QAM-W: Joint 2D Codebook Quantization for LLM Weights via Hadamard Rotation and Activation-Aware Scaling
Pith reviewed 2026-06-29 22:11 UTC · model grok-4.3
The pith
QAM-W recovers pairwise structure in LLM weight rows via Hadamard rotation and 2D codebook quantization, staying within 0.4 percent of BF16 perplexity at 5.5 bits per weight.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
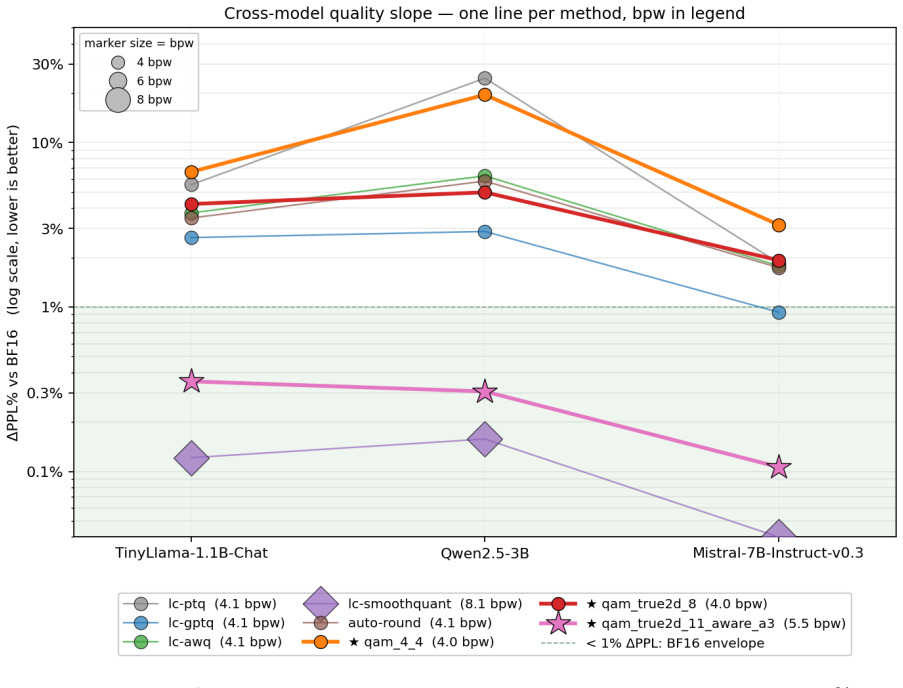
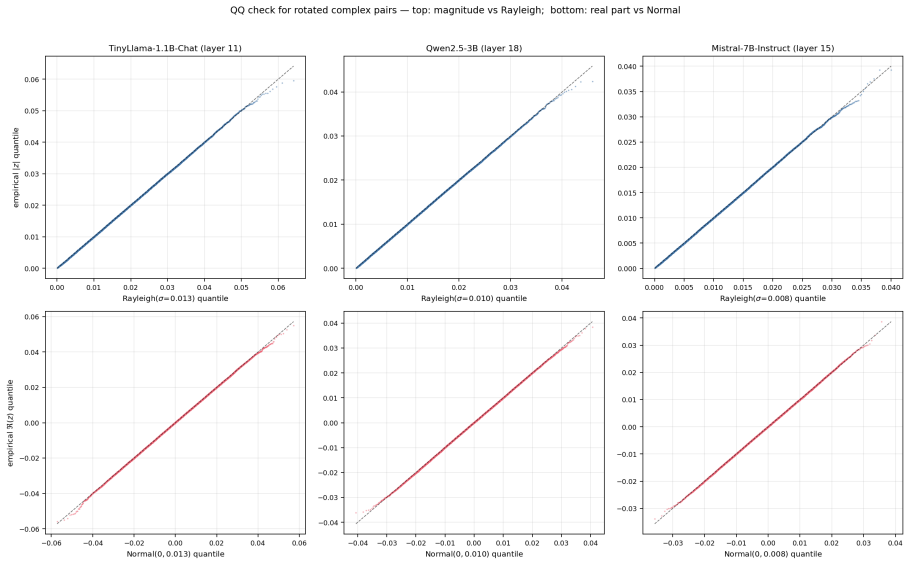
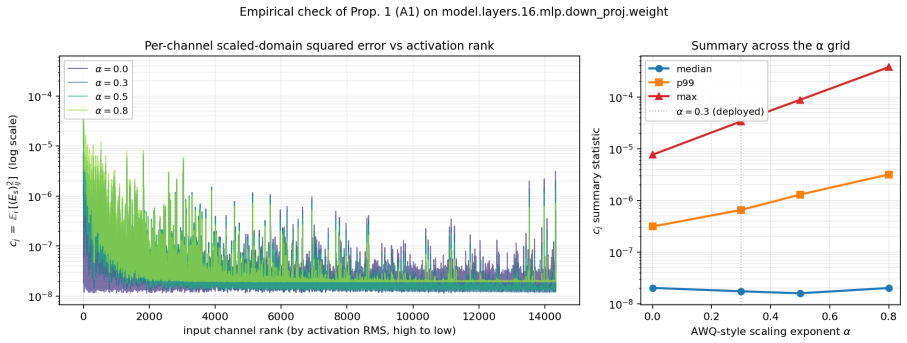
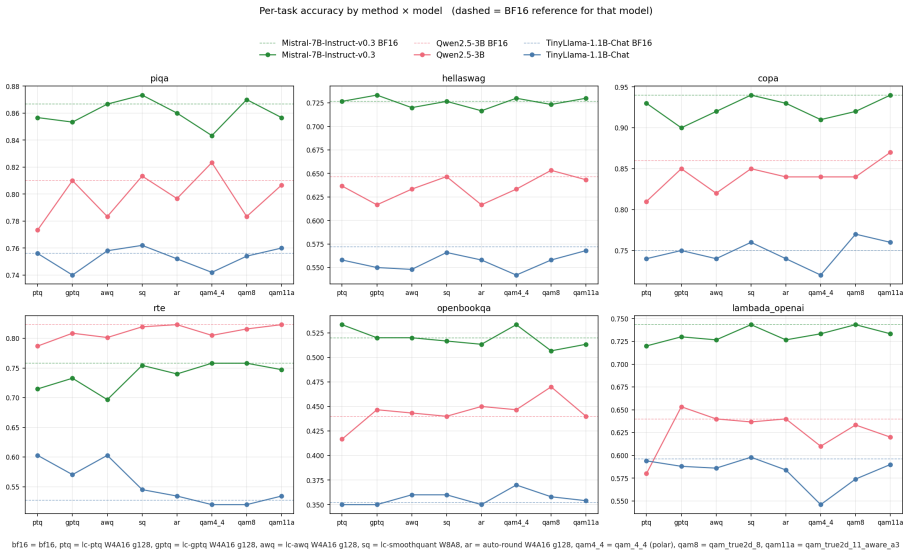
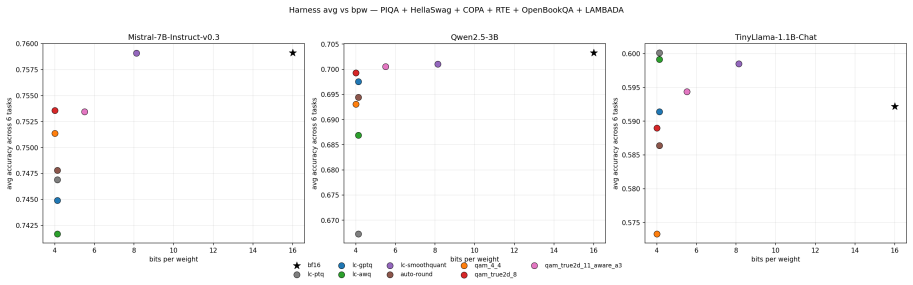
QAM-W quantizes LLM weights by L2-normalizing each row, applying a block-Hadamard rotation, pairing the rotated coordinates into 2D points, and mapping those points to a Lloyd-Max codebook trained on the unit circular Gaussian, with an additional activation-aware per-channel scaling factor; the resulting codec keeps perplexity within plus or minus 0.4 percent of BF16 at roughly 5.5 bits per weight across the tested models and configurations.
What carries the argument
Block-Hadamard rotation of normalized rows followed by 2D pairing and quantization against a single Lloyd-Max codebook trained on the unit circular Gaussian, combined with activation-aware per-channel scaling.
If this is right
- Joint 2D coding outperforms polar amplitude-by-phase coding by 2-15 percentage points in relative perplexity change at equal bitrate.
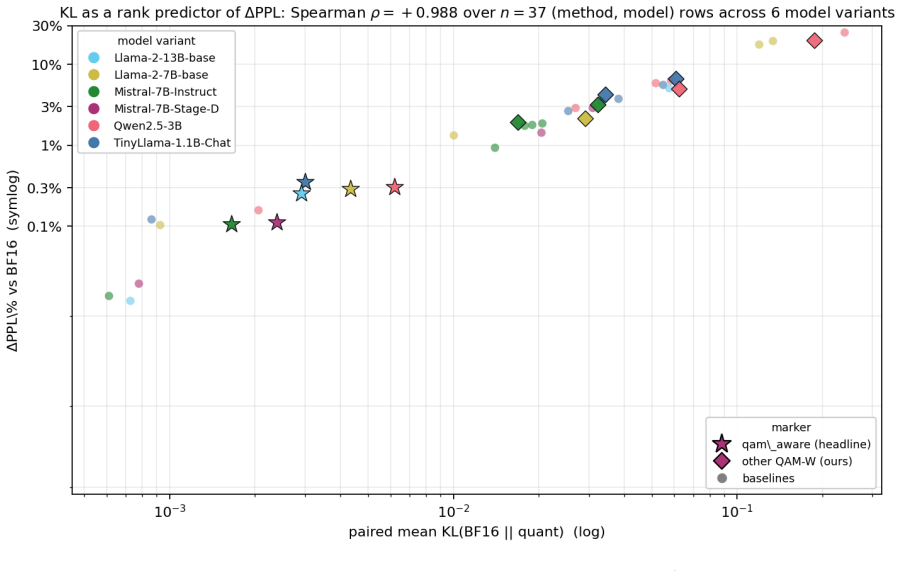
- Paired KL divergence against BF16 tracks relative perplexity change with Spearman correlation 0.99 across 37 method-model combinations.
- The activation-aware variant matches SmoothQuant W8A8 quality at 32 percent fewer weight bits.
- A 3.5 bpw configuration remains competitive on quantization-tolerant architectures.
- At strict 4 bpw the QTIP rotated-codebook method outperforms QAM-W.
Where Pith is reading between the lines
- The same rotation-plus-2D-pairing pattern could be tested on activation tensors or on attention matrices to reduce total model size further.
- The high KL-to-perplexity correlation suggests KL divergence on a small calibration set could serve as a fast proxy metric for ranking new quantizers.
- Applying the method to models larger than 13B or to instruction-tuned checkpoints would test whether the 0.4 percent bound holds outside the current range.
- Layer-wise adaptation of the codebook scale or rotation block size might close the remaining gap at 4 bpw.
Load-bearing premise
The Lloyd-Max codebook trained on the unit circular Gaussian remains near-optimal after the block-Hadamard rotation, and activation-aware scaling introduces no distribution shift large enough to invalidate the reported perplexity bounds.
What would settle it
Quantize one of the tested models at 5.5 bpw with QAM-W, evaluate perplexity on C4 or a downstream task suite, and check whether the deviation from BF16 exceeds 0.4 percent.
Figures
read the original abstract
Scalar post-training quantizers discard pairwise coordinate structure within weight rows. We introduce QAM-W (Quadrature Amplitude Modulation for Weights), a codec that recovers this structure: each row is L2-normalized, block-Hadamard rotated, paired into 2D coordinates, and quantized against a single Lloyd-Max codebook trained on the unit circular Gaussian, with activation-aware per-channel scaling. In a cross-model study spanning five LLMs from four families (1.1B--13B parameters) and eight quantized configurations, the activation-aware variant at $\approx 5.5$ bpw stays within $\pm 0.4\%$ of BF16 WikiText-2 perplexity on every model, matching the SmoothQuant W8A8 quality envelope at $32\%$ fewer weight bits. Joint 2D coding outperforms polar (amplitude $\times$ phase) coding by 2--15~pp $\Delta$PPL at equal bitrate, and paired KL against BF16 tracks $\Delta$PPL\% at Spearman $\rho = 0.99$ across 37 (method, model) rows, consistent with a monotone composite bound from codec distortion to KL divergence. A 3.5~bpw variant is competitive on quantization-tolerant architectures. At strict 4~bpw, the rotated-codebook frontier method QTIP outperforms QAM-W; the contribution is the quality-preserving 5--6~bpw band.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QAM-W, a post-training weight quantization codec for LLMs that L2-normalizes each row, applies block-Hadamard rotation, pairs coordinates into 2D, and quantizes against a fixed Lloyd-Max codebook trained on the unit circular Gaussian, augmented by activation-aware per-channel scaling. Across five models (1.1B–13B) from four families and eight configurations, the activation-aware variant at ≈5.5 bpw is reported to stay within ±0.4% of BF16 WikiText-2 perplexity, matching SmoothQuant W8A8 quality at 32% fewer bits; joint 2D coding beats polar coding, and paired KL tracks ΔPPL% with Spearman ρ=0.99 over 37 rows. A 3.5 bpw variant is competitive on tolerant architectures, while QTIP is noted as superior at strict 4 bpw.
Significance. If the empirical claims hold after verification, the work would demonstrate that recovering pairwise coordinate structure via rotation and 2D coding can preserve LLM quality at 5–6 bpw, offering a practical middle ground between 4 bpw and 8 bpw methods. The reported high Spearman correlation between KL and perplexity change provides suggestive support for a distortion-to-PPL link, and the cross-model, cross-bitwidth scope strengthens the result if protocols are complete. The contribution is localized to the 5–6 bpw regime rather than claiming broad superiority.
major comments (3)
- [Abstract] Abstract: the central performance claim (activation-aware QAM-W at ≈5.5 bpw stays within ±0.4% of BF16 PPL on every model) rests on the unverified assumption that L2-normalized, block-Hadamard-rotated, activation-scaled 2D coordinates remain sufficiently close to the unit circular Gaussian for the fixed Lloyd-Max codebook to stay near-optimal; no histogram, marginal KL, or ablation confirming post-transform distribution match is referenced, which directly affects whether the reported quality is a property of the codec or an artifact of the tested models.
- [Abstract] Abstract: the monotone composite bound from codec distortion to KL to PPL is asserted to explain the Spearman ρ=0.99 but is not derived or proven; without the derivation or an explicit statement that the 37-row correlation was pre-specified, the correlation cannot be treated as confirmatory evidence for the bound.
- [Abstract] Abstract / experimental description: no error bars, dataset splits, full training/evaluation protocol, or verification that the 37-row Spearman analysis was pre-registered are supplied, rendering the central cross-model claim impossible to assess for statistical reliability.
minor comments (1)
- [Abstract] Abstract: the exact definition of 'bpw' (including overhead for scaling factors) and the precise pairing strategy after Hadamard rotation should be stated explicitly rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with clarifications and proposed changes to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (activation-aware QAM-W at ≈5.5 bpw stays within ±0.4% of BF16 PPL on every model) rests on the unverified assumption that L2-normalized, block-Hadamard-rotated, activation-scaled 2D coordinates remain sufficiently close to the unit circular Gaussian for the fixed Lloyd-Max codebook to stay near-optimal; no histogram, marginal KL, or ablation confirming post-transform distribution match is referenced, which directly affects whether the reported quality is a property of the codec or an artifact of the tested models.
Authors: We agree that explicit verification of the post-transform distribution would strengthen the central claim. The Hadamard rotation is selected because it is known to approximately Gaussianize and decorrelate coordinates for a wide range of input distributions, and L2 normalization enforces unit scale. To directly address the concern, we will add histograms of the rotated 2D coordinates, marginal KL values to the unit circular Gaussian, and an ablation removing the rotation in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the monotone composite bound from codec distortion to KL to PPL is asserted to explain the Spearman ρ=0.99 but is not derived or proven; without the derivation or an explicit statement that the 37-row correlation was pre-specified, the correlation cannot be treated as confirmatory evidence for the bound.
Authors: The manuscript states the correlation is 'consistent with' a monotone composite bound rather than claiming a formal derivation or proof. The observed ρ=0.99 provides empirical support for using paired KL as a proxy but does not constitute confirmatory evidence of a bound. We will revise the wording to remove any implication of a proven bound and clarify that the relationship is empirical. revision: partial
-
Referee: [Abstract] Abstract / experimental description: no error bars, dataset splits, full training/evaluation protocol, or verification that the 37-row Spearman analysis was pre-registered are supplied, rendering the central cross-model claim impossible to assess for statistical reliability.
Authors: We will expand the experimental section with the complete evaluation protocol, including WikiText-2 splits and quantization procedure. Error bars will be added for main results via repeated runs with different seeds. The 37-row Spearman analysis was exploratory rather than pre-registered; we will state this explicitly. revision: partial
- Verification that the 37-row Spearman analysis was pre-registered (it was not pre-registered)
Circularity Check
No circularity; results are direct empirical measurements on measured perplexity
full rationale
The paper defines a quantization procedure (L2 normalization + block-Hadamard rotation + 2D pairing + fixed Lloyd-Max codebook trained on unit circular Gaussian + activation-aware scaling) and reports measured WikiText-2 perplexity on five LLMs. No equation or claim reduces a reported quantity to a fitted parameter by construction, no self-citation chain supports a load-bearing uniqueness result, and no 'prediction' is statistically forced from the training distribution. The asserted monotone bound from distortion to KL to PPL is not used to derive the numerical results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Information Process- ing Systems (NeurIPS)
QuaRot: Outlier-free 4-bit inference in rotated LLMs. InAdvances in Neural Information Process- ing Systems (NeurIPS). Hicham Badri and Appu Shaji. 2023. Half-quadratic quantization of large machine learning models. https://mobiusml.github.io/hqq_blog/. 8 Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. PIQA: Reasoning about...
-
[2]
InProceedings of the 41st International Conference on Machine Learning (ICML)
Extreme compression of large language mod- els via additive quantization. InProceedings of the 41st International Conference on Machine Learning (ICML). Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2023. GPTQ: Accurate post-training quantization for generative pre-trained transformers. InInternational Conference on Learning Representa...
2023
-
[3]
Measuring massive multitask language under- standing. InICLR. Albert Q Jiang, Alexandre Sablayrolles, Arthur Men- sch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guil- laume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Llama 2: Open Foundation and Fine-Tuned Chat Models
VPTQ: Extreme low-bit vector post-training quantization for large language models. InEmpirical Methods in Natural Language Processing (EMNLP). Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoor- thi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. 2025. SpinQuant: LLM quantization with learned rotations. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Qwen2.5 technical report.arXiv preprint arXiv:2412.15115. Paul L Zador. 1982. Asymptotic quantization error of continuous signals and the quantization dimen- sion.IEEE Transactions on Information Theory, 28(2):139–149. Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a machine really finish your sentence? InAnnu...
work page internal anchor Pith review Pith/arXiv arXiv 1982
-
[6]
bounded constant independent of s
Combining with (27) gives DKL(p∥q)≲ L2 4 X ℓ ∥Xℓ∆W ⊤ ℓ ∥F 2 ,(29) valid in the regime where the cubic remainder is small relative to the quadratic term. Proof. Taylor expansion of softmax cross-entropy around logits f. The first-order term vanishes be- cause KL is minimized at q=p , and the Hes- sian is Fp. The operator-norm bound ∥Fp∥2 ≤ 1/2 follows from...
1982
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.