Gradient-Free Warm-Start Library Recovery: an Amortized-Regret Separation
Pith reviewed 2026-06-26 14:53 UTC · model grok-4.3
The pith
A warm-start library learner attains amortized recovery cost O(KD/ε²+(R-K)logK/Δ²) versus Θ(RD/ε²) for memoryless re-estimation on recurring streams with given segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given segmentation of the stream into regimes, the warm-start library learner attains an amortized recovery cost of O(KD/ε²+(R-K)logK/Δ²) versus a memoryless re-estimator's Θ(RD/ε²), because regime recognition costs O(log K/Δ²) independent of D whereas regime estimation costs Θ(D/ε²); matching lower bounds establish that each term is individually minimax-tight.
What carries the argument
Decoupling of regime recognition, which costs O(log K/Δ²) and is independent of dimension, from regime estimation, which costs Θ(D/ε²).
If this is right
- The advantage scales with dimension D and recurrence density (R-K).
- Recognition is Θ(log K/Δ²) and memoryless estimation is Ω(RD/ε²) in the worst case.
- The method requires no end-to-end backprop and guarantees zero forgetting by construction.
- A count-calibrated variant matches the leading constant of a Bayesian baseline up to bounded overshoot.
Where Pith is reading between the lines
- If regimes are well-separated, library methods could support efficient continual learning on resource-constrained devices without gradients.
- High-dimensional data with many distinct regimes may benefit most from this separation, up to the simplex packing limit of e^Θ(D) regimes.
- The cost structure might generalize to other local, online learners that can store and recall past estimates.
Load-bearing premise
The input stream is externally segmented into regimes that remain separated by a minimum distance Δ allowing cheap recognition.
What would settle it
Run the library learner and a memoryless re-estimator on a synthetic stream with known segmentation, R recurrences of K regimes, and measure whether the amortized costs match the stated bounds as D and R vary.
Figures

read the original abstract
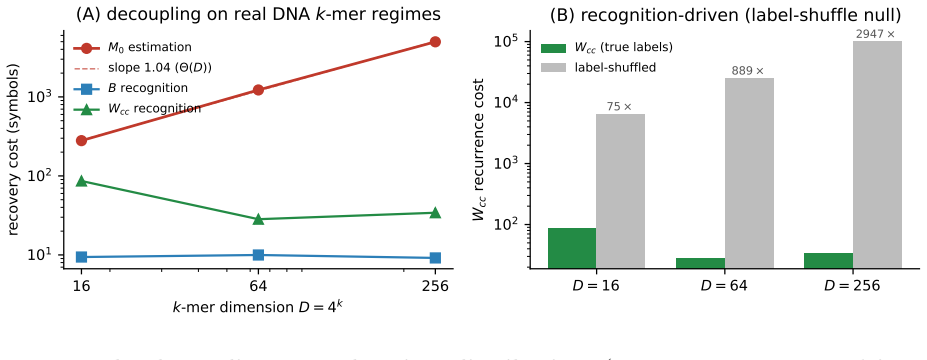
Continual learning that is gradient-free, local, online, and append-only is attractive for edge and streaming deployment, but its value is usually argued informally. We give a provable account on recurring-regime streams. Given segmentation, a warm-start library learner attains amortized recovery cost $O\!\big(KD/\varepsilon^2+(R-K)\logK/\Delta^2\big)$ versus a memoryless re-estimator's $\Theta(RD/\varepsilon^2)$, an advantage $(R-K)\,\Theta(D/\varepsilon^2)$ growing with dimension $D$ and recurrence density. The mechanism is a decoupling: recognizing which of $K$ seen regimes is active costs $O(\log K/\Delta^2)$, independent of $D$, whereas estimating a regime costs $\Theta(D/\varepsilon^2)$. We prove this is tight: matching lower bounds give recognition $\Theta(\log K/\Delta^2)$ and a memoryless-class bound $\Omega(RD/\varepsilon^2)$, so each term is individually minimax-tight (the joint statement is conditional). The separation is born-immune (a memoryless learner's advantage is identically zero) and paradigm-level: it matches, and does not beat, a fair spawn-capable Bayesian baseline; the contribution is attaining this cost structure without end-to-end backprop and with zero forgetting by construction. A count-calibrated variant ties the baseline's leading constant up to a bounded, never-negative per-recurrence overshoot, hyperparameter-free and with no per-step transcendentals. We bound the scope: recognizable regimes are capped by simplex packing (walls $e^{\Theta(D)}$); autonomous segmentation is impossible at the packing wall (no detector escapes the false-alarm/delay frontier as regimes overlap); the advantage vanishes under overlap. The dimension-dependent separation is corroborated on synthetic streams and real $k$-mer genome distributions (memoryless cost $\propto D^{1.04}$, recognition $D$-independent); the one real sequential stream sits in the $D{=}1$ near-null corner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript provides a theoretical analysis of gradient-free, local, online, append-only continual learning on recurring-regime streams. Conditional on externally supplied segmentation into K well-separated regimes (minimum distance Δ), it claims that a warm-start library learner attains amortized recovery cost O(KD/ε² + (R-K)logK/Δ²) versus Θ(RD/ε²) for a memoryless re-estimator, yielding advantage (R-K)Θ(D/ε²) that grows with dimension D and recurrence density. The separation arises from decoupling recognition (O(logK/Δ²), D-independent) from estimation (Θ(D/ε²)); matching lower bounds establish individual minimax tightness (joint bound conditional). The result is birth-immune, matches but does not beat a fair Bayesian baseline, and is hyperparameter-free in a count-calibrated variant. Scope is bounded by simplex packing (recognizable regimes ≲ e^Θ(D)); autonomous segmentation is impossible at the packing wall and the advantage vanishes under overlap. Empirical corroboration is given on synthetic streams and real k-mer genome data.
Significance. If the derivations hold, the work supplies a rigorous, paradigm-level cost separation for library-based warm-start recovery in continual learning without gradients or forgetting. Explicit matching lower bounds, the D-dependent advantage, the birth-immune property, and the hyperparameter-free variant are concrete strengths. The scope analysis (packing wall, overlap) and empirical scaling (memoryless cost ∝ D^1.04, recognition D-independent) add value for edge/streaming settings.
minor comments (3)
- [Abstract] Abstract: the symbols R, K, D, ε, Δ are used in the cost expressions without an immediate parenthetical definition; a one-sentence glossary on first appearance would aid readability.
- [Experiments] Empirical section: the description of error-bar handling, data-exclusion rules, and the precise synthetic-stream generation protocol is not fully detailed in the visible material; adding these would strengthen reproducibility.
- [Main theorems] Notation: the distinction between the joint upper bound (conditional) and the individually tight lower bounds could be restated once in the main theorem statement for emphasis.
Simulated Author's Rebuttal
We thank the referee for the accurate and positive summary of the manuscript together with the recommendation of minor revision. No specific major comments appear in the report.
Circularity Check
No significant circularity detected
full rationale
The paper's central bounds are derived from standard concentration and minimax arguments applied to externally supplied segmentation into regimes separated by Δ. Recognition cost decouples as O(log K / Δ²) independent of D while estimation remains Θ(D / ε²); the amortized expressions and lower bounds follow directly without reducing to fitted parameters or self-referential definitions inside the paper. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear. The analysis is explicitly conditional on the segmentation assumption and states that the advantage vanishes under overlap, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard concentration inequalities suffice to bound regime recognition at O(log K / Δ²) and regime estimation at Θ(D / ε²)
Reference graph
Works this paper leans on
-
[1]
Michael McCloskey and Neal J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of Learning and Motivation, volume 24, pages 109–165. Academic Press, 1989
1989
-
[2]
Parisi, Ronald Kemker, Jose L
German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71, 2019
2019
-
[3]
Cambridge University Press
Nicol` o Cesa-Bianchi and G´ abor Lugosi.Prediction, Learning, and Games. Cambridge University Press. Cambridge University Press, Cambridge, 2006
2006
-
[4]
Hicl: Hippocampal- inspired continual learning.arXiv preprint arXiv:2508.16651, 2025
Kushal Kapoor, Wyatt Mackey, Yiannis Aloimonos, and Xiaomin Lin. Hicl: Hippocampal- inspired continual learning.arXiv preprint arXiv:2508.16651, 2025
-
[5]
Weinberger
Tsachy Weissman, Erik Ordentlich, Gadiel Seroussi, Sergio Verd´ u, and Marcelo J. Weinberger. Inequalities for the L1 deviation of the empirical distribution.Hewlett-Packard Labs Technical Report, HPL-2003-97R1, 2003. Technical report
2003
-
[6]
Tsybakov.Introduction to Nonparametric Estimation
Alexandre B. Tsybakov.Introduction to Nonparametric Estimation. Springer Series in Statistics. Springer, New York, 2009
2009
-
[7]
Ryan Prescott Adams and David J. C. MacKay. Bayesian online changepoint detection.arXiv preprint arXiv:0710.3742, 2007
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[8]
Jianwei Lou. Persistent memory through triple-loop consolidation in a non-gradient dissipative cognitive architecture.arXiv preprint arXiv:2603.27188, 2026. Under review, Frontiers in Computational Neuroscience. 11
-
[9]
John Wiley & Sons, New York, 1947
Abraham Wald.Sequential Analysis. John Wiley & Sons, New York, 1947
1947
-
[10]
Dragalin, Alexander G
Vladimir P. Dragalin, Alexander G. Tartakovsky, and Venugopal V. Veeravalli. Multihypothesis sequential probability ratio tests — Part I: Asymptotic optimality.IEEE Transactions on Information Theory, 45(7):2448–2461, 1999
1999
-
[11]
A measure of asymptotic efficiency for tests of a hypothesis based on the sum of observations.The Annals of Mathematical Statistics, 23(4):493–507, 1952
Herman Chernoff. A measure of asymptotic efficiency for tests of a hypothesis based on the sum of observations.The Annals of Mathematical Statistics, 23(4):493–507, 1952
1952
-
[12]
Estimation des densit´ es: risque minimax.Zeitschrift f¨ ur Wahrscheinlichkeitstheorie und Verwandte Gebiete, 47:119–137, 1979
Jean Bretagnolle and Catherine Huber. Estimation des densit´ es: risque minimax.Zeitschrift f¨ ur Wahrscheinlichkeitstheorie und Verwandte Gebiete, 47:119–137, 1979
1979
-
[13]
Edgar N. Gilbert. A comparison of signalling alphabets.The Bell System Technical Journal, 31(3):504–522, 1952
1952
-
[14]
Varshamov
Rom R. Varshamov. Estimate of the number of signals in error correcting codes.Doklady Akademii Nauk SSSR, 117:739–741, 1957
1957
-
[15]
Kabatiansky and Vladimir I
Grigorii A. Kabatiansky and Vladimir I. Levenshtein. Bounds for packings on a sphere and in space.Problems of Information Transmission, 14(1):1–17, 1978
1978
-
[16]
Beal, Zoubin Ghahramani, and Carl Edward Rasmussen
Matthew J. Beal, Zoubin Ghahramani, and Carl Edward Rasmussen. The infinite hidden Markov model. InAdvances in Neural Information Processing Systems, volume 14, pages 577–584, 2002
2002
-
[17]
Fox, Erik B
Emily B. Fox, Erik B. Sudderth, Michael I. Jordan, and Alan S. Willsky. A sticky HDP-HMM with application to speaker diarization.The Annals of Applied Statistics, 5(2A):1020–1056, 2011
2011
-
[18]
The infinite gaussian mixture model.Advances in Neural Information Processing Systems, 12, 2000
Carl Edward Rasmussen. The infinite gaussian mixture model.Advances in Neural Information Processing Systems, 12, 2000. In NIPS 12
2000
-
[19]
Procedures for reacting to a change in distribution.The Annals of Mathematical Statistics, 42(6):1897–1908, 1971
Gary Lorden. Procedures for reacting to a change in distribution.The Annals of Mathematical Statistics, 42(6):1897–1908, 1971
1908
-
[20]
Moustakides
George V. Moustakides. Quickest detection of abrupt changes for a class of random processes. IEEE Transactions on Information Theory, 44(5):1965–1968, 1998
1965
-
[21]
Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic for- getting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3...
2017
-
[22]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems, volume 30, pages 6467–6476, 2017
2017
-
[23]
Standardized and reproducible measurement of decision- making in mice.eLife, 10:e63711, 2021
The International Brain Laboratory. Standardized and reproducible measurement of decision- making in mice.eLife, 10:e63711, 2021
2021
-
[24]
A stochastic approximation method.The Annals of Mathematical Statistics, 22(3):400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.The Annals of Mathematical Statistics, 22(3):400–407, 1951. 12
1951
-
[25]
McClelland, Bruce L
James L. McClelland, Bruce L. McNaughton, and Randall C. O’Reilly. Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory.Psychological Review, 102(3):419– 457, 1995
1995
-
[26]
McClelland
Dharshan Kumaran, Demis Hassabis, and James L. McClelland. What learning systems do intelligent agents need? Complementary learning systems theory updated.Trends in Cognitive Sciences, 20(7):512–534, 2016
2016
- [27]
-
[28]
Equilibrium propagation: Bridging the gap between energy-based models and backpropagation.Frontiers in Computational Neuroscience, 11:24, 2017
Benjamin Scellier and Yoshua Bengio. Equilibrium propagation: Bridging the gap between energy-based models and backpropagation.Frontiers in Computational Neuroscience, 11:24, 2017
2017
-
[29]
A model of inductive bias learning.Journal of Artificial Intelligence Research, 12:149–198, 2000
Jonathan Baxter. A model of inductive bias learning.Journal of Artificial Intelligence Research, 12:149–198, 2000
2000
-
[30]
The benefit of multitask representation learning.Journal of Machine Learning Research, 17(81):1–32, 2016
Andreas Maurer, Massimiliano Pontil, and Bernardino Romera-Paredes. The benefit of multitask representation learning.Journal of Machine Learning Research, 17(81):1–32, 2016
2016
-
[31]
Cl´ ement L. Canonne. A survey on distribution testing: Your data is big. but is it blue?Theory of Computing, (9):1–100, 2020
2020
-
[32]
Omar Fawzi, Nicolas Flammarion, Aur´ elien Garivier, and Aadil Oufkir. Sequential algorithms for testing identity and closeness of distributions.arXiv preprint arXiv:2205.06069, 2022
-
[33]
Information bounds and quick detection of parameter changes in stochastic systems.IEEE Transactions on Information Theory, 44(7):2917–2929, 1998
Tze Leung Lai. Information bounds and quick detection of parameter changes in stochastic systems.IEEE Transactions on Information Theory, 44(7):2917–2929, 1998
1998
-
[34]
Igal Sason. An improved reverse pinsker inequality for probability distributions on a finite set. arXiv preprint arXiv:1503.03417, 2015. A Proofs Proof of Lemma 1. Writebθn for the empirical histogram from n i.i.d. draws from θ∈ ∆D−1. Since TV(bθn, θ) = 1 2 ∥bθn −θ∥ 1, the Weissmanℓ 1 tail bound [5] gives Pr θ TV(bθn, θ)> ε = Pr θ ∥bθn −θ∥ 1 >2ε ≤(2 D −2)...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[35]
, K}isF τ-measurable
bJ∈ {1, . . . , K}isF τ-measurable
-
[36]
, qK}lies in the simplex interior and satisfies min i̸=j TV(qi, qj)≥∆
the library{q 1, . . . , qK}lies in the simplex interior and satisfies min i̸=j TV(qi, qj)≥∆
-
[37]
recognition
the maximal error is controlled uniformly: sup j Pj(bJ̸=j)≤δ, for some fixedδ <1/2. The theorem concerns inf (τ, bJ)∈S(K,∆,δ) sup 1≤j≤K Ejτ. Step 1: the1/∆ 2 factor.Take two Bernoulli laws q0 = ( 1 2 + ∆, 1 2 −∆), q 1 = ( 1 2 −∆, 1 2 + ∆), which satisfy TV(q0, q1) = ∆ for ∆ < 1/2. For any sequential test with P0(bJ̸ = 0) ∨P 1(bJ̸ = 1) ≤δ , the standard ch...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.