The Rollout Infrastructure Tax in Coding-Agent Reinforcement Learning
Pith reviewed 2026-07-03 21:17 UTC · model grok-4.3
The pith
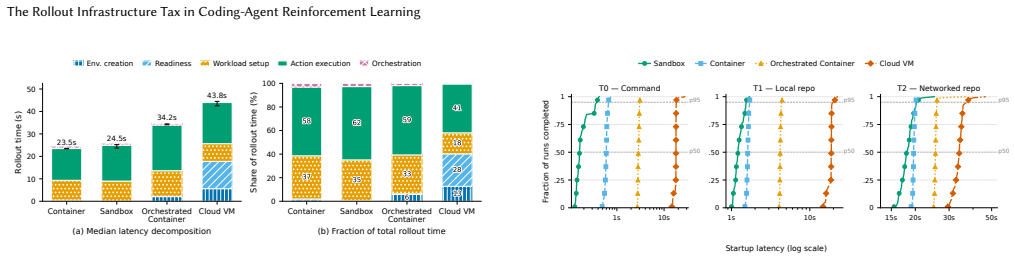
Coding-agent RL rollouts show up to 110× cold-start latency variation across execution substrates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
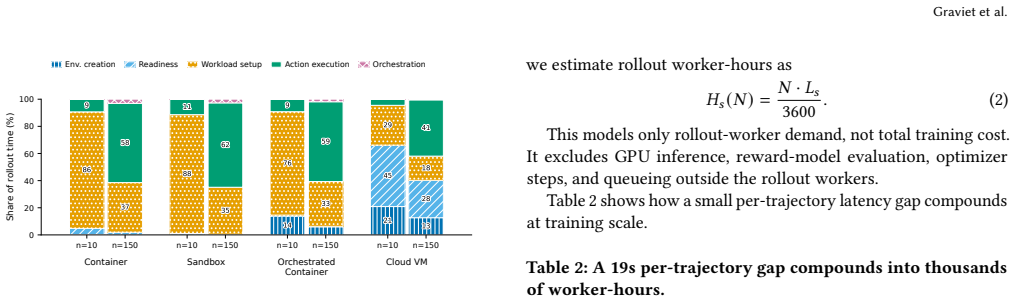
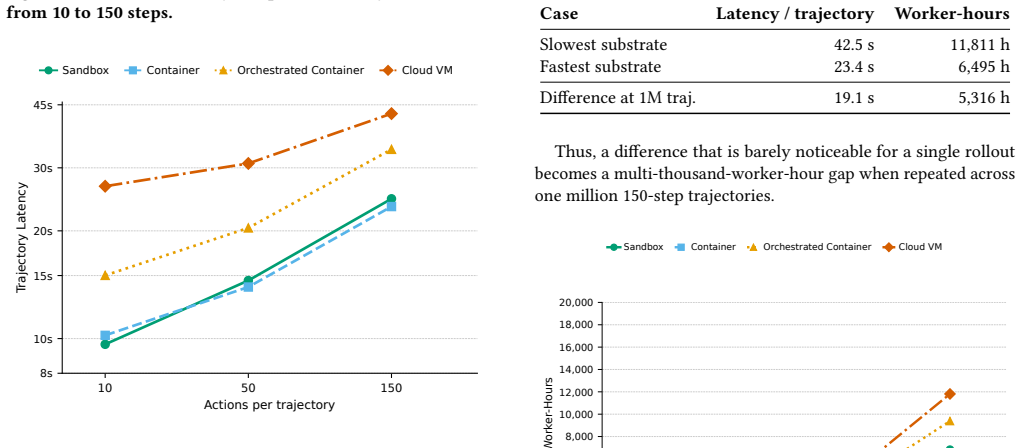
Coding-agent reinforcement learning treats execution infrastructure as a background implementation detail, despite relying on large numbers of interactive software rollouts. Measuring infrastructure overhead reveals practical efficiency gains for RL post-training, where small per-rollout savings compound at scale. A comparative study of single containers, hosted sandboxes, Kubernetes-orchestrated containers, and cloud virtual machines finds up to 110× variation in cold-start latency and a 1.8× spread in projected worker-hours for one million 150-step trajectories.
What carries the argument
Comparative measurement of cold-start latency and projected worker-hours across four execution substrates for sequences of coding-agent trajectories.
If this is right
- Coding-agent RL systems gain efficiency by optimizing execution substrates inside the training loop rather than treating them as separate deployment concerns.
- Per-rollout latency reductions compound across one million trajectories to produce measurable differences in total worker-hours.
- Infrastructure choice becomes a first-class design decision for RL post-training pipelines that rely on interactive code execution.
- Small constant-factor improvements in substrate performance scale into large absolute savings at the trajectory volumes used in current systems.
Where Pith is reading between the lines
- The same substrate variation could appear in other agent RL domains that execute external code or simulators at scale.
- Training pipelines might achieve further gains by dynamically switching substrates mid-training based on workload phase.
- Reliability or setup overhead differences not captured in the latency metric could narrow the effective advantage of the fastest substrates.
- Extending the comparison to include container image size, network isolation cost, or GPU passthrough would test whether the latency spread persists under richer execution requirements.
Load-bearing premise
The four tested substrates and the chosen trajectory length and count are representative of typical coding-agent RL workloads, and the observed latency and cost differences translate directly into training efficiency gains without being offset by other factors.
What would settle it
Running an actual end-to-end coding-agent RL training loop on each of the four substrates and directly measuring total wall-clock training time and compute usage for the same policy improvement task.
Figures

read the original abstract
Coding-agent reinforcement learning treats execution infrastructure as a background implementation detail, despite relying on large numbers of interactive software rollouts. This is a missed opportunity: measuring infrastructure overhead can reveal practical efficiency gains for RL post-training, where small per-rollout savings compound at scale. We present a comparative study of four execution substrates: single containers, hosted sandboxes, Kubernetes-orchestrated containers, and cloud virtual machines. We find up to $110\times$ variation in cold-start latency and a $1.8\times$ spread in projected worker-hours for one million 150-step trajectories. Our results suggest that future coding-agent RL systems should optimize execution substrates as part of the training system itself, not merely as deployment plumbing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical comparative study of four execution substrates (single containers, hosted sandboxes, Kubernetes-orchestrated containers, and cloud virtual machines) for coding-agent RL rollouts. It reports up to 110× variation in cold-start latency and a 1.8× spread in projected worker-hours for one million 150-step trajectories, concluding that future systems should optimize execution substrates as part of the training system rather than treating them as deployment plumbing.
Significance. If the reported measurements are reproducible and representative, the work identifies a concrete and potentially large source of overhead in scaling RL post-training for coding agents. The direct timing data and straightforward linear projections supply a falsifiable, quantitative basis for the infrastructure recommendation, which could usefully shift attention in the field from model-centric to system-level optimizations.
major comments (2)
- [Methods / Experimental Setup] The manuscript reports specific numerical claims (110× latency variation, 1.8× worker-hour spread) but provides no description of the experimental protocol, number of repetitions, measurement methodology, statistical procedures, or the precise formula used to compute the one-million-trajectory projections. This absence is load-bearing for the central empirical claim and prevents assessment of whether the data support the stated results.
- [Discussion / Conclusion] The four tested substrates, 150-step trajectory length, and one-million-trajectory scale are presented without justification or sensitivity analysis showing they are representative of typical coding-agent RL workloads; the recommendation to treat infrastructure as first-class therefore rests on an untested generalizability assumption that directly affects the practical significance of the findings.
minor comments (1)
- [Results] A summary table listing per-substrate cold-start latencies, standard deviations (if measured), and the derived worker-hour projections would improve readability and allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important gaps in the presentation of our empirical results. We will revise the manuscript to address both major concerns by adding the requested methodological details and workload justification.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] The manuscript reports specific numerical claims (110× latency variation, 1.8× worker-hour spread) but provides no description of the experimental protocol, number of repetitions, measurement methodology, statistical procedures, or the precise formula used to compute the one-million-trajectory projections. This absence is load-bearing for the central empirical claim and prevents assessment of whether the data support the stated results.
Authors: We agree that the current version omits these details. The revised manuscript will include a new 'Experimental Protocol' subsection specifying: 10 independent repetitions per substrate; cold-start latency measured via high-resolution system timers from container/VM creation to first code execution; per-step execution times logged via instrumentation; means and standard deviations reported; and the projection formula as (average per-trajectory worker-seconds) × 1,000,000, scaled by the number of parallel workers to obtain total worker-hours. These additions will make the central claims reproducible and verifiable. revision: yes
-
Referee: [Discussion / Conclusion] The four tested substrates, 150-step trajectory length, and one-million-trajectory scale are presented without justification or sensitivity analysis showing they are representative of typical coding-agent RL workloads; the recommendation to treat infrastructure as first-class therefore rests on an untested generalizability assumption that directly affects the practical significance of the findings.
Authors: The four substrates were selected as representative of common production and research deployments (local, hosted, orchestrated, and cloud VM), and the 150-step length aligns with median trajectory lengths reported in prior coding-agent RL literature. We acknowledge the absence of explicit justification and sensitivity analysis. The revision will add a 'Workload Parameters and Sensitivity' subsection with citations to representative workloads and a sensitivity study varying trajectory length (50–300 steps) and scale (10^5–10^7 trajectories), confirming that relative overhead rankings remain stable across this range. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical comparative study that reports measured cold-start latencies and worker-hour projections across four execution substrates. It contains no derivations, equations, fitted parameters, models, or self-citations that reduce any claim to its own inputs by construction. The central results are direct observations and simple extrapolations from those observations, with no load-bearing steps that qualify under the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alexandru Agache, Marc Brooker, Alexandra Iordache, Anthony Liguori, Rolf Neugebauer, Phil Piwonka, and Diana-Maria Popa. 2020. Firecracker: Light- weight Virtualization for Serverless Applications. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20). USENIX Associ- ation, Santa Clara, CA, 419–434. https://www.usenix.org/confe...
2020
-
[2]
Brendan Burns, Brian Grant, David Oppenheimer, Eric Brewer, and John Wilkes
-
[3]
http: //queue.acm.org/detail.cfm?id=2898444
Borg, Omega, and Kubernetes.ACM Queue14 (2016), 70–93. http: //queue.acm.org/detail.cfm?id=2898444
2016
-
[4]
James Cadden, Thomas Unger, Yara Awad, Han Dong, Orran Krieger, and Jonathan Appavoo. 2020. SEUSS: Skip Redundant Paths to Make Serverless Fast. InProceedings of the Fifteenth European Conference on Computer Systems. Article 32, 15 pages. doi:10.1145/3342195.3392698
-
[5]
Shiyi Cao, Dacheng Li, Fangzhou Zhao, Shuo Yuan, Sumanth R. Hegde, Connor Chen, Charlie Ruan, Tyler Griggs, Shu Liu, Eric Tang, Richard Liaw, Philipp Moritz, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. 2025. SkyRL-Agent: Efficient RL Training for Multi-turn LLM Agent. arXiv:2511.16108 [cs.AI] https: //arxiv.org/abs/2511.16108
-
[6]
Dong Du, Tianyi Yu, Yubin Xia, Binyu Zang, Guanglu Yan, Chenggang Qin, Qixuan Wu, and Haibo Chen. 2020. Catalyzer: Sub-millisecond Startup for Serverless Computing with Initialization-less Booting. InProceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 467–481. doi:10.1145/33733...
-
[7]
Wei Gao, Yuheng Zhao, Dakai An, Tianyuan Wu, Lunxi Cao, Shaopan Xiong, Ju Huang, Weixun Wang, Siran Yang, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng, and Wei Wang. 2025. RollPacker: Mitigating Long-Tail Rollouts for Fast, Synchronous RL Post-Training. arXiv:2509.21009 [cs.DC] https://arxiv.org/abs/ 2509.21009
-
[8]
Wei Gao, Yuheng Zhao, Tianyuan Wu, Shaopan Xiong, Weixun Wang, Dakai An, Lunxi Cao, Dilxat Muhtar, Zichen Liu, Haizhou Zhao, Ju Huang, Siran Yang, Yong- bin Li, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng, and Wei Wang. 2026. RollArt: Disaggregated Multi-Task Agentic RL Training at Scale. arXiv:2512.22560 [cs.DC] https://arxiv.org/abs/2512.22560
-
[9]
Shin, Yibo Zhu, Myeongjae Jeon, Junjie Qian, Hongqiang Harry Liu, and Chuanxiong Guo
Juncheng Gu, Mosharaf Chowdhury, Kang G. Shin, Yibo Zhu, Myeongjae Jeon, Junjie Qian, Hongqiang Harry Liu, and Chuanxiong Guo. 2019. Tiresias: A GPU Cluster Manager for Distributed Deep Learning. In16th USENIX Symposium on Networked Systems Design and Implementation. 485–500. https://www.usenix. org/conference/nsdi19/presentation/gu
2019
-
[10]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[11]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/2310. 06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Eric Liang, Zhanghao Wu, Michael Luo, Sven Mika, Joseph E. Gonzalez, and Ion Stoica. 2021. RLlib Flow: Distributed Reinforcement Learning is a Dataflow Problem. arXiv:2011.12719 [cs.LG] https://arxiv.org/abs/2011.12719
-
[13]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Mari- anna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Ray: A Distributed Framework for Emerging AI Applications
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. 2018. Ray: A Distributed Framework for Emerging AI Applications. arXiv:1712.05889 [cs.DC] https://arxiv.org/abs/1712.05889
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schul- man, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Pe- ter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer In- terfaces Enable Automated Software Engineering. arXiv:2405.15793 [cs.SE] https://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Yuzhen Zhou, Jiajun Li, Yusheng Su, Gowtham Ramesh, Zilin Zhu, Xiang Long, Chenyang Zhao, Jin Pan, Xiaodong Yu, Ze Wang, Kangrui Du, Jialian Wu, Ximeng Sun, Jiang Liu, Qiaolin Yu, Hao Chen, Zicheng Liu, and Emad Barsoum. 2025. APRIL: Active Partial Rollouts in Reinforcement Learning to Tame Long-tail Generation. arXiv:2509.18521 [cs.LG] https://arxiv.org/...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.