Clinically Structured Rank-Gated LoRA for Cross-Benchmark Medical Question Answering
Pith reviewed 2026-07-01 05:52 UTC · model grok-4.3
The pith
A biaxial gate makes LoRA rank input-conditioned by clinical priors and achieves top macro-average accuracy on four medical QA benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
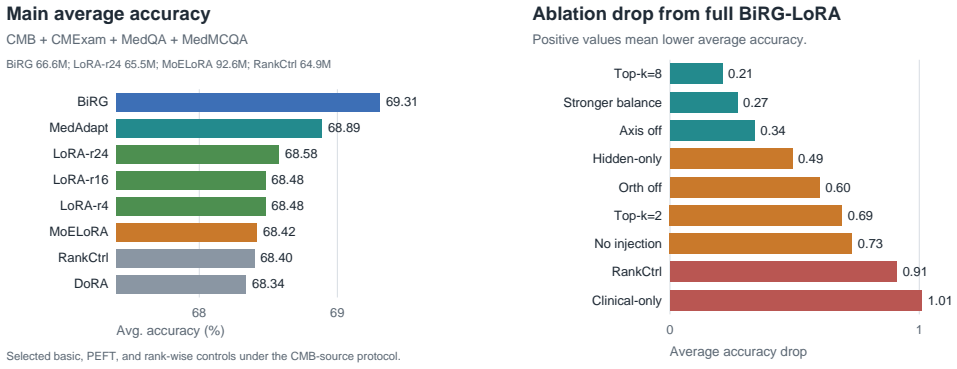
BiRG-LoRA keeps one LoRA module per target layer but makes its rank dimension input-conditioned: for each question, a biaxial gate combines hidden semantic evidence with specialty/profession priors, clinical-operation priors, and their interaction to select a sparse top-k subset of rank atoms. A scalar injection coefficient further controls the strength of the selected adapter update. Under a matched Qwen3-8B CMB-source protocol, BiRG-LoRA achieves the highest four-benchmark macro-average accuracy among trainable PEFT baselines and matched routing controls at 69.31 percent averaged over CMB, CMExam, MedQA, and MedMCQA, improving over MoELoRA by 0.89 percentage points while using 28.1 percent
What carries the argument
The biaxial gate that combines hidden semantic evidence with specialty/profession priors, clinical-operation priors, and their interaction to select a sparse top-k subset of rank atoms for each input question.
If this is right
- Clinically structured rank allocation improves cross-benchmark medical QA accuracy under a matched single-seed protocol.
- The method reaches 69.31 percent macro-average while using 28.1 percent fewer trainable parameters than MoELoRA.
- BiRG-LoRA outperforms vanilla LoRA r16 and active-rank-matched LoRA r4 by 0.83 macro points.
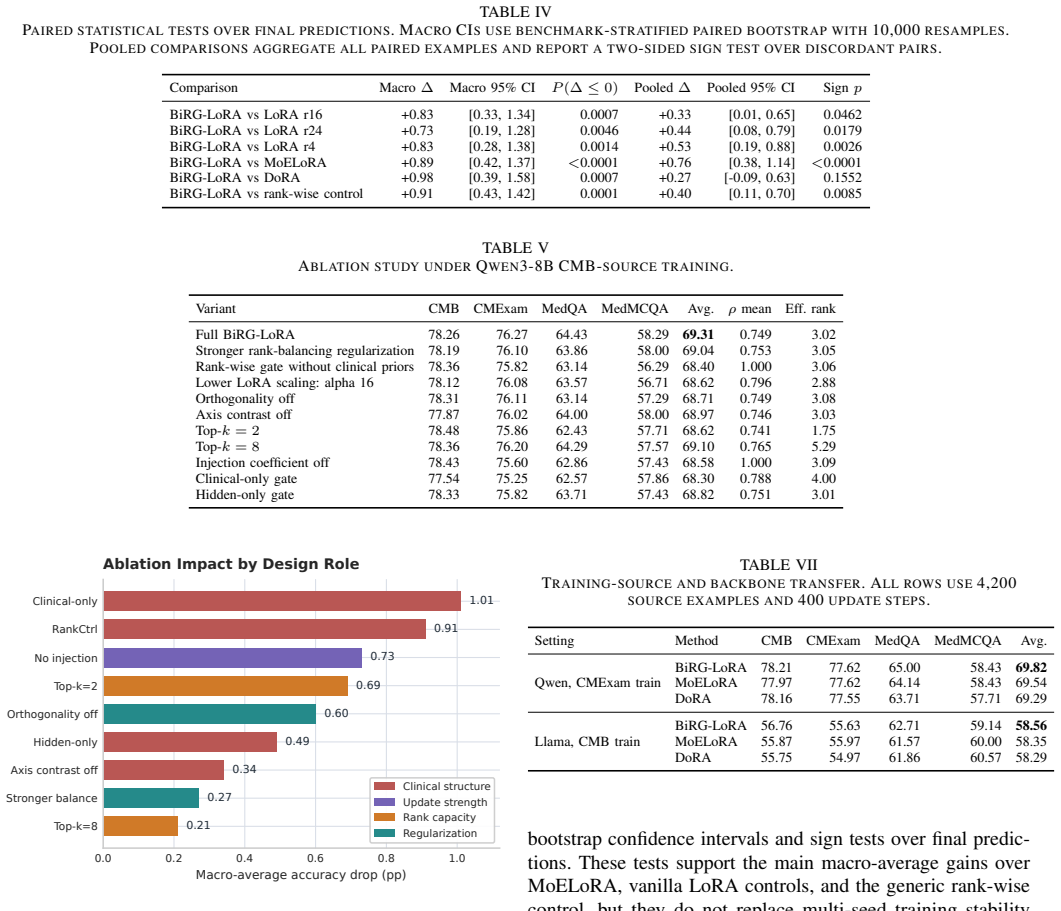
- An evaluation-time weak-axis perturbation check indicates performance is not brittle to moderate tag noise.
Where Pith is reading between the lines
- The same gating idea could be tested on non-medical tasks that also have structured domain priors, such as legal or financial question answering.
- Reporting results across multiple random seeds would clarify whether the observed gain is stable beyond the single-seed protocol used here.
- The scalar injection coefficient might be made input-dependent as well to further reduce unnecessary updates on recall-heavy items.
Load-bearing premise
The biaxial gate can reliably select a useful sparse top-k subset of rank atoms for each input question by combining hidden semantic evidence with clinical priors.
What would settle it
Replacing the biaxial gate with random rank selection or a fixed non-gated rank while keeping all other factors matched produces no gain or a loss on the four-benchmark macro-average.
Figures

read the original abstract
Medical multiple-choice question answering requires parameter-efficient adaptation across heterogeneous knowledge domains and reasoning operations. A medication question, a diagnostic decision, a public-health item, and a nursing-action item may require different low-rank updates, while some recall items should preserve the base model's representation with only mild adapter intervention. We propose BiRG-LoRA, a single-adapter rank-gated LoRA method for medical question answering. BiRG-LoRA keeps one LoRA module per target layer but makes its rank dimension input-conditioned: for each question, a biaxial gate combines hidden semantic evidence with specialty/profession priors, clinical-operation priors, and their interaction to select a sparse top-$k$ subset of rank atoms. A scalar injection coefficient further controls the strength of the selected adapter update. Under a matched Qwen3-8B CMB-source protocol, BiRG-LoRA achieves the highest four-benchmark macro-average accuracy among trainable PEFT baselines and matched routing controls: 69.31% averaged over CMB, CMExam, MedQA, and MedMCQA. It improves over MoELoRA by 0.89 percentage points while using 28.1% fewer trainable parameters; a paired, benchmark-stratified bootstrap over final predictions gives a 95% confidence interval of [0.42, 1.37] for this macro-average gain. Basic controls show that BiRG-LoRA also improves over vanilla LoRA r16 and active-rank-matched LoRA r4 by 0.83 macro points, and an evaluation-time weak-axis perturbation check suggests that performance is not brittle to moderate tag noise. The results support a bounded claim: clinically structured rank allocation improves cross-benchmark medical QA under a matched single-seed protocol, while training-seed variance remains future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BiRG-LoRA, a single-adapter rank-gated LoRA variant for medical MCQA. For each input question, a biaxial gate fuses hidden semantic features with specialty/profession priors, clinical-operation priors, and their interaction to select a sparse top-k subset of rank atoms from a shared LoRA module; a scalar injection coefficient modulates update strength. Under a matched Qwen3-8B protocol, BiRG-LoRA reports the highest four-benchmark macro-average (69.31% on CMB, CMExam, MedQA, MedMCQA), a 0.89 pp gain over MoELoRA (bootstrap CI [0.42, 1.37]) with 28.1% fewer trainable parameters, plus improvements over vanilla LoRA r=16 and active-rank LoRA r=4; an evaluation-time perturbation check is included. The central claim is bounded to a single-seed protocol with training-seed variance noted as future work.
Significance. If the empirical result holds under the stated controls, the work supplies concrete evidence that clinically structured, input-conditioned rank allocation can improve cross-benchmark medical QA while reducing parameter count relative to MoELoRA. The bootstrap CI, matched baselines, and weak-axis perturbation check strengthen the bounded claim; the single-seed limitation is explicitly acknowledged.
minor comments (3)
- [Abstract / Method description] The abstract states that the biaxial gate 'combines hidden semantic evidence with specialty/profession priors, clinical-operation priors, and their interaction,' but does not specify the exact functional form of the interaction term or the top-k selection operator; a short methods subsection or equation would clarify reproducibility.
- [Results paragraph] The reported macro-average gain carries a paired benchmark-stratified bootstrap CI, yet the number of bootstrap replicates and the exact stratification procedure are not stated; adding these details would allow readers to assess CI stability.
- [Results] The claim of '28.1% fewer trainable parameters' is useful, but the absolute parameter counts for BiRG-LoRA versus MoELoRA (and the two LoRA controls) should be tabulated for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, accurate summary of BiRG-LoRA, and recommendation of minor revision. The report correctly notes our bounded single-seed claim and the explicit acknowledgment of training-seed variance as future work.
Circularity Check
No significant circularity; empirical result on held-out benchmarks
full rationale
The paper reports an empirical performance comparison of BiRG-LoRA against baselines on four medical QA benchmarks under a matched single-seed protocol. The central claim is a measured macro-average accuracy gain (0.89 pp over MoELoRA) with bootstrap CI, plus controls for parameter count and perturbation. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or method description that would reduce the reported result to its own inputs by construction. The derivation chain consists of a proposed architecture followed by standard training and evaluation; the result is falsifiable against external benchmarks and does not rely on internal re-derivation of its own metrics.
Axiom & Free-Parameter Ledger
free parameters (2)
- top-k subset size
- scalar injection coefficient
axioms (2)
- domain assumption Low-rank updates suffice for task adaptation
- ad hoc to paper Clinical specialty and operation priors are sufficiently informative for rank gating
invented entities (2)
-
Biaxial gate
no independent evidence
-
Rank atoms
no independent evidence
Reference graph
Works this paper leans on
-
[1]
CMB: A comprehensive medical benchmark in chinese,
X. Wang, G. H. Chen, D. Song, Z. Zhang, Z. Chen, Q. Xiao, F. Jiang, J. Li, X. Wan, B. Wang, and H. Li, “CMB: A comprehensive medical benchmark in chinese,” 2024. [Online]. Available: https://arxiv.org/abs/2308.08833
-
[2]
Benchmarking large language models on CMExam: A comprehensive chinese medical exam dataset,
J. Liu, P. Zhou, Y . Hua, D. Chong, Z. Tian, A. Liu, H. Wang, C. You, Z. Guo, L. Zhu, and M. L. Li, “Benchmarking large language models on CMExam: A comprehensive chinese medical exam dataset,” 2023. [Online]. Available: https://arxiv.org/abs/2306.03030
-
[3]
D. Jin, E. Pan, N. Oufattole, W.-H. Weng, H. Fang, and P. Szolovits, “What disease does this patient have? a large-scale open domain question answering dataset from medical exams,” 2020. [Online]. Available: https://arxiv.org/abs/2009.13081
-
[4]
MedMCQA: A large- scale multi-subject multi-choice dataset for medical domain question answering,
A. Pal, L. K. Umapathi, and M. Sankarasubbu, “MedMCQA: A large- scale multi-subject multi-choice dataset for medical domain question answering,” inProceedings of the Conference on Health, Inference, and Learning, ser. Proceedings of Machine Learning Research, vol. 174. PMLR, 2022, pp. 248–260
2022
-
[5]
Towards modular LLMs by building and reusing a library of LoRAs,
O. Ostapenko, Z. Su, E. Ponti, L. Charlin, N. Le Roux, L. Caccia, and A. Sordoni, “Towards modular LLMs by building and reusing a library of LoRAs,” inForty-first International Conference on Machine Learning, 2024. [Online]. Available: https://openreview.net/forum?id= 0ZFWfeVsaD
2024
-
[6]
MedAdapter: Efficient test-time adaptation of large language models towards medical reasoning,
W. Shi, R. Xu, Y . Zhuang, Y . Yu, H. Sun, H. Wu, C. Yang, and M. D. Wang, “MedAdapter: Efficient test-time adaptation of large language models towards medical reasoning,” 2024. [Online]. Available: https://arxiv.org/abs/2405.03000
-
[7]
MeteoRA: Multiple-tasks embedded LoRA for large language models,
J. Xu, J. Lai, and Y . Huang, “MeteoRA: Multiple-tasks embedded LoRA for large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2405.13053
-
[8]
LoRA-Mixer: Coordinate modular LoRA experts through serial attention routing,
W. Li, Z. Song, H. Zhou, Y . Zhang, J. Yu, and W. Yang, “LoRA-Mixer: Coordinate modular LoRA experts through serial attention routing,”
-
[9]
LoRA-Mixer: Coordinate Modular LoRA Experts Through Serial Attention Routing
[Online]. Available: https://arxiv.org/abs/2507.00029
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
T. Luo, J. Lei, F. Lei, W. Liu, S. He, J. Zhao, and K. Liu, “MoELoRA: Contrastive learning guided mixture of experts on parameter-efficient fine-tuning for large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2402.12851
-
[11]
MixLoRA: Enhancing large language models fine-tuning with LoRA-based mixture of experts,
D. Li, Y . Ma, N. Wang, Z. Ye, Z. Cheng, Y . Tang, Y . Zhang, L. Duan, J. Zuo, C. Yang, and M. Tang, “MixLoRA: Enhancing large language models fine-tuning with LoRA-based mixture of experts,”
-
[12]
Available: https://arxiv.org/abs/2404.15159
[Online]. Available: https://arxiv.org/abs/2404.15159
-
[13]
Y . Liao, S. Jiang, Y . Wang, and Y . Wang, “MING-MOE: Enhancing medical multi-task learning in large language models with sparse mixture of low-rank adapter experts,” 2024. [Online]. Available: https://arxiv.org/abs/2404.09027
-
[14]
X. Wu, S. Huang, and F. Wei, “Mixture of LoRA experts,” 2024. [Online]. Available: https://arxiv.org/abs/2404.13628
-
[15]
arXiv preprint arXiv:2501.15103 , year=
Z. Zhao, Y . Zhou, Z. Zhang, D. Zhu, T. Shen, Z. Li, J. Yang, X. Wang, J. Su, K. Kuang, Z. Wei, F. Wu, and Y . Cheng, “Each rank could be an expert: Single-ranked mixture of experts LoRA for multi-task learning,” 2025. [Online]. Available: https://arxiv.org/abs/2501.15103
-
[16]
PubMedQA: A Dataset for Biomedical Research Question Answering
Q. Jin, B. Dhingra, Z. Liu, W. W. Cohen, and X. Lu, “PubMedQA: A dataset for biomedical research question answering,” 2019. [Online]. Available: https://arxiv.org/abs/1909.06146
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
Large language models encode clinical knowledge,
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohlet al., “Large language models encode clinical knowledge,” 2022. [Online]. Available: https://arxiv.org/abs/2212.13138
-
[18]
Towards Expert-Level Medical Question Answering with Large Language Models
K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, L. Hou, K. Clark, S. Pfohl, H. Cole-Lewiset al., “Towards expert-level medical question answering with large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2305.09617
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022
2022
-
[20]
QLoRA: Efficient Finetuning of Quantized LLMs
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient finetuning of quantized LLMs,” 2023. [Online]. Available: https://arxiv.org/abs/2305.14314
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
DoRA: Weight-Decomposed Low-Rank Adaptation
S.-Y . Liu, C.-Y . Wang, H. Yin, P. Molchanov, Y .-C. F. Wang, K.-T. Cheng, and M.-H. Chen, “DoRA: Weight-decomposed low-rank adaptation,” 2024. [Online]. Available: https://arxiv.org/abs/2402.09353
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Q. Zhang, M. Chen, A. Bukharin, N. Karampatziakis, P. He, Y . Cheng, W. Chen, and T. Zhao, “AdaLoRA: Adaptive budget allocation for parameter-efficient fine-tuning,” 2023. [Online]. Available: https://arxiv.org/abs/2303.10512
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
DyLoRA: Parameter efficient tuning of pre-trained models using dynamic search- free low-rank adaptation,
M. Valipour, M. Rezagholizadeh, I. Kobyzev, and A. Ghodsi, “DyLoRA: Parameter efficient tuning of pre-trained models using dynamic search- free low-rank adaptation,” inProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, 2023
2023
-
[24]
IncreLoRA: Incremental parameter allocation method for parameter-efficient fine- tuning,
F. Zhang, L. Li, J. Chen, Z. Jiang, B. Wang, and Y . Qian, “IncreLoRA: Incremental parameter allocation method for parameter-efficient fine- tuning,” 2023. [Online]. Available: https://arxiv.org/abs/2308.12043
-
[25]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inInternational Conference on Learning Representations, 2017
2017
-
[26]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[27]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan et al., “The Llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inProceedings of the 34th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 70. PMLR, 2017, pp. 1321–1330
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.