MI-CXR: A Benchmark for Longitudinal Reasoning over Multi-Interval Chest X-rays
Pith reviewed 2026-05-20 19:49 UTC · model grok-4.3
The pith
Vision-language models achieve only 29.3% accuracy on multi-visit chest X-ray reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
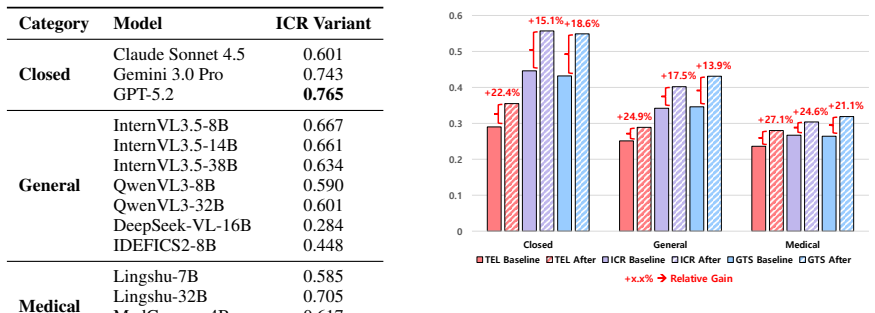
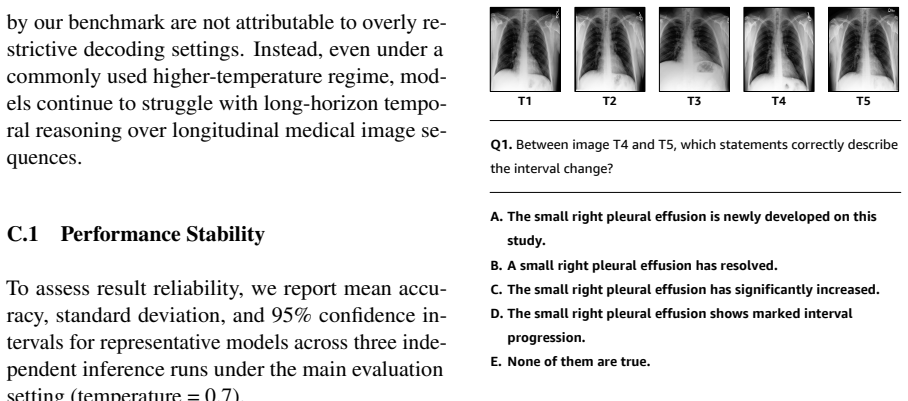
MI-CXR instantiates clinically grounded visual reasoning over time through five-way multiple-choice questions on five-visit patient timelines and shows that state-of-the-art vision-language models average 29.3 percent accuracy while producing locally plausible interval descriptions that nevertheless violate temporal constraints and lack global consistency.
What carries the argument
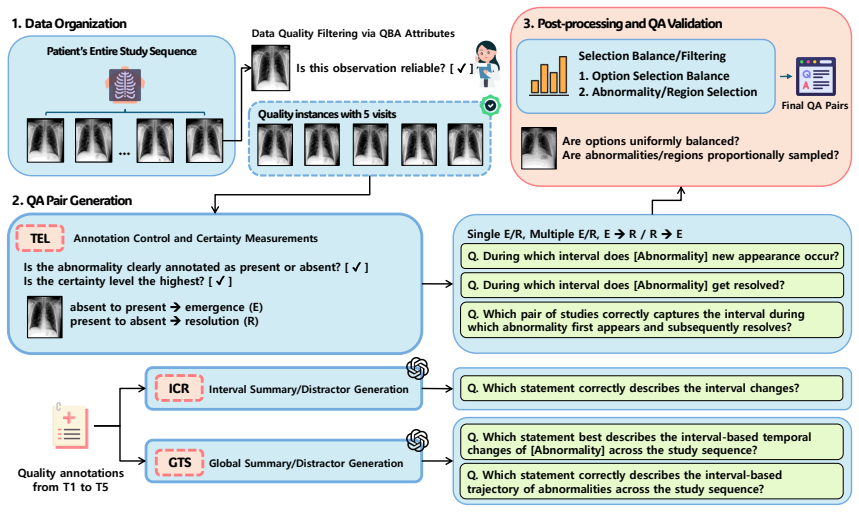
The MI-CXR benchmark of five-way multiple-choice questions over five-visit CXR sequences, which probes for enforcement of temporal constraints and composition of evidence into globally consistent decisions.
If this is right
- Models require explicit mechanisms to enforce temporal order when processing sequences of medical images.
- Global consistency across an entire patient timeline must be checked separately from local interval accuracy.
- Current vision-language models remain limited for reliable longitudinal monitoring of disease progression.
- Benchmarks focused on multi-interval reasoning can expose gaps that single-image or short-pair tests miss.
Where Pith is reading between the lines
- Training procedures that explicitly reward temporal ordering and cross-interval consistency could close part of the observed gap.
- The same evaluation approach could be applied to other sequential imaging modalities such as CT or MRI follow-ups.
- In practice, low global consistency may cause models to miss slow disease trends that span multiple visits.
Load-bearing premise
That five-way multiple-choice questions over five visits, without free-form report generation or extra clinical context, accurately capture clinically grounded visual reasoning over time.
What would settle it
A future model that scores near perfect accuracy on the MI-CXR questions yet still produces temporally inconsistent or contradictory statements when asked to generate free-form longitudinal reports on real patient sequences.
Figures





















read the original abstract
Longitudinal chest X-ray (CXR) interpretation requires reasoning over disease evolution across multiple patient visits, yet most existing medical VQA benchmarks focus on single images or short-horizon image pairs. We introduce MI-CXR, a benchmark for standardized evaluation of Multi-Interval longitudinal reasoning over multi-visit CXR sequences, without requiring free-form report generation or additional clinical context. MI-CXR comprises five-way multiple-choice questions over five-visit patient timelines and instantiates three complementary task families: Temporal Event Localization, Interval-wise Change Reasoning, and Global Trajectory Summarization, which assess clinically grounded visual reasoning over time. Evaluating 14 state-of-the-art vision-language models (VLMs) shows low overall performance, with an average accuracy of 29.3%, only modestly above random guessing. Using stage-wise diagnostic probing, we find that models often produce locally plausible interval descriptions but fail to enforce temporal constraints or compose evidence into globally consistent decisions over the full timeline. These findings reveal key limitations of current VLMs and establish MI-CXR as a principled benchmark for longitudinal medical reasoning. The benchmark is available at https://github.com/AIDASLab/MI-CXR
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MI-CXR, a benchmark for standardized evaluation of multi-interval longitudinal reasoning over five-visit chest X-ray timelines. It defines three task families (Temporal Event Localization, Interval-wise Change Reasoning, and Global Trajectory Summarization) instantiated as five-way multiple-choice questions without free-form generation or extra clinical context. Evaluation of 14 VLMs reports 29.3% average accuracy (modestly above random), with stage-wise probing showing models produce locally plausible descriptions but fail to enforce temporal constraints or achieve global consistency.
Significance. If the questions are validated to require full-timeline integration, the work is significant for filling a gap in medical VQA benchmarks focused on single images or pairs. It provides a reproducible public resource (GitHub link) that exposes concrete limitations in current VLMs for clinically grounded temporal reasoning over disease evolution, supporting targeted progress in longitudinal medical AI.
major comments (1)
- [Benchmark Construction / Question Design] The manuscript provides no quantitative validation (e.g., radiologist ratings of question difficulty, ablation removing all but one interval, or shortcut-detection experiments) that the five-way MCQs over five-visit timelines cannot be solved from static visual features in a single image or adjacent pair. This is load-bearing for the central claim in the abstract and §4 that the 29.3% accuracy and probing results demonstrate specific failure at 'enforcing temporal constraints or compose evidence into globally consistent decisions'; without it, the performance gap may reflect local shortcuts rather than a longitudinal reasoning deficit.
minor comments (2)
- [Abstract] The abstract and results would benefit from an explicit statement of the random baseline (20% for five-way MCQ) alongside the 29.3% figure to better contextualize 'modestly above random guessing'.
- [Data Curation] Provide more detail on inter-annotator agreement and quality control during question creation to strengthen the claim of clinical groundedness.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address the major comment below and commit to revisions that incorporate additional validation experiments to strengthen the claims regarding longitudinal reasoning requirements.
read point-by-point responses
-
Referee: [Benchmark Construction / Question Design] The manuscript provides no quantitative validation (e.g., radiologist ratings of question difficulty, ablation removing all but one interval, or shortcut-detection experiments) that the five-way MCQs over five-visit timelines cannot be solved from static visual features in a single image or adjacent pair. This is load-bearing for the central claim in the abstract and §4 that the 29.3% accuracy and probing results demonstrate specific failure at 'enforcing temporal constraints or compose evidence into globally consistent decisions'; without it, the performance gap may reflect local shortcuts rather than a longitudinal reasoning deficit.
Authors: We acknowledge that the current manuscript does not include explicit quantitative validation such as radiologist ratings, single-interval ablations, or dedicated shortcut-detection experiments to empirically confirm that the questions cannot be solved without full-timeline integration. The task families were designed to require multi-interval reasoning (e.g., Temporal Event Localization specifies identifying the exact visit of an event among five, and Global Trajectory Summarization requires synthesizing the overall disease progression), and the stage-wise probing already indicates models generate locally plausible outputs yet fail at global consistency. Nevertheless, to directly address this concern and support the central claim, we will add shortcut-detection experiments (e.g., performance on single-image or adjacent-pair inputs) and radiologist validation of question difficulty in the revised manuscript. These results will be reported in a new subsection of §3 or §4. revision: yes
Circularity Check
No significant circularity in benchmark construction or evaluation
full rationale
The paper introduces a new dataset and benchmark (MI-CXR) consisting of five-way MCQs over five-visit timelines across three task families, then reports direct empirical results from evaluating 14 VLMs (average 29.3% accuracy). No equations, fitted parameters, or derivations are present that reduce predictions to inputs by construction. The central claims rest on newly created questions and data rather than self-citation chains, ansatz smuggling, or renaming of known results. The evaluation is self-contained against external model performance and does not presuppose its own conclusions via definitional loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiple-choice questions over five-visit patient timelines can assess clinically grounded visual reasoning over time without free-form report generation or additional clinical context.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MI-CXR comprises five-way multiple-choice questions over five-visit patient timelines and instantiates three complementary task families: Temporal Event Localization, Interval-wise Change Reasoning, and Global Trajectory Summarization
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Evaluating 14 state-of-the-art vision-language models shows low overall performance, with an average accuracy of 29.3%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A dataset of clinically generated visual questions and answers about radiology images , author=. Scientific data , volume=. 2018 , publisher=
work page 2018
-
[2]
PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals , author=. circulation , volume=. 2000 , publisher=
work page 2000
-
[3]
PathVQA: 30000+ Questions for Medical Visual Question Answering
PathVQA: 30000+ Questions for Medical Visual Question Answering , author=. arXiv preprint arXiv:2003.10286 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[4]
MMXU: A Multi-Modal and Multi-X-ray Understanding Dataset for Disease Progression , author=. 2025 , eprint=
work page 2025
-
[5]
TemMed-Bench: Evaluating Temporal Medical Image Reasoning in Vision-Language Models , author=. 2025 , eprint=
work page 2025
-
[6]
Lunguage: A Benchmark for Structured and Sequential Chest X-ray Interpretation , author=. 2025 , eprint=
work page 2025
-
[7]
CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays , author=. 2025 , eprint=
work page 2025
-
[8]
Journal of Biomedical Informatics , volume=
Review of Temporal Reasoning in the Clinical Domain for Timeline Extraction: Where we are and where we need to be , author=. Journal of Biomedical Informatics , volume=. 2021 , issn=
work page 2021
-
[9]
Nature Communications , volume=
Predicting treatment response from longitudinal images using multi-task deep learning , author=. Nature Communications , volume=. 2021 , doi=
work page 2021
-
[10]
The Need for Medical Artificial Intelligence That Incorporates Prior Images , author=. Radiology , volume=. 2022 , doi=
work page 2022
-
[11]
Longitudinal Image Data for Outcome Modeling , author=. Clinical Oncology , volume=. 2025 , doi=
work page 2025
-
[12]
PriorRG: Prior-Guided Contrastive Pre-training and Coarse-to-Fine Decoding for Chest X-ray Report Generation , author=. 2025 , eprint=
work page 2025
-
[13]
HERGen: Elevating Radiology Report Generation with Longitudinal Data , author=. 2024 , eprint=
work page 2024
-
[14]
Liu, Kang and Ma, Zhuoqi and Kang, Xiaolu and Li, Yunan and Xie, Kun and Jiao, Zhicheng and Miao, Qiguang , year=. Enhanced Contrastive Learning with Multi-view Longitudinal Data for Chest X-ray Report Generation , url=. doi:10.1109/cvpr52734.2025.00968 , booktitle=
-
[15]
Insights into a radiology-specialised multimodal large language model with sparse autoencoders , author=. 2025 , eprint=
work page 2025
-
[16]
MIMIC-Ext-CXR-QBA: A Structured, Tagged, and Localized Visual Question Answering Dataset with Question-Box-Answer Triplets and Scene Graphs for Chest X-ray Images , author=. 2025 , howpublished=
work page 2025
-
[17]
MIMIC-CXR-JPG: Chest Radiographs with Structured Labels , author=. 2024 , howpublished=
work page 2024
-
[18]
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs
MIMIC-CXR: A Large Publicly Available Database of Labeled Chest Radiographs , author=. arXiv preprint arXiv:1901.07042 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[19]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning , author=. 2025 , eprint=
work page 2025
-
[20]
Zhang, Kai and Zhou, Rong and Adhikarla, Eashan and Yan, Zhiling and Liu, Yixin and Yu, Jun and Liu, Zhengliang and Chen, Xun and Davison, Brian D. and Ren, Hui and Huang, Jing and Chen, Chen and Zhou, Yuyin and Fu, Sunyang and Liu, Wei and Liu, Tianming and Li, Xiang and Chen, Yong and He, Lifang and Zou, James and Li, Quanzheng and Liu, Hongfang and Sun...
- [21]
-
[22]
MedVLM-R1: Incentivizing Medical Reasoning Capability of Vision-Language Models (VLMs) via Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[23]
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day , author=. 2023 , eprint=
work page 2023
-
[24]
and Lausen, Mads and Bruun, Niels Henrik and Nielsen, Michael Bachmann and Zacho, Helle D
Lange, Mine Benedicte and Petersen, Lars J. and Lausen, Mads and Bruun, Niels Henrik and Nielsen, Michael Bachmann and Zacho, Helle D. , TITLE =. Diagnostics , VOLUME =. 2022 , NUMBER =
work page 2022
-
[25]
K. White and K. Berbaum and W. L. Smith , title =. Investigative Radiology , year =. doi:10.1097/00004424-199403000-00002 , pmid =
-
[26]
Insights into Imaging , year =
Li Zhang and Xin Wen and Jian-Wei Li and Xu Jiang and Xian-Feng Yang and Meng Li , title =. Insights into Imaging , year =. doi:10.1186/s13244-023-01521-7 , url =
-
[27]
SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering , author=. 2021 , eprint=
work page 2021
-
[28]
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering , author=. 2024 , eprint=
work page 2024
-
[29]
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale , author=. 2024 , eprint=
work page 2024
-
[30]
Bae, Seongmin and Kyung, Donghyun and Ryu, Jaeho and Cho, Eunji and Lee, Gyeongmin and Kweon, Seungwoo and Oh, Jaehun and Ji, Limin and Chang, Eunsol and Kim, Taeyoung and Choi, Edward , title =. 2024 , version =. doi:10.13026/deqx-d943 , url =
-
[31]
EHRXQA: A Multi-Modal Question Answering Dataset for Electronic Health Records with Chest X-ray Images , author=. 2023 , eprint=
work page 2023
-
[32]
CheXpert Plus: Augmenting a Large Chest X-ray Dataset with Text Radiology Reports, Patient Demographics and Additional Image Formats , author=. 2024 , eprint=
work page 2024
-
[33]
Libra: Leveraging Temporal Images for Biomedical Radiology Analysis , author=. 2025 , eprint=
work page 2025
-
[34]
Pretraining Vision-Language Model for Difference Visual Question Answering in Longitudinal Chest X-rays , author=. 2024 , eprint=
work page 2024
-
[35]
Hu, Xinyue and Gu, Lin and An, Qiyuan and Zhang, Mengliang and Liu, Liangchen and Kobayashi, Kazuma and Harada, Tatsuya and Summers, Ronald M. and Zhu, Yingying , title =. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =. 2023 , isbn =. doi:10.1145/3580305.3599819 , abstract =
-
[36]
Describing and Localizing Multiple Changes with Transformers , author=. 2021 , eprint=
work page 2021
-
[37]
ReXrank: A Public Leaderboard for AI-Powered Radiology Report Generation , author=. 2024 , eprint=
work page 2024
-
[38]
Anchored Answers: Unravelling Positional Bias in GPT-2's Multiple-Choice Questions , author=. 2025 , eprint=
work page 2025
-
[39]
Large Language Models Are Not Robust Multiple Choice Selectors , author=. 2024 , eprint=
work page 2024
- [40]
- [41]
- [42]
- [43]
-
[44]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding , author=. 2024 , eprint=
work page 2024
-
[49]
OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents , author=. 2023 , eprint=
work page 2023
-
[50]
What matters when building vision-language models? , author=. 2024 , eprint=
work page 2024
-
[51]
Evaluating Step-by-step Reasoning Traces: A Survey , author=. 2025 , eprint=
work page 2025
-
[52]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
work page 2023
-
[53]
MRGAgents: A Multi-Agent Framework for Improved Medical Report Generation with Med-LVLMs , author=. 2025 , eprint=
work page 2025
-
[54]
CoMT: Chain-of-Medical-Thought Reduces Hallucination in Medical Report Generation , author=. 2025 , eprint=
work page 2025
-
[55]
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT , author=. 2020 , eprint=
work page 2020
-
[56]
Guo*, Li and Tahir, Anas M. and Zhang, Dong and Wang, Z. Jane and Ward, Rabab K. , year=. Automatic Medical Report Generation: Methods and Applications , volume=. APSIPA Transactions on Signal and Information Processing , publisher=. doi:10.1561/116.20240044 , number=
-
[57]
Towards Predicting Temporal Changes in a Patient's Chest X-ray Images based on Electronic Health Records , author=. 2025 , eprint=
work page 2025
-
[58]
Mingyu Zhang and Chenglong Xu and Yihong Gan and Yu Wang and Yi Fu and Yongqiang Chen , keywords =. Automating construction contract question answering using large language model and fine-tuning , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.eswa.2025.129493 , url =
-
[59]
BleedOrigin: Dynamic Bleeding Source Localization in Endoscopic Submucosal Dissection via Dual-Stage Detection and Tracking , author=. 2025 , eprint=
work page 2025
-
[60]
Mann, Ritse M. , title =. The Lancet , year =. doi:10.1016/S0140-6736(25)00093-5 , url =
-
[61]
Hoang, Jenny K. , title =. Journal of the American College of Radiology , year =. doi:10.1016/j.jacr.2015.10.017 , url =
-
[62]
Holste, G. and Lin, M. and Zhou, R. and others , title =. npj Digital Medicine , year =. doi:10.1038/s41746-024-01207-4 , url =
-
[63]
Longitudinal Image Data for Outcome Modeling , journal =
J.E. Longitudinal Image Data for Outcome Modeling , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.clon.2024.06.053 , url =
-
[64]
Large Language Models are Zero-Shot Reasoners , volume =
Kojima, Takeshi and Gu, Shixiang (Shane) and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , booktitle =. Large Language Models are Zero-Shot Reasoners , volume =
-
[65]
Vedantam, Ramakrishna and Lawrence Zitnick, C. and Parikh, Devi , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[66]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
work page 2004
-
[67]
METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
Banerjee, Satanjeev and Lavie, Alon. METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 2005
work page 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.