On the Identifiability of Semi-Blind Estimation in Cell-Free Massive MIMO Networks
Pith reviewed 2026-05-21 01:50 UTC · model grok-4.3
The pith
Recursive probabilistic analysis on an approximated random graph model defines the region of AP and UE densities and connectivity radius where semi-blind joint channel estimation and data detection succeeds with high probability in cellfree
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
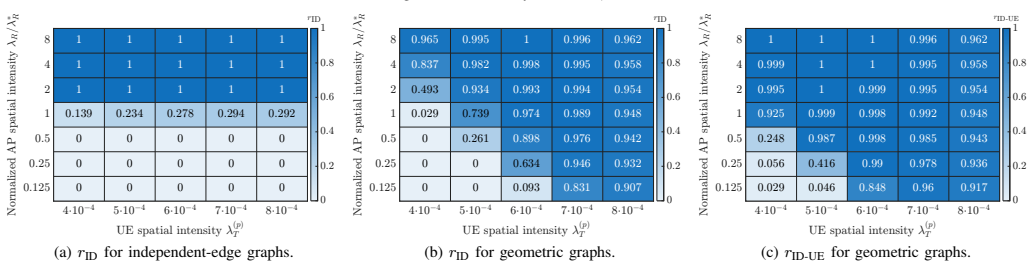
The central claim is that semi-blind recovery succeeds with high probability when the network parameters place the system inside an identifiability region whose boundaries are characterized by a recursive probabilistic analysis performed on a surrogate independent-edge random graph whose degree distributions match those of the original bipartite random geometric graph induced by Poisson point processes and a finite connectivity radius.
What carries the argument
The recursive probabilistic analysis performed on the surrogate independent-edge random graph with matched degree distributions, which tracks the probability that the semi-blind recovery procedure can uniquely resolve the unknown channels and data symbols.
If this is right
- Higher access-point density enlarges the set of user densities for which recovery succeeds.
- Increasing the connectivity radius beyond a critical value can shrink the identifiability region by adding interfering links.
- Shorter pilot sequences become admissible once the operating point lies well inside the predicted region.
- Deployment guidelines can be read directly from the boundary curves without needing to simulate every realization of the geometric graph.
Where Pith is reading between the lines
- The same approximation technique may apply to other large-scale wireless problems that involve local connectivity, such as device-to-device networks or sensor placement.
- If the identifiability region is confirmed, operators could trade pilot overhead against infrastructure density in real deployments.
- Testing the predicted boundaries with measured channel traces rather than purely geometric models would check how well the Poisson assumption holds outdoors.
Load-bearing premise
The spatially dependent connections created by wireless propagation can be replaced, without changing the recovery outcome, by an independent-edge random graph that only matches the average number of neighbors each access point and user has.
What would settle it
Monte Carlo trials on the exact bipartite random geometric graph for the same densities and radius that show the fraction of successful recoveries deviates substantially from the high-probability prediction of the recursive analysis.
Figures



read the original abstract
Semi-blind joint channel estimation and data detection (JCD) is a promising approach to mitigate pilot contamination in cell-free massive multiple-input multiple-output (CF-MaMIMO) networks. The effectiveness of such methods fundamentally depends on identifiability, i.e., the ability to unambiguously recover the unknown channel coefficients and transmitted data signals from the received uplink observations. In this work, we investigate the identifiability of semi-blind JCD from a large-scale system design perspective. We consider a CF-MaMIMO network in which access points (APs) and user equipments (UEs) are spatially distributed according to Poisson point processes (PPPs). The resulting network topology is modeled as bipartite random geometric graph (BRGG) that captures local connectivity induced by wireless propagation. To enable a tractable analysis, the spatially dependent graph model is approximated by a surrogate independent-edge random graph with matched degree distributions. Building on this model, we develop a recursive probabilistic analysis that characterizes the conditions under which semi-blind recovery succeeds with high probability. The proposed analysis reveals an identifiability region as a function of key system parameters, including AP and UE densities and the connectivity radius beyond which channel coefficients are assumed negligible. Monte Carlo simulations validate the predicted identifiability region and assess the accuracy of the proposed graph approximation. The proposed framework provides system level insights into how network density and connectivity affect identifiability in large-scale CF-MaMIMO systems and offers guidelines for selecting deployment parameters and pilot sequence lengths that enable reliable semi-blind recovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates identifiability of semi-blind joint channel estimation and data detection (JCD) in cell-free massive MIMO networks with Poisson point process distributed access points and user equipments. The network topology is modeled as a bipartite random geometric graph (BRGG) capturing local connectivity via a finite radius. This is approximated by a surrogate independent-edge random graph with matched degree distributions to enable a recursive probabilistic analysis that derives an identifiability region as a function of AP/UE densities and connectivity radius. Monte Carlo simulations are presented to validate the predicted region and assess the graph approximation accuracy.
Significance. If the degree-matched surrogate approximation is shown to preserve the relevant connectivity properties for identifiability propagation, the work would deliver useful large-scale system design insights for mitigating pilot contamination via semi-blind methods. The recursive analysis framework combined with stochastic geometry modeling and empirical validation constitutes a strength for understanding density and radius effects on recovery success probability.
major comments (2)
- [Section II and Section IV] The modeling step (abstract and Section II): the recursive probabilistic analysis is performed exclusively on the independent-edge surrogate whose degrees match the BRGG. Because the actual BRGG induced by PPP locations and finite radius exhibits spatial edge dependencies (local clustering and correlations), it is unclear whether degree matching alone suffices to preserve the identifiability threshold; the Monte Carlo validation should include direct head-to-head comparison of recovery probability on the true BRGG versus the surrogate for the same parameter values.
- [Section III] Section III (recursive analysis): the derivation of the identifiability region lacks explicit statement of the base cases, termination conditions, and any assumptions on the message-passing or propagation rule used in the recursion. Without these, it is difficult to assess whether the predicted region is robust to the geometric correlations omitted by the surrogate.
minor comments (2)
- [Figures 2-4] Figure captions and axis labels should explicitly state whether the plotted curves correspond to the BRGG or the surrogate model.
- [Theorem 1] Clarify the precise definition of 'high probability' success (e.g., 1-epsilon with epsilon->0 as network size grows) in the statement of the main theorem.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our modeling and analysis. We address each major comment below and will revise the manuscript accordingly to improve explicitness and validation.
read point-by-point responses
-
Referee: [Section II and Section IV] The modeling step (abstract and Section II): the recursive probabilistic analysis is performed exclusively on the independent-edge surrogate whose degrees match the BRGG. Because the actual BRGG induced by PPP locations and finite radius exhibits spatial edge dependencies (local clustering and correlations), it is unclear whether degree matching alone suffices to preserve the identifiability threshold; the Monte Carlo validation should include direct head-to-head comparison of recovery probability on the true BRGG versus the surrogate for the same parameter values.
Authors: We agree that the BRGG exhibits spatial edge dependencies arising from the PPP locations and finite-radius connectivity, which are absent in the independent-edge surrogate despite degree matching. The current Monte Carlo experiments generate networks from the true BRGG to compute empirical recovery probabilities and compare them against the analytical predictions derived from the surrogate; this already provides an indirect assessment of approximation quality. To directly address the concern, we will add in the revised manuscript a head-to-head comparison of recovery success probabilities obtained by running the semi-blind JCD algorithm on both the BRGG and the degree-matched surrogate for identical density and radius values, thereby quantifying any effect of the omitted geometric correlations on the observed threshold. revision: yes
-
Referee: [Section III] Section III (recursive analysis): the derivation of the identifiability region lacks explicit statement of the base cases, termination conditions, and any assumptions on the message-passing or propagation rule used in the recursion. Without these, it is difficult to assess whether the predicted region is robust to the geometric correlations omitted by the surrogate.
Authors: We acknowledge that Section III would benefit from greater explicitness. The recursion begins with the base case that any UE equipped with a pilot sequence is initially identifiable. It then iteratively computes the probability that an AP or UE becomes identifiable given the current state of its neighbors, using a threshold rule that an AP resolves its channels to a UE once at least one neighboring UE is identifiable (and symmetrically for data detection at UEs). The process terminates when the vector of identifiability probabilities converges or no further nodes can be updated. These details are implicit in the current derivation but will be stated explicitly in the revision, together with the precise propagation assumptions, to allow readers to evaluate robustness to correlations not captured by the surrogate. revision: yes
Circularity Check
No significant circularity; approximation is modeling choice with external validation
full rationale
The derivation approximates the BRGG by an independent-edge surrogate with matched degree distributions explicitly to enable tractable recursive probabilistic analysis. The identifiability region is obtained by applying the recursion to this surrogate model. Monte Carlo simulations on the original geometric model are used to validate both the region and the approximation accuracy. No equations reduce the output region to the input matching step by construction, no self-citations are load-bearing for the central claim, and no fitted parameters are renamed as predictions. The approach is a standard surrogate-model technique whose validity is checked externally rather than assumed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The spatially dependent graph model induced by wireless propagation can be approximated by a surrogate independent-edge random graph with matched degree distributions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.lean (D=3 forcing via linking)alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Karp-Sipser core... identifiability region as a function of AP and UE densities and the connectivity radius
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cell-free massive MIMO versus small cells,
H. Q. Ngo, A. Ashikhmin, H. Yang, E. G. Larsson, and T. L. Marzetta, “Cell-free massive MIMO versus small cells,”IEEE Trans. Wireless Commun., vol. 16, no. 3, pp. 1834–1850, 2017
work page 2017
-
[2]
On the total energy efficiency of cell-free massive MIMO,
H. Q. Ngo, L.-N. Tran, T. Q. Duong, M. Matthaiou, and E. G. Larsson, “On the total energy efficiency of cell-free massive MIMO,”IEEE Trans. Green Commun. Netw., vol. 2, no. 1, pp. 25–39, 2018
work page 2018
-
[3]
Next- generation multiple access with cell-free massive MIMO,
M. Mohammadi, Z. Mobini, H. Quoc Ngo, and M. Matthaiou, “Next- generation multiple access with cell-free massive MIMO,”Proc. IEEE, vol. 112, no. 9, pp. 1372–1420, 2024
work page 2024
-
[4]
R. Gholami, L. Cottatellucci, and D. Slock, “Tackling pilot contamina- tion in cell-free massive MIMO by joint channel estimation and linear multi-user detection,” inProc. IEEE Int. Symp. Inf. Theory (ISIT), 2021
work page 2021
-
[5]
Message passing for a bayesian semi-blind approach to cell-free massive MIMO,
——, “Message passing for a bayesian semi-blind approach to cell-free massive MIMO,” inProc. 55th Asilomar Conf. Signals, Syst., Comput., 2021
work page 2021
-
[6]
A. Karataev, C. Forsch, and L. Cottatellucci, “Bilinear expectation propagation for distributed semi-blind joint channel estimation and data detection in cell-free massive MIMO,”IEEE Open J. Signal Process., vol. 5, pp. 284–293, 2024
work page 2024
-
[7]
Z. Zhao and D. Slock, “Decentralized message-passing for semi-blind channel estimation in cell-free systems based on Bethe free energy optimization,” inProc. 58th Asilomar Conf. Signals, Syst., and Comput., 2024, pp. 1443–1447
work page 2024
-
[8]
Bayesian learning for pilot decontamination in cell-free massive MIMO,
C. Forsch, Z. Zhao, D. Slock, and L. Cottatellucci, “Bayesian learning for pilot decontamination in cell-free massive MIMO,” inProc. 28th Int. Workshop Smart Antennas (WSA), 2025, pp. 19–25
work page 2025
-
[9]
Subspace-based semi-blind channel estimation for user-centric cell-free massive MIMO systems,
B. Zhong, X. Zhu, and E. G. Lim, “Subspace-based semi-blind channel estimation for user-centric cell-free massive MIMO systems,” inProc. IEEE 99th Veh. Technol. Conf. (VTC2024-Spring), 2024, pp. 1–5
work page 2024
-
[10]
Z. Yang, Z. Li, T. Wang, L. Gao, and Y . Jiang, “A modified expectation maximization semi-blind channel estimation for symbiotic cell-free massive MIMO,” inProc. IEEE 102nd Veh. Technol. Conf. (VTC2025- Fall), 2025, pp. 1–6
work page 2025
-
[11]
Blind and semi-blind FIR multichan- nel estimation: (global) identifiability conditions,
E. de Carvalho and D. Slock, “Blind and semi-blind FIR multichan- nel estimation: (global) identifiability conditions,”IEEE Trans. Signal Process., vol. 52, no. 4, pp. 1053–1064, 2004
work page 2004
-
[12]
Maximum matching in sparse random graphs,
R. M. Karp and M. Sipser, “Maximum matching in sparse random graphs,” inProc. IEEE 22nd Annu. Symp. Found. Comput. Sci. (SFCS 1981), 1981, pp. 364–375
work page 1981
-
[13]
Maximum matchings in sparse random graphs: Karp-Sipser revisited,
J. Aronson, A. Frieze, and B. G. Pittel, “Maximum matchings in sparse random graphs: Karp-Sipser revisited,”J. Random Struct. Algorithms, vol. 12, no. 2, pp. 111–177, 1998
work page 1998
-
[14]
Core percolation in random graphs: a critical phenomena analysis,
M. Bauer and O. Golinelli, “Core percolation in random graphs: a critical phenomena analysis,”Eur. Phys. J. B, vol. 24, no. 3, pp. 339–352, 2001
work page 2001
-
[15]
A central limit theorem for the matching number of a sparse random graph,
M. Glasgow, M. Kwan, A. Sah, and M. Sawhney, “A central limit theorem for the matching number of a sparse random graph,”J. London Math. Soc., vol. 111, no. 4, p. e70101, 2025
work page 2025
-
[16]
Maximum matchings in random bipartite graphs and the space utilization of cuckoo hash tables,
A. Frieze and P. Melsted, “Maximum matchings in random bipartite graphs and the space utilization of cuckoo hash tables,”J. Random Struct. Algorithms, vol. 41, no. 3, pp. 334–364, 2012
work page 2012
-
[17]
Penrose,Random Geometric Graphs
M. Penrose,Random Geometric Graphs. Oxford University Press, 2003
work page 2003
-
[18]
Continuum AB percolation and AB random geometric graphs,
M. D. Penrose, “Continuum AB percolation and AB random geometric graphs,”J. Appl. Probability, vol. 51, no. A, pp. 333–344, 2014
work page 2014
-
[19]
On the critical threshold for continuum AB percolation,
D. Dereudre and M. Penrose, “On the critical threshold for continuum AB percolation,”J. Appl. Probability, vol. 55, no. 4, p. 1228–1237, 2018
work page 2018
-
[20]
D. J. Daley and D. Vere-Jones,An Introduction to the Theory of Point Processes, 2nd ed. Springer New York, 2003
work page 2003
-
[21]
T. Richardson and R. Urbanke,Modern Coding Theory. Cambridge University Press, 2008
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.