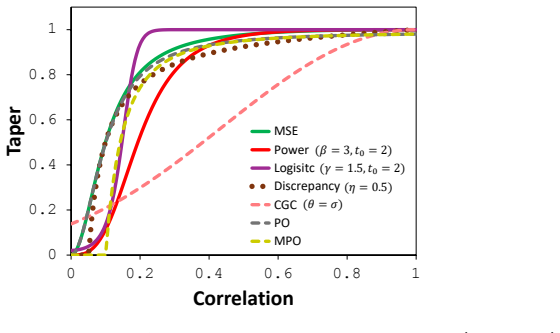
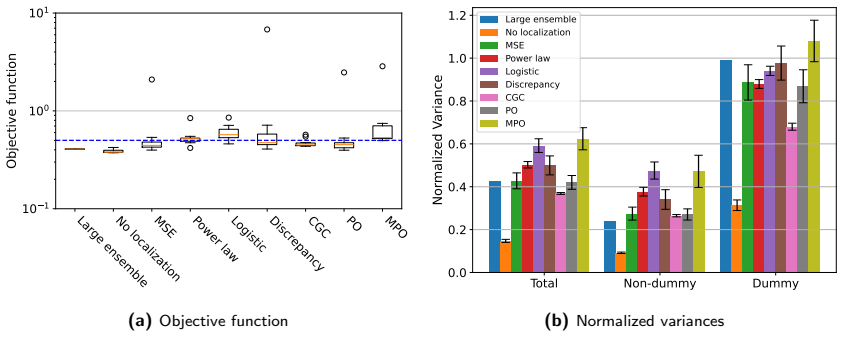
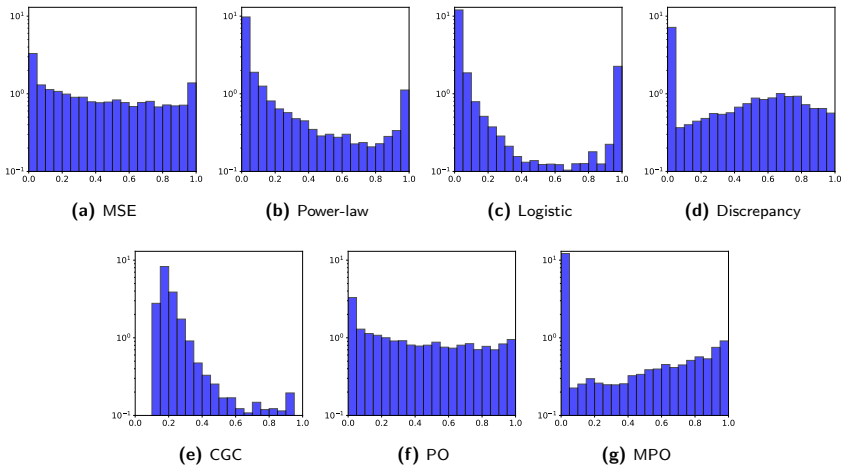
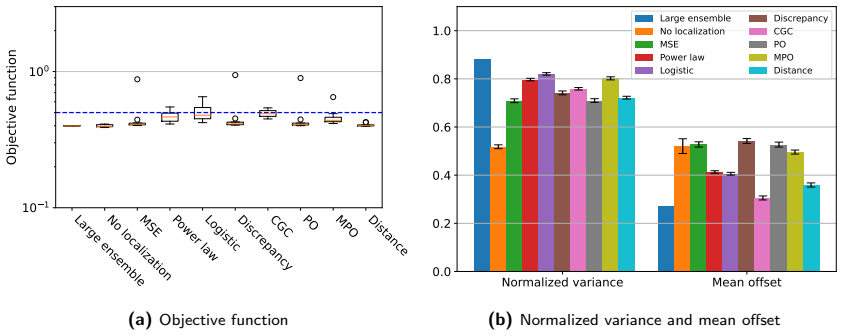
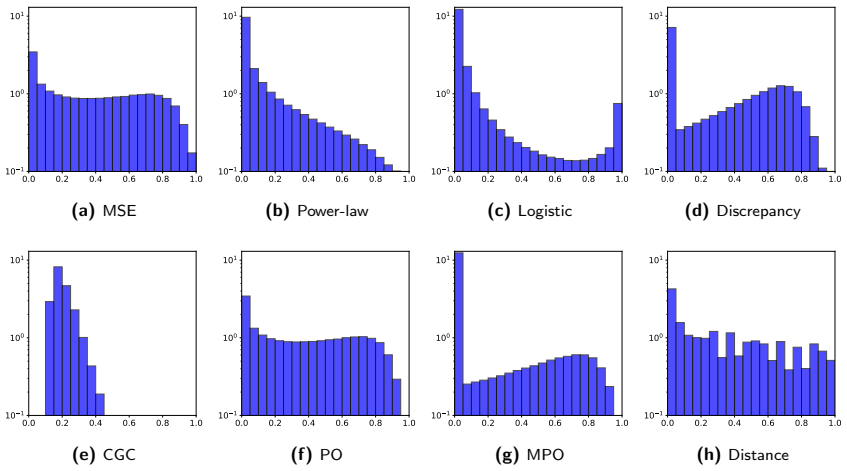
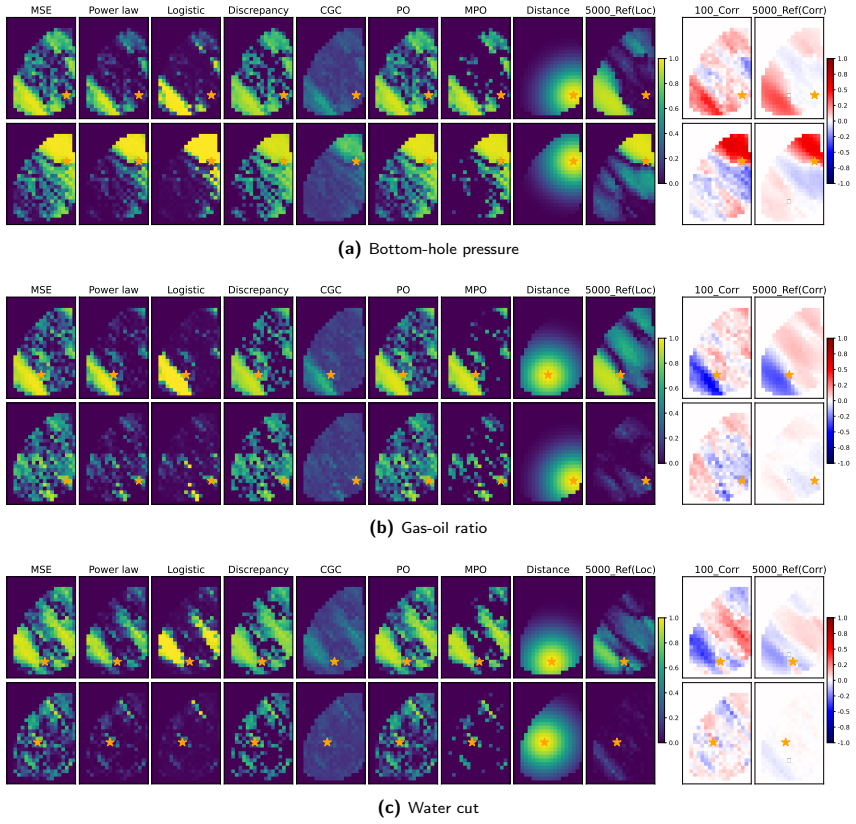
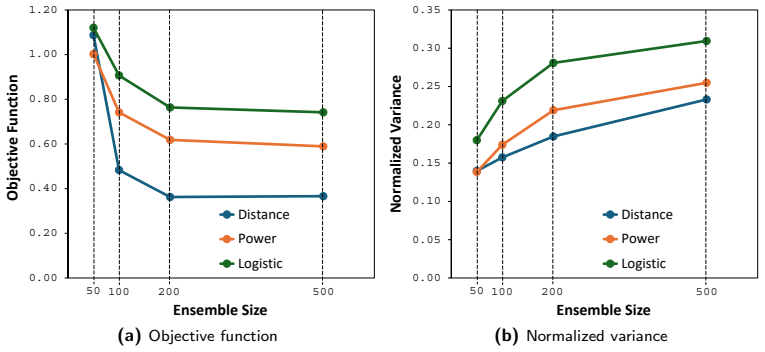
The central claim is that tapering coefficients computed from the statistical reliability of estimated model-data correlations suppress spurious correlations while preserving meaningful parameter-data relationships; in the synthetic tests the power-law and logistic tapers retained more posterior ensemble variance than distance-based localization while still achieving acceptable data-match quality, with the logistic taper giving the strongest variance preservation.
What carries the argument
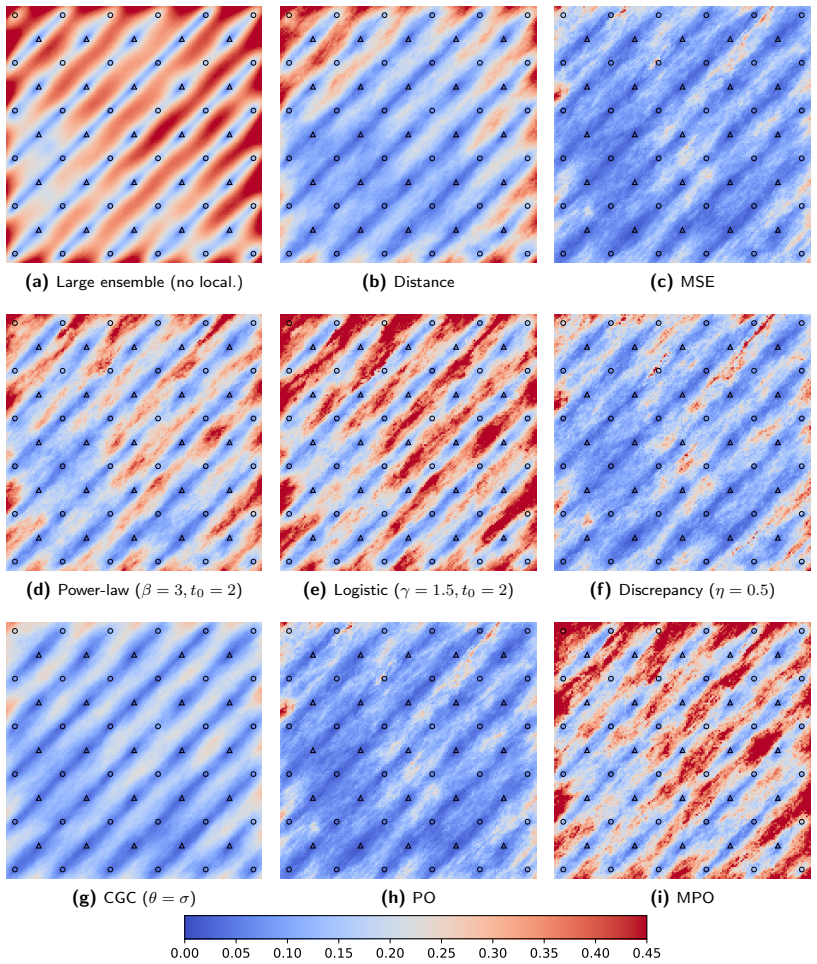
Three statistical tapers (generalized power-law motivated by mean-square-error correction, logistic derived from Bayesian spike-and-slab, and discrepancy-based inspired by Morozov's principle) that act as shrinkage operators on estimated correlations according to their reliability.
If this is right
- Correlation-based localization applies directly to cases where spatial distance does not align with parameter-data relationships, such as non-local parameters or prior conditioning effects.
- Power-law and logistic tapers can retain higher posterior ensemble variance than distance-based localization while keeping data-match quality acceptable.
- The logistic taper favors variance preservation; smoother tapers favor data-match quality.
- The approach works for both scalar parameters and grid-based parameters with non-trivial correlation patterns.
Where Pith is reading between the lines
- The reliability-based shrinkage could be tested in ensemble methods outside reservoir applications, such as atmospheric or ocean data assimilation where correlations are strongly flow-dependent.
- Hybrid schemes that blend correlation reliability with distance when both are available might reduce sensitivity to the choice of taper.
- Because the tapers are derived from ensemble statistics, they could adapt automatically across assimilation cycles without manual retuning.
Load-bearing premise
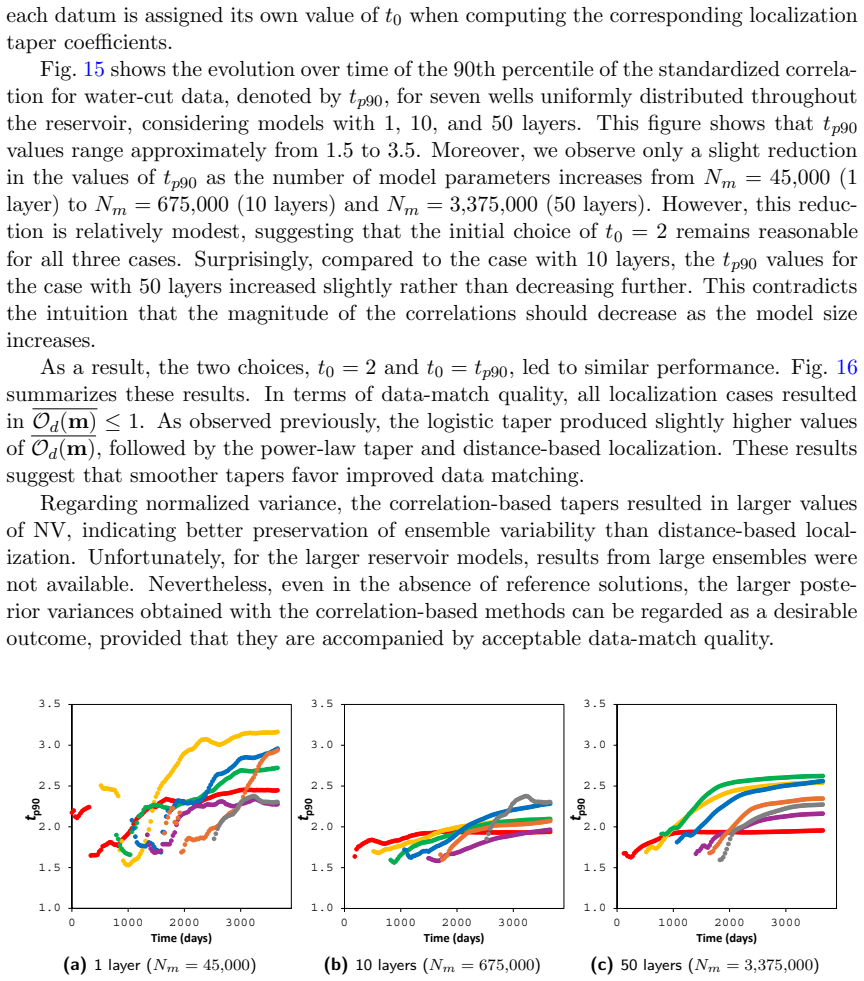
That the statistical reliability of estimated correlations will consistently separate spurious from meaningful relationships across the range of tested synthetic problems without additional case-specific tuning.
What would settle it
A controlled synthetic experiment in which the reliability metric either fails to taper known spurious correlations or over-tapers known meaningful ones, producing visibly worse posterior variance or data match than distance-based localization.
Figures




read the original abstract
Localization is essential in ensemble-based data assimilation because finite ensembles produce noisy covariance estimates, causing spurious updates and excessive loss of ensemble variance. In subsurface applications, localization is usually based on spatial distance, but this criterion can be hard to justify when parameter-data relationships are controlled by flow dynamics, nonlinear operators, non-local parameters, or prior conditioning effects. This work investigates correlation-based localization as an alternative strategy in which tapering coefficients are computed from the statistical reliability of estimated model-data correlations. We interpret localization as a shrinkage problem in correlation space and propose three tapers: a generalized power-law taper motivated by mean-square-error correction, a logistic taper derived from a Bayesian spike-and-slab formulation, and a discrepancy-based taper inspired by Morozov's principle. The tapers are evaluated using synthetic reservoir data assimilation problems involving scalar and grid-based parameters, localized flow responses, non-trivial correlation patterns, and increasing model dimension. The results show that correlation-based localization can suppress spurious correlations while preserving meaningful parameter-data relationships. In several cases, the proposed power-law and logistic tapers retained more posterior ensemble variance than distance-based localization while maintaining acceptable data-match quality. The logistic taper provided the strongest variance preservation, whereas smoother tapers favored better data matches. Overall, the results indicate that correlation-based localization is a statistically motivated alternative to distance-based localization, especially when spatial distance is unavailable or misleading.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes three correlation-based tapers (generalized power-law motivated by MSE correction, logistic from Bayesian spike-and-slab, and discrepancy-based inspired by Morozov's principle) for localization in ensemble data assimilation. Tapering coefficients are derived from the statistical reliability of estimated model-data correlations rather than spatial distance. The tapers are evaluated on synthetic reservoir problems involving scalar/grid parameters and varying correlation patterns, with the claim that the power-law and logistic tapers can suppress spurious correlations while retaining more posterior ensemble variance than distance-based localization, and that the logistic taper provides the strongest variance preservation.
Significance. If the central claims hold after addressing verification gaps, the work supplies a statistically motivated alternative to distance-based localization for subsurface DA applications where spatial distance is a poor proxy due to flow dynamics or non-local effects. The focus on ensemble variance preservation is relevant for uncertainty quantification. The absence of quantitative benchmarks and independent validation of the reliability measure, however, limits the strength of the current evidence.
major comments (3)
- The tapering coefficients rely on reliability estimates (p-values, bootstrap, etc.) computed from the same finite ensemble used to obtain the raw correlations. Because sampling noise that produces spurious correlations will also affect the reliability scores, the separation of spurious from meaningful correlations is not guaranteed to be informative when the true correlation structure is unknown.
- The abstract and evaluation sections provide no error bars, exact quantitative comparisons between tapers and distance-based baselines, or details on data exclusion. This prevents verification of the claim that the proposed tapers retained more posterior ensemble variance while maintaining acceptable data-match quality.
- The synthetic tests are constructed with known ground-truth correlation structures. This setup permits implicit selection of regimes where the reliability measure succeeds and does not test performance when the true correlation pattern must be discovered without external knowledge.
minor comments (2)
- Define the precise functional forms, hyperparameters, and implementation details of the three tapers (including how the reliability measure is converted to a taper coefficient) to enable reproducibility.
- Report the ensemble sizes used for correlation estimation and localization, and discuss their relation to the reliability estimation procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: The tapering coefficients rely on reliability estimates (p-values, bootstrap, etc.) computed from the same finite ensemble used to obtain the raw correlations. Because sampling noise that produces spurious correlations will also affect the reliability scores, the separation of spurious from meaningful correlations is not guaranteed to be informative when the true correlation structure is unknown.
Authors: We agree that reliability estimates are subject to the same sampling noise as the correlations themselves, so the separation cannot be guaranteed to be fully informative in all regimes. The tapers are nevertheless constructed as shrinkage operators that downweight low-reliability estimates, and the synthetic results show empirical gains over distance-based localization. We will add a limitations paragraph in the methods section acknowledging this dependence on ensemble-derived statistics. revision: partial
-
Referee: The abstract and evaluation sections provide no error bars, exact quantitative comparisons between tapers and distance-based baselines, or details on data exclusion. This prevents verification of the claim that the proposed tapers retained more posterior ensemble variance while maintaining acceptable data-match quality.
Authors: The referee is correct; the current manuscript lacks error bars, precise numerical comparisons, and explicit data-exclusion details. We will revise the abstract and results sections to report error bars from repeated ensemble realizations, exact variance and data-mismatch values, and clarify any data handling steps. revision: yes
-
Referee: The synthetic tests are constructed with known ground-truth correlation structures. This setup permits implicit selection of regimes where the reliability measure succeeds and does not test performance when the true correlation pattern must be discovered without external knowledge.
Authors: The experiments use known ground truth only for post-hoc evaluation; the tapers themselves are computed exclusively from the ensemble without access to the true correlations. The test suite already includes multiple correlation patterns (localized flow, non-local effects) to probe robustness. We will expand the discussion to emphasize applicability when no ground truth is available. revision: partial
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper derives tapers from independent statistical principles (MSE correction, Bayesian spike-and-slab, Morozov's discrepancy) and evaluates them on separate synthetic test cases. No equations reduce to their own inputs by construction, no load-bearing self-citations, and no fitted parameters renamed as predictions. Reliability estimates from the ensemble are a methodological input rather than a tautological reduction of the claimed results. This is the common honest outcome for a methods paper with external motivation and independent validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Finite ensembles produce noisy covariance estimates causing spurious updates and excessive loss of ensemble variance.
Reference graph
Works this paper leans on
-
[1]
DOI: 10.2118/117274-PA. Anderson, J. L. Exploring the need for localization in ensemble data assimilation using a hierarchical ensemble filter.Physica D: Nonlinear Phenomena, 230(1–2):99–111,
-
[2]
DOI: 10.1016/j.physd.2006.02.011. Anderson, J. L. Localization and sampling error correction in ensemble Kalman filter data assim- ilation.Monthly Weather Review, 140:2359–2371,
-
[3]
DOI: 10.1175/MWR-D-11-00013.1. Bishop, C. H. and Hodyss, D. Flow-adaptive moderation of spurious ensemble correlations and its use in ensemble-based data assimilation.Quarterly Journal of the Royal Meteorological Society, 133(629):2029–2044,
-
[4]
DOI: 10.1002/qj.169. Chen, Y. and Oliver, D. S. Cross-covariance and localization for EnKF in multiphase flow data assimilation.Computational Geosciences, 14(4):579–601,
-
[5]
DOI: 10.1007/s10596-009-9174-6. Deutsch, C. V.Geostatistical reservoir modeling. Oxford University Press,
-
[6]
DOI: 10.1007/s10596-010-9198-y. Emerick, A. A. and Reynolds, A. C. Ensemble smoother with multiple data assimilation.Computers & Geosciences, 55:3–15,
-
[7]
DOI: 10.1016/j.cageo.2012.03.011. Evensen, G., Raanes, P. N., Stordal, A. S., and Hove, J. Efficient implementation of an iterative ensemble smoother for data assimilation and reservoir history matching.Frontiers in Applied Mathematics and Statistics, 3,
-
[8]
DOI: 10.3389/fams.2019.00047. Evensen, G., Oliver, D. S., and Hanea, R. G.Ensemble History Matching: Conditioning Reservoir Models on Dynamic Data. Springer Cham,
-
[9]
A Piecewise Rotation of the Circle, IPR Maps and Their Connection with Translation Surfaces
ISBN 978-3-031-99157-8. DOI: 10.1007/978- 3-031-99155-4. Fisher, R. A. On the probable error of a coefficient of correlation deduced from a small sample. Metron, 1,
-
[10]
DOI: 10.1144/petgeo.7.S.S87. Flowerdew, J. Towards a theory of optimal localisation.Tellus A: Dynamic Meteorology and Oceanography, 67(1),
-
[11]
DOI: 10.3402/tellusa.v67.25257. Furrer, R. and Bengtsson, T. Estimation of high-dimensional prior and posterior covariance matrices in Kalman filter variants.Journal of Multivariate Analysis, 98(2):227–255,
-
[12]
DOI: 10.1016/j.jmva.2006.08.003. Gaspari, G. and Cohn, S. E. Construction of correlation functions in two and three di- mensions.Quarterly Journal of the Royal Meteorological Society, 125(554):723–757,
-
[13]
DOI: 10.1002/qj.49712555417. Gnambs, T. A brief note on the standard error of the pearson correlation.Collabra: Psychology, 9(1),
-
[14]
DOI: 10.1525/collabra.87615. Houtekamer, P. L. and Mitchell, H. L. A sequential ensemble Kalman filter for atmospheric data assimilation.Monthly Weather Review, 129(1):123–137,
-
[16]
DOI: 10.1016/j.petrol.2018.08.056. Lacerda, J. M., Emerick, A. A., and Pires, A. P. Using a machine learning proxy for localization in ensemble data assimilation.Computational Geosciences, 25:931–944,
-
[17]
DOI: 10.1007/s10596- 020-10031-0. Lee, Y. Sampling error correction in ensemble kalman inversion.arXiv:2105.11341,
-
[18]
DOI: 10.48550/arXiv.2105.11341. Lorenc, A. C. The potential of the ensemble Kalman filter for NWP—a comparison with 4D-Var.Quarterly Journal of the Royal Meteorological Society, 129(595):3183–3203,
-
[19]
DOI: 10.1256/qj.02.132. Luo, X. and Bhakta, T. Automatic and adaptive localization for ensemble-based history matching. Journal of Petroleum Science and Engineering, 184,
-
[20]
Luo, X., Bhakta, T., and Nævdal, G
DOI: 10.1016/j.petrol.2019.106559. Luo, X., Bhakta, T., and Nævdal, G. Correlation-based adaptive localization with applica- tions to ensemble-based 4D-seismic history matching.SPE Journal, 23(2):396–427,
-
[21]
M´ en´ etrier, B., Montmerle, T., Michel, Y., and Berre, L
DOI: 10.2118/185936-PA. M´ en´ etrier, B., Montmerle, T., Michel, Y., and Berre, L. Linear filtering of sample covariances for ensemble-based data assimilation. part i: Optimality criteria and application to variance filtering and covariance localization.Monthly Weather Review, 143(5),
-
[22]
DOI: 10.1175/MWR-D-14- 00157.1. Mitchell, T. J. and Beauchamp, J. J. Bayesian variable selection in linear regression.Journal of the American Statistical Association, 83(404),
-
[23]
Morozov, V.Methods for Solving Incorrectly Posed Problems
DOI: 10.2307/2290129. Morozov, V.Methods for Solving Incorrectly Posed Problems. Springer-Verlag New York,
-
[24]
DOI: 10.1007/978-1-4612-5280-1. O’Hara, R. B. and Sillanpaa, M. J. A review of Bayesian variable selection methods: what, how and which.Bayesian Analysis, 4(1),
-
[25]
DOI: 10.1214/09-BA403. Oliver, D. S. and Alfonzo, M. Calibration of imperfect models to biased observations.Computa- tional Geosciences, 22:145–161,
-
[26]
DOI: 10.1007/s10596-017-9678-4. 33 Oliver, D. S., Reynolds, A. C., and Liu, N.Inverse Theory for Petroleum Reservoir Charac- terization and History Matching. Cambridge University Press, Cambridge, UK,
-
[27]
ISBN 978-0511535642. DOI: 10.1017/CBO9780511535642. Raanes, P. N., Stordal, A. S., and Evensen, G. Revising the stochastic iterative ensemble smoother. Nonlinear Processes in Geophysics, 26(3),
-
[28]
DOI: 10.5194/npg-2019-10. Ranazzi, P. H., Luo, X., and Sampaio, M. A. Improving pseudo-optimal Kalman-gain localization using the random shuffle method.Journal of Petroleum Science and Engineering, 215,
-
[29]
DOI: 10.1016/j.petrol.2022.110589. Ranazzi, P. H., Luo, X., and Sampaio, M. A. Covariance scaling: Theory, extension, and ap- plications to ensemble-based history matching.Computational Geosciences, on line,
-
[30]
DOI: 10.1007/s10596-026-10413-w. Rice, J. A.Mathematical Statistics and Data Analysis. Thomson Brooks/Cole, third edition,
-
[31]
DOI: 10.1007/s10596-010-9202-6. Sakov, P. and Oke, P. R. Implications of the form of the ensemble transformation in the ensemble square root filters.Monthly Weather Review, 136:1042–1053,
-
[32]
DOI: 10.1175/2007MWR2021.1. Silva, V. L. S., Seabra, G. S., and Emerick, A. A. Machine learning to enhance the covariance esti- mations of non-local model parameters in ensemble based-data assimilation. InProceedings of the SPE Reservoir Simulation Conference, number SPE-223908-MS, 2025a. DOI: 10.2118/223908- MS. Silva, V. L. S., Seabra, G. S., and Emeric...
-
[33]
DOI: 10.2307/2331802. Tippett, M. K., Anderson, J. L., Bishop, C. H., Hamill, T. M., and Whitaker, J. S. Ensem- ble square-root filters.Monthly Weather Review, 131:1485–1490,
-
[34]
Vishny, D., Morzfeld, M., Gwirtz, K., Bach, E., Dunbar, O
DOI: 10.1175/1520- 0493(2003)131<1485:ESRF>2.0.CO;2. Vishny, D., Morzfeld, M., Gwirtz, K., Bach, E., Dunbar, O. R. A., and Hodyss, D. High-dimensional covariance estimation from a small number of samples.Journal of Advances in Modeling Earth Systems, 16(9),
-
[35]
DOI: 10.1029/2024MS004417. Vossepoel, F. C., Evensen, G., and van Leeuwen, P. J. Adaptive correlation- and distance-based localization for iterative ensemble smoothers in a coupled nonlinear multiscale model.Monthly Weather Review, 153(11),
-
[36]
DOI: 10.1175/MWR-D-24-0269.1. Zhang, Y. and Oliver, D. S. Improving the ensemble estimate of the Kalman gain by bootstrap sampling.Mathematical Geosciences, 42:327–345,
-
[37]
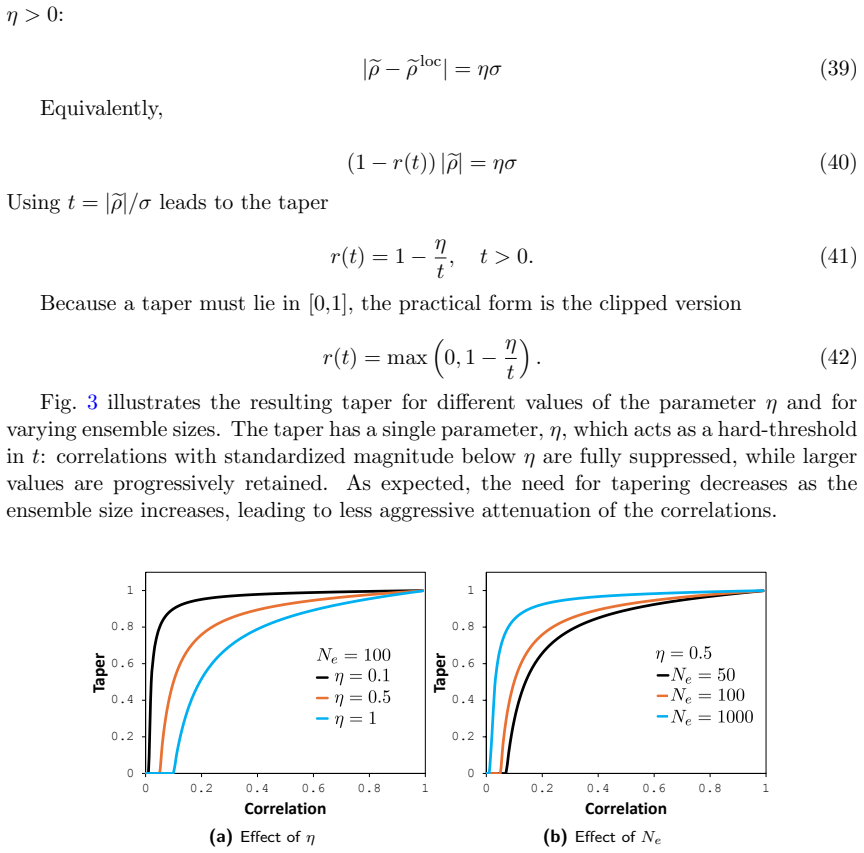
A Appendix A.1 Derivation of the MSE taper To derive Eq
DOI: 10.1007/s11004-010-9267-8. A Appendix A.1 Derivation of the MSE taper To derive Eq. 7, we start from the MSE 34 J(r) =E (reρ−ρ)2 (50) =E r2eρ2 −2reρρ+ρ 2 =r 2E eρ2 −2rE[eρ]ρ+ρ
-
[38]
spike”) or drawn from a continuous distribution allowing nonzero values (the “slab
Then, we compute the derivative with respect torand set to zero, which leads to r⋆ = ρE[eρ] E[eρ2] .(51) Assumingeρis approximately unbiased for moderate ensemble sizes,E[eρ]≈ρ, the optimal taper can be written as r⋆ = ρ2 ρ2 + var[eρ]= ρ2 ρ2 +σ 2 .(52) A.2 Spike-and-Slab Distribution The spike-and-slab distribution is a mixture distribution commonly used ...
1988
-
[39]
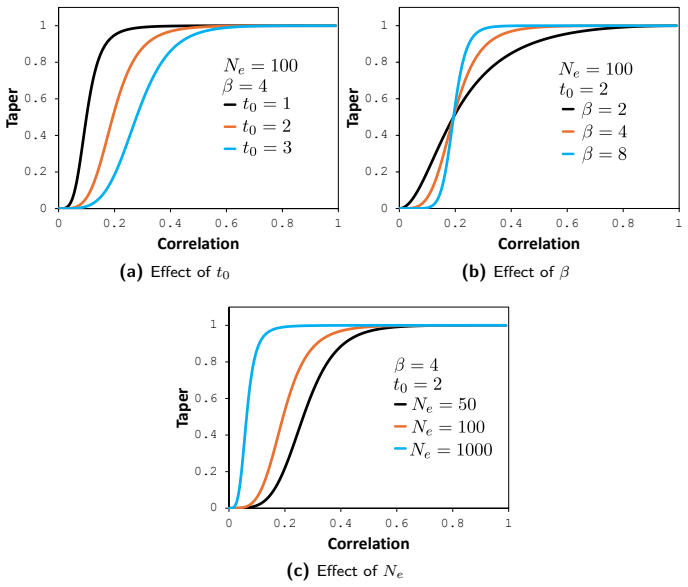
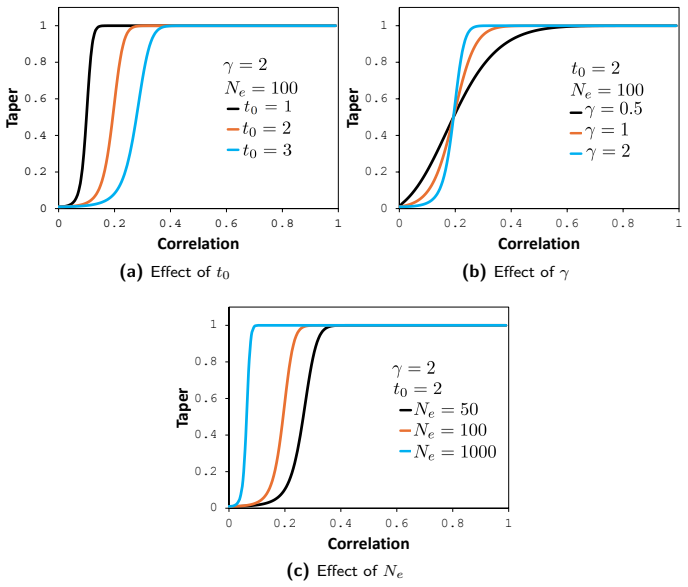
Generalized logistic taper Alternatively, assume that the log-Bayes factor grows proportionally to a power oft: ln (BF(t)) =c(t γ −t γ 0),(107) whereγ >0,c >0, andt 0 >0
The generalization toβ̸= 2 therefore corresponds to assuming that the evidence in favor of inclusion grows as a powert β. Generalized logistic taper Alternatively, assume that the log-Bayes factor grows proportionally to a power oft: ln (BF(t)) =c(t γ −t γ 0),(107) whereγ >0,c >0, andt 0 >0. Exponentiating 107 gives BF(t) = exp(c(t γ −t γ 0)).(108) Substi...
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.