DeRes: Decoupling Residual Stability and Adaptivity for Scalable CTR Prediction
Pith reviewed 2026-06-27 19:22 UTC · model grok-4.3
The pith
DeRes decouples residual connections into parallel identity and block-attention paths with per-dimension gating to improve CTR scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
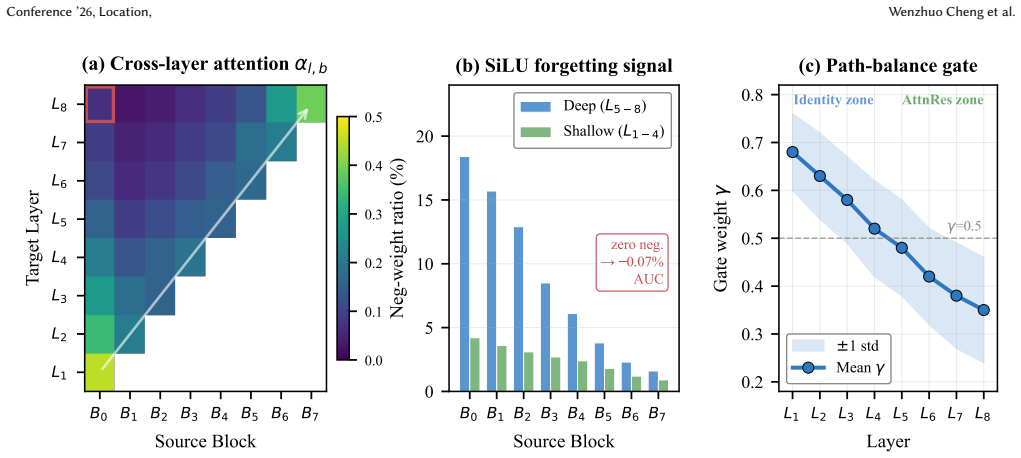
DeRes routes each layer through an Identity residual path that preserves first-order feature reuse and a Block Attention Residual path that attends over compressed outputs of all earlier blocks, combined with a vector-wise gate and SiLU replacing Softmax in the cross-layer attention, resulting in higher AUC and a steeper compute-AUC scaling law than standard or attention-based residuals.
What carries the argument
Dual-path residual consisting of an identity skip plus a Block Attention Residual that attends over prior block outputs, blended by a vector-wise gate and using SiLU for simultaneous multi-block activation and negative forgetting weights.
If this is right
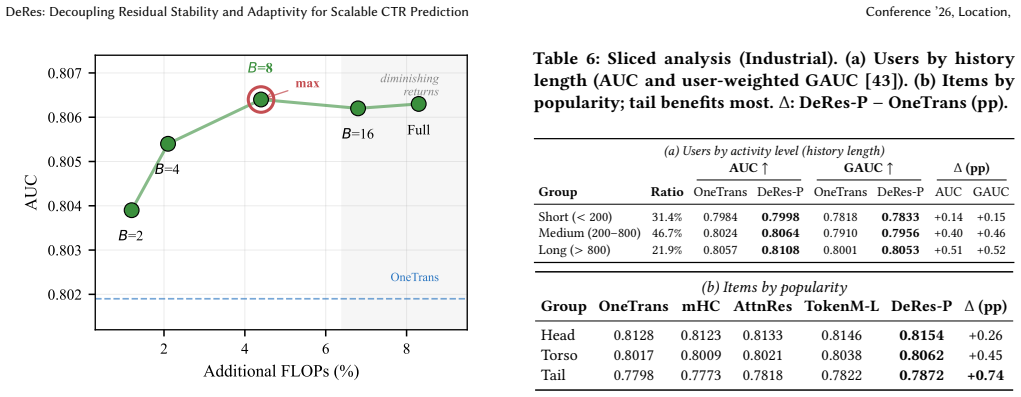
- DeRes reaches up to 0.32 percent higher AUC than twelve baselines at less than 5 percent extra FLOPs.
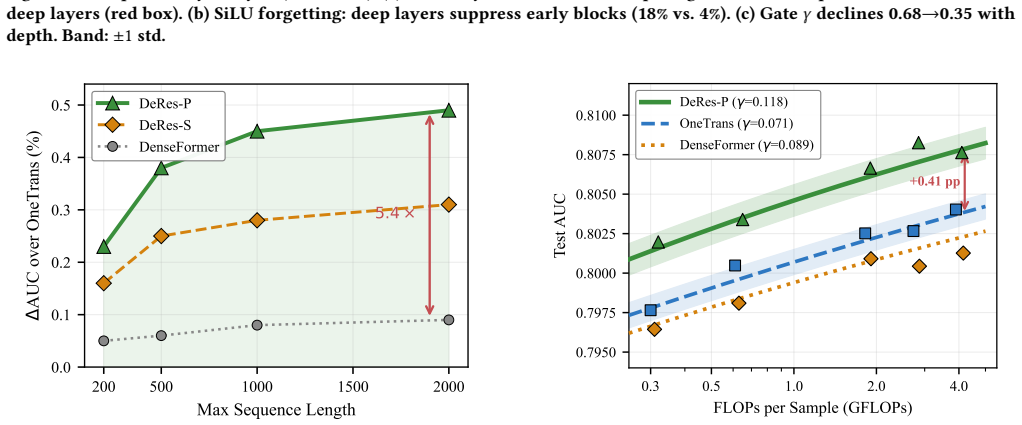
- An eight-layer DeRes matches the AUC of a sixteen-layer OneTrans, delivering roughly 2x compute saving at equivalent accuracy.
- The dual-path design outperforms either the identity path or the block-attention path used alone.
- Identity residuals outperform learnable residuals, and SiLU outperforms Softmax inside the cross-layer attention.
- DeRes exhibits a compute-AUC exponent of 0.118 versus 0.071 for OneTrans.
Where Pith is reading between the lines
- The same dual-path split could be tested in non-CTR transformer stacks where early-token signals also degrade with depth.
- Industrial pipelines that currently scale depth for marginal AUC gains might instead allocate saved compute to wider embeddings or more training data.
- If the vector-wise gate learns to suppress entire dimensions on some paths, it may reduce effective parameter count without explicit pruning.
Load-bearing premise
The block attention residual, when attending over compressed prior outputs and combined with the vector-wise gate and SiLU, will reliably capture long-range cross-layer dependencies and enable forgetting without instability or overfitting.
What would settle it
A replication on held-out CTR datasets in which the measured compute-AUC slope for DeRes falls to the same value as OneTrans or in which the AUC gains vanish beyond twelve layers would falsify the central claim.
Figures

read the original abstract
Transformer-based CTR models face a growing bottleneck at the residual connection: under Pre-Norm, early user-interest signals are diluted layer by layer; the identity skip cannot forget stale interests; and each layer sees only its immediate predecessor, losing long-range cross-layer dependencies. Recent attention-based residual variants (AttnRes) address parts of this in language models, but drop the protective identity skip and have not been tried in recommendation. Drawing on Dual Path Networks (DPN) and the HORNN view of residuals, we present DeRes, which routes each layer through two parallel paths -- an Identity residual path that preserves first-order feature reuse and gradient flow, and a Block Attention Residual path that attends over compressed outputs of all earlier blocks for high-order recall. A vector-wise gate decides, per hidden dimension, the weight given to each path. We further propose Pointwise AttnRes, replacing the Softmax in the cross-layer attention with SiLU so that multiple past blocks can be activated simultaneously and irrelevant ones receive negative (forgetting) weights -- better aligned with CTR's parallel multi-interest patterns. On a large-scale industrial dataset (331M interactions from a major social-media platform), Criteo (45M), and Avazu (40M), DeRes outperforms twelve baselines including OneTrans, TokenMixer-Large, UniMixer, mHC, and AttnRes, achieving up to +0.32% AUC at under 5% extra FLOPs. Beyond a single operating point, DeRes fits a markedly steeper compute-AUC scaling law (gamma=0.118 vs. 0.071 for OneTrans, a 1.66x gap), so an 8-layer DeRes matches a 16-layer OneTrans -- about 2x compute saving at equivalent AUC. Ablations confirm that the dual-path design outperforms either single path, Identity beats learnable residuals, and SiLU beats Softmax.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DeRes, a dual-path residual for transformer CTR models consisting of an identity path for stability and a Block Attention Residual path (with vector-wise gate and SiLU replacing Softmax) for adaptivity and cross-layer recall. It reports outperformance over 12 baselines (OneTrans, TokenMixer-Large, UniMixer, mHC, AttnRes) on Criteo, Avazu and a 331M-interaction industrial dataset, with gains up to +0.32% AUC at <5% extra FLOPs, plus a steeper compute-AUC scaling law (γ=0.118 vs 0.071) implying an 8-layer DeRes matches a 16-layer OneTrans.
Significance. If the scaling-law difference holds under controlled conditions, the result would be significant for efficient scaling of production CTR models. The design draws explicitly on DPN and HORNN ideas and is supported by ablations showing dual-path superiority, identity over learnable residuals, and SiLU over Softmax. Multi-dataset evaluation and explicit FLOPs reporting are strengths.
major comments (2)
- [Abstract] Abstract and scaling-law paragraph: the reported γ values (0.118 vs 0.071) and the claim that 'an 8-layer DeRes matches a 16-layer OneTrans' are load-bearing for the central efficiency claim, yet no details are given on the functional form fitted, the range of depths or widths used, or whether the same random seeds and data order were used across all scaling points.
- [Experiments] Experimental section (baseline comparisons): the +0.32% AUC gains are presented against OneTrans, TokenMixer-Large, etc., but the manuscript does not state whether all baselines were re-implemented with the identical optimizer schedule, embedding dimension, and negative-sampling strategy as DeRes; without this, attribution of gains to the dual-path design remains uncertain.
minor comments (2)
- [Abstract] The abstract states 'under 5% extra FLOPs' but no table or appendix lists the exact FLOPs or parameter counts for each model variant at each depth.
- [Method] Notation for the vector-wise gate and the compressed outputs of earlier blocks is introduced without an accompanying equation or diagram in the main text.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract and scaling-law paragraph: the reported γ values (0.118 vs 0.071) and the claim that 'an 8-layer DeRes matches a 16-layer OneTrans' are load-bearing for the central efficiency claim, yet no details are given on the functional form fitted, the range of depths or widths used, or whether the same random seeds and data order were used across all scaling points.
Authors: We agree that the scaling-law analysis requires additional methodological details for full reproducibility. In the revised version we will explicitly state the fitted functional form (AUC = a · compute^γ), the exact range of depths (2–16 layers) and widths used to generate the scaling points, and confirm that identical random seeds and data ordering were used for all compared models at each scale. revision: yes
-
Referee: [Experiments] Experimental section (baseline comparisons): the +0.32% AUC gains are presented against OneTrans, TokenMixer-Large, etc., but the manuscript does not state whether all baselines were re-implemented with the identical optimizer schedule, embedding dimension, and negative-sampling strategy as DeRes; without this, attribution of gains to the dual-path design remains uncertain.
Authors: All baselines were re-implemented under identical hyper-parameters, optimizer schedule, embedding dimension, and negative-sampling strategy as DeRes. We will add an explicit statement to this effect in the experimental section of the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claims consist of an architectural proposal (dual-path residual with vector-wise gating and SiLU-based Pointwise AttnRes) whose benefits are asserted via direct empirical measurement on three external datasets against twelve independent baselines, plus an observed difference in fitted scaling exponents. No derivation chain reduces any claimed performance quantity to a fitted parameter or self-citation by construction; the scaling-law comparison is presented as an empirical outcome rather than a model-derived prediction, and external citations (DPN, HORNN, AttnRes) supply only high-level motivation without load-bearing uniqueness theorems. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Identity residual path preserves first-order feature reuse and gradient flow
- domain assumption Block attention over compressed prior-block outputs can supply high-order recall
invented entities (2)
-
DeRes dual-path residual with vector-wise gate
no independent evidence
-
Pointwise AttnRes using SiLU
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Avazu. 2015. Avazu Click-Through Rate Prediction. https://www.kaggle.com/c/ avazu-ctr-prediction
2015
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. 2016. Layer normaliza- tion.arXiv preprint arXiv:1607.06450(2016)
Pith/arXiv arXiv 2016
-
[3]
Yukuo Cen, Jianwei Zhang, Xu Zou, Chang Zhou, Hongxia Yang, and Jie Tang
-
[4]
InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Controllable multi-interest framework for recommendation. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2942–2951
-
[5]
Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, and Wenwu Ou. 2019. Behavior sequence transformer for e-commerce recommendation in alibaba. InProceedings of the 1st international workshop on deep learning practice for high-dimensional sparse data. 1–4
2019
-
[6]
Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, and Jiashi Feng. 2017. Dual path networks.Advances in neural information processing systems30 (2017)
2017
-
[7]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al
-
[8]
InProceedings of the 1st workshop on deep learning for recommender systems
Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems. 7–10
-
[9]
Criteo Labs. 2014. Criteo Display Advertising Challenge. https://www.kaggle. com/c/criteo-display-ad-challenge
2014
-
[10]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction.arXiv preprint arXiv:1703.04247(2017)
Pith/arXiv arXiv 2017
-
[11]
Mingming Ha, Guanchen Wang, Linxun Chen, Xuan Rao, Yuexin Shi, Tianbao Ma, Zhaojie Liu, Yunqian Fan, Zilong Lu, Yanan Niu, et al . 2026. UniMixer: A Unified Architecture for Scaling Laws in Recommendation Systems.arXiv preprint arXiv:2604.00590(2026)
arXiv 2026
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[13]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[14]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
Pith/arXiv arXiv 2015
-
[15]
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger
-
[16]
InProceedings of the IEEE conference on computer vision and pattern recognition
Densely connected convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition. 4700–4708
-
[17]
Tongwen Huang, Zhiqi Zhang, and Junlin Zhang. 2019. FiBiNET: combining fea- ture importance and bilinear feature interaction for click-through rate prediction. InProceedings of the 13th ACM conference on recommender systems. 169–177
2019
-
[18]
Yuchen Jiang, Jie Zhu, Xintian Han, Hui Lu, Kunmin Bai, Mingyu Yang, Shikang Wu, Ruihao Zhang, Wenlin Zhao, Shipeng Bai, et al. 2026. TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders.arXiv preprint arXiv:2602.06563(2026)
arXiv 2026
-
[19]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[20]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
Pith/arXiv arXiv 2014
-
[21]
Chao Li, Zhiyuan Liu, Mengmeng Wu, Yuchi Xu, Huan Zhao, Pipei Huang, Guoliang Kang, Qiwei Chen, Wei Li, and Dik Lun Lee. 2019. Multi-interest network with dynamic routing for recommendation at Tmall. InProceedings of the 28th ACM international conference on information and knowledge management. 2615–2623
2019
-
[22]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature in- teractions for recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1754–1763
2018
-
[23]
Mingyang Liu, Yong Bai, Zhangming Chan, Sishuo Chen, Xiang-Rong Sheng, Han Zhu, Jian Xu, and Xinyang Chen. 2026. EST: Towards Efficient Scaling Laws in Click-Through Rate Prediction via Unified Modeling.arXiv preprint arXiv:2602.10811(2026)
arXiv 2026
-
[24]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. 2018. Modeling task relationships in multi-task learning with multi-gate mixture-of- experts. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1930–1939
2018
-
[25]
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire space multi-task model: An effective approach for estimating post-click conversion rate. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 1137–1140
2018
-
[26]
Matteo Pagliardini, Amirkeivan Mohtashami, Francois Fleuret, and Martin Jaggi
-
[27]
Denseformer: Enhancing information flow in transformers via depth weighted averaging.Advances in neural information processing systems37 (2024), 136479–136508
2024
-
[28]
Qi Pi, Xiaoqiang Zhu, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, and Kun Gai. 2020. Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction.Proceedings of the 29th ACM International Conference on Information & Knowledge Management (2020). https://api.semanticscholar.org/CorpusID:219558850
2020
-
[29]
Jiarui Qin, Weinan Zhang, Xin Wu, Jiarui Jin, Yuchen Fang, and Yong Yu. 2020. User behavior retrieval for click-through rate prediction. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 2347–2356
2020
-
[30]
Prajit Ramachandran, Barret Zoph, and Quoc V Le. 2017. Searching for activation functions.arXiv preprint arXiv:1710.05941(2017)
Pith/arXiv arXiv 2017
-
[31]
Steffen Rendle. 2010. Factorization machines. In2010 IEEE International conference on data mining. IEEE, 995–1000
2010
-
[32]
Rohollah Soltani and Hui Jiang. 2016. Higher order recurrent neural networks. arXiv preprint arXiv:1605.00064(2016)
Pith/arXiv arXiv 2016
-
[33]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. Autoint: Automatic feature interaction learning via self- attentive neural networks. InProceedings of the 28th ACM international conference on information and knowledge management. 1161–1170
2019
-
[34]
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research15, 1 (2014), 1929–1958
2014
-
[35]
Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, et al. 2026. Attention residu- als.arXiv preprint arXiv:2603.15031(2026)
Pith/arXiv arXiv 2026
-
[36]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[37]
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of the web conference 2021. 1785–1797
2021
-
[38]
Da Xiao, Qingye Meng, Shengping Li, and Xingyuan Yuan. 2025. Muddformer: Breaking residual bottlenecks in transformers via multiway dynamic dense con- nections.arXiv preprint arXiv:2502.12170(2025)
arXiv 2025
-
[39]
Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Kuai Yu, et al. 2025. mhc: Manifold- constrained hyper-connections.arXiv preprint arXiv:2512.24880(2025)
Pith/arXiv arXiv 2025
-
[40]
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. 2020. On layer normalization in the transformer architecture. InInternational conference on machine learning. PMLR, 10524–10533
2020
-
[41]
Bencheng Yan, Yuejie Lei, Zhiyuan Zeng, Di Wang, Kaiyi Lin, Pengjie Wang, Jian Xu, and Bo Zheng. 2025. From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction.arXiv preprint arXiv:2511.12081(2025)
Pith/arXiv arXiv 2025
-
[42]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
Pith/arXiv arXiv 2024
-
[43]
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Daifeng Guo, Yanli Zhao, Shen Li, Yuchen Hao, Yantao Yao, et al. 2024. Wukong: Towards a scaling law for Conference ’26, Location, Wenzhuo Cheng et al. large-scale recommendation.arXiv preprint arXiv:2403.02545(2024)
arXiv 2024
-
[44]
Biao Zhang and Rico Sennrich. 2019. Root mean square layer normalization. Advances in neural information processing systems32 (2019)
2019
-
[45]
Yilang Zhang, Bingcong Li, Niao He, and Georgios B Giannakis. 2026. ANCRe: Adaptive Neural Connection Reassignment for Efficient Depth Scaling.arXiv preprint arXiv:2602.09009(2026)
arXiv 2026
-
[46]
Zhaoqi Zhang, Haolei Pei, Jun Guo, Tianyu Wang, Yufei Feng, Hui Sun, Shaowei Liu, and Aixin Sun. 2026. Onetrans: Unified feature interaction and sequence modeling with one transformer in industrial recommender. InProceedings of the ACM Web Conference 2026. 8162–8170
2026
-
[47]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948
2019
-
[48]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
-
[49]
Defa Zhu, Hongzhi Huang, Zihao Huang, Yutao Zeng, Yunyao Mao, Banggu Wu, Qiyang Min, and Xun Zhou. 2025. Hyper-connections. InInternational Conference on Learning Representations, Vol. 2025. 97183–97219
2025
-
[50]
Jieming Zhu, Jinyang Liu, Shuai Yang, Qi Zhang, and Xiuqiang He. 2021. Open benchmarking for click-through rate prediction. InProceedings of the 30th ACM international conference on information & knowledge management. 2759–2769
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.