ART-VS: Adaptive Resolution Tiling for Vision Transformer Visual Servoing
Pith reviewed 2026-06-26 20:53 UTC · model grok-4.3
The pith
Adaptive resolution tiling lets self-supervised ViT features reach 95.4% convergence in visual servoing under perturbation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
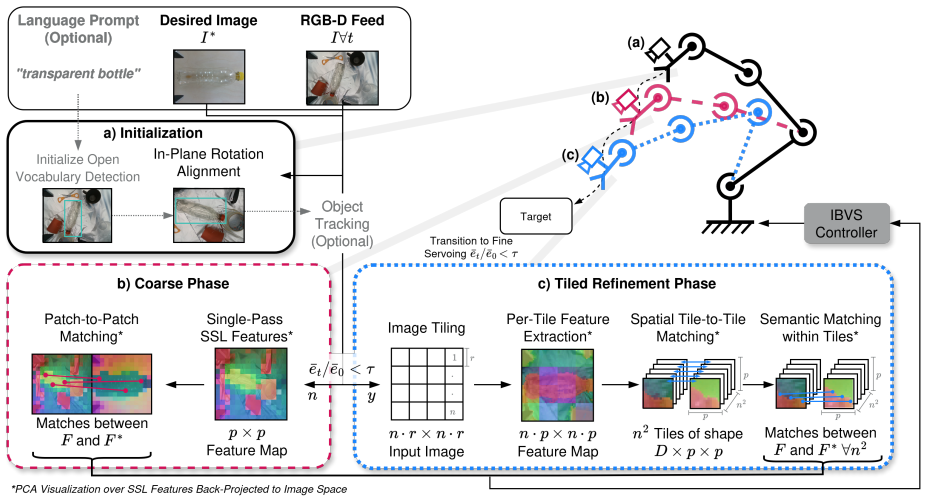
ART-VS performs visual servoing by running a coarse phase at the ViT's native resolution to obtain stable correspondences, then a tiled high-resolution phase that restricts feature matching to local neighborhoods determined by the coarse results. This yields 95.4% convergence success under perturbation, an 18.8-point gain over standard ViT servoing and a 14.4-point gain over full-resolution ViT servoing, a 53% reduction in positioning error relative to the standard baseline, more than 10 times higher speed, and 27% lower VRAM usage than full high-resolution processing, with the same gains observed across three different ViT backbones and in real-world category-level grasping of unseen instan
What carries the argument
Adaptive Resolution Tiling, the two-phase mechanism that restricts high-resolution ViT feature matching to local neighborhoods after an initial coarse alignment at native resolution.
If this is right
- Convergence success rises to 95.4% under perturbation while positioning error drops 53% compared with standard ViT servoing.
- Speed increases more than 10 times and VRAM usage drops 27% relative to full high-resolution ViT processing.
- The same performance pattern holds across three different ViT backbones.
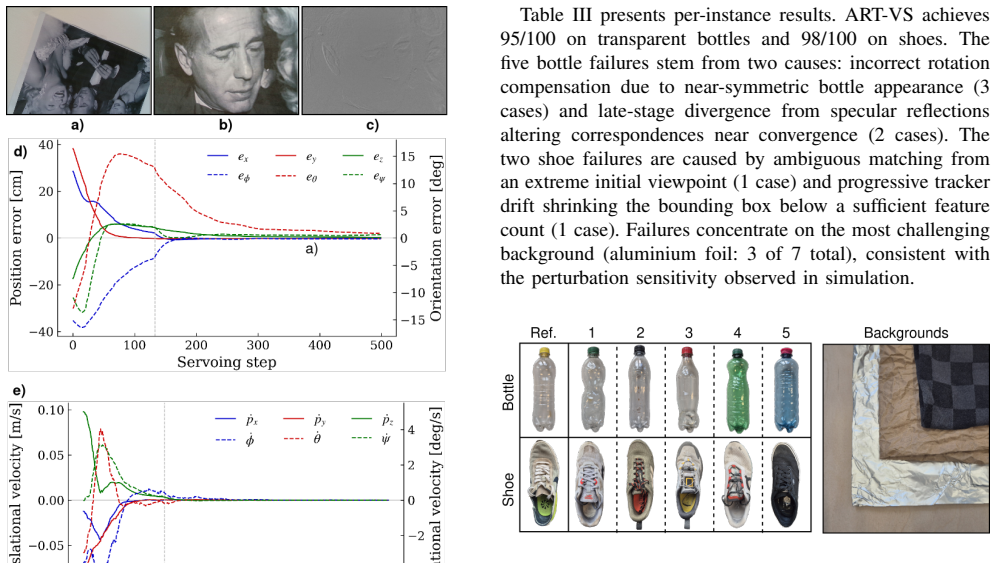
- Real-world category-level grasping of unseen objects reaches 95 out of 100 trials on transparent bottles and 98 out of 100 on shoes.
Where Pith is reading between the lines
- The same coarse-then-local-high-resolution pattern could be applied to other ViT-based robotic perception pipelines that currently face resolution versus compute trade-offs.
- Monitoring servoing progress to trigger the resolution change may allow the method to adapt automatically to different levels of image disturbance without extra learned modules.
- Because the tiling decision depends only on the coarse output, the approach may extend directly to dynamic scenes where the required resolution changes over time.
Load-bearing premise
The coarse native-resolution phase always produces an initial alignment close enough that restricting later high-resolution matching to local neighborhoods will increase precision without introducing new failure modes.
What would settle it
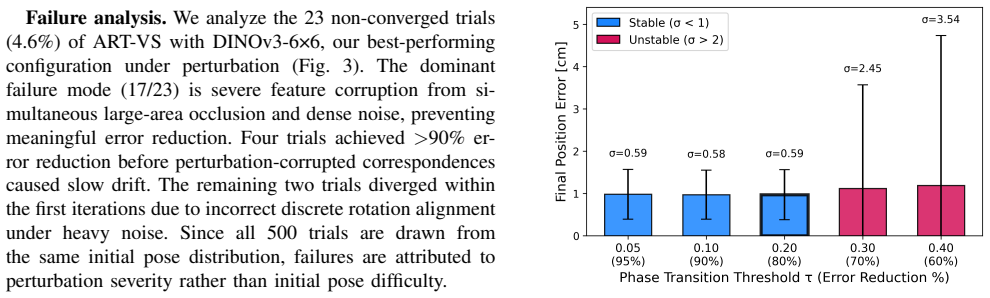
A set of trials in which strong perturbations cause the coarse phase to place the target outside the local high-resolution search neighborhoods, producing either lower convergence than full-resolution processing or no accuracy gain.
Figures



read the original abstract
Visual servoing with self-supervised Vision Transformer (ViT) features enables training-free robotic positioning with strong generalization, but faces a fundamental trade-off between robustness and precision. Coarse patch-level descriptors provide stable correspondences yet limit positioning accuracy. Increasing image resolution improves precision but yields only marginal robustness gains - under perturbation, high-resolution processing improves convergence success rate from 76.6% to just 81.0% despite 12x more ViT patches. Therefore, we propose Adaptive Resolution Tiling Visual Servoing (ART-VS), a two-phase method that adapts feature granularity to servoing progress: a coarse phase at native ViT resolution for stable alignment, then a tiled high-resolution phase that restricts matching to local neighborhoods improving positioning accuracy. Without any task-specific training, ART-VS achieves 95.4% convergence under perturbation, outperforming standard and full-resolution ViT-based servoing by 18.8 and 14.4 percentage points. Over the former it reduces positioning error by 53%, while running at over 10x higher speed and 27% lower VRAM than the latter. We validate ART-VS across three ViT backbones and demonstrate real-world category-level grasping of unseen object instances, achieving 95/100 on transparent bottles and 98/100 on shoes. Code available under https://art-vs.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Adaptive Resolution Tiling Visual Servoing (ART-VS), a two-phase method for Vision Transformer-based visual servoing. The first phase uses coarse patch-level features at native resolution for stable initial alignment under perturbation, while the second phase applies high-resolution processing restricted to local neighborhoods around the coarse estimate to enhance positioning precision. Without task-specific training, it claims 95.4% convergence success under perturbation (outperforming standard ViT servoing by 18.8 pp and full-resolution by 14.4 pp), 53% reduction in positioning error compared to the standard approach, over 10x speed and 27% lower VRAM than full-resolution, validated on three ViT backbones and real-world grasping tasks (95/100 transparent bottles, 98/100 shoes).
Significance. If the central claims hold, ART-VS would represent a meaningful advance in training-free visual servoing by adaptively balancing robustness and precision, achieving notable improvements in convergence rates and efficiency. The availability of code at https://art-vs.github.io/ supports reproducibility. The real-world validation on unseen object instances strengthens the practical relevance for robotic manipulation tasks.
major comments (2)
- [Abstract and §3 (Method)] The reported 95.4% convergence rate under perturbation rests on the assumption that the coarse native-resolution phase produces an alignment error always small enough for the high-resolution tiled phase's local neighborhoods to capture the correct correspondence. No quantitative bound or distribution of post-coarse errors relative to the neighborhood radius is provided, and no ablation studies isolate cases where the coarse estimate falls outside the tile radius, which could introduce new failure modes.
- [§4 (Experiments)] The performance numbers (95.4% convergence, 53% error reduction) are presented without error bars, statistical tests, or full details on the experimental protocol, perturbation types, dataset sizes, or number of trials, which are necessary to evaluate the statistical significance of the improvements over the baselines.
minor comments (2)
- [Abstract] The specific ViT backbones used in the three-backbone validation are not named in the abstract, though presumably detailed later.
- [Throughout] Ensure consistent notation for 'native resolution' versus 'full-resolution' to avoid potential confusion between the coarse phase and the full-resolution baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and address the major comments point by point below. We will revise the manuscript to incorporate the requested analyses and details.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] The reported 95.4% convergence rate under perturbation rests on the assumption that the coarse native-resolution phase produces an alignment error always small enough for the high-resolution tiled phase's local neighborhoods to capture the correct correspondence. No quantitative bound or distribution of post-coarse errors relative to the neighborhood radius is provided, and no ablation studies isolate cases where the coarse estimate falls outside the tile radius, which could introduce new failure modes.
Authors: We agree that an explicit quantitative bound and distribution of post-coarse errors relative to the tile radius, along with an ablation on out-of-neighborhood cases, would strengthen the presentation. In the revised manuscript we will add this analysis (including histograms of coarse-phase errors and a dedicated ablation isolating failures where the coarse estimate exceeds the neighborhood radius) to demonstrate that such cases remain rare under the evaluated perturbations and do not introduce new dominant failure modes. revision: yes
-
Referee: [§4 (Experiments)] The performance numbers (95.4% convergence, 53% error reduction) are presented without error bars, statistical tests, or full details on the experimental protocol, perturbation types, dataset sizes, or number of trials, which are necessary to evaluate the statistical significance of the improvements over the baselines.
Authors: We acknowledge that the current experimental section lacks error bars, statistical tests, and complete protocol details. The revised version will expand §4 to report standard deviations across repeated trials, include statistical significance tests (e.g., paired t-tests against baselines), and provide full details on perturbation distributions, dataset sizes, and exact trial counts for each reported metric. revision: yes
Circularity Check
No circularity in ART-VS method or claims
full rationale
The paper proposes an empirical two-phase algorithm (coarse native ViT resolution followed by local tiled high-resolution matching) and reports measured success rates, error reductions, and runtime metrics from experiments on three backbones plus real-world grasping. No equations, parameter fits, or derivations appear that reduce any claimed result to its own inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing support. The performance numbers are presented as direct experimental outcomes, not as predictions derived from the method definition itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visual servo control. i. basic approaches,
F. Chaumette and S. Hutchinson, “Visual servo control. i. basic approaches,”IEEE Robotics & Automation Magazine, vol. 13, no. 4, pp. 82–90, 2006
2006
-
[2]
Visual servo control part ii: Advanced approaches,
C. Francois and H. Seth, “Visual servo control part ii: Advanced approaches,”IEEE Trans on Robotics and Automation, vol. 14, no. 1, pp. 109–118, 2007
2007
-
[3]
Kovis: Keypoint-based visual servoing with zero-shot sim-to-real transfer for robotics manipulation,
E. Y . Puang, K. P. Tee, and W. Jing, “Kovis: Keypoint-based visual servoing with zero-shot sim-to-real transfer for robotics manipulation,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 7527–7533
2020
-
[4]
Robotic grasping based on efficient track- ing and visual servoing using local feature descriptors,
T. La Anh and J.-B. Song, “Robotic grasping based on efficient track- ing and visual servoing using local feature descriptors,”International Journal of Precision Engineering and Manufacturing, vol. 13, pp. 387–393, 2012
2012
-
[5]
Image matching using sift, surf, brief and orb: performance comparison for distorted images,
E. Karami, S. Prasad, and M. Shehata, “Image matching using sift, surf, brief and orb: performance comparison for distorted images,” arXiv preprint arXiv:1710.02726, 2017
Pith/arXiv arXiv 2017
-
[6]
Visual servoing in autoencoder latent space,
S. Felton, P. Brault, E. Fromont, and E. Marchand, “Visual servoing in autoencoder latent space,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3234–3241, 2022
2022
-
[7]
Deep metric learning for visual servoing: when pose and image meet in latent space,
S. Felton, E. Fromont, and E. Marchand, “Deep metric learning for visual servoing: when pose and image meet in latent space,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 741–747
2023
-
[8]
Training deep neural networks for visual servoing,
Q. Bateux, E. Marchand, J. Leitner, F. Chaumette, and P. Corke, “Training deep neural networks for visual servoing,” in2018 IEEE International Conference on Robotics and Automation (ICRA), 2018, pp. 3307–3314
2018
-
[9]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[10]
Vit-vs: On the applicability of pretrained vision trans- former features for generalizable visual servoing,
A. Scherl, S. Thalhammer, B. Neuberger, W. W ¨ober, and J. Garc ´ıa- Rodr´ıguez, “Vit-vs: On the applicability of pretrained vision trans- former features for generalizable visual servoing,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 17 769–17 776
2025
-
[11]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoaet al., “Dinov3,” arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[12]
A tutorial on visual servo control,
S. Hutchinson, G. D. Hager, and P. I. Corke, “A tutorial on visual servo control,”IEEE transactions on robotics and automation, vol. 12, no. 5, pp. 651–670, 1996
1996
-
[13]
Distinctive image features from scale-invariant key- points,
D. G. Lowe, “Distinctive image features from scale-invariant key- points,”International journal of computer vision, vol. 60, pp. 91–110, 2004
2004
-
[14]
Orb: An efficient alternative to sift or surf,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in2011 International conference on computer vision. Ieee, 2011, pp. 2564–2571
2011
-
[15]
Fast explicit diffusion for acceler- ated features in nonlinear scale spaces,
P. F. Alcantarilla and T. Solutions, “Fast explicit diffusion for acceler- ated features in nonlinear scale spaces,”IEEE Trans. Patt. Anal. Mach. Intell, vol. 34, no. 7, pp. 1281–1298, 2011
2011
-
[16]
Visual servoing with moments of sift features,
F. Hoffmann, T. Nierobisch, T. Seyffarth, and G. Rudolph, “Visual servoing with moments of sift features,” in2006 IEEE International Conference on Systems, Man and Cybernetics, vol. 5. IEEE, 2006, pp. 4262–4267
2006
-
[17]
Siame-se(3): regression in se(3) for end-to-end visual servoing,
S. Felton, ´E. Fromont, and E. Marchand, “Siame-se(3): regression in se(3) for end-to-end visual servoing,” in2021 IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 14 454– 14 460
2021
-
[18]
CNS: Correspondence encoded neural image servo policy,
A. Chen, H. Yu, Y . Wang, and R. Xiong, “CNS: Correspondence encoded neural image servo policy,” inIEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 17 410–17 416
2024
-
[19]
Depth-PC: Sim-to-real transfer for zero-shot visual servoing via cross-modal fusion,
H. Zhang, Y . Liu, Y . Jiang, W. Lin, and C. Ye, “Depth-PC: Sim-to-real transfer for zero-shot visual servoing via cross-modal fusion,”IEEE Robotics and Automation Letters, vol. 10, no. 11, pp. 11 976–11 983, 2025
2025
-
[20]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/forum?id=YicbFdNTTy
2021
-
[21]
Emerging properties in self-supervised vision trans- formers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision trans- formers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660
2021
-
[22]
Am-radio: Agglomerative vision foundation model reduce all domains into one,
M. Ranzinger, G. Heinrich, J. Kautz, and P. Molchanov, “Am-radio: Agglomerative vision foundation model reduce all domains into one,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 12 490–12 500
2024
-
[23]
Deep vit features as dense visual descriptors,
S. Amir, Y . Gandelsman, S. Bagon, and T. Dekel, “Deep vit features as dense visual descriptors,”ECCVW What is Motion For?, 2022
2022
-
[24]
Zero-shot category- level object pose estimation,
W. Goodwin, S. Vaze, I. Havoutis, and I. Posner, “Zero-shot category- level object pose estimation,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 516–532
2022
-
[25]
Featup: A model-agnostic framework for features at any resolution,
S. Fu, M. Hamilton, L. Brandt, A. Feldman, Z. Zhang, and W. T. Freeman, “Featup: A model-agnostic framework for features at any resolution,”arXiv preprint arXiv:2403.10516, 2024
arXiv 2024
-
[26]
Loftup: Learning a coordinate-based feature upsampler for vision foundation models,
H. Huang, A. Chen, V . Havrylov, A. Geiger, and D. Zhang, “Loftup: Learning a coordinate-based feature upsampler for vision foundation models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 9913–9923
2025
-
[27]
Dgc-net: Dense geometric correspondence network,
I. Melekhov, A. Tiulpin, T. Sattler, M. Pollefeys, E. Rahtu, and J. Kannala, “Dgc-net: Dense geometric correspondence network,” in 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2019, pp. 1034–1042
2019
-
[28]
Loftr: Detector- free local feature matching with transformers,
J. Sun, Z. Shen, Y . Wang, H. Bao, and X. Zhou, “Loftr: Detector- free local feature matching with transformers,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8922–8931
2021
-
[29]
Su- perglue: Learning feature matching with graph neural networks,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “Su- perglue: Learning feature matching with graph neural networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4938–4947
2020
-
[30]
Best-buddies similarity for robust template matching,
T. Dekel, S. Oron, M. Rubinstein, S. Avidan, and W. T. Freeman, “Best-buddies similarity for robust template matching,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 2021–2029
2015
-
[31]
LangSAM: Language-guided expert routing on SAM2 for dense scene understanding,
Y . Xu, H. Yuan, and J. Zhu, “LangSAM: Language-guided expert routing on SAM2 for dense scene understanding,” 2025. [Online]. Available: https://openreview.net/forum?id=o0hpH7ck29
2025
-
[32]
Lighttrack: Finding lightweight neural networks for object tracking via one-shot architecture search,
B. Yan, H. Peng, K. Wu, D. Wang, J. Fu, and H. Lu, “Lighttrack: Finding lightweight neural networks for object tracking via one-shot architecture search,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 15 180–15 189
2021
-
[33]
Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes,
Y . Xiang, T. Schmidt, V . Narayanan, and D. Fox, “Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes,”arXiv preprint arXiv:1711.00199, 2017
Pith/arXiv arXiv 2017
-
[34]
Discriminative correlation filter with channel and spatial reliability,
A. Lukezic, T. V ojir, L.ˇCehovin Zajc, J. Matas, and M. Kristan, “Discriminative correlation filter with channel and spatial reliability,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6309–6318
2017
-
[35]
Two-frame motion estimation based on polynomial expansion,
G. Farneb ¨ack, “Two-frame motion estimation based on polynomial expansion,” inScandinavian conference on Image analysis. Springer, 2003, pp. 363–370
2003
-
[36]
Sam 3: Segment anything with concepts,
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huanget al., “Sam 3: Segment anything with concepts,”arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.