Self-supervised Hierarchical Visual Reasoning with World Model
Pith reviewed 2026-05-20 12:37 UTC · model grok-4.3
The pith
A world model hierarchy based on residual reconstruction achieves state-of-the-art efficiency in self-supervised visual reasoning for reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
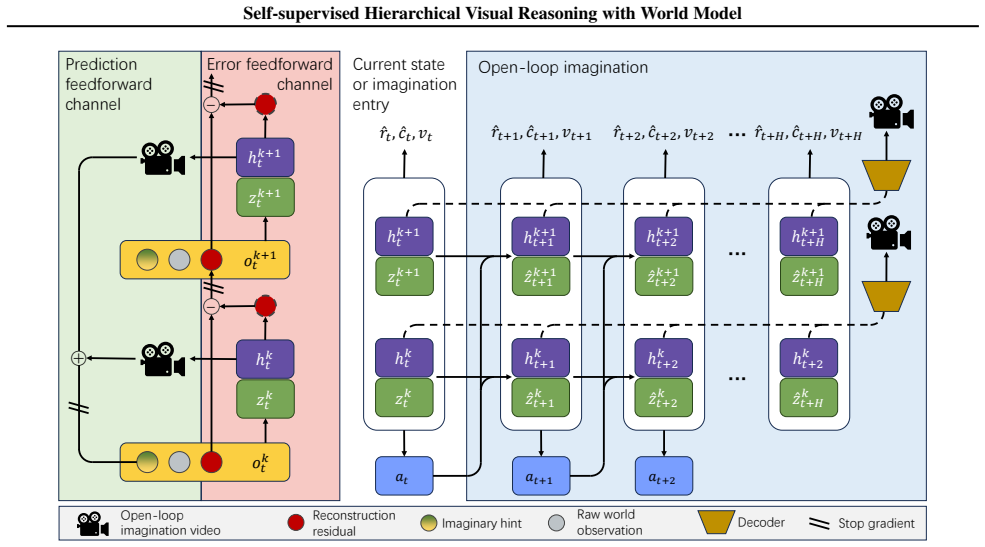
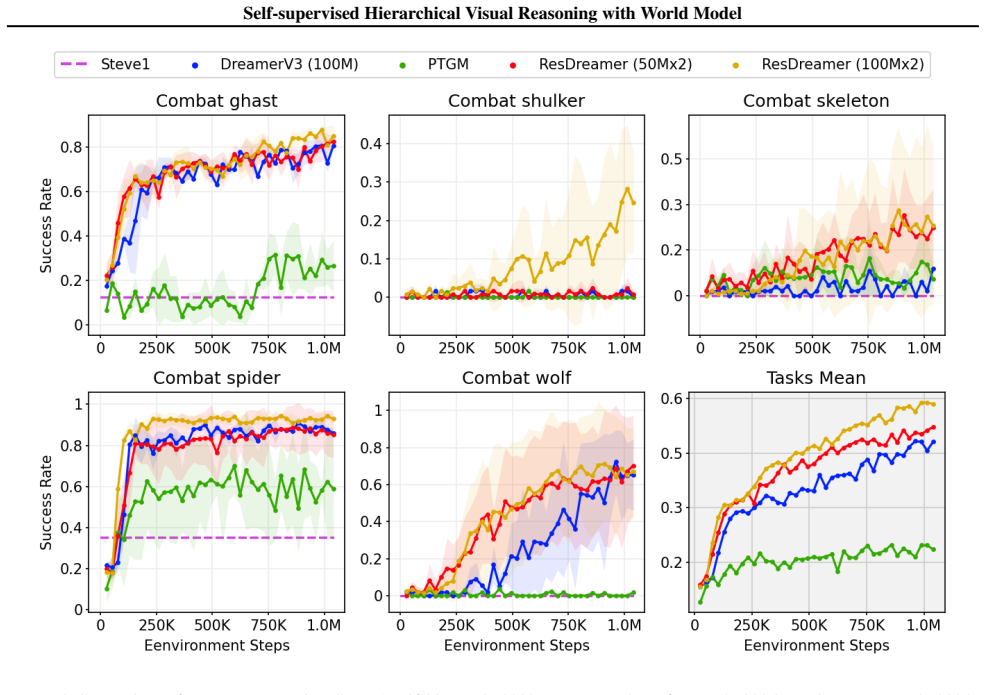
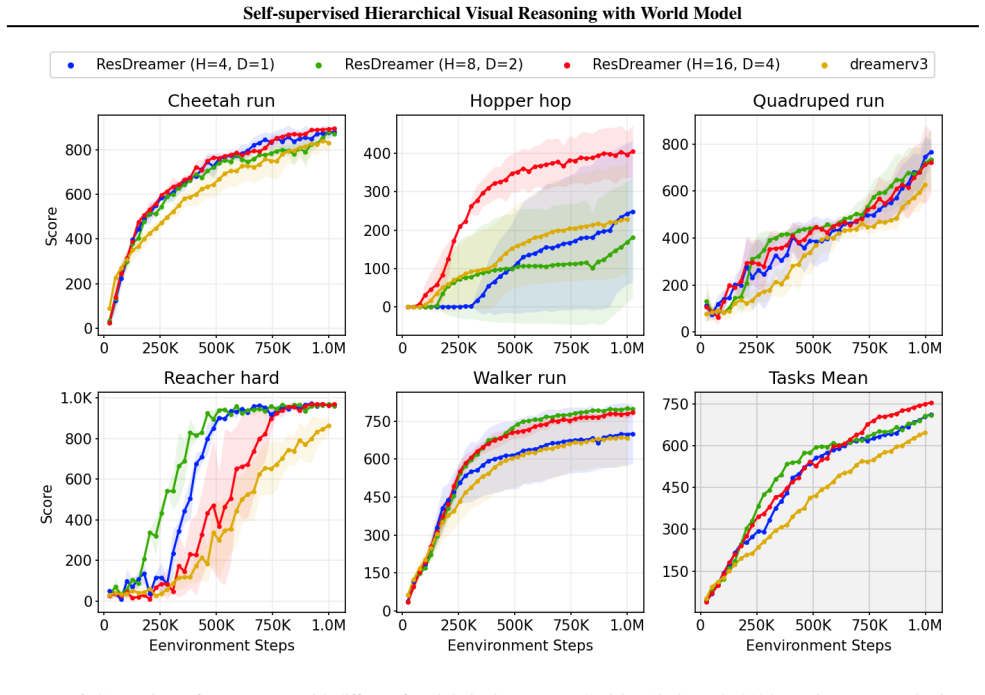
The central claim is that a hierarchical world model in which each higher-level layer is trained to reconstruct the residuals of the layer below enables progressive abstraction of sophisticated world dynamics and the emergence of richer latent representations. These higher-level residual representations then modulate lower-level predictions. The design allows the model to scale with only linearly increasing cross-layer communication costs and supports fully self-supervised training. Experiments demonstrate that this yields state-of-the-art sample efficiency and parameter efficiency in 3D open-world environments with adversarial opponents.
What carries the argument
Residual reconstruction across hierarchical layers, where each higher layer is trained to predict the difference from the lower layer's output in order to build more abstract and informative representations for visual foresight.
If this is right
- Higher layers supply modulation signals that improve the accuracy of lower-level predictions in the world model.
- The architecture maintains only linearly increasing cross-layer communication costs as the number of layers grows.
- Richer latent representations emerge that carry informative, task-relevant signals without requiring photorealistic output fidelity.
- State-of-the-art sample efficiency and parameter efficiency are reached in 3D open-world reinforcement learning settings.
- The method supports development of more capable online RL agents in open-ended and dynamic environments.
Where Pith is reading between the lines
- The residual hierarchy could be tested in non-visual reinforcement learning domains such as robotics control to check for similar efficiency gains.
- Residual connections may offer a general way to limit error growth in any multi-step predictive model used for long-horizon planning.
- Experiments in environments with greater visual complexity or larger numbers of opponents could show whether the linear scaling property continues to hold.
- This design might reduce the need to inject domain-specific knowledge into world models for achieving stable multi-step reasoning.
Load-bearing premise
The assumption that training higher layers to reconstruct residuals of lower layers will produce richer, more informative latent representations that reduce multi-step error accumulation without introducing new instabilities.
What would settle it
Direct comparison experiments in the same 3D open-world environments with adversarial opponents that show no reduction in multi-step prediction error or no gains in agent sample efficiency when using the residual hierarchy versus a flat non-hierarchical baseline would falsify the central claim.
Figures





read the original abstract
3D open-world environments with adversarial opponents remain a core challenge for reinforcement learning due to their vast state spaces. Effective reasoning representations are essential in such settings. While existing self-supervised visual foresight reasoning approaches often suffer from multi-step error accumulation, many recent studies resort to injecting domain-specific knowledge for more stable guidance. Our key insight is that the photorealistic fidelity of visual reasoning representations is secondary; what truly matters is providing informative, task-relevant signals. To this end, we propose ResDreamer, a hierarchical world model in which each higher-level layer is trained to reconstruct the residuals of the layer below. This design enables progressive abstraction of increasingly sophisticated world dynamics and fosters the emergence of richer latent representations. Drawing inspiration from the "Bitter Lesson", ResDreamer trains its reasoning representations in a purely self-supervised manner. The higher-level residual representations are used to modulate lower-level predictions, allowing the world model to scale effectively with only linearly increasing cross-layer communication costs. Experiments show that ResDreamer achieves state-of-the-art sample efficiency and parameter efficiency. This scalable hierarchical visual foresight reasoning architecture paves the way for more capable online RL agents in open-ended, dynamic environments. The code is accessible at https://github.com/XuYuanFei01/ResDreamer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ResDreamer, a hierarchical world model for self-supervised visual reasoning in 3D open-world RL environments with adversarial opponents. Higher layers are trained to reconstruct residuals of lower layers to produce richer, task-relevant latent representations that reduce multi-step error accumulation; these modulate lower-level predictions with linearly scaling communication costs. The model is trained purely self-supervised following the Bitter Lesson, and experiments claim state-of-the-art sample and parameter efficiency for downstream RL agents.
Significance. If the efficiency gains hold and are attributable to the residual hierarchy, the work could advance scalable world-model RL in complex dynamic settings by avoiding domain-specific priors and multi-step compounding errors. The public code release at https://github.com/XuYuanFei01/ResDreamer is a positive for reproducibility.
major comments (2)
- [§5] §5 (Experimental Results): the central efficiency claims rest on the residual reconstruction objective producing richer latents that curb compounding errors, yet no ablation is reported that compares against a matched-capacity hierarchical baseline trained to reconstruct full lower-layer outputs rather than residuals. Without this control or held-out multi-step rollout MSE, it remains possible that gains arise from capacity, modulation details, or schedule rather than the residual mechanism itself.
- [§4] §4 (Model Architecture): the modulation of lower-level predictions by higher-level residual representations is described at a high level; more precise equations or pseudocode are needed to verify the claimed linear cross-layer communication cost and to assess potential instability from residual training.
minor comments (2)
- [Abstract] Abstract: the phrase 'state-of-the-art sample efficiency and parameter efficiency' should be accompanied by the specific baselines and quantitative margins for immediate context.
- [§3] Notation: the distinction between residual reconstruction loss and standard reconstruction loss should be clarified with explicit loss equations to avoid ambiguity in the hierarchical training procedure.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We address each major comment below and commit to revisions that directly strengthen the manuscript's claims regarding the residual hierarchy.
read point-by-point responses
-
Referee: [§5] §5 (Experimental Results): the central efficiency claims rest on the residual reconstruction objective producing richer latents that curb compounding errors, yet no ablation is reported that compares against a matched-capacity hierarchical baseline trained to reconstruct full lower-layer outputs rather than residuals. Without this control or held-out multi-step rollout MSE, it remains possible that gains arise from capacity, modulation details, or schedule rather than the residual mechanism itself.
Authors: We agree that this control experiment is necessary to isolate the benefit of residual reconstruction. In the revised manuscript we will add a matched-capacity hierarchical baseline that reconstructs full lower-layer outputs (rather than residuals) and report held-out multi-step rollout MSE for both models. This will allow direct comparison of compounding error and confirm that the efficiency gains are attributable to the residual objective rather than capacity or scheduling differences. revision: yes
-
Referee: [§4] §4 (Model Architecture): the modulation of lower-level predictions by higher-level residual representations is described at a high level; more precise equations or pseudocode are needed to verify the claimed linear cross-layer communication cost and to assess potential instability from residual training.
Authors: We acknowledge that the current description of cross-layer modulation is high-level. The revised Section 4 will include explicit equations defining the residual modulation operation, the communication cost between layers, and pseudocode for the forward pass. We will also add a short analysis of training dynamics under residual objectives to address potential instability concerns. revision: yes
Circularity Check
No circularity: architectural proposal and empirical results are self-contained
full rationale
The paper introduces ResDreamer as an explicit architectural design choice—a hierarchical world model in which higher layers are trained to reconstruct residuals of lower layers—motivated by the insight that task-relevant signals matter more than photorealistic fidelity and drawing inspiration from the Bitter Lesson for purely self-supervised training. The central claims of improved sample and parameter efficiency are presented as outcomes of experiments in 3D open-world adversarial environments rather than any mathematical derivation that reduces to fitted parameters or prior self-citations by construction. No equations or load-bearing steps equate the residual objective or modulation mechanism to the reported efficiency metrics; the approach remains an independent proposal with external experimental validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Photorealistic fidelity of visual reasoning representations is secondary to providing informative, task-relevant signals.
invented entities (1)
-
ResDreamer hierarchical residual world model
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
each higher-level layer is trained to reconstruct the residuals of the layer below... modeling visual reconstruction residuals... transmitting only unexpected surprise
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.