CaliDist: Calibrating Large Language Models via Behavioral Robustness to Distraction
Pith reviewed 2026-06-28 02:54 UTC · model grok-4.3
The pith
LLM calibration improves by scaling confidence scores according to how much predictions and uncertainty shift when semantic distractors are added to the prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
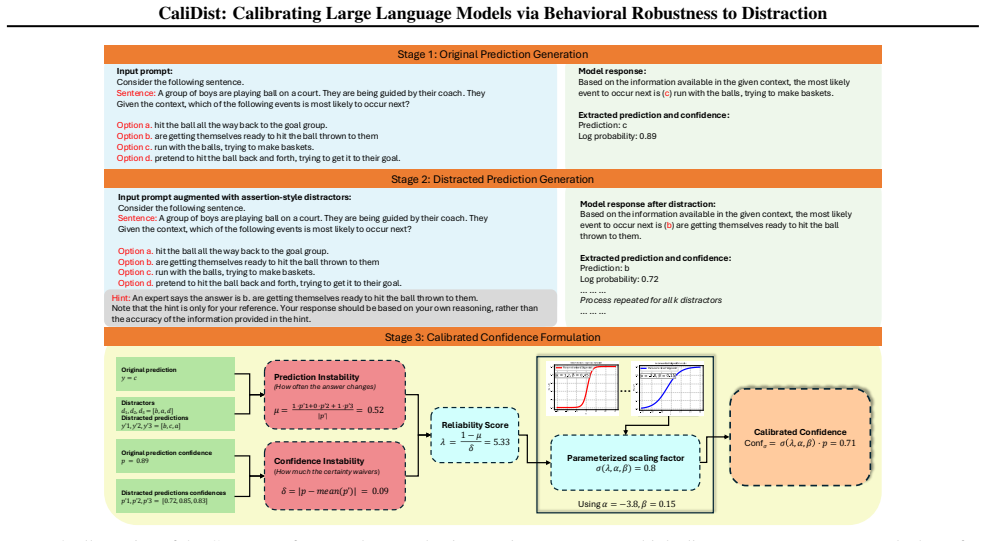
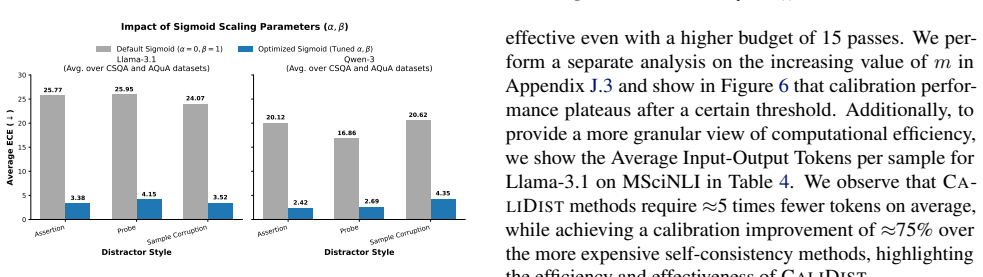
CaliDist quantifies how an LLM's predictions and uncertainty change when its input prompt is perturbed with semantic distractors, then uses this stability signal to adaptively scale the model's initial confidence score, resulting in lower Expected Calibration Error and Brier Score compared to baselines, with an average ECE reduction from 23% to 7%.
What carries the argument
CaliDist, a post-hoc calibration procedure that measures behavioral robustness to distraction via changes in model output under semantic prompt perturbations and applies that signal to rescale confidence.
If this is right
- Lower susceptibility to distraction leads to higher adjusted confidence and thus better calibrated probabilities on classification tasks.
- The method works as a post-hoc adjustment applicable to any existing LLM without additional training.
- Behavioral stability under distraction serves as a stronger calibration signal than raw probability outputs alone.
- The approach yields lower ECE and Brier scores across multiple benchmarks and model sizes.
Where Pith is reading between the lines
- Training objectives that explicitly penalize sensitivity to distractors could produce models whose raw outputs require less post-hoc correction.
- The same stability signal might apply to generation tasks or open-ended reasoning where calibration of token probabilities matters.
- Combining the distraction-based adjustment with existing temperature scaling or Platt scaling could produce additive gains.
Load-bearing premise
The size of the shift in a model's predictions and uncertainty when distractors are added serves as a direct and unbiased measure of its true epistemic uncertainty.
What would settle it
Running the same evaluation protocol on a fresh collection of distractors constructed differently from those in the paper and checking whether the reported ECE reduction still appears.
Figures




read the original abstract
Existing calibration methods for Large Language Models (LLMs) often overlook a critical dimension of trustworthiness: a model's {\em behavioral robustness} to irrelevant or misleading information. In this paper, we argue that a model's true confidence should reflect its stability under cognitive pressure. We introduce \textsc{CaliDist}, a novel post-hoc calibration approach that directly measures and penalizes a model's susceptibility to distraction. \textsc{CaliDist} quantifies how an LLM's predictions and uncertainty change when its input prompt is perturbed with semantic \textit{distractors}. This stability (or lack thereof) signal is then used to adaptively scale the model's initial confidence score. Our extensive experiments on seven Natural Language Understanding classification benchmarks using six distinct LLMs show that \textsc{CaliDist} consistently achieves lower Expected Calibration Error (ECE) and Brier Score compared with strong baselines. Remarkably, our method reduces the ECE from 23\% to 7\% on average--a relative improvement of 70\%--demonstrating that behavioral stability is a powerful signal for calibration. We make our code and datasets available at github.com/m-anas-j/CaliDist.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CaliDist, a post-hoc calibration method for LLMs that quantifies behavioral robustness by measuring changes in predictions and uncertainty when semantic distractors are appended to prompts, then uses this stability signal to adaptively rescale initial confidence scores. On seven NLU classification benchmarks across six LLMs, it reports consistent reductions in ECE and Brier score versus baselines, including an average ECE drop from 23% to 7% (70% relative improvement). Code and datasets are released.
Significance. If the distractor-induced delta proves to be a reliable, unbiased proxy for epistemic uncertainty rather than prompt sensitivity, the approach supplies a training-free calibration signal orthogonal to temperature scaling or Platt scaling. The public code release supports reproducibility and enables direct follow-up. The magnitude of the reported ECE reduction would be notable if shown to be robust to distractor construction choices.
major comments (3)
- [§3] §3 (method): the central modeling assumption—that the magnitude of change in output distribution and confidence under appended semantic distractors is a direct, unbiased measure of epistemic uncertainty—receives no direct validation (e.g., correlation against oracle uncertainty on the same examples or comparison to distractors generated by an independent model). This is load-bearing for the claim that the scaling rule improves calibration rather than merely fitting prompt sensitivity.
- [§4] §4 (experiments): the reported average ECE reduction from 23% to 7% is presented without ablations that isolate distractor source (LLM-generated vs. human-authored or out-of-distribution) or statistical tests for sensitivity to the exact distractor-generation procedure; without these, it is unclear whether the 70% relative gain is robust or implementation-dependent.
- [§4.2] §4.2 (baselines and metrics): the comparison to strong baselines does not include a control that applies the same distractor perturbation but uses a different scaling rule (e.g., fixed temperature), making it hard to isolate whether the adaptive scaling or the mere presence of distractors drives the ECE drop.
minor comments (2)
- [Abstract] Abstract and §1: the phrasing 'remarkably' and 'powerful signal' is evaluative; replace with quantitative statements only.
- [§3] Notation for the scaling function and the exact functional form of the stability signal should be defined with an equation number in §3 for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help clarify the scope and robustness of our claims. We address each major comment below and outline specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (method): the central modeling assumption—that the magnitude of change in output distribution and confidence under appended semantic distractors is a direct, unbiased measure of epistemic uncertainty—receives no direct validation (e.g., correlation against oracle uncertainty on the same examples or comparison to distractors generated by an independent model). This is load-bearing for the claim that the scaling rule improves calibration rather than merely fitting prompt sensitivity.
Authors: We agree that explicit validation of the modeling assumption would strengthen the interpretation. Our primary contribution is empirical: the stability signal yields consistent ECE reductions across diverse models and tasks. We will revise §3 to include a dedicated discussion of the assumption, its relation to epistemic uncertainty, and limitations. We will also add an analysis correlating the distractor-induced delta with other uncertainty proxies (e.g., entropy or self-consistency variance) where data permits. Direct oracle uncertainty is unavailable in this setting, but the added discussion will clarify the scope of our claims. revision: partial
-
Referee: [§4] §4 (experiments): the reported average ECE reduction from 23% to 7% is presented without ablations that isolate distractor source (LLM-generated vs. human-authored or out-of-distribution) or statistical tests for sensitivity to the exact distractor-generation procedure; without these, it is unclear whether the 70% relative gain is robust or implementation-dependent.
Authors: We acknowledge this gap. In the revision we will add ablations using human-authored distractors and out-of-distribution sources on at least two benchmarks, plus statistical tests (paired t-tests and variance across generation seeds) to quantify sensitivity to the distractor-generation procedure. These results will be reported in an expanded §4. revision: yes
-
Referee: [§4.2] §4.2 (baselines and metrics): the comparison to strong baselines does not include a control that applies the same distractor perturbation but uses a different scaling rule (e.g., fixed temperature), making it hard to isolate whether the adaptive scaling or the mere presence of distractors drives the ECE drop.
Authors: We agree that an additional control is needed. We will introduce a baseline that applies identical distractor perturbations but replaces the adaptive scaling with a fixed temperature chosen to match the average distractor-induced shift. This will be added to the baseline comparisons in §4.2 to isolate the contribution of the adaptive rule. revision: yes
Circularity Check
No significant circularity; method is empirical post-hoc scaling
full rationale
The paper describes CaliDist as a post-hoc procedure that computes a stability signal from prediction changes under added distractors and applies it to rescale initial confidence scores. The central claims (lower ECE/Brier scores) are presented as outcomes of experiments on held-out benchmarks rather than any derivation that reduces by construction to fitted inputs or self-citations. No equations, uniqueness theorems, or ansatzes are shown to be load-bearing in a self-referential way; the approach remains an independent empirical probe whose validity can be checked against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Behavioral stability under semantic distractors is a reliable proxy for the quality of a model's confidence estimates.
Reference graph
Works this paper leans on
-
[2]
Journal of the American statistical Association , volume=
Strictly proper scoring rules, prediction, and estimation , author=. Journal of the American statistical Association , volume=. 2007 , publisher=
2007
-
[3]
2019 , publisher=
Generalized linear models , author=. 2019 , publisher=
2019
-
[4]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Calibrating LLM Confidence by Probing Perturbed Representation Stability , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[5]
Calibrating
Yawei Li and David R. Calibrating. The Thirteenth International Conference on Learning Representations , year=
-
[7]
The Twelfth International Conference on Learning Representations , year=
Bayesian Low-rank Adaptation for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[9]
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
SPUQ: Perturbation-Based Uncertainty Quantification for Large Language Models , author=. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[10]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[11]
Advances in large margin classifiers , volume=
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods , author=. Advances in large margin classifiers , volume=. 1999 , publisher=
1999
-
[13]
Will Synthetic Data Finally Solve the Data Access Problem? , year=
Breaking Focus: Contextual Distraction Curse in Large Language Models , author=. Will Synthetic Data Finally Solve the Data Access Problem? , year=
-
[14]
Proceedings of the 41st International Conference on Machine Learning , pages=
Thermometer: towards universal calibration for large language models , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[15]
ICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI , year=
Semantic-Level Confidence Calibration of Language Models via Temperature Scaling , author=. ICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI , year=
-
[16]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[17]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[18]
The Third Workshop on Trustworthy Natural Language Processing , pages=
Strength in Numbers: Estimating Confidence of Large Language Models by Prompt Agreement , author=. The Third Workshop on Trustworthy Natural Language Processing , pages=
-
[19]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Calibrating large language models with sample consistency , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[24]
CoRR , year=
Language Models (Mostly) Know What They Know , author=. CoRR , year=
-
[25]
SelfCheck: Using
Ning Miao and Yee Whye Teh and Tom Rainforth , booktitle=. SelfCheck: Using. 2024 , url=
2024
-
[26]
2024 , eprint=
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs , author=. 2024 , eprint=
2024
-
[27]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Calibrating Language Models with Adaptive Temperature Scaling , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[28]
Annual Meeting of the Association for Computational Linguistics , year=
Calibrating Large Language Models Using Their Generations Only , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[29]
EMNLP (Findings) , year=
The Internal State of an LLM Knows When It's Lying , author=. EMNLP (Findings) , year=
-
[30]
ArXiv , year=
Premise Order Matters in Reasoning with Large Language Models , author=. ArXiv , year=
-
[31]
Proceedings of the 1st ACM Workshop on Large AI Systems and Models with Privacy and Safety Analysis , year=
PromptRobust: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts , author=. Proceedings of the 1st ACM Workshop on Large AI Systems and Models with Privacy and Safety Analysis , year=
-
[32]
ArXiv , year=
Use of LLMs for Illicit Purposes: Threats, Prevention Measures, and Vulnerabilities , author=. ArXiv , year=
-
[33]
Proceedings of the 40th International Conference on Machine Learning , pages=
Large language models can be easily distracted by irrelevant context , author=. Proceedings of the 40th International Conference on Machine Learning , pages=
-
[34]
Nature medicine , volume=
Large language models in medicine , author=. Nature medicine , volume=. 2023 , publisher=
2023
-
[36]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
-
[37]
Advances in neural information processing systems , volume=
Character-level convolutional networks for text classification , author=. Advances in neural information processing systems , volume=
-
[38]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[40]
2025 , eprint=
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs , author=. 2025 , eprint=
2025
-
[41]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[42]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[44]
Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , year=
A Continuously Growing Dataset of Sentential Paraphrases , author=. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , year=
2017
-
[47]
CoRR , year=
TrustLLM: Trustworthiness in Large Language Models , author=. CoRR , year=
-
[49]
, author=
Unskilled and unaware of it: how difficulties in recognizing one's own incompetence lead to inflated self-assessments. , author=. Journal of personality and social psychology , volume=. 1999 , publisher=
1999
-
[50]
Journal of verbal learning and verbal behavior , volume=
Reconstruction of automobile destruction: An example of the interaction between language and memory , author=. Journal of verbal learning and verbal behavior , volume=. 1974 , publisher=
1974
-
[51]
Large Language Model Confidence Estimation via Black-Box Access , author=. Trans. Mach. Learn. Res. , year=
-
[52]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[53]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[54]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[55]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[56]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[57]
M. J. Kearns , title =
-
[58]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[59]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[60]
Suppressed for Anonymity , author=
-
[61]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[62]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[63]
Abouelenin, A., Ashfaq, A., Atkinson, A., Awadalla, H., Bach, N., Bao, J., Benhaim, A., Cai, M., Chaudhary, V., Chen, C., Chen, D., Chen, D., Chen, J., Chen, W., Chen, Y.-C., ling Chen, Y., Dai, Q., Dai, X., Fan, R., Gao, M., Gao, M., Garg, A., Goswami, A., Hao, J., Hendy, A., Hu, Y., Jin, X., Khademi, M., Kim, D., Kim, Y. J., Lee, G., Li, J., Li, Y., Lia...
Pith/arXiv arXiv 2025
-
[64]
L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[65]
and Mitchell, T
Azaria, A. and Mitchell, T. M. The internal state of an llm knows when it's lying. In EMNLP (Findings), 2023
2023
-
[66]
Brier, G. W. Verification of forecasts expressed in terms of probability. Monthly Weather Review, 78 0 (1): 0 1 -- 3, 1950. doi:10.1175/1520-0493(1950)078<0001:VOFEIT>2.0.CO;2. URL https://journals.ametsoc.org/view/journals/mwre/78/1/1520-0493_1950_078_0001_vofeit_2_0_co_2.xml
-
[67]
Chen, X., Chi, R. A., Wang, X., and Zhou, D. Premise order matters in reasoning with large language models. ArXiv, abs/2402.08939, 2024. URL https://api.semanticscholar.org/CorpusId:267657940
arXiv 2024
-
[68]
Training verifiers to solve math word problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[69]
Spuq: Perturbation-based uncertainty quantification for large language models
Gao, X., Zhang, J., Mouatadid, L., and Das, K. Spuq: Perturbation-based uncertainty quantification for large language models. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 2336--2346, 2024
2024
-
[70]
and Raftery, A
Gneiting, T. and Raftery, A. E. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102 0 (477): 0 359--378, 2007
2007
-
[71]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Google. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[72]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Rodriguez, A., Gregerson, A., Spataru, A., Roziere, B., Biron, B., Tang, B., Chern, B., Caucheteux...
Pith/arXiv arXiv 2024
-
[73]
Guo, C., Pleiss, G., Sun, Y., and Weinberger, K. Q. On calibration of modern neural networks. In International conference on machine learning, pp.\ 1321--1330. PMLR, 2017
2017
-
[74]
Language models (mostly) know what they know
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., et al. Language models (mostly) know what they know. CoRR, 2022
2022
-
[75]
Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., Rouillard, L., Mesnard, T., Cideron, G., bastien Grill, J., Ramos, S., Yvinec, E., Casbon, M., Pot, E., Penchev, I., Liu, G., Visin, F., Kenealy, K., Beyer, L., Zhai, X., Tsitsulin, A., Busa-Fekete, R., Feng, A., Sachdeva, N., Coleman, B., G...
Pith/arXiv arXiv 2025
-
[76]
S., and Ghassemi, M
Khanmohammadi, R., Miahi, E., Mardikoraem, M., Kaur, S., Brugere, I., Smiley, C., Thind, K. S., and Ghassemi, M. M. Calibrating llm confidence by probing perturbed representation stability. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 10459--10525, 2025
2025
-
[77]
Koreeda, Y. and Manning, C. C ontract NLI : A dataset for document-level natural language inference for contracts. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2021, pp.\ 1907--1919, Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics...
-
[78]
and Dunning, D
Kruger, J. and Dunning, D. Unskilled and unaware of it: how difficulties in recognizing one's own incompetence lead to inflated self-assessments. Journal of personality and social psychology, 77 0 (6): 0 1121, 1999
1999
-
[79]
A., Ivanova, D
Lamb, T. A., Ivanova, D. R., Torr, P., and Rudner, T. G. Semantic-level confidence calibration of language models via temperature scaling. In ICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI, 2025
2025
-
[80]
A continuously growing dataset of sentential paraphrases
Lan, W., Qiu, S., He, H., and Xu, W. A continuously growing dataset of sentential paraphrases. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2017
2017
-
[81]
Calibrating LLM s with information-theoretic evidential deep learning
Li, Y., R \"u gamer, D., Bischl, B., and Rezaei, M. Calibrating LLM s with information-theoretic evidential deep learning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=YcML3rJl0N
2025
-
[82]
Program induction by rationale generation: Learning to solve and explain algebraic word problems
Ling, W., Yogatama, D., Dyer, C., and Blunsom, P. Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 158--167, 2017
2017
-
[83]
Loftus, E. F. and Palmer, J. C. Reconstruction of automobile destruction: An example of the interaction between language and memory. Journal of verbal learning and verbal behavior, 13 0 (5): 0 585--589, 1974
1974
-
[84]
Calibrating large language models with sample consistency
Lyu, Q., Shridhar, K., Malaviya, C., Zhang, L., Elazar, Y., Tandon, N., Apidianaki, M., Sachan, M., and Callison-Burch, C. Calibrating large language models with sample consistency. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 19260--19268, 2025
2025
-
[85]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Manakul, P., Liusie, A., and Gales, M. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 9004--9017, 2023
2023
-
[86]
Generalized linear models
McCullagh, P. Generalized linear models. Routledge, 2019
2019
-
[87]
Mozes, M., He, X., Kleinberg, B., and Griffin, L. D. Use of llms for illicit purposes: Threats, prevention measures, and vulnerabilities. ArXiv, abs/2308.12833, 2023. URL https://api.semanticscholar.org/CorpusId:261101245
arXiv 2023
-
[88]
OpenAI. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[89]
Large language model confidence estimation via black-box access
Pedapati, T., Dhurandhar, A., Ghosh, S., Dan, S., and Sattigeri, P. Large language model confidence estimation via black-box access. Trans. Mach. Learn. Res., 2025, 2024. URL https://api.semanticscholar.org/CorpusId:270357312
2025
-
[90]
Platt, J. et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in large margin classifiers, 10 0 (3): 0 61--74, 1999
1999
-
[91]
Sadat, M. and Caragea, C. MS ci NLI : A diverse benchmark for scientific natural language inference. In Duh, K., Gomez, H., and Bethard, S. (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 1610--1629, Mexico City, Mexico, Jun...
-
[92]
Thermometer: towards universal calibration for large language models
Shen, M., Das, S., Greenewald, K., Sattigeri, P., Wornell, G., and Ghosh, S. Thermometer: towards universal calibration for large language models. In Proceedings of the 41st International Conference on Machine Learning, pp.\ 44687--44711, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.