Set-Supervised Diffusion Policy: Learning Action-Chunking Diffusion through Corrections
Pith reviewed 2026-06-28 14:23 UTC · model grok-4.3
The pith
Set-Supervised Diffusion Policy trains diffusion policies to align with sets of desired action chunks derived from paired human corrections and undesired actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
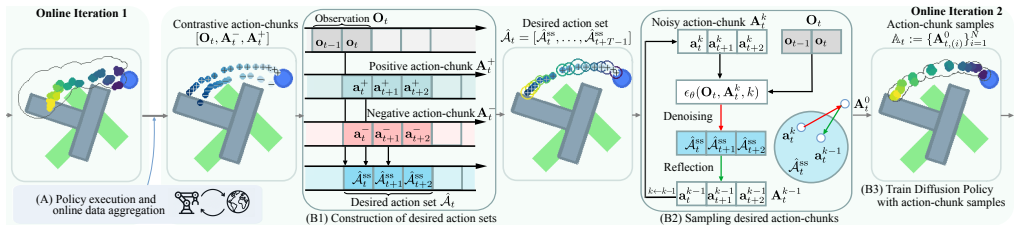
From paired positive corrective and negative undesired action chunks, SDP constructs a set of desired action chunks and replaces the usual behavior-cloning objective with a training pipeline that pushes the diffusion model to align its generated chunks with that set, producing policies that perform better and remain more robust when the collected data contains noise.
What carries the argument
The set of desired action chunks constructed from each contrastive correction pair, which supplies the alignment target for the diffusion denoising process.
If this is right
- Policy success rates rise across multiple robotic manipulation tasks when SDP replaces standard behavior cloning.
- Robustness gains are largest when the training corrections contain noise or distribution shift.
- The resulting aggregated datasets support more efficient subsequent policy learning from further human corrections.
- Reliance on purely expert demonstrations decreases because negative signals from undesired actions now contribute to training.
Where Pith is reading between the lines
- The same paired-correction construction could be applied to other action-chunking or sequence models beyond diffusion policies.
- Collecting corrections online during deployment might allow iterative dataset improvement without separate expert data collection phases.
- The approach may reduce the total number of human interventions needed to reach a target performance level in long-horizon tasks.
Load-bearing premise
The sets formed from paired corrections supply an alignment signal that improves the policy without introducing new overfitting or mode collapse.
What would settle it
A controlled comparison in which SDP policies trained on the same correction pairs achieve equal or lower success rates and equal or lower robustness under added noise than standard diffusion policies trained on the positive actions alone.
Figures










read the original abstract
Diffusion policies have recently emerged as a powerful framework for robotic manipulation. However, like other behavior cloning methods, they remain vulnerable to distributional shift, often requiring human-in-the-loop interventions to correct failures during deployment. These interactions naturally provide paired supervision in the form of the robot's undesired actions and the human teacher's corrective actions. Yet existing data aggregation pipelines and standard behavior cloning losses largely ignore this negative signal from undesired actions, leading to overfitting to teacher's actions and an increasing reliance on costly expert data. To address this limitation, we propose Set-Supervised Diffusion Policy (SDP), a novel learning framework that utilizes contrastive action-chunk data to train diffusion policies from human corrections. From paired positive and negative action-chunks, SDP constructs a set of desired action-chunks and designs a training pipeline that encourages the diffusion policy to align with the set. Through extensive experiments across multiple robotic manipulation tasks, we demonstrate that SDP consistently improves policy performance, with particularly strong gains in robustness to noisy data. Moreover, SDP induces high-quality aggregated datasets, enabling more efficient and reliable policy learning from human-in-the-loop corrections. Our code is available at https://set-supervised-diffusion-policy.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Set-Supervised Diffusion Policy (SDP), a framework that converts paired undesired robot actions and human corrective actions into a set of desired action chunks. It then trains a diffusion policy via a modified objective that encourages alignment to this set rather than a single expert mode. The central claims are that SDP yields consistent performance gains over standard diffusion policies on robotic manipulation tasks, with especially large robustness improvements under noisy data, and that the resulting aggregated datasets support more efficient subsequent policy learning.
Significance. If the construction and training pipeline are shown to be free of mode collapse or incidental augmentation effects, the approach would meaningfully extend behavior-cloning methods by exploiting negative signals from human corrections. The open release of code at the cited URL is a concrete strength that aids reproducibility.
major comments (2)
- [§3] §3 (SDP construction and objective): the manuscript supplies no explicit equations, pseudocode, or ablation for how the set of desired action chunks is formed from each paired (undesired, corrective) chunk (union, filtering, re-weighting, or other) nor how the diffusion denoising loss is altered to align to the set. This mechanism is load-bearing for the claim that the alignment signal improves robustness without introducing overfitting or mode collapse.
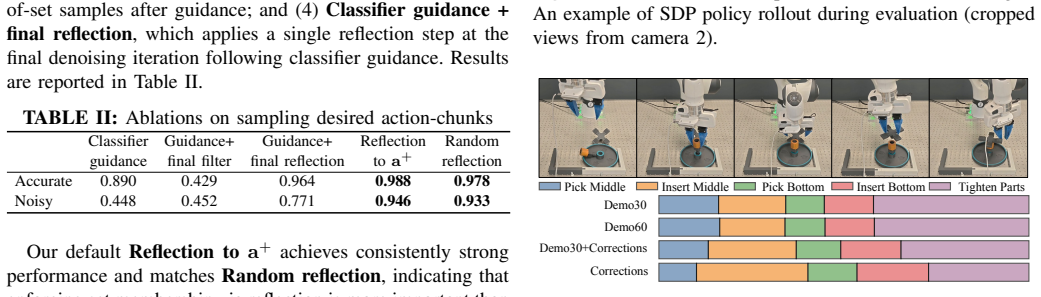
- [§4] §4 (experiments): the headline claim of 'particularly strong gains in robustness to noisy data' is not accompanied by reported dataset sizes, number of tasks, baseline implementations, or statistical tests in the visible sections; without these the performance advantage cannot be isolated from possible data-augmentation effects.
minor comments (1)
- [Abstract] Abstract: the sentence describing the training pipeline is high-level; a single additional clause indicating the form of the set or the contrastive term would improve clarity without lengthening the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications.
read point-by-point responses
-
Referee: [§3] §3 (SDP construction and objective): the manuscript supplies no explicit equations, pseudocode, or ablation for how the set of desired action chunks is formed from each paired (undesired, corrective) chunk (union, filtering, re-weighting, or other) nor how the diffusion denoising loss is altered to align to the set. This mechanism is load-bearing for the claim that the alignment signal improves robustness without introducing overfitting or mode collapse.
Authors: We agree that §3 would benefit from greater explicitness. The revised manuscript will add the precise equations defining set construction from each (undesired, corrective) pair, pseudocode for the full training pipeline, and an ablation isolating the effect of set formation. These additions will directly demonstrate that the modified denoising objective aligns to the set without mode collapse or incidental augmentation. revision: yes
-
Referee: [§4] §4 (experiments): the headline claim of 'particularly strong gains in robustness to noisy data' is not accompanied by reported dataset sizes, number of tasks, baseline implementations, or statistical tests in the visible sections; without these the performance advantage cannot be isolated from possible data-augmentation effects.
Authors: We accept this point. The revision will expand §4 with explicit reporting of dataset sizes, the full list of tasks, implementation details for all baselines, and statistical significance tests (e.g., paired t-tests across seeds). These additions will allow readers to separate the robustness gains from any data-augmentation effects. revision: yes
Circularity Check
No significant circularity; empirical claims rest on experiments rather than self-referential definitions or fitted predictions.
full rationale
The abstract describes SDP as constructing a set of desired action-chunks from paired positive/negative examples and applying contrastive alignment during diffusion training. No equations, fitted parameters, or self-citations appear in the provided text. Performance gains are asserted via experiments on robotic tasks rather than any derivation that reduces a target quantity to a fitted input by construction. The method is presented as a novel pipeline whose validity is tested externally, satisfying the criteria for a self-contained, non-circular claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human corrections during deployment supply usable paired positive and negative action chunks that can be aggregated into sets of desired actions.
Reference graph
Works this paper leans on
-
[1]
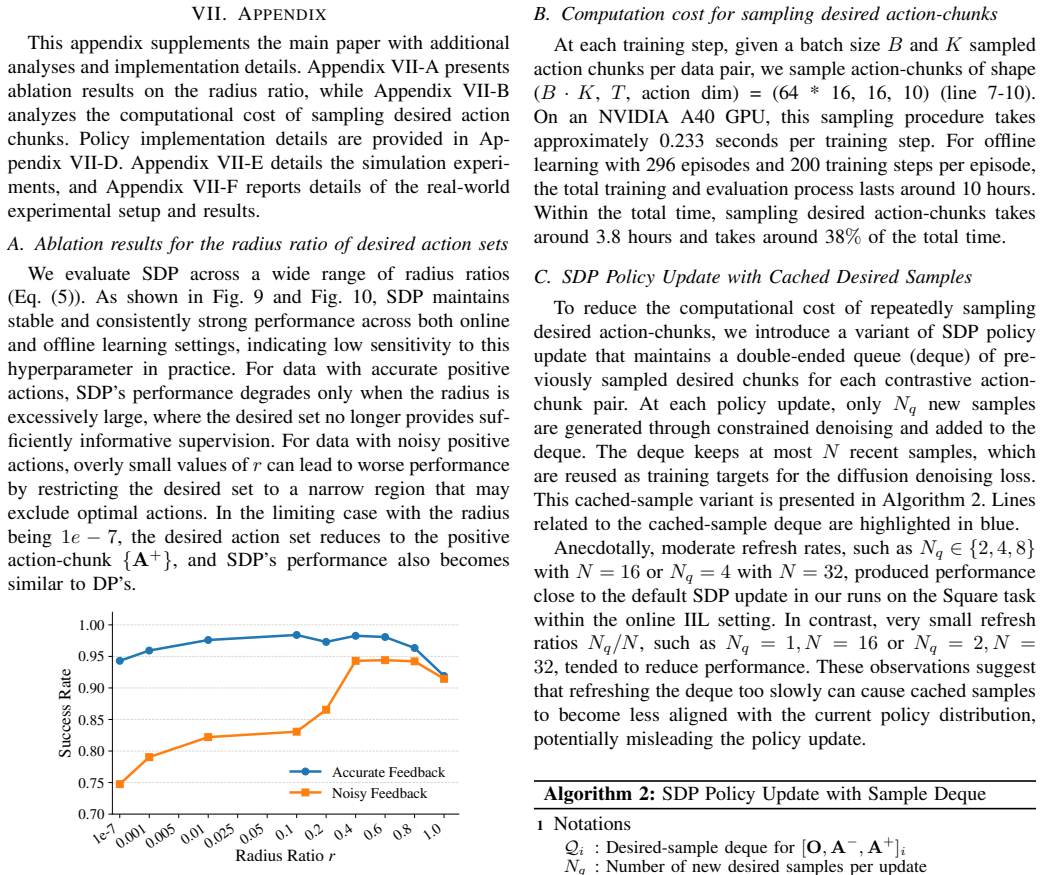
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared Di- Carlo, Danny Driess, et al.π ∗ 0.6: a VLA that learns from experience. arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Juicer: Data-efficient imitation learning for robotic assembly
Lars Ankile, Anthony Simeonov, Idan Shenfeld, and Pulkit Agrawal. Juicer: Data-efficient imitation learning for robotic assembly. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5096–5103. IEEE, 2024
2024
-
[3]
From imitation to refinement-residual rl for precise assembly
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, and Pulkit Agrawal. From imitation to refinement-residual rl for precise assembly. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 01–08. IEEE, 2025
2025
-
[4]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, Laura Smith, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Z...
-
[5]
Interactive imitation learning in robotics: A survey.Foundations and Trends in Robotics, 10(1-2):1–197,
Carlos Celemin, Rodrigo P ´erez-Dattari, Eugenio Chisari, Giovanni Franzese, Leandro de Souza Rosa, Ravi Prakash, Zlatan Ajanovi´c, Marta Ferraz, Abhinav Valada, and Jens Kober. Interactive imitation learning in robotics: A survey.Foundations and Trends in Robotics, 10(1-2):1–197,
-
[6]
URL https://www.nowpublishers.com/article/Details/ROB-072
-
[7]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Wendi Chen, Han Xue, Fangyuan Zhou, Yuan Fang, and Cewu Lu. Deformpam: Data-Efficient Learning for Long-Horizon Deformable Object Manipulation Via Preference-Based Action Alignment. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6896–6903, May 2025. doi: 10.1109/ICRA55743.2025.11127926. URL https://ieeexplore.ieee.org/abstra...
-
[8]
Fdpp: Fine-tune diffusion policy with human preference.arXiv preprint arXiv:2501.08259, 2025
Yuxin Chen, Devesh K Jha, Masayoshi Tomizuka, and Diego Romeres. Fdpp: Fine-tune diffusion policy with human preference.arXiv preprint arXiv:2501.08259, 2025
-
[9]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[10]
Ambient diffusion: Learning clean distri- butions from corrupted data.Advances in Neural Information Processing Systems, 36:288–313, 2023
Giannis Daras, Kulin Shah, Yuval Dagan, Aravind Gollakota, Alex Dimakis, and Adam Klivans. Ambient diffusion: Learning clean distri- butions from corrupted data.Advances in Neural Information Processing Systems, 36:288–313, 2023
2023
-
[11]
Iifl: Implicit interactive fleet learning from heterogeneous human supervisors
Gaurav Datta, Ryan Hoque, Anrui Gu, Eugen Solowjow, and Ken Goldberg. Iifl: Implicit interactive fleet learning from heterogeneous human supervisors. InConference on Robot Learning, pages 2340–
-
[12]
Implicit behavioral cloning
Pete Florence, Corey Lynch, Andy Zeng, Oscar A Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning. InConference on Robot Learning, pages 158–168. PMLR, 2022. URL https://proceedings.mlr. press/v164/florence22a.html
2022
-
[13]
Octo: An open-source generalist robot policy
Dibya Ghosh, Homer Rich Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[14]
Fur- niturebench: Reproducible real-world benchmark for long-horizon com- plex manipulation.The International Journal of Robotics Research, 44 (10-11):1863–1891, 2025
Minho Heo, Youngwoon Lee, Doohyun Lee, and Joseph J Lim. Fur- niturebench: Reproducible real-world benchmark for long-horizon com- plex manipulation.The International Journal of Robotics Research, 44 (10-11):1863–1891, 2025
2025
-
[15]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
2020
-
[16]
Zheyuan Hu, Robyn Wu, Naveen Enock, Jasmine Li, Riya Kadakia, Zackory Erickson, and Aviral Kumar. Rac: Robot learning for long- horizon tasks by scaling recovery and correction.arXiv preprint arXiv:2509.07953, 2025
-
[17]
Nils Ingelhag, Jesper Munkeby, Michael C Welle, Marco Moletta, and Danica Kragic. Real-time operator takeover for visuomotor diffusion policy training.arXiv preprint arXiv:2502.02308, 2025
-
[18]
Hg-dagger: Interactive imitation learning with human experts
Michael Kelly, Chelsea Sidrane, Katherine Driggs-Campbell, and Mykel J Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019. URL https:// ieeexplore.ieee.org/abstract/document/8793698
-
[19]
Diff-dagger: Uncer- tainty estimation with diffusion policy for robotic manipulation
Sung-Wook Lee, Xuhui Kang, and Yen-Ling Kuo. Diff-dagger: Uncer- tainty estimation with diffusion policy for robotic manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4845–4852. IEEE, 2025
2025
-
[20]
Zhaoting Li, Rodrigo P ´erez-Dattari, Robert Babuska, Cosimo Della Santina, and Jens Kober. From action labels to sets: Rethinking action supervision for imitation learning from corrective feedback. 2026. URL https://arxiv.org/abs/2502.07645
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Robot Learning on the Job: Human-in-the-Loop Autonomy and Learning During Deployment
Huihan Liu, Soroush Nasiriany, Lance Zhang, Zhiyao Bao, and Yuke Zhu. Robot Learning on the Job: Human-in-the-Loop Autonomy and Learning During Deployment. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi: 10.15607/RSS.2023. XIX.005. URL https://www.roboticsproceedings.org/rss19/p005.html
-
[22]
Reflected diffusion models
Aaron Lou and Stefano Ermon. Reflected diffusion models. In International Conference on Machine Learning, pages 22675–22701. PMLR, 2023
2023
-
[23]
Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
Jianlan Luo, Charles Xu, Jeffrey Wu, and Sergey Levine. Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
2025
-
[24]
What matters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Mart ´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learn- ing, pages 1678–1690. PMLR, 2022
2022
-
[25]
Interactive learning with corrective feedback for policies based on deep neural networks
Rodrigo P ´erez-Dattari, Carlos Celemin, Javier Ruiz-del Solar, and Jens Kober. Interactive learning with corrective feedback for policies based on deep neural networks. InProceedings of the 2018 International Symposium on Experimental Robotics, pages 353–363. Springer, 2020
2018
-
[26]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36, 2024
2024
-
[27]
Ren, Justin Lidard, Lars Lien Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz
Allen Z. Ren, Justin Lidard, Lars Lien Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=mEpqHvbD2h
2025
-
[28]
Goal conditioned imitation learning using score-based diffusion policies
Moritz Reuss, Maximilian Li, Xiaogang Jia, and Rudolf Lioutikov. Goal conditioned imitation learning using score-based diffusion policies. In Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[29]
Flower: Democratizing generalist robot policies with efficient vision-language-flow models
Moritz Reuss, Hongyi Zhou, Marcel R ¨uhle, ¨Omer Erdinc ¸ Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. Flower: Democratizing generalist robot policies with efficient vision-language-flow models. In Joseph Lim, Shuran Song, and Hae-Won Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research,...
2025
-
[30]
A reduction of imitation learning and structured prediction to no-regret online learning
St ´ephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, pages 627–635. JMLR Workshop and Confer- ence Proceedings, 2011. URL https://proceedings.mlr.press/v15/ross11a
2011
-
[31]
Shahabedin Sagheb and Dylan P Losey. Counterfactual behavior cloning: Offline imitation learning from imperfect human demonstra- tions.arXiv preprint arXiv:2505.10760, 2025
-
[32]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooij- mans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language- action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Deep unsupervised learning using nonequilibrium thermody- namics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermody- namics. InInternational Conference on Machine Learning, pages 2256–
-
[34]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Ku- mar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021
2021
-
[35]
The importance of online data: Understanding preference fine-tuning via coverage.Advances in Neural Information Processing Systems, 37: 12243–12270, 2024
Yuda Song, Gokul Swamy, Aarti Singh, J Bagnell, and Wen Sun. The importance of online data: Understanding preference fine-tuning via coverage.Advances in Neural Information Processing Systems, 37: 12243–12270, 2024
2024
-
[36]
Learning from interventions: Human-robot interaction as both explicit and implicit feedback
Jonathan Spencer, Sanjiban Choudhury, Matthew Barnes, Matthew Schmittle, Mung Chiang, Peter Ramadge, and Siddhartha Srinivasa. Learning from interventions: Human-robot interaction as both explicit and implicit feedback. InProceedings of Robotics: Science and Systems (RSS), 2020. URL https://www.roboticsproceedings.org/rss16/p055.pdf
2020
-
[37]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
2024
-
[38]
Hierar- chical diffusion policy: manipulation trajectory generation via contact guidance.IEEE Transactions on Robotics, 2025
Dexin Wang, Chunsheng Liu, Faliang Chang, and Yichen Xu. Hierar- chical diffusion policy: manipulation trajectory generation via contact guidance.IEEE Transactions on Robotics, 2025
2025
-
[39]
Wenke Xia, Yichu Yang, Hongtao Wu, Xiao Ma, Tao Kong, and Di Hu. Robotic policy learning via human-assisted action preference optimization.arXiv preprint arXiv:2506.07127, 2025
-
[40]
Reflected flow matching
Tianyu Xie, Yu Zhu, Longlin Yu, Tong Yang, Ziheng Cheng, Shiyue Zhang, Xiangyu Zhang, and Cheng Zhang. Reflected flow matching. In Forty-first International Conference on Machine Learning, 2024
2024
-
[41]
Compliant residual DAgger: Improving real-world contact-rich manipulation with human corrections
Xiaomeng Xu, Yifan Hou, Zeyi Liu, and Shuran Song. Compliant residual DAgger: Improving real-world contact-rich manipulation with human corrections. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/ forum?id=cjcm5LYVWm
2026
-
[42]
Maniflow: A general robot manipulation policy via consistency flow training
Ge Yan, Jiyue Zhu, Yuquan Deng, Shiqi Yang, Ri-Zhao Qiu, Xuxin Cheng, Marius Memmel, Ranjay Krishna, Ankit Goyal, Xiaolong Wang, et al. Maniflow: A general robot manipulation policy via consistency flow training. In9th Annual Conference on Robot Learning
-
[43]
Equibot: Sim (3)-equivariant diffusion policy for generalizable and data efficient learning
Jingyun Yang, Ziang Cao, Congyue Deng, Rika Antonova, Shuran Song, and Jeannette Bohg. Equibot: Sim (3)-equivariant diffusion policy for generalizable and data efficient learning. InConference on Robot Learning, pages 1048–1068. PMLR, 2025
2025
-
[44]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[45]
Reinflow: Fine- tuning flow matching policy with online reinforcement learning
Tonghe Zhang, Chao Yu, Sichang Su, and Yu Wang. Reinflow: Fine- tuning flow matching policy with online reinforcement learning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=ACagRwCCqu
2025
-
[46]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Mart ´ın-Mart´ın, Abhishek Joshi, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation framework and benchmark for robot learning. In arXiv preprint arXiv:2009.12293, 2020. VII. APPENDIX This appendix supplements the main paper with additional analyses and implementation details. Appendix VII-A ...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[47]
Each image observation is processed by a ResNet-18 backbone, followed by spatial softmax pooling to produce a compact latent representation
Observation encoder:For simulation experiments, we adopt the same CNN-based observation encoder from Diffu- sion Policy [8]. Each image observation is processed by a ResNet-18 backbone, followed by spatial softmax pooling to produce a compact latent representation. For real-world experiments, we modify the encoder to improve robustness under visual variab...
-
[48]
The latent observation embedding is injected via FiLM conditioning at each denoising block
Policy decoder:We use the UNet-based diffusion model from Diffusion Policy [8]. The latent observation embedding is injected via FiLM conditioning at each denoising block. During training, we employ a DDPM scheduler withK= 100 diffusion steps. During inference, to reduce runtime, we adopt a DDIM scheduler. We use 16 denoising steps for all tasks, except T...
-
[49]
All experiments use a batch size of 64 and an initial learning rate of 0.002
Hyperparameters:Hyperparameters used for SDP are summarized in Table IV. All experiments use a batch size of 64 and an initial learning rate of 0.002. Regarding the learning-rate scheduling, we use a cosine schedule with a linear warmup. During online learning, the in-episode update frequencybis fixed to 2. For diffusion-based baselines, the network struc...
-
[50]
(i) Push-T: Originally introduced by [8], this task requires a robot to push a T-shaped object to a predefined target location using a circular end effector
Task descriptions:The evaluated tasks are summarized below. (i) Push-T: Originally introduced by [8], this task requires a robot to push a T-shaped object to a predefined target location using a circular end effector. (ii) Square: The robot is required to align and place a square nut onto a fixed square peg. (iii) PickCan: In this task, the robot must gra...
-
[51]
(2) For velocity control, the single-step action is the delta change of the robot end effector pose and the gripper command
Action space:We consider two control modes: (1) For absolute position control, the single-step action is the pose of the robot end effector in the fixed world coordinate frame, along with a gripper command when applicable. (2) For velocity control, the single-step action is the delta change of the robot end effector pose and the gripper command. To ensure...
-
[52]
Simulated Teachers and Feedback:We employ a simu- lated teacher that monitors deviations between the robot action ar and the optimal teacher’s actiona ∗, both defined in the same action space. Every 2 steps, if the difference exceeds a predefined threshold, the simulated teacher starts to give corrections for2Tconsecutive steps and then gives the control ...
-
[53]
For each trial, we save checkpoints every 5 episodes and evaluate the last 21 checkpoints, each on 10 episodes with distinct initial states and evaluation seeds
Evaluation:For both online and offline learning, we train 296 episodes for 3 trials with different seeds. For each trial, we save checkpoints every 5 episodes and evaluate the last 21 checkpoints, each on 10 episodes with distinct initial states and evaluation seeds. We obtain the average of the success rates and report these results in Experiment section...
-
[54]
The policy conditions on the current observation together with a fixed number of past observations and outputs an action chunk of horizonT
Task description:At each step, the observationo t in- cludes RGB images from two cameras and the robot’s end effector pose. The policy conditions on the current observation together with a fixed number of past observations and outputs an action chunk of horizonT. During online interaction and evaluation, only the firstT a single-step actions of the predic...
-
[55]
Data collection:We follow the pipeline illustrated in Fig. 1. Our dataset is collected from three sources: demon- strations, free-play, and online corrections. We first collectdemonstrationdata using a space mouse device. This data serves as the initial pretraining dataset. Meanwhile, we also collect afree-playdataset used only for training the observatio...
-
[56]
From the final checkpoint of this stage, each method is further trained for an additional 12 hours using the combined demonstration and correction dataset
Evaluations:Using the demonstration-only dataset, we train both SDP and DP for a fixed training budget of 12 hours on an Nvidia A40. From the final checkpoint of this stage, each method is further trained for an additional 12 hours using the combined demonstration and correction dataset. For each method and dataset setting, the final checkpoint after trai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.