Avoiding Bias in Clipped SGD for Overparameterized Models under Generalized Smoothness
Pith reviewed 2026-06-30 20:11 UTC · model grok-4.3
The pith
Clipped and normalized SGD converge without bias at deterministic rates in overparameterized interpolating models under generalized smoothness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under overparameterization and the interpolation condition, both clipped SGD and normalized SGD reach the same convergence rates as their deterministic counterparts without incurring the bias that clipping typically introduces. The proof uses the (L0,L1)-smoothness assumption, which relaxes standard Lipschitz-gradient requirements, and yields faster rates than earlier work on generalized smoothness; the same framework covers heavy-tailed noise, (H0,H1)-smoothness, and the deterministic regime.
What carries the argument
The (L0,L1)-smoothness condition together with overparameterization and interpolation, which jointly remove the clipping bias term from the convergence analysis.
If this is right
- Clipped SGD matches deterministic convergence rates under the stated conditions.
- Normalized SGD behaves identically with respect to bias elimination.
- The analysis applies directly to heavy-tailed noise distributions.
- Rates improve on the best previously known bounds for generalized smoothness.
- The same guarantees hold in the fully deterministic regime.
Where Pith is reading between the lines
- Clipping can be used in large-scale training without paying an asymptotic rate penalty once interpolation is reached.
- The mild batch-size condition suggests a practical threshold that grows slowly with dimension or noise level.
- The bias-elimination mechanism may extend to other first-order methods that truncate or rescale gradients.
- Empirical checks on modern architectures that reach near-zero training loss would directly test the prediction.
Load-bearing premise
The model must be overparameterized enough to achieve exact zero training loss on the data.
What would settle it
Clipped SGD exhibiting a slower rate or measurable bias relative to unclipped SGD when training an overparameterized model to zero loss with batches larger than the stated mild threshold would falsify the claim.
Figures

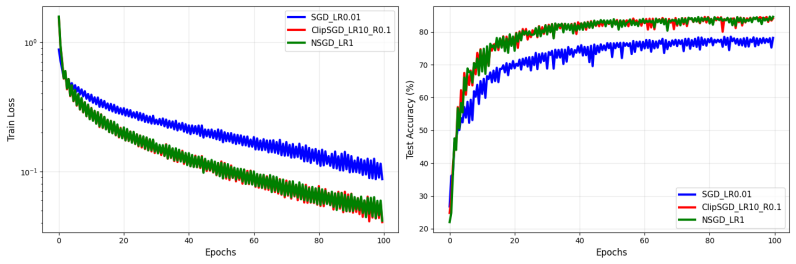
read the original abstract
Modern machine learning is dominated by complex, overparameterized architectures capable of interpolating data and achieving zero training loss. For such models, we investigate the convergence properties of two popular modifications to standard SGD: clipped SGD and normalized SGD. We show that under overparameterization and a mild assumption on batch size, both clipped and normalized SGD do not suffer from the bias typically introduced by clipping, converging effectively at the same rate as their deterministic counterparts. This provides a rigorous theoretical justification for the empirical success of gradient clipping methods. In our analysis, we employ the $(L_0,L_1)$-smoothness condition, under which we obtain convergence rates that improve upon the best known results in prior work. Furthermore, we extend our analysis to specific challenging regimes, including heavy-tailed noise, $(H_0,H_1)$-smoothness (which is strictly weaker than standard assumptions in optimization literature) and the deterministic regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that for overparameterized interpolating models (zero training loss), clipped SGD and normalized SGD avoid the usual clipping-induced bias under a mild batch-size assumption. Using the (L0,L1)-smoothness condition, both methods achieve convergence rates matching their deterministic counterparts and improve on prior results; the analysis is extended to heavy-tailed noise, the weaker (H0,H1)-smoothness, and the deterministic regime.
Significance. If the derivations hold, the work supplies a rigorous explanation for the empirical effectiveness of gradient clipping in modern overparameterized networks and advances the state of the art on convergence under generalized smoothness. The key technical contribution is showing that interpolation plus overparameterization eliminates bias without additional assumptions beyond a batch-size lower bound.
minor comments (2)
- [Abstract] Abstract: the statement that the new rates 'improve upon the best known results in prior work' would be strengthened by an explicit comparison (e.g., dependence on L0, L1, or dimension) to the rates cited in the introduction.
- [Main theorems] The manuscript invokes a 'mild assumption on batch size' to remove bias; a precise statement of this assumption (in terms of n, batch size B, or variance parameters) should appear in the main theorem statements rather than only in the abstract.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for recognizing its potential significance in providing a rigorous justification for gradient clipping in overparameterized interpolating models under (L0,L1)-smoothness. We note that the report lists no specific major comments, so we have no points to address point-by-point at this time. We remain available to provide clarifications or revisions should additional feedback be supplied.
Circularity Check
No significant circularity; derivation self-contained under stated assumptions
full rationale
The provided abstract and description present convergence rates as derived from explicit assumptions (overparameterization + interpolation, (L0,L1)-smoothness, mild batch-size condition) that eliminate clipping bias. No equations, self-citations, or steps are quoted that reduce a claimed prediction to a fitted input or prior self-result by construction. The central claim is an implication under those conditions rather than a renaming or self-referential definition. This matches the default expectation for theoretical papers whose results remain falsifiable against the listed assumptions.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Overparameterization with interpolation (zero training loss)
- domain assumption (L0,L1)-smoothness condition
- domain assumption Mild assumption on batch size
Reference graph
Works this paper leans on
-
[1]
Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy http://dx.doi.org/10.1145/2976749.2978318. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS’16, page 308–318. ACM, October 2016
-
[2]
Why Do We Need Warm-up? A Theoretical Perspective
Foivos Alimisis, Rustem Islamov, and Aurelien Lucchi. Why do we need warm-up? a theoretical perspective. arXiv preprint arXiv:2510.03164, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A convergence theory for deep learning via over-parameterization
Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. In International conference on machine learning, pages 242--252. PMLR, 2019
2019
-
[4]
Learning theory from first principles
Francis Bach. Learning theory from first principles. MIT press, 2024
2024
-
[5]
Convexity, classification, and risk bounds
Peter L Bartlett, Michael I Jordan, and Jon D McAuliffe. Convexity, classification, and risk bounds. Journal of the American Statistical Association, 101 0 (473): 0 138--156, 2006
2006
-
[6]
On the linear convergence of the stochastic gradient method with constant step-size
Volkan Cevher and Bang C \^o ng V \ u . On the linear convergence of the stochastic gradient method with constant step-size. Optimization Letters, 13 0 (5): 0 1177--1187, 2019
2019
-
[7]
Optimal mean estimation without a variance
Yeshwanth Cherapanamjeri, Nilesh Tripuraneni, Peter Bartlett, and Michael Jordan. Optimal mean estimation without a variance. In Conference on Learning Theory, pages 356--357. PMLR, 2022
2022
-
[8]
Convergence of clipped-sgd for convex (l\_0, l\_1) -smooth optimization with heavy-tailed noise
Savelii Chezhegov, Aleksandr Beznosikov, Samuel Horv \'a th, and Eduard Gorbunov. Convergence of clipped-sgd for convex (l\_0, l\_1) -smooth optimization with heavy-tailed noise. arXiv preprint arXiv:2505.20817, 2025
-
[9]
Global minima of overparameterized neural networks
Yaim Cooper. Global minima of overparameterized neural networks. SIAM Journal on Mathematics of Data Science, 3 0 (2): 0 676--691, 2021
2021
-
[10]
Note on a martingale inequality of pisier
David C Cox. Note on a martingale inequality of pisier. In Mathematical Proceedings of the Cambridge Philosophical Society, volume 92, pages 163--165. Cambridge University Press, 1982
1982
-
[11]
Momentum improves normalized sgd
Ashok Cutkosky and Harsh Mehta. Momentum improves normalized sgd. In International conference on machine learning, pages 2260--2268. PMLR, 2020
2020
-
[12]
On the ineffectiveness of variance reduced optimization for deep learning
Aaron Defazio and L \'e on Bottou. On the ineffectiveness of variance reduced optimization for deep learning. Advances in Neural Information Processing Systems, 32, 2019
2019
-
[13]
Saga: A fast incremental gradient method with support for non-strongly convex composite objectives
Aaron Defazio, Francis Bach, and Simon Lacoste-Julien. Saga: A fast incremental gradient method with support for non-strongly convex composite objectives. Advances in neural information processing systems, 27, 2014
2014
-
[14]
Convergence of clipped SGD on convex \ (l\_0,l\_1)\ -smooth functions
Ofir Gaash, Kfir Yehuda Levy, and Yair Carmon. Convergence of clipped SGD on convex \ (l\_0,l\_1)\ -smooth functions. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[15]
Optimal stochastic approximation algorithms for strongly convex stochastic composite optimization i: A generic algorithmic framework
Saeed Ghadimi and Guanghui Lan. Optimal stochastic approximation algorithms for strongly convex stochastic composite optimization i: A generic algorithmic framework. SIAM Journal on Optimization, 22 0 (4): 0 1469--1492, 2012
2012
-
[16]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming
Saeed Ghadimi and Guanghui Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM journal on optimization, 23 0 (4): 0 2341--2368, 2013
2013
-
[17]
Methods for convex \ (l\_0,l\_1)\ -smooth optimization: Clipping, acceleration, and adaptivity
Eduard Gorbunov, Nazarii Tupitsa, Sayantan Choudhury, Alen Aliev, Peter Richt \'a rik, Samuel Horv \'a th, and Martin Tak \'a c . Methods for convex \ (l\_0,l\_1)\ -smooth optimization: Clipping, acceleration, and adaptivity. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[18]
Sgd for structured nonconvex functions: Learning rates, minibatching and interpolation
Robert Gower, Othmane Sebbouh, and Nicolas Loizou. Sgd for structured nonconvex functions: Learning rates, minibatching and interpolation. In International Conference on Artificial Intelligence and Statistics, pages 1315--1323. PMLR, 2021
2021
-
[19]
Sgd: General analysis and improved rates
Robert Mansel Gower, Nicolas Loizou, Xun Qian, Alibek Sailanbayev, Egor Shulgin, and Peter Richt \'a rik. Sgd: General analysis and improved rates. In International conference on machine learning, pages 5200--5209. PMLR, 2019
2019
-
[20]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778, 2016
2016
-
[21]
Gradient correlation is a key ingredient to accelerate sgd with momentum
Julien Hermant, Marien Renaud, Jean-Fran c ois Aujol, Charles Dossal, and Aude Rondepierre. Gradient correlation is a key ingredient to accelerate sgd with momentum. In International Conference on Learning Representations, 2025, 2025
2025
-
[22]
Parameter-agnostic optimization under relaxed smoothness
Florian H \"u bler, Junchi Yang, Xiang Li, and Niao He. Parameter-agnostic optimization under relaxed smoothness. In International Conference on Artificial Intelligence and Statistics, pages 4861--4869. PMLR, 2024
2024
-
[23]
From gradient clipping to normalization for heavy tailed sgd
Florian H \"u bler, Ilyas Fatkhullin, and Niao He. From gradient clipping to normalization for heavy tailed sgd. In International Conference on Artificial Intelligence and Statistics, pages 2413--2421. PMLR, 2025
2025
-
[24]
Double momentum and error feedback for clipping with fast rates and differential privacy
Rustem Islamov, Samuel Horvath, Aurelien Lucchi, Peter Richtarik, and Eduard Gorbunov. Double momentum and error feedback for clipping with fast rates and differential privacy. arXiv preprint arXiv:2502.11682, 2025
-
[25]
Accelerating stochastic gradient descent using predictive variance reduction
Rie Johnson and Tong Zhang. Accelerating stochastic gradient descent using predictive variance reduction. Advances in neural information processing systems, 26, 2013
2013
-
[26]
First order methods for nonsmooth convex large-scale optimization, ii: utilizing problems structure
Anatoli Juditsky, Arkadi Nemirovski, et al. First order methods for nonsmooth convex large-scale optimization, ii: utilizing problems structure. Optimization for Machine Learning, 30 0 (9): 0 149--183, 2011
2011
-
[27]
Linear convergence of gradient and proximal-gradient methods under the polyak- ojasiewicz condition
Hamed Karimi, Julie Nutini, and Mark Schmidt. Linear convergence of gradient and proximal-gradient methods under the polyak- ojasiewicz condition. In Joint European conference on machine learning and knowledge discovery in databases, pages 795--811. Springer, 2016
2016
-
[28]
Scaffold: Stochastic controlled averaging for federated learning
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. Scaffold: Stochastic controlled averaging for federated learning. In International conference on machine learning, pages 5132--5143. PMLR, 2020
2020
-
[29]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
A unified theory of decentralized sgd with changing topology and local updates
Anastasia Koloskova, Nicolas Loizou, Sadra Boreiri, Martin Jaggi, and Sebastian Stich. A unified theory of decentralized sgd with changing topology and local updates. In International conference on machine learning, pages 5381--5393. PMLR, 2020
2020
-
[31]
Revisiting gradient clipping: Stochastic bias and tight convergence guarantees
Anastasia Koloskova, Hadrien Hendrikx, and Sebastian U Stich. Revisiting gradient clipping: Stochastic bias and tight convergence guarantees. In International Conference on Machine Learning, pages 17343--17363. PMLR, 2023
2023
-
[32]
Accelerated zeroth-order method for non-smooth stochastic convex optimization problem with infinite variance
Nikita Kornilov, Ohad Shamir, Aleksandr Lobanov, Darina Dvinskikh, Alexander Gasnikov, Innokentiy Shibaev, Eduard Gorbunov, and Samuel Horv \'a th. Accelerated zeroth-order method for non-smooth stochastic convex optimization problem with infinite variance. Advances in Neural Information Processing Systems, 36: 0 64083--64102, 2023
2023
-
[33]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. In Toronto, ON, Canada, 2009
2009
-
[34]
An optimal method for stochastic composite optimization
Guanghui Lan. An optimal method for stochastic composite optimization. Mathematical Programming, 133 0 (1): 0 365--397, 2012
2012
-
[35]
First-order and stochastic optimization methods for machine learning, volume 1
Guanghui Lan. First-order and stochastic optimization methods for machine learning, volume 1. Springer, 2020
2020
-
[36]
Theoretical analysis on how learning rate warmup accelerates convergence
Yuxing Liu, Yuze Ge, Rui Pan, An Kang, and Tong Zhang. Theoretical analysis on how learning rate warmup accelerates convergence. arXiv preprint arXiv:2509.07972, 2025
-
[37]
Nonconvex stochastic optimization under heavy-tailed noises: Optimal convergence without gradient clipping https://openreview.net/forum?id=NKotdPUc3L
Zijian Liu and Zhengyuan Zhou. Nonconvex stochastic optimization under heavy-tailed noises: Optimal convergence without gradient clipping https://openreview.net/forum?id=NKotdPUc3L. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[38]
Breaking the lower bound with (little) structure: Acceleration in non-convex stochastic optimization with heavy-tailed noise
Zijian Liu, Jiawei Zhang, and Zhengyuan Zhou. Breaking the lower bound with (little) structure: Acceleration in non-convex stochastic optimization with heavy-tailed noise. In The Thirty Sixth Annual Conference on Learning Theory, pages 2266--2290. PMLR, 2023
2023
-
[39]
Power of generalized smoothness in stochastic convex optimization: First-and zero-order algorithms
Aleksandr Lobanov and Alexander Gasnikov. Power of generalized smoothness in stochastic convex optimization: First-and zero-order algorithms. arXiv preprint arXiv:2501.18198, 2025
-
[40]
black-box
Aleksandr Lobanov, Nail Bashirov, and Alexander Gasnikov. The “black-box” optimization problem: Zero-order accelerated stochastic method via kernel approximation. Journal of Optimization Theory and Applications, 203 0 (3): 0 2451--2486, 2024 a
2024
-
[41]
Aleksandr Lobanov, Alexander Gasnikov, Eduard Gorbunov, and Martin Tak \'a c . Linear convergence rate in convex setup is possible! gradient descent method variants under (l\_0, l\_1) -smoothness. arXiv preprint arXiv:2412.17050, 2024 b
-
[42]
Highly smooth zeroth-order methods for solving optimization problems under the pl condition
Aleksandr Lobanov, Alexander Gasnikov, and Fedor Stonyakin. Highly smooth zeroth-order methods for solving optimization problems under the pl condition. Computational Mathematics and Mathematical Physics, 64 0 (4): 0 739--770, 2024 c
2024
-
[43]
The power of interpolation: Understanding the effectiveness of sgd in modern over-parametrized learning
Siyuan Ma, Raef Bassily, and Mikhail Belkin. The power of interpolation: Understanding the effectiveness of sgd in modern over-parametrized learning. In International Conference on Machine Learning, pages 3325--3334. PMLR, 2018
2018
-
[44]
Statistical language models based on neural networks
Tom \'a s Mikolov et al. Statistical language models based on neural networks. Presentation at Google, Mountain View, 2nd April, 80 0 (26), 2012
2012
-
[45]
Non-asymptotic analysis of stochastic approximation algorithms for machine learning
Eric Moulines and Francis Bach. Non-asymptotic analysis of stochastic approximation algorithms for machine learning. Advances in neural information processing systems, 24, 2011
2011
-
[46]
Deep double descent: Where bigger models and more data hurt
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: Where bigger models and more data hurt. Journal of Statistical Mechanics: Theory and Experiment, 2021 0 (12): 0 124003, 2021
2021
-
[47]
Problem complexity and method efficiency in optimization
Arkadi Nemirovski and D Yudin. Problem complexity and method efficiency in optimization. Wiley, 1983
1983
-
[48]
Robust stochastic approximation approach to stochastic programming
Arkadi Nemirovski, Anatoli Juditsky, Guanghui Lan, and Alexander Shapiro. Robust stochastic approximation approach to stochastic programming. SIAM Journal on optimization, 19 0 (4): 0 1574--1609, 2009
2009
-
[49]
Introductory lectures on convex optimization: A basic course, volume 87
Yurii Nesterov. Introductory lectures on convex optimization: A basic course, volume 87. Springer Science & Business Media, 2013
2013
-
[50]
Minimization methods for nonsmooth convex and quasiconvex functions
Yurii E Nesterov. Minimization methods for nonsmooth convex and quasiconvex functions. Matekon, 29 0 (3): 0 519--531, 1984
1984
-
[51]
Martingales with values in uniformly convex spaces
Gilles Pisier. Martingales with values in uniformly convex spaces. Israel Journal of Mathematics, 20 0 (3): 0 326--350, 1975
1975
-
[52]
Gradient methods for the minimisation of functionals
Boris T Polyak. Gradient methods for the minimisation of functionals. USSR Computational Mathematics and Mathematical Physics, 3 0 (4): 0 864--878, 1963
1963
-
[53]
Stochastic variance reduction for nonconvex optimization
Sashank J Reddi, Ahmed Hefny, Suvrit Sra, Barnabas Poczos, and Alex Smola. Stochastic variance reduction for nonconvex optimization. In International conference on machine learning, pages 314--323. PMLR, 2016
2016
-
[54]
A stochastic approximation method
Herbert Robbins and Sutton Monro. A stochastic approximation method. The annals of mathematical statistics, pages 400--407, 1951
1951
-
[55]
A stochastic gradient method with an exponential convergence rate for finite training sets
Nicolas Roux, Mark Schmidt, and Francis Bach. A stochastic gradient method with an exponential convergence rate for finite training sets. Advances in neural information processing systems, 25, 2012
2012
-
[56]
Minimizing finite sums with the stochastic average gradient
Mark Schmidt, Nicolas Le Roux, and Francis Bach. Minimizing finite sums with the stochastic average gradient. Mathematical Programming, 162 0 (1): 0 83--112, 2017
2017
-
[57]
Sparsified sgd with memory
Sebastian U Stich, Jean-Baptiste Cordonnier, and Martin Jaggi. Sparsified sgd with memory. Advances in neural information processing systems, 31, 2018
2018
-
[58]
Optimizing \ (l\_0, l\_1)\ -smooth functions by gradient methods https://openreview.net/forum?id=GQ1Tc3vHbt
Daniil Vankov, Anton Rodomanov, Angelia Nedich, Lalitha Sankar, and Sebastian U Stich. Optimizing \ (l\_0, l\_1)\ -smooth functions by gradient methods https://openreview.net/forum?id=GQ1Tc3vHbt. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[59]
Armijo line-search can make (stochastic) gradient descent provably faster
Sharan Vaswani and Reza Babanezhad. Armijo line-search can make (stochastic) gradient descent provably faster. arXiv preprint arXiv:2503.00229, 2025
-
[60]
Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron
Sharan Vaswani, Francis Bach, and Mark Schmidt. Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron. In The 22nd international conference on artificial intelligence and statistics, pages 1195--1204. PMLR, 2019 a
2019
-
[61]
Painless stochastic gradient: Interpolation, line-search, and convergence rates
Sharan Vaswani, Aaron Mishkin, Issam Laradji, Mark Schmidt, Gauthier Gidel, and Simon Lacoste-Julien. Painless stochastic gradient: Interpolation, line-search, and convergence rates. Advances in neural information processing systems, 32, 2019 b
2019
-
[62]
Inequalities for the rth absolute moment of a sum of random variables, 1 r 2
Bengt von Bahr and Carl-Gustav Esseen. Inequalities for the rth absolute moment of a sum of random variables, 1 r 2 . The Annals of Mathematical Statistics, pages 299--303, 1965
1965
-
[63]
An even more optimal stochastic optimization algorithm: minibatching and interpolation learning
Blake E Woodworth and Nathan Srebro. An even more optimal stochastic optimization algorithm: minibatching and interpolation learning. Advances in neural information processing systems, 34: 0 7333--7345, 2021
2021
-
[64]
Faster single-loop algorithms for minimax optimization without strong concavity
Junchi Yang, Antonio Orvieto, Aurelien Lucchi, and Niao He. Faster single-loop algorithms for minimax optimization without strong concavity. In International conference on artificial intelligence and statistics, pages 5485--5517. PMLR, 2022
2022
-
[65]
On the lower bound of minimizing polyak- ojasiewicz functions
Pengyun Yue, Cong Fang, and Zhouchen Lin. On the lower bound of minimizing polyak- ojasiewicz functions. In The Thirty Sixth Annual Conference on Learning Theory, pages 2948--2968. PMLR, 2023
2023
-
[66]
Improved analysis of clipping algorithms for non-convex optimization
Bohang Zhang, Jikai Jin, Cong Fang, and Liwei Wang. Improved analysis of clipping algorithms for non-convex optimization. Advances in Neural Information Processing Systems, 33: 0 15511--15521, 2020 a
2020
-
[67]
Why gradient clipping accelerates training: A theoretical justification for adaptivity
Jingzhao Zhang, Tianxing He, Suvrit Sra, and Ali Jadbabaie. Why gradient clipping accelerates training: A theoretical justification for adaptivity. In International Conference on Learning Representations, 2020 b
2020
-
[68]
Why are adaptive methods good for attention models? Advances in Neural Information Processing Systems, 33: 0 15383--15393, 2020 c
Jingzhao Zhang, Sai Praneeth Karimireddy, Andreas Veit, Seungyeon Kim, Sashank Reddi, Sanjiv Kumar, and Suvrit Sra. Why are adaptive methods good for attention models? Advances in Neural Information Processing Systems, 33: 0 15383--15393, 2020 c
2020
-
[69]
On the convergence and improvement of stochastic normalized gradient descent
Shen-Yi Zhao, Yin-Peng Xie, and Wu-Jun Li. On the convergence and improvement of stochastic normalized gradient descent. Science China Information Sciences, 64 0 (3): 0 132103, 2021
2021
-
[70]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.