Zero-Shot Faithful Textual Explanations via Directional-Derivative Influence on Predictions
Pith reviewed 2026-05-19 20:16 UTC · model grok-4.3
pith:IL6PIF3P Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{IL6PIF3P}
Prints a linked pith:IL6PIF3P badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
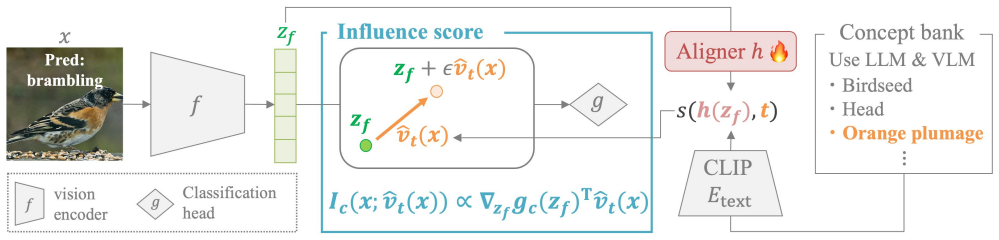
FaithTrace generates more faithful zero-shot textual explanations for image classifiers by using directional derivatives of class logits in feature space as a faithfulness proxy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FaithTrace measures the influence of a textual explanation by computing the directional derivative of the class logit along the text-induced direction in the classifier's feature space and treats this value as a proxy for faithfulness, thereby selecting or ranking explanations that more accurately reflect the features underlying the model's decision.
What carries the argument
The influence score, computed as the directional derivative of the class logit along the text-induced direction in the classifier's feature space.
If this is right
- Explanations produced by FaithTrace more closely track the actual features that change the model's output.
- The same influence score supplies quantitative metrics that can rank or evaluate textual explanations for faithfulness.
- Zero-shot textual explanations become feasible for any image classifier whose feature space is accessible, without extra labeled data.
- Model transparency improves because explanations are tied directly to changes in the prediction logit rather than to external text-image alignment.
Where Pith is reading between the lines
- The directional-derivative approach could extend to other modalities such as audio or tabular classifiers if their feature spaces allow analogous text or concept directions.
- If the proxy holds, it may reduce the need for post-hoc methods that require large vision-language models for explanation generation.
- Applying the score across multiple layers or heads of the classifier could reveal which internal representations most affect faithfulness.
Load-bearing premise
The directional derivative of the class logit along a text-induced direction in feature space serves as a valid proxy for the true faithfulness of the textual explanation to the model's decision process.
What would settle it
A direct test would be to remove or mask the visual concepts described in a high-influence explanation and measure whether the model's class logit changes by an amount proportional to the reported influence score; a consistent mismatch would falsify the proxy.
Figures





read the original abstract
Zero-shot textual explanations aim to make image classifiers more transparent by probing their internal representations, without relying on task-specific supervision or LVLMs. However, existing methods often miss the features that truly drive the prediction, resulting in limited \textit{faithfulness} to the evidence underlying the model's decision. To address this, we propose FaithTrace. Motivated by the idea that faithful explanations should describe concepts that strongly influence the prediction, FaithTrace directly measures how much the representation induced by the explanation changes the class logit. We introduce an influence score, computed as the directional derivative of the class logit along the text-induced direction in the classifier's feature space, and use it as a proxy for faithfulness. Moreover, we extend this influence score into quantitative evaluation metrics, helping fill the gap in faithfulness evaluation for textual explanations. Experiments show that FaithTrace yields more faithful explanations than baselines, facilitating a more accurate understanding of the model. The code will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FaithTrace, a zero-shot method for generating faithful textual explanations of image classifier predictions. It defines an influence score as the directional derivative of the class logit along the direction in feature space induced by the explanation text, using this score as a proxy for faithfulness. The approach extends the score to quantitative faithfulness evaluation metrics and claims that experiments demonstrate superior faithfulness over baselines.
Significance. If the directional-derivative proxy is shown to be valid, the work would provide a principled, supervision-free way to both generate and quantitatively evaluate textual explanations, addressing a noted gap in faithfulness assessment for zero-shot textual methods in computer vision. The parameter-free nature of the influence computation and the extension to metrics are strengths that could enable reproducible comparisons across models.
major comments (2)
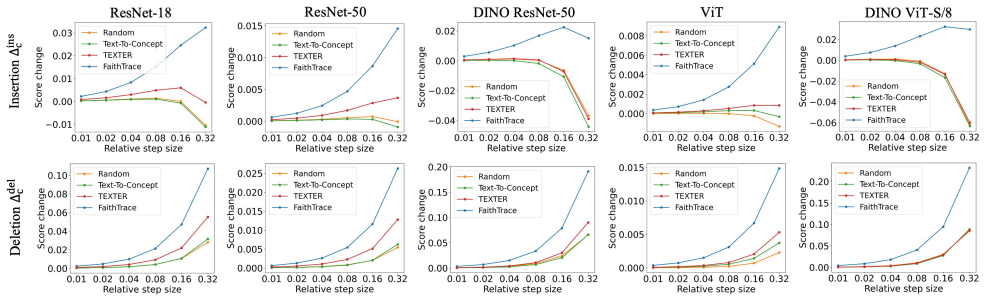
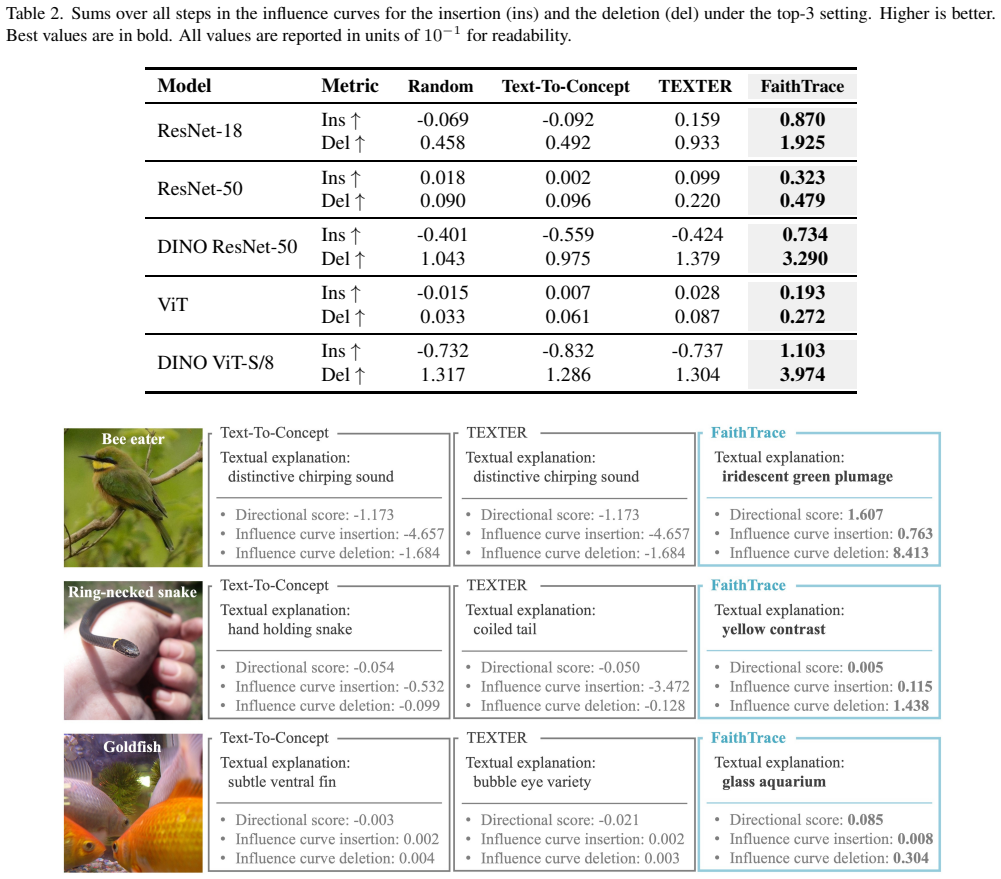
- [Abstract and §5] Abstract and §5 (Experiments): the claim that FaithTrace 'yields more faithful explanations than baselines' is presented without any description of datasets, baselines, statistical significance tests, or controls. This information is load-bearing for the central empirical claim and must be supplied to allow verification.
- [§3] §3 (Method, influence-score definition): the directional derivative is used both to rank candidate explanations and to construct the quantitative faithfulness metrics. Because the same first-order quantity serves as both the ranking criterion and the evaluation target, an independent validation (e.g., against human judgments or perturbation-based ground truth) is required to rule out circularity in the faithfulness assessment.
minor comments (2)
- [§3] The notation for the text-induced direction vector and the precise definition of the directional derivative should be written as an explicit equation with all symbols defined.
- [§5] Figure captions and axis labels in the experimental results should explicitly state which faithfulness metric is plotted and which baselines are compared.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, indicating where we agree that revisions are needed and outlining the specific changes we will make.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experiments): the claim that FaithTrace 'yields more faithful explanations than baselines' is presented without any description of datasets, baselines, statistical significance tests, or controls. This information is load-bearing for the central empirical claim and must be supplied to allow verification.
Authors: We agree that the abstract's high-level claim would benefit from more immediate context. While Section 5 of the manuscript already details the datasets (ImageNet and COCO subsets), the baselines (including concept activation vectors and other zero-shot textual methods), statistical significance testing (paired t-tests with reported p-values), and controls (random and shuffled explanations), we will revise the abstract to include a concise summary of the evaluation protocol. We will also add an explicit statement in the opening of Section 5 reiterating these elements for readers who focus on the empirical claims. This revision will be made. revision: yes
-
Referee: [§3] §3 (Method, influence-score definition): the directional derivative is used both to rank candidate explanations and to construct the quantitative faithfulness metrics. Because the same first-order quantity serves as both the ranking criterion and the evaluation target, an independent validation (e.g., against human judgments or perturbation-based ground truth) is required to rule out circularity in the faithfulness assessment.
Authors: We acknowledge the potential for circularity when the same directional-derivative quantity is used both to select explanations and to define the faithfulness metrics. To address this directly, we will add a new subsection to the experiments that reports independent validation: (1) correlation of the influence-based scores with human faithfulness ratings collected on a held-out subset of 200 image-explanation pairs, and (2) perturbation experiments that mask image regions corresponding to the textual concepts and measure the resulting change in class logit. These results will be presented alongside the existing metrics to show alignment with external signals. This revision will be made. revision: yes
Circularity Check
Influence score used both to select explanations and to define the faithfulness metrics that evaluate them
specific steps
-
self definitional
[Abstract]
"we introduce an influence score, computed as the directional derivative of the class logit along the text-induced direction in the classifier's feature space, and use it as a proxy for faithfulness. Moreover, we extend this influence score into quantitative evaluation metrics"
The influence score is simultaneously the quantity maximized by FaithTrace to produce explanations and the basis for the quantitative faithfulness metrics used to demonstrate superiority. Consequently the reported improvement in faithfulness is equivalent to the selection criterion by definition.
full rationale
The paper defines an influence score via directional derivative and explicitly uses it as the proxy for faithfulness while extending the identical score into the quantitative evaluation metrics. Because FaithTrace selects or ranks textual explanations according to this same influence score, any claim that it produces higher-scoring (i.e., more faithful) explanations on the derived metrics follows by construction rather than from independent validation. This matches the self-definitional pattern: the central empirical result reduces to the definition of the metric itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The directional derivative along the text-induced direction accurately reflects the influence of the described concept on the prediction.
invented entities (1)
-
FaithTrace influence score
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
influence score, computed as the directional derivative of the class logit along the text-induced direction in the classifier’s feature space
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
gc(zf + ϵ v̂t(x)) − gc(zf) via first-order Taylor
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., et al.: Gpt-4 technical report, arXiv: 2303. 08774, 2023 1, 2
work page 2023
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P ., Lin , J., Zhou, C., Zhou, J.: Qwen-vl: A versatile vision-languag e model for understanding, localization, text reading, and b e- yond. arXiv preprint arXiv:2308.12966 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
In: Advances in Neural Information Processing Sys- tems (NeurIPS) (2024) 2
Balasubramanian, S., Basu, S., Feizi, S.: Decomposing a nd interpreting image representations via text in vits beyond CLIP. In: Advances in Neural Information Processing Sys- tems (NeurIPS) (2024) 2
work page 2024
-
[4]
In: 2017 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR)
Bau, D., Zhou, B., Khosla, A., Oliva, A., Torralba, A.: Ne t- work Dissection: Quantifying Interpretability of Deep Vi- sual Representations . In: 2017 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 3319– 3327 (2017) 2, 1
work page 2017
-
[5]
In: Proceedings of t he IEEE International Conference on Computer Vision (ICCV) (2021) 6
Caron, M., Touvron, H., Misra, I., J´ egou, H., Mairal, J., Bojanowski, P ., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of t he IEEE International Conference on Computer Vision (ICCV) (2021) 6
work page 2021
-
[6]
Dani, M., Rio-Torto, I., Alaniz, S., Akata, Z.: Devil: De cod- ing vision features into language. CoRR (2023) 1
work page 2023
-
[7]
I n: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. I n: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR). pp. 248–255 (2009) 6
work page 2009
-
[8]
In: The International Conference on Learning Rep- resentations (ICLR) (2021) 6
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenbor n, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: The International Conference on Learning Rep- resentations (ICLR) (2021) 6
work page 2021
-
[9]
In: Advances in Neural Information Process- ing Systems (NeurIPS) (2023) 2, 8, 9
FEL, T., Boissin, T., Boutin, V ., Picard, A.M., Novello, P ., Colin, J., Linsley, D., ROUSSEAU, T., Cadene, R., Goetschalckx, L., Gardes, L., Serre, T.: Unlocking feature visualization for deep network with MAgnitude constrained optimization. In: Advances in Neural Information Process- ing Systems (NeurIPS) (2023) 2, 8, 9
work page 2023
-
[10]
In: The International Conference on Learning Representa- tions (ICLR) (2024) 2
Gandelsman, Y ., Efros, A.A., Steinhardt, J.: Interpre ting CLIP’s image representation via text-based decomposition . In: The International Conference on Learning Representa- tions (ICLR) (2024) 2
work page 2024
- [11]
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
He, K., Zhang, X., Ren, S., Sun, J.: Deep Residual Learni ng for Image Recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 770–778 (2016) 6
work page 2016
-
[13]
In: Leibe, B., Matas, J., Sebe, N., Welling, M
Hendricks, L.A., Akata, Z., Rohrbach, M., Donahue, J., Schiele, B., Darrell, T.: Generating visual explanations. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Pro- ceedings of the European Conference on Computer Vision (ECCV). pp. 3–19 (2016) 2, 1
work page 2016
-
[14]
In: Proceedings of the International Conference on Machine Learning (ICML)
Kim, B., Wattenberg, M., Gilmer, J., Cai, C.J., Wexler, J., Vi´ egas, F.B., Sayres, R.: Interpretability beyond feature attri- bution: Quantitative testing with concept activation vect ors (tcav). In: Proceedings of the International Conference on Machine Learning (ICML). vol. 80, pp. 2673–2682 (2018) 2, 1
work page 2018
-
[15]
In: Pro- ceedings of the International Conference on Machine Learn- ing (ICML) (2020) 1, 2
Koh, P .W., Nguyen, T., Tang, Y .S., Mussmann, S., Pierso n, E., Kim, B., Liang, P .: Concept bottleneck models. In: Pro- ceedings of the International Conference on Machine Learn- ing (ICML) (2020) 1, 2
work page 2020
-
[16]
In: Proceedings of the 39th In- ternational Conference on Machine Learning
Li, J., Li, D., Xiong, C., Hoi, S.: BLIP: Bootstrapping language-image pre-training for unified vision-language u n- derstanding and generation. In: Proceedings of the 39th In- ternational Conference on Machine Learning. vol. 162, pp. 12888–12900 (2022) 1, 2
work page 2022
-
[17]
In: Advances in Neural Information Processing Sys- tems
Liu, H., Li, C., Wu, Q., Lee, Y .J.: Visual instruction tu n- ing. In: Advances in Neural Information Processing Sys- tems. vol. 36, pp. 34892–34916 (2023) 1, 2
work page 2023
-
[18]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Liu, Y ., Zhang, T., Gu, S.: Hybrid concept bottleneck mo d- els. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 20179– 20189 (June 2025) 1
work page 2025
-
[19]
Menon, S., V ondrick, C.: Visual classification via desc ription from large language models (2023) 2
work page 2023
-
[20]
In: Proceed- ings of the International Conference on Machine Learning (ICML) (2023) 1, 2, 3, 6
Moayeri, M., Rezaei, K., Sanjabi, M., Feizi, S.: Text-t o- concept (and back) via cross-model alignment. In: Proceed- ings of the International Conference on Machine Learning (ICML) (2023) 1, 2, 3, 6
work page 2023
-
[21]
In: Proceedings o f the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Nguyen, A., Clune, J., Bengio, Y ., Dosovitskiy, A., Y os in- ski, J.: Plug & play generative networks: Conditional itera - tive generation of images in latent space. In: Proceedings o f the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3510–3520 (2017) 9
work page 2017
-
[22]
In: Advances in Neural Information Processing Systems (NeurIPS)
Nguyen, A., Dosovitskiy, A., Y osinski, J., Brox, T., Clune, J.: Synthesizing the preferred inputs for neurons in neural net - works via deep generator networks. In: Advances in Neural Information Processing Systems (NeurIPS). p. 3395–3403 (2016) 9
work page 2016
-
[23]
In: The International Con- ference on Learning Representations (ICLR) (2023) 1, 2
Oikarinen, T., Das, S., Nguyen, L.M., Weng, T.W.: Label - free concept bottleneck models. In: The International Con- ference on Learning Representations (ICLR) (2023) 1, 2
work page 2023
-
[24]
Olah, C., Schubert, L., Mordvintsev, A.: Feature visua liza- tion. Distill (2017) 2, 9
work page 2017
-
[25]
https://platform.openai.com/docs/models/gpt-3-5 (2025), accessed 2025-10-13 4
OpenAI: Gpt-3.5 turbo models. https://platform.openai.com/docs/models/gpt-3-5 (2025), accessed 2025-10-13 4
work page 2025
-
[26]
Park, D.H., Hendricks, L.A., Akata, Z., Rohrbach, A., Schiele, B., Darrell, T., Rohrbach, M.: Multimodal expla- nations: Justifying decisions and pointing to the evidence . In: Proceedings of the IEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR) (June 2018) 2, 1
work page 2018
-
[27]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G. , Agarwal, S., Sastry, G., Askell, A., Mishkin, P ., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual mod- els from natural language supervision. In: Proceedings of t he International Conference on Machine Learning (ICML). pp. 8748–8763 (2021) 1, 3 10
work page 2021
-
[28]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners. OpenAI (2019) 1
work page 2019
-
[29]
Salewski, L., Koepke, A.S., Lensch, H.P .A., Akata, Z.: Zero- shot translation of attention patterns in vqa models to natu - ral language. In: Pattern Recognition. pp. 378–393. Cham (2024) 2
work page 2024
-
[30]
In: Proce ed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV) Workshops
Sammani, F., Deligiannis, N.: Uni-nlx: Unifying textu al ex- planations for vision and vision-language tasks. In: Proce ed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV) Workshops. pp. 4634–4639 (October 2023) 1, 2
work page 2023
-
[31]
In: The International Conference on Learnin g Representations (ICLR) (2025) 1, 2
Sammani, F., Deligiannis, N.: Zero-shot natural langu age explanations. In: The International Conference on Learnin g Representations (ICLR) (2025) 1, 2
work page 2025
-
[32]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR)
Sammani, F., Mukherjee, T., Deligiannis, N.: Nlx-gpt: A model for natural language explanations in vision and vision- language tasks. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 8322–8332 (June 2022) 1, 2
work page 2022
-
[33]
In: Pr o- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Shang, C., Zhou, S., Zhang, H., Ni, X., Yang, Y ., Wang, Y .: Incremental residual concept bottleneck models. In: Pr o- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11030–11040 (June 2024) 1
work page 2024
-
[34]
Sharma, P ., Ding, N., Goodman, S., Soricut, R.: Concep- tual captions: A cleaned, hypernymed, image alt-text datas et for automatic image captioning. In: Gurevych, I., Miyao, Y . (eds.) Proceedings of the 56th Annual Meeting of the Asso- ciation for Computational Linguistics (V olume 1: Long Pa- pers). pp. 2556–2565 (Jul 2018) 1
work page 2018
-
[35]
Shtedritski, A., Rupprecht, C., V edaldi, A.: What does clip know about a red circle? visual prompt engineering for vlms (2023) 2
work page 2023
-
[36]
Team, Q.: Qwen2.5-vl (January 2025), https://qwenlm.github.io/blog/qwen2.5-vl/ 4
work page 2025
-
[37]
In: Proceedin gs of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR)
Wang, B., Li, L., Nakashima, Y ., Nagahara, H.: Learning bottleneck concepts in image classification. In: Proceedin gs of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR). pp. 10962–10971 (June 2023) 1
work page 2023
-
[38]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P ., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Che n, K., Liu, X., Wang, J., Ge, W., Fan, Y ., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Wojciechowski, A., Lango, M., Dusek, O.: Faithful and plausible natural language explanations for image classifi ca- tion: A pipeline approach. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 2340–
work page 2024
-
[40]
Association for Computational Linguistics (Nov 2024) 3
work page 2024
-
[41]
Yamauchi, T., Kera, H., Kawamoto, K.: Zero-shot textua l explanations via translating decision-critical features (2025) 1, 2, 4, 6
work page 2025
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yang, Y ., Panagopoulou, A., Zhou, S., Jin, D., Callison - Burch, C., Yatskar, M.: Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19187–19197 (June 2023) 2, 1 11 Zero-Shot Faithful Textual Explanations v...
work page 2023
-
[43]
Generate GENERAL concepts that can apply to many different photos of the same object type
-
[46]
DO NOT include class names or object names directly. Q: What are useful visual features for distinguishing a lemur in a photo? A: There are several useful visual features to tell there is a lemur in a photo: - long tail - large eyes - gray fur - trees - branches - forest Q: What are useful features for distinguishing a {class_name} in a photo? Already gen...
-
[47]
Generate DETAILED and SPECIFIC concepts that can apply to this image
-
[48]
Include both OBJECT features (e.g., shape, color, parts) AND CONTEXT features (e.g., background, environment, setting)
-
[49]
Keep concepts short and specific (1-3 words)
-
[50]
Examples: Q: Look at this image carefully
DO NOT include class names or object names directly. Examples: Q: Look at this image carefully. Based on what you can actually see in the image, identify useful visual 2 features that help distinguish this as a koi fish. A: There are several useful visual features to tell there is a koi fish in a photo: - bright orange scales - curved tail fin - spotted p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.