Controlling Decision Drift in Multimodal Sentiment Analysis with Missing Modalities
Pith reviewed 2026-05-19 21:41 UTC · model grok-4.3
pith:IDAIXY2P Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{IDAIXY2P}
Prints a linked pith:IDAIXY2P badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A two-level reference alignment framework maintains stable sentiment predictions under missing modalities by anchoring both features and decisions to complete samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
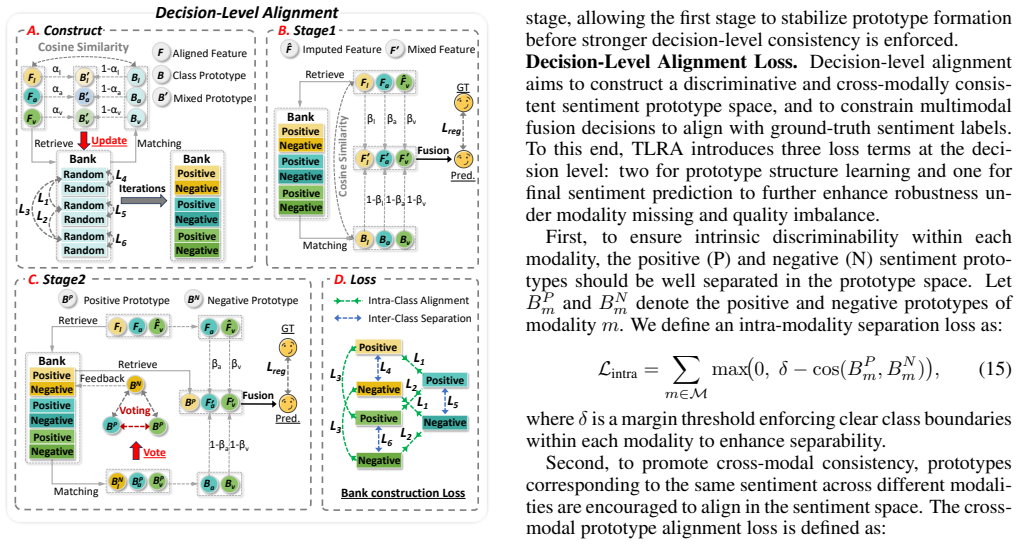
The framework introduces stable references at the feature representation and sentiment decision levels to improve robustness under modality missing. First-level reference alignment leverages complete-modality samples to constrain representations and align different modality combinations into a shared sentiment space. Second-level reference alignment enforces cross-modal consistency at the decision level by suppressing unreliable modalities through prototype retrieval and voting. As a result, the framework maintains stable and reliable sentiment predictions under diverse missing-modality patterns.
What carries the argument
Two-level reference alignment, in which complete-modality samples constrain and align representations at the feature level while prototype retrieval and voting enforce decision consistency at the output level.
If this is right
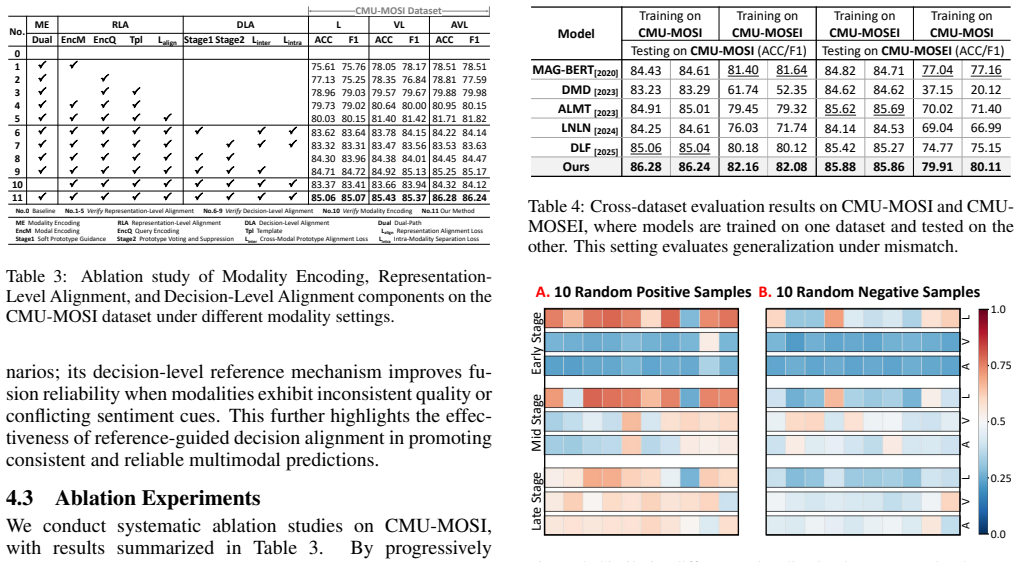
- The framework delivers consistent improvements across various missing-modality settings on CMU-MOSI and CMU-MOSEI.
- Under full-modality input it reaches state-of-the-art performance with 86.28% ACC and 86.24% F1 on MOSI and 85.88% ACC and 85.86% F1 on MOSEI.
- Representation shift across modality combinations is reduced because all combinations are pulled into one shared sentiment space.
- Unreliable modalities are prevented from dominating fusion through explicit suppression at the decision level.
Where Pith is reading between the lines
- The same anchoring strategy could be tested on other multimodal tasks such as emotion recognition or visual question answering where modality dropout is common.
- When complete-modality samples are scarce, the framework might require unsupervised or synthetic reference generation to remain effective.
- Decision-level prototype voting could be paired with temporal modeling to handle streaming inputs that lose modalities at different times.
Load-bearing premise
That complete-modality samples provide sufficiently stable references to constrain representations and align different modality combinations into a shared sentiment space without introducing new distribution shifts.
What would settle it
If removing either alignment level causes accuracy to drop sharply or variance across missing-modality patterns to rise on CMU-MOSEI, the claim that the references prevent drift would be falsified.
Figures


read the original abstract
Multimodal sentiment analysis relies on textual, acoustic, and visual signals, yet real-world data often suffer from modality missing and quality imbalance. Existing methods generate features for modality missing from available ones, but differences in expression mechanisms and sentiment dynamics across modalities may cause the generated features to deviate from true distributions and mislead prediction. In addition, unreliable modalities may dominate fusion, resulting in representation shift across modality combinations and unstable sentiment representations. To address these challenges, we propose a two-level reference alignment framework. The framework introduces stable references at the feature representation and sentiment decision levels to improve robustness under modality missing. First-level reference alignment leverages complete-modality samples to constrain representations and align different modality combinations into a shared sentiment space. Second-level reference alignment enforces cross-modal consistency at the decision level by suppressing unreliable modalities through prototype retrieval and voting. As a result, the framework maintains stable and reliable sentiment predictions under diverse missing-modality patterns. Experiments on CMU-MOSI and CMU-MOSEI show consistent improvements across various missing-modality settings. Under full-modality input, the proposed method achieves state-of-the-art performance, with ACC of 86.28% and 85.88%, and F1 of 86.24% and 85.86%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-level reference alignment framework for multimodal sentiment analysis to mitigate decision drift caused by missing modalities and unreliable signals. The first level uses complete-modality samples to constrain feature representations and map all modality combinations into a shared sentiment space. The second level applies prototype retrieval and voting to enforce decision-level consistency by downweighting unreliable modalities. Experiments on CMU-MOSI and CMU-MOSEI report state-of-the-art results under full-modality input (ACC 86.28%/85.88%, F1 86.24%/85.86%) and consistent gains across missing-modality patterns.
Significance. If the two-level alignment demonstrably prevents representation and decision drift without introducing new biases from the complete-sample anchors, the work would offer a practical advance for robust multimodal systems in noisy real-world settings. The dual-level design directly targets both feature and decision instability, which is a common failure mode in missing-modality literature. However, the absence of ablations, error bars, and distribution-shift diagnostics currently prevents a clear assessment of whether the reported gains are attributable to the proposed controls or to other factors.
major comments (2)
- [Abstract] Abstract and Experiments section: The central claim that the framework 'maintains stable and reliable sentiment predictions under diverse missing-modality patterns' rests on reported ACC/F1 numbers that lack error bars, ablation studies isolating each alignment level, and statistical significance tests against baselines. Without these controls it is impossible to determine whether the gains reflect genuine drift reduction or experimental variance.
- [§3.1] §3.1 (First-level reference alignment): The assumption that complete-modality samples serve as unbiased anchors to align all modality combinations into a shared space is load-bearing for the drift-control claim, yet no analysis is provided of potential distribution mismatch between complete and incomplete samples (e.g., class imbalance or recording-condition differences). If such mismatch exists, the alignment step could itself induce new representation shifts rather than suppress them.
minor comments (2)
- [§3.2] The description of prototype retrieval and voting in the second-level alignment would benefit from an explicit equation or pseudocode to clarify how prototypes are selected and how votes are aggregated.
- [Experiments] Table or figure captions for the missing-modality results should explicitly state the exact missing-pattern simulation protocol and the number of runs used for averaging.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our paper. We address the major concerns regarding empirical validation and potential biases in the reference alignment below, and we plan to incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: The central claim that the framework 'maintains stable and reliable sentiment predictions under diverse missing-modality patterns' rests on reported ACC/F1 numbers that lack error bars, ablation studies isolating each alignment level, and statistical significance tests against baselines. Without these controls it is impossible to determine whether the gains reflect genuine drift reduction or experimental variance.
Authors: We agree that additional statistical controls would enhance the credibility of our results. In the revised manuscript, we will report error bars from multiple random seeds, conduct ablation studies to isolate the contribution of each alignment level, and perform statistical significance tests (e.g., paired t-tests) comparing our method against the baselines. These additions will help attribute the performance gains to the proposed drift-control mechanisms. revision: yes
-
Referee: [§3.1] §3.1 (First-level reference alignment): The assumption that complete-modality samples serve as unbiased anchors to align all modality combinations into a shared space is load-bearing for the drift-control claim, yet no analysis is provided of potential distribution mismatch between complete and incomplete samples (e.g., class imbalance or recording-condition differences). If such mismatch exists, the alignment step could itself induce new representation shifts rather than suppress them.
Authors: This is a valid concern. While our framework is designed to use complete-modality samples as stable references, we did not explicitly analyze potential mismatches in the original submission. In the revision, we will include a new subsection or appendix with statistics comparing the class distributions and other metadata (such as recording conditions if available) between complete and incomplete samples in CMU-MOSI and CMU-MOSEI. We will also discuss any observed mismatches and their implications for the alignment process. revision: yes
Circularity Check
No significant circularity; method and claims are self-contained with external validation
full rationale
The paper introduces a two-level reference alignment framework that uses complete-modality samples for first-level alignment and prototype-based voting for second-level consistency. These steps are presented as novel design choices rather than reductions of fitted parameters or self-citations. Performance is measured on independent benchmarks (CMU-MOSI, CMU-MOSEI) with reported ACC/F1 scores under full and missing-modality conditions. No equations or derivations in the provided text reduce by construction to the inputs; the central claims rest on empirical results and the proposed architecture rather than tautological self-definition or load-bearing self-citation chains. This is the normal case of a method paper whose derivation chain remains independent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gated Multimodal Units for Information Fusion
[Arevaloet al., 2017 ] John Arevalo, Thamar Solorio, Manuel Montes-y G ´omez, and Fabio A Gonz ´alez. Gated multimodal units for information fusion.arXiv preprint arXiv:1702.01992,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Openface: an open source facial behavior analysis toolkit
[Baltruˇsaitiset al., 2016 ] Tadas Baltruˇsaitis, Peter Robinson, and Louis-Philippe Morency. Openface: an open source facial behavior analysis toolkit. InWACV, pages 1–10. IEEE,
work page 2016
-
[3]
Multimodal ma- chine learning: A survey and taxonomy.IEEE TPAMI, 41(2):423–443,
[Baltruˇsaitiset al., 2018 ] Tadas Baltru ˇsaitis, Chaitanya Ahuja, and Louis-Philippe Morency. Multimodal ma- chine learning: A survey and taxonomy.IEEE TPAMI, 41(2):423–443,
work page 2018
-
[4]
[Chenet al., 2025 ] Jili Chen, Yihua Zhong, Qionghao Huang, Changqin Huang, Fan Jiang, Xiaodi Huang, and Xun Wang. Ucmib-pns: Balancing sufficiency and ne- cessity with probabilistic causality and cross-modal uncer- tainty in multimodal sentiment analysis.IEEE TAC,
work page 2025
-
[5]
Unbiased missing-modality mul- timodal learning
[Daiet al., 2025 ] Ruiting Dai, Chenxi Li, Yandong Yan, Lisi Mo, Ke Qin, and Tao He. Unbiased missing-modality mul- timodal learning. InICCV, pages 24507–24517,
work page 2025
-
[6]
Bert: Pre-training of deep bidirectional transformers for language understand- ing
[Devlinet al., 2019 ] Jacob Devlin, Ming-Wei Chang, Ken- ton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understand- ing. InNAACL-HLT, pages 4171–4186,
work page 2019
-
[7]
[Guoet al., 2024 ] Zirun Guo, Tao Jin, and Zhou Zhao. Mul- timodal prompt learning with missing modalities for sen- timent analysis and emotion recognition.arXiv preprint arXiv:2407.05374,
-
[8]
[Hanet al., 2021 ] Wei Han, Hui Chen, and Soujanya Poria. Improving multimodal fusion with hierarchical mutual in- formation maximization for multimodal sentiment analy- sis.arXiv preprint arXiv:2109.00412,
-
[9]
Misa: Modality-invariant and-specific representations for multimodal sentiment analysis
[Hazarikaet al., 2020 ] Devamanyu Hazarika, Roger Zim- mermann, and Soujanya Poria. Misa: Modality-invariant and-specific representations for multimodal sentiment analysis. InACM MM, pages 1122–1131,
work page 2020
-
[10]
De- coupled multimodal distilling for emotion recognition
[Liet al., 2023 ] Yong Li, Yuanzhi Wang, and Zhen Cui. De- coupled multimodal distilling for emotion recognition. In CVPR, pages 6631–6640,
work page 2023
-
[11]
[Liet al., 2024 ] Mingcheng Li, Dingkang Yang, Yang Liu, Shunli Wang, Jiawei Chen, Shuaibing Wang, Jinjie Wei, Yue Jiang, Qingyao Xu, Xiaolu Hou, et al. Toward robust incomplete multimodal sentiment analysis via hierarchical representation learning.NIPS, 37:28515–28536,
work page 2024
-
[12]
[Lin and Hu, 2023] Ronghao Lin and Haifeng Hu. Miss- modal: Increasing robustness to missing modality in mul- timodal sentiment analysis.TACL, 11:1686–1702,
work page 2023
-
[13]
Efficient low-rank multimodal fusion with modality-specific factors
[Liuet al., 2018 ] Zhun Liu, Ying Shen, Varun Bharadhwaj Lakshminarasimhan, Paul Pu Liang, AmirAli Bagher Zadeh, and Louis-Philippe Morency. Efficient low-rank multimodal fusion with modality-specific factors. InACL, pages 2247–2256,
work page 2018
-
[14]
[Liuet al., 2024 ] Zhizhong Liu, Bin Zhou, Dianhui Chu, Yuhang Sun, and Lingqiang Meng. Modality translation- based multimodal sentiment analysis under uncertain missing modalities.Information Fusion, 101:101973,
work page 2024
-
[15]
[Liu, 2022] Bing Liu.Sentiment analysis and opinion min- ing. Springer Nature,
work page 2022
-
[16]
Robust-msa: Understand- ing the impact of modality noise on multimodal sentiment analysis
[Maoet al., 2023 ] Huisheng Mao, Baozheng Zhang, Hua Xu, Ziqi Yuan, and Yihe Liu. Robust-msa: Understand- ing the impact of modality noise on multimodal sentiment analysis. InAAAI, volume 37, pages 16458–16460,
work page 2023
-
[17]
librosa: Audio and music signal analysis in python.SciPy, 2015:18–24,
[McFeeet al., 2015 ] Brian McFee, Colin Raffel, Dawen Liang, Daniel PW Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto. librosa: Audio and music signal analysis in python.SciPy, 2015:18–24,
work page 2015
-
[18]
Moddrop: adap- tive multi-modal gesture recognition.IEEE TPAMI, 38(8):1692–1706,
[Neverovaet al., 2015 ] Natalia Neverova, Christian Wolf, Graham Taylor, and Florian Nebout. Moddrop: adap- tive multi-modal gesture recognition.IEEE TPAMI, 38(8):1692–1706,
work page 2015
-
[19]
[Phamet al., 2019 ] Hai Pham, Paul Pu Liang, Thomas Manzini, Louis-Philippe Morency, and Barnab ´as P ´oczos. Found in translation: Learning robust joint representations by cyclic translations between modalities. InAAAI, vol- ume 33, pages 6892–6899,
work page 2019
-
[20]
[Poriaet al., 2017 ] Soujanya Poria, Erik Cambria, Rajiv Ba- jpai, and Amir Hussain. A review of affective computing: From unimodal analysis to multimodal fusion.Informa- tion fusion, 37:98–125,
work page 2017
-
[21]
Integrating multimodal information in large pretrained transformers
[Rahmanet al., 2020 ] Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, AmirAli Bagher Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Ehsan Hoque. Integrating multimodal information in large pretrained transformers. InACL, pages 2359–2369,
work page 2020
-
[22]
Robust multimodal learning with missing modalities via parameter-efficient adaptation
[Rezaet al., 2024 ] Md Kaykobad Reza, Ashley Prater- Bennette, and M Salman Asif. Robust multimodal learning with missing modalities via parameter-efficient adaptation. IEEE TPAMI,
work page 2024
-
[23]
Multimodal transformer for un- aligned multimodal language sequences
[Tsaiet al., 2019 ] Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. Multimodal transformer for un- aligned multimodal language sequences. InACL, volume 2019, page 6558,
work page 2019
-
[24]
Words can shift: Dynamically adjusting word represen- tations using nonverbal behaviors
[Wanget al., 2019 ] Yansen Wang, Ying Shen, Zhun Liu, Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. Words can shift: Dynamically adjusting word represen- tations using nonverbal behaviors. InAAAI, volume 33, pages 7216–7223,
work page 2019
-
[25]
Cross-modal enhance- ment network for multimodal sentiment analysis.TMM, 25:4909–4921,
[Wanget al., 2022 ] Di Wang, Shuai Liu, Quan Wang, Yumin Tian, Lihuo He, and Xinbo Gao. Cross-modal enhance- ment network for multimodal sentiment analysis.TMM, 25:4909–4921,
work page 2022
-
[26]
Deep Multimodal Learning with Missing Modality: A Survey
[Wuet al., 2024 ] Renjie Wu, Hu Wang, Hsiang-Ting Chen, and Gustavo Carneiro. Deep multimodal learning with missing modality: A survey.arXiv preprint arXiv:2409.07825,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Trustworthy multimodal fusion for sentiment analysis in ordinal sentiment space
[Xieet al., 2024 ] Zhuyang Xie, Yan Yang, Jie Wang, Xi- aorong Liu, and Xiaofan Li. Trustworthy multimodal fusion for sentiment analysis in ordinal sentiment space. IEEE TCSVT, 34(8):7657–7670,
work page 2024
-
[28]
[Yuet al., 2021 ] Wenmeng Yu, Hua Xu, Ziqi Yuan, and Jiele Wu. Learning modality-specific representations with self- supervised multi-task learning for multimodal sentiment analysis. InAAAI, volume 35, pages 10790–10797,
work page 2021
-
[29]
[Yuet al., 2024 ] Xiaomin Yu, Feiyang Wang, and Ziyue Qiao. Spikemo: Enhancing emotion recognition with spik- ing temporal dynamics in conversations.arXiv preprint arXiv:2411.13917,
-
[30]
[Yuet al., 2026a ] Xiaomin Yu, Yijiang Li, Yuhui Zhang, Hanzhen Zhao, Yue Yang, Hao Tang, Yue Song, Xiaobin Hu, Chengwei Qin, Shuicheng Yan, et al. Anisotropic modality align.arXiv preprint arXiv:2605.07825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Modality Gap-Driven Subspace Alignment Training Paradigm For Multimodal Large Language Models
[Yuet al., 2026b ] Xiaomin Yu, Yi Xin, Yuhui Zhang, Wenjie Zhang, Chonghan Liu, Hanzhen Zhao, Chen Liu, Xiaox- ing Hu, Ziyue Qiao, Hao Tang, et al. Modality gap-driven subspace alignment training paradigm for multimodal large language models.arXiv preprint arXiv:2602.07026,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Transformer-based feature reconstruction net- work for robust multimodal sentiment analysis
[Yuanet al., 2021 ] Ziqi Yuan, Wei Li, Hua Xu, and Wen- meng Yu. Transformer-based feature reconstruction net- work for robust multimodal sentiment analysis. InACM MM, pages 4400–4407,
work page 2021
-
[33]
MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos
[Zadehet al., 2016 ] Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos.arXiv preprint arXiv:1606.06259,
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[34]
Mitigating inconsistencies in multimodal sentiment analysis under uncertain missing modalities
[Zenget al., 2022 ] Jiandian Zeng, Jiantao Zhou, and Tianyi Liu. Mitigating inconsistencies in multimodal sentiment analysis under uncertain missing modalities. InEMNLP, pages 2924–2934,
work page 2022
-
[35]
[Zhanget al., 2023 ] Haoyu Zhang, Yu Wang, Guanghao Yin, Kejun Liu, Yuanyuan Liu, and Tianshu Yu. Learn- ing language-guided adaptive hyper-modality representa- tion for multimodal sentiment analysis.arXiv preprint arXiv:2310.05804,
-
[36]
Towards robust multimodal sentiment analysis with incomplete data.NIPS, 37:55943–55974, 2024
[Zhanget al., 2024 ] Haoyu Zhang, Wenbin Wang, and Tian- shu Yu. Towards robust multimodal sentiment analysis with incomplete data.NIPS, 37:55943–55974, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.