An LLM-Based System for Argument Reconstruction
Pith reviewed 2026-05-14 19:07 UTC · model grok-4.3
Add this Pith Number to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{HVR6JYBJ}
Prints a linked pith:HVR6JYBJ badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
An LLM pipeline reconstructs natural language text into argument graphs with premises, conclusions, and support, attack or undercut relations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The end-to-end LLM-based system follows a multi-stage pipeline that progressively identifies argumentative components, selects relevant elements, and uncovers their logical relations. These are represented as directed acyclic graphs consisting of premises and conclusions connected by support, attack, or undercut relations. Manual checks on textbook arguments confirm adequate recovery of structure, while tests on benchmark datasets show reasonable performance once outputs are mapped to existing annotation schemes.
What carries the argument
The multi-stage LLM pipeline that identifies components, selects elements, and determines support, attack, or undercut relations to form directed acyclic argument graphs.
If this is right
- Argument reconstruction scales to larger text collections without manual annotation at every step.
- The same pipeline can be adapted to match different existing annotation schemes for direct comparison with prior methods.
- Graphs with attack and undercut relations become available for downstream tasks such as summarization or evaluation.
- Performance holds across benchmark datasets once outputs are aligned to the target scheme.
Where Pith is reading between the lines
- The graphs could feed into tools that track how arguments evolve across multiple documents or debates.
- Further tests on noisy sources such as social media threads would show whether the pipeline needs extra safeguards.
- Combining the output graphs with automated evaluation metrics might allow real-time feedback on argument strength.
Load-bearing premise
The multi-stage LLM pipeline reliably identifies argumentative components and their relations without systematic human correction or domain-specific fine-tuning beyond the described prompting.
What would settle it
A fresh manual comparison on 50 textbook arguments where the system outputs are checked against expert annotations and show repeated errors in choosing undercut relations over support or attack.
Figures



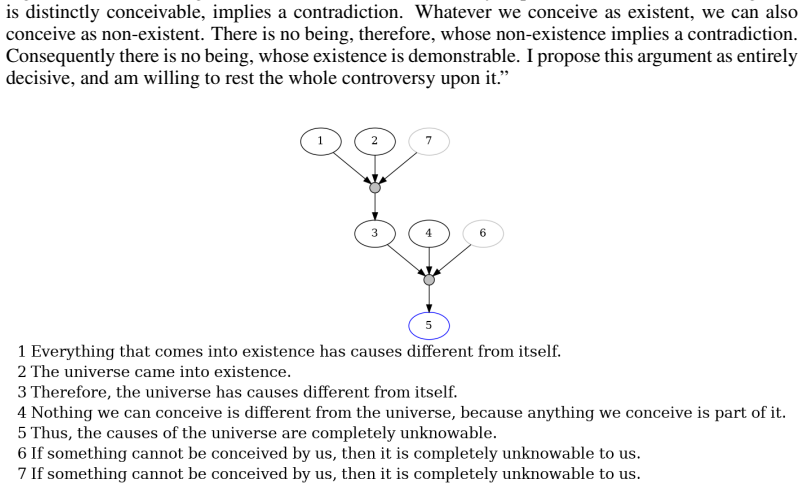


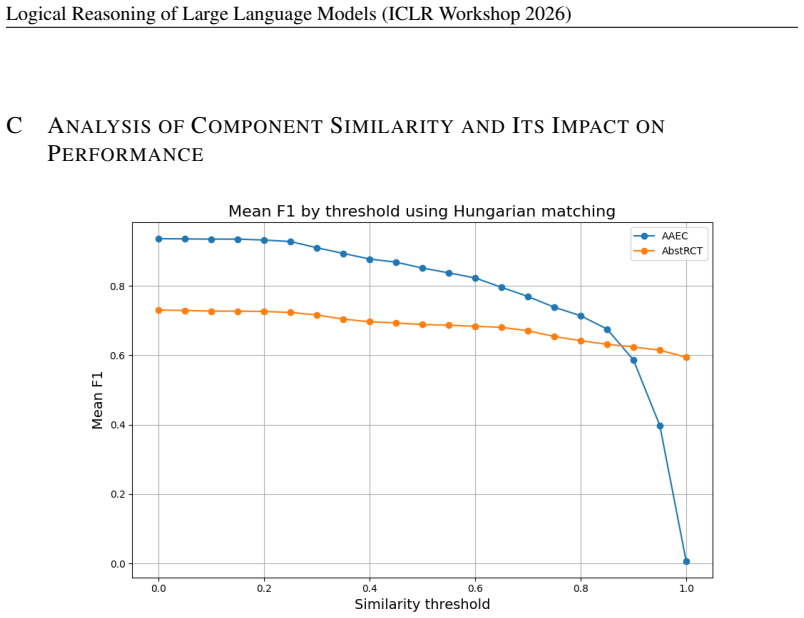
read the original abstract
Arguments are a fundamental aspect of human reasoning, in which claims are supported, challenged, and weighed against one another. We present an end-to-end large language model (LLM)-based system for reconstructing arguments from natural language text into abstract argument graphs. The system follows a multi-stage pipeline that progressively identifies argumentative components, selects relevant elements, and uncovers their logical relations. These elements are represented as directed acyclic graphs consisting of two component types (premises and conclusions) and three relation types (support, attack, and undercut). We conduct two complementary experiments to evaluate the system. First, we perform a manual evaluation on arguments drawn from an argumentation theory textbook to assess the system's ability to recover argumentative structure. Second, we conduct a quantitative evaluation on benchmark datasets, allowing comparison with prior work by mapping our outputs to established annotation schemes. Results show that the system can adequately recover argumentative structures and, when adapted to different annotation schemes, achieve reasonable performance across benchmark datasets. These findings highlight the potential of LLM-based pipelines for scalable argument reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an end-to-end LLM-based multi-stage pipeline for reconstructing arguments from natural language text into directed acyclic graphs consisting of premises and conclusions connected by support, attack, and undercut relations. It evaluates the system through a manual assessment on arguments from an argumentation theory textbook and a quantitative evaluation on benchmark datasets, where outputs are mapped to established annotation schemes. The central claim is that the system adequately recovers argumentative structures and achieves reasonable performance across benchmarks when adapted to different schemes.
Significance. If the reported results hold with sufficient quantitative backing, the work would demonstrate a flexible, prompt-based approach to argument reconstruction that avoids domain-specific fine-tuning and adapts across annotation schemes. This could support scalable applications in computational argumentation, provided the pipeline's reliability is more rigorously quantified.
major comments (2)
- [Quantitative evaluation] Quantitative evaluation section: The claim of 'reasonable performance across benchmark datasets' after mapping outputs to prior schemes is stated without any specific metrics (e.g., precision, recall, F1), error analysis, failure mode breakdown, or details on the mapping procedure and prompt engineering choices. This leaves the central performance claim only loosely supported, as noted in the abstract's description of complementary experiments.
- [Manual evaluation] Manual evaluation description: The manual recovery assessment on textbook arguments is described only at a high level ('assess the system's ability to recover argumentative structure') without reporting inter-annotator agreement, specific success/failure rates, or examples of recovered graphs versus ground truth. This makes it difficult to evaluate the adequacy claim for the multi-stage pipeline.
minor comments (1)
- [Abstract and introduction] The abstract and introduction could more explicitly define the three relation types (support, attack, undercut) and the DAG constraints to improve accessibility for readers unfamiliar with argumentation theory.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate planned revisions to strengthen the quantitative and manual evaluation sections.
read point-by-point responses
-
Referee: Quantitative evaluation section: The claim of 'reasonable performance across benchmark datasets' after mapping outputs to prior schemes is stated without any specific metrics (e.g., precision, recall, F1), error analysis, failure mode breakdown, or details on the mapping procedure and prompt engineering choices. This leaves the central performance claim only loosely supported, as noted in the abstract's description of complementary experiments.
Authors: We agree that the quantitative evaluation would be strengthened by explicit metrics and supporting details. In the revised manuscript we will add precision, recall, and F1 scores for the mapped benchmark results, include an error analysis and failure-mode breakdown, and expand the description of the mapping procedure and prompt-engineering choices used to adapt outputs to prior annotation schemes. revision: yes
-
Referee: Manual evaluation description: The manual recovery assessment on textbook arguments is described only at a high level ('assess the system's ability to recover argumentative structure') without reporting inter-annotator agreement, specific success/failure rates, or examples of recovered graphs versus ground truth. This makes it difficult to evaluate the adequacy claim for the multi-stage pipeline.
Authors: The manual evaluation was presented at a high level to illustrate qualitative recovery of argumentative structure. We will revise this section to report inter-annotator agreement, specific success and failure rates, and concrete examples of recovered graphs compared against ground-truth structures from the textbook arguments. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical multi-stage LLM pipeline for argument reconstruction, with manual evaluation on textbook examples and quantitative mapping to external benchmark datasets. No equations, fitted parameters, or derivations appear; the central claims rest on independent performance metrics against established annotation schemes rather than any self-referential reduction or self-citation load-bearing step. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gerhard Brewka, Sylwia Polberg, and Stefan Woltran. Abstract dialectical frameworks.Proceedings of the Twelfth International Conference on Principles of Knowledge Representation and Reason- ing (KR 2010), pp. 102–111,
work page 2010
-
[2]
Claudette Cayrol and Marie-Christine Lagasquie-Schiex. On the acceptability of arguments in bipo- lar argumentation frameworks.Proceedings of the Eighth European Conference on Symbolic and Quantitative Approaches to Reasoning with Uncertainty (ECSQARU 2005), pp. 378–389,
work page 2005
-
[3]
Yanran Chen and Steffen Eger. Do emotions really affect argument convincingness? a dynamic approach with LLM-based manipulation checks. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.),Findings of the Association for Computational Linguistics: ACL 2025, pp. 24357–24381, Vienna, Austria, July
work page 2025
-
[4]
Association for Computa- tional Linguistics. ISBN 979-8-89176-256-5. Kaustubh Dhole, Kai Shu, and Eugene Agichtein. ConQRet: A new benchmark for fine-grained au- tomatic evaluation of retrieval augmented computational argumentation. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.),Proceedings of the 2025 Conference of the Nations of the Americas Chapter ...
work page 2025
-
[5]
Which side are you on? a multi-task dataset for end-to-end argument summarisation and evaluation
Hao Li, Yuping Wu, Viktor Schlegel, Riza Batista-Navarro, Tharindu Madusanka, Iqra Zahid, Ji- ayan Zeng, Xiaochi Wang, Xinran He, Yizhi Li, and Goran Nenadic. Which side are you on? a multi-task dataset for end-to-end argument summarisation and evaluation. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.),Findings of the Association for Computationa...
work page 2024
-
[6]
Hao Li, Viktor Schlegel, Yizheng Sun, Riza Batista-Navarro, and Goran Nenadic
Association for Computational Lin- guistics. Hao Li, Viktor Schlegel, Yizheng Sun, Riza Batista-Navarro, and Goran Nenadic. Large language models in argument mining: A survey.arXiv preprint arXiv:2506.16383,
-
[7]
Transformer-based argument mining for healthcare applications
Tobias Mayer, Elena Cabrio, and Serena Villata. Transformer-based argument mining for healthcare applications. InECAI 2020, pp. 2108–2115. IOS Press,
work page 2020
-
[8]
Dissecting Content and Context in Argumentative Relation Analysis
Juri Opitz and Anette Frank. Dissecting content and context in argumentative relation analysis. arXiv preprint arXiv:1906.03338,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[9]
A corpus of erulemaking user comments for measuring evaluability of arguments
Joonsuk Park and Claire Cardie. A corpus of erulemaking user comments for measuring evaluability of arguments. InProceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018),
work page 2018
-
[10]
Show me your evidence-an automatic method for context dependent evidence detection
Ruty Rinott, Lena Dankin, Carlos Alzate, Mitesh M Khapra, Ehud Aharoni, and Noam Slonim. Show me your evidence-an automatic method for context dependent evidence detection. InPro- ceedings of the 2015 conference on empirical methods in natural language processing, pp. 440– 450,
work page 2015
-
[11]
Unsu- pervised expressive rules provide explainability and assist human experts grasping new domains
Eyal Shnarch, Leshem Choshen, Guy Moshkowich, Noam Slonim, and Ranit Aharonov. Unsu- pervised expressive rules provide explainability and assist human experts grasping new domains. arXiv preprint arXiv:2010.09459,
-
[12]
URLhttps: //arxiv.org/abs/2601.03267. Christian Stab and Iryna Gurevych. Parsing argumentation structures in persuasive essays.Compu- tational Linguistics, 43(3):619–659,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.