LENS: A Staged Design for Interaction Granularity in Sequential CTR Prediction
Pith reviewed 2026-06-29 20:40 UTC · model grok-4.3
The pith
LENS restores target-specific control in latent-query models for sequential CTR prediction through conditioned gates and biases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
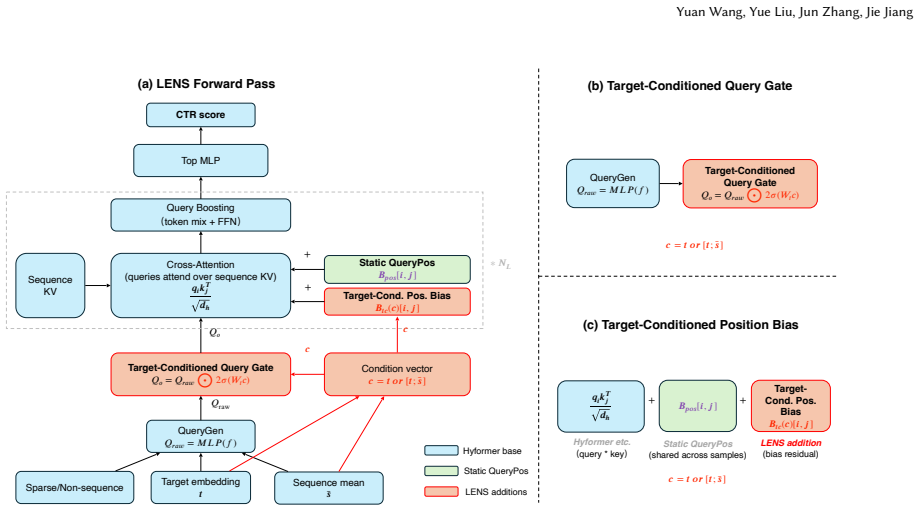
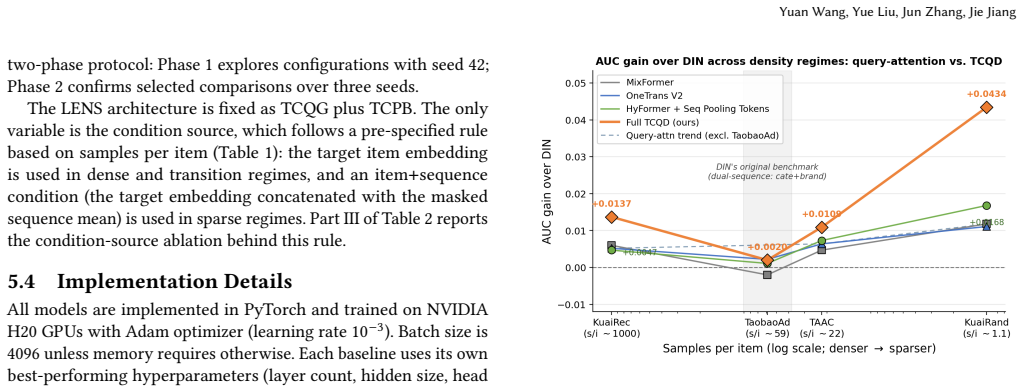
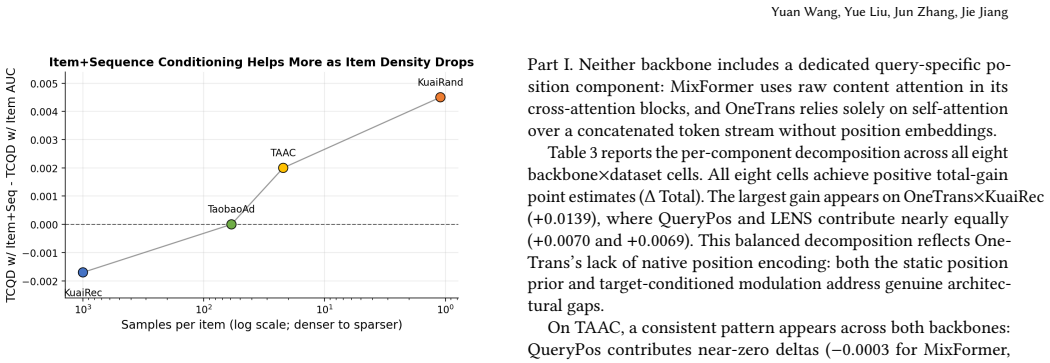
LENS restores target-specific control within coarser latent-query bottlenecks through a Target-Conditioned Query Gate for query activation and a Target-Conditioned Position Bias for history retrieval. Combined with Query-Specific Position Bias, the design produces positive total-gain point estimates in all twelve evaluated backbone-dataset cells and identifies a density-dependent conditioning rule in which the optimal source shifts from item-only to item-plus-sequence as item density decreases.
What carries the argument
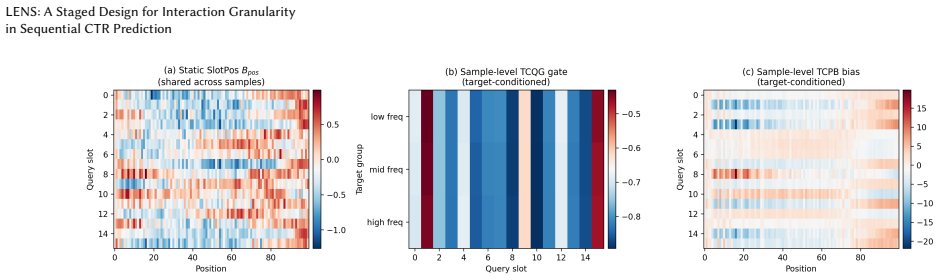
LENS's Target-Conditioned Query Gate (TCQG) and Target-Conditioned Position Bias (TCPB), which use the target to activate queries and bias position retrieval inside latent-query backbones.
If this is right
- Latent-query backbones gain consistent performance lifts when the proposed conditioning modules are added.
- The density-dependent rule supplies a concrete guideline for selecting the condition source based on observed item sparsity.
- QueryPos supplies a lightweight static position reference that improves any latent-query backbone.
- The staged design supplies target control without returning to the brittleness of direct raw-item interaction.
Where Pith is reading between the lines
- The same staged conditioning pattern could be tested in adjacent sequential tasks such as next-item recommendation.
- An adaptive model that switches between item-only and item-plus-sequence conditioning according to local density might be built from the observed rule.
- Whether the reported gains appear in live ranking metrics such as revenue or session length remains open to direct measurement.
Load-bearing premise
The measured positive gains arise specifically from the TCQG, TCPB, and QueryPos modules rather than from other unstated implementation details, and the three backbones plus four datasets are representative enough to support the density-dependent rule.
What would settle it
Re-running the twelve backbone-dataset experiments on a fresh set of backbones or datasets and obtaining zero or negative gains, or failing to observe the shift in optimal condition source with density, would falsify the central claims.
Figures

read the original abstract
In sequential CTR prediction, a central design question is at what granularity the target should interact with the user behaviour sequence. Existing models mainly follow two routes. Raw-item architectures such as DIN let the target score each item in the sequence directly. This relies on well-trained item embeddings and becomes brittle for sparse items. Latent-query architectures such as HyFormer, MixFormer, and OneTrans build query representations by combining the target with other information. This is more robust across item-density regimes but blunter: target-specific control is diluted. We propose LENS to restore target-specific control within these coarser bottlenecks. LENS has two modules: a Target-Conditioned Query Gate (TCQG) for query activation and a Target-Conditioned Position Bias (TCPB) for history retrieval. We further introduce Query-Specific Position Bias (QueryPos), a simple static position-aware reference for latent-query backbones. Across three representative latent-query backbones and four datasets, the combined QueryPos+LENS design achieves positive total-gain point estimates in all twelve evaluated backbone--dataset cells. We also identify a density-dependent conditioning rule: as item density decreases, the optimal condition source shifts from item-only to item-plus-sequence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LENS, consisting of a Target-Conditioned Query Gate (TCQG) for query activation and a Target-Conditioned Position Bias (TCPB) for history retrieval, to restore target-specific control in latent-query architectures (e.g., HyFormer, MixFormer, OneTrans) for sequential CTR prediction. It further introduces Query-Specific Position Bias (QueryPos) as a static position-aware reference. The central empirical claims are that the combined QueryPos+LENS design yields positive total-gain point estimates in all 12 backbone–dataset cells across three latent-query backbones and four datasets, and that a density-dependent conditioning rule holds: as item density decreases, the optimal condition source shifts from item-only to item-plus-sequence.
Significance. If the reported gains are shown to be produced by the TCQG, TCPB, and QueryPos modules (rather than confounding implementation factors) and the density-dependent rule is shown to generalize, the work would supply a practical, staged design principle for choosing interaction granularity between raw-item and latent-query regimes, with direct implications for robustness in sparse-item settings.
major comments (2)
- [Abstract] Abstract: the claim of positive total-gain point estimates in all twelve backbone–dataset cells is presented as evidence for the efficacy of TCQG, TCPB, and QueryPos, yet the manuscript provides no module-level ablations that isolate these components while holding optimizer settings, data splits, and re-implementation details fixed; without such controls the attribution of the observed gains remains unverified.
- [Abstract] Abstract: the density-dependent conditioning rule is asserted on the basis of four datasets, but the manuscript cites no section containing cross-validation across additional density regimes, statistical tests for the shift, or sensitivity analysis; this leaves the generalizability of the rule as a load-bearing claim without the required supporting evidence.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the three backbones and four datasets explicitly rather than referring to them only as “representative.”
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on attribution of gains and validation of the density-dependent rule. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of positive total-gain point estimates in all twelve backbone–dataset cells is presented as evidence for the efficacy of TCQG, TCPB, and QueryPos, yet the manuscript provides no module-level ablations that isolate these components while holding optimizer settings, data splits, and re-implementation details fixed; without such controls the attribution of the observed gains remains unverified.
Authors: We agree that the manuscript does not contain module-level ablations that isolate TCQG, TCPB, and QueryPos while holding all other factors fixed. The reported results demonstrate the combined QueryPos+LENS design. In revision we will add these controlled ablations to verify component-level contributions. revision: yes
-
Referee: [Abstract] Abstract: the density-dependent conditioning rule is asserted on the basis of four datasets, but the manuscript cites no section containing cross-validation across additional density regimes, statistical tests for the shift, or sensitivity analysis; this leaves the generalizability of the rule as a load-bearing claim without the required supporting evidence.
Authors: The rule is observed across the four datasets of varying density in the current experiments. We acknowledge the need for additional supporting evidence. In revision we will incorporate statistical tests for the observed shift, sensitivity analysis on density thresholds, and any feasible cross-validation on further regimes. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivation chain
full rationale
The paper reports observed performance gains from LENS modules across three backbones and four datasets, plus an empirically identified density-dependent rule. No equations, first-principles derivations, or predictions are presented that could reduce to inputs by construction. The central claims rest on experimental point estimates rather than any self-definitional, fitted-input, or self-citation load-bearing steps, so the evaluation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alibaba Tianchi. 2018. Alibaba Display Advertising Challenge Dataset. https: //tianchi.aliyun.com/dataset/56
2018
-
[2]
Yue Cao, Xiaojiang Zhou, Jiaqi Feng, Peihao Huang, Yao Xiao, Dayao Chen, and Sheng Chen. 2022. Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 2974–2983
2022
-
[3]
Yukuo Cen, Jianwei Zhang, Xu Zou, Chang Zhou, Hongxia Yang, and Jie Tang
-
[4]
InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
Controllable Multi-Interest Framework for Recommendation. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2942–2951
-
[5]
Qiwei Chen, Changhua Pei, Shanshan Lv, Chao Li, Junfeng Ge, and Wenwu Ou
- [6]
-
[7]
Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, and Wenwu Ou. 2019. Behavior Se- quence Transformer for E-commerce Recommendation in Alibaba. InProceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data
2019
-
[8]
Zhaoqi Zhang, Haolei Pei, Jun Guo, Tianyu Wang, Yufei Feng, Hui Sun, Shaowei Liu, and Aixin Sun. 2026. OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender. InProceedings of The Web Conference 2026
2026
-
[9]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah
-
[10]
InProceedings of the 1st Workshop on Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems. InProceedings of the 1st Workshop on Deep Learning for Recommender Systems. 7–10
-
[11]
Le, and Ruslan Salakhutdinov
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, and Ruslan Salakhutdinov. 2019. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2978–2988
2019
-
[12]
Dauphin, Angela Fan, Michael Auli, and David Grangier
Yann N. Dauphin, Angela Fan, Michael Auli, and David Grangier. 2017. Lan- guage Modeling with Gated Convolutional Networks. InProceedings of the 34th International Conference on Machine Learning. 933–941
2017
-
[13]
Yufei Feng, Fuyu Lv, Weichen Shen, Menghan Wang, Fei Sun, Yu Zhu, and Keping Yang. 2019. Deep Session Interest Network for Click-Through Rate Prediction. InProceedings of the 28th International Joint Conference on Artificial Intelligence. 2301–2307
2019
-
[14]
Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. 2022. KuaiRec: A Fully-Observed Dataset and Insights for Evaluating Recommender Systems. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 540–550
2022
-
[15]
Chongming Gao, Shijun Li, Yuan Zhang, Jiawei Chen, Biao Li, Wenqiang Lei, Peng Jiang, and Xiangnan He. 2022. KuaiRand: An Unbiased Sequential Rec- ommendation Dataset with Randomly Exposed Videos. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 3953–3957
2022
-
[16]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A Factorization-Machine Based Neural Network for CTR Prediction. InProceedings of the 26th International Joint Conference on Artificial Intelligence. 1725–1731
2017
-
[17]
Dai, and Quoc V
David Ha, Andrew M. Dai, and Quoc V. Le. 2017. HyperNetworks. InInternational Conference on Learning Representations
2017
-
[18]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[19]
In International Conference on Learning Representations
Session-based Recommendations with Recurrent Neural Networks. In International Conference on Learning Representations
-
[20]
Jie Hu, Li Shen, and Gang Sun. 2018. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7132–7141
2018
-
[21]
Xu Huang, Hao Zhang, Zhifang Fan, Yunwen Huang, Zhuoxing Wei, Zheng Chai, Jinan Ni, Yuchao Zheng, and Qiwei Chen. 2026. MixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders.arXiv preprint arXiv:2602.14110 (2026). 11 Yuan Wang, Yue Liu, Jun Zhang, Jie Jiang
work page internal anchor Pith review arXiv 2026
-
[22]
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and João Carreira. 2021. Perceiver: General Perception with Iterative Attention. In Proceedings of the 38th International Conference on Machine Learning. 4651–4664
2021
-
[23]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Recom- mendation. In2018 IEEE International Conference on Data Mining. 197–206
2018
-
[24]
Kosiorek, Seungjin Choi, and Yee Whye Teh
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam R. Kosiorek, Seungjin Choi, and Yee Whye Teh. 2019. Set Transformer: A Framework for Attention-Based Permutation-Invariant Neural Networks. InProceedings of the 36th International Conference on Machine Learning. 3744–3753
2019
-
[25]
Chao Li, Zhiyuan Liu, Mengmeng Wu, Yuchi Xu, Huan Zhao, Pipei Huang, Guoliang Kang, Qiwei Chen, Wei Li, and Dik Lun Lee. 2019. Multi-Interest Net- work with Dynamic Routing for Recommendation at Tmall. InProceedings of the 28th ACM International Conference on Information and Knowledge Management. 2615–2623
2019
- [26]
-
[27]
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahen- dran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf
-
[28]
InAdvances in Neural Infor- mation Processing Systems
Object-Centric Learning with Slot Attention. InAdvances in Neural Infor- mation Processing Systems. 11525–11538
-
[29]
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, et al. 2019. Deep Learning Recommendation Model for Personalization and Recommenda- tion Systems.arXiv preprint arXiv:1906.00091(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[30]
Junwei Pan, Wei Xue, Chao Zhou, Xing Zhou, Lunan Fan, Yanbo Wang, Haoran Xin, Zhiyu Hu, Yaozheng Wang, Fengye Xu, et al. 2026. Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation.arXiv preprint arXiv:2604.04976(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. 2018. FiLM: Visual Reasoning with a General Conditioning Layer. In Proceedings of the AAAI Conference on Artificial Intelligence. 3942–3951
2018
-
[32]
Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2671–2679
2019
- [33]
-
[34]
Smith, and Mike Lewis
Ofir Press, Noah A. Smith, and Mike Lewis. 2022. Train Short, Test Long: At- tention with Linear Biases Enables Input Length Extrapolation. InInternational Conference on Learning Representations
2022
-
[35]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research21, 140 (2020), 1–67
2020
-
[36]
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. 2018. Self-Attention with Relative Position Representations. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 464–468
2018
-
[37]
Noam Shazeer. 2020. GLU Variants Improve Transformer.arXiv preprint arXiv:2002.05202(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[38]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. AutoInt: Automatic Feature Interaction Learning via Self- Attentive Neural Networks. InProceedings of the 28th ACM International Confer- ence on Information and Knowledge Management. 1161–1170
2019
-
[39]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. RoFormer: Enhanced Transformer with Rotary Position Embedding. Neurocomputing568 (2024), 127063
2024
-
[40]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[41]
InProceedings of the 28th ACM International Conference on Information and Knowledge Management
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Rep- resentations from Transformer. InProceedings of the 28th ACM International Conference on Information and Knowledge Management. 1441–1450
-
[42]
Jiaxi Tang and Ke Wang. 2018. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. InProceedings of the Eleventh ACM International Conference on Web Search and Data Mining. 565–573
2018
-
[43]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems. 5998–6008
2017
-
[44]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. InProceedings of the ADKDD’17. 1–7
2017
-
[45]
Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed H
Ruoxi Wang, Rakesh Shivanna, Derek Z. Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed H. Chi. 2021. DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems. InProceedings of the Web Conference. 1785–1795
2021
-
[46]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Gen- erative Recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep Interest Evolution Network for Click-Through Rate Prediction. InProceedings of the AAAI Conference on Artificial Intelligence. 5941–5948
2019
-
[48]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click- Through Rate Prediction. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1059–1068. 12 LENS: A Staged Design for Interaction Granularity in Sequential...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.