Measuring the Symmetry--Data Exchange Rate
Pith reviewed 2026-06-28 16:47 UTC · model grok-4.3
The pith
A misaligned symmetry prior harms performance more than having no symmetry prior at all.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
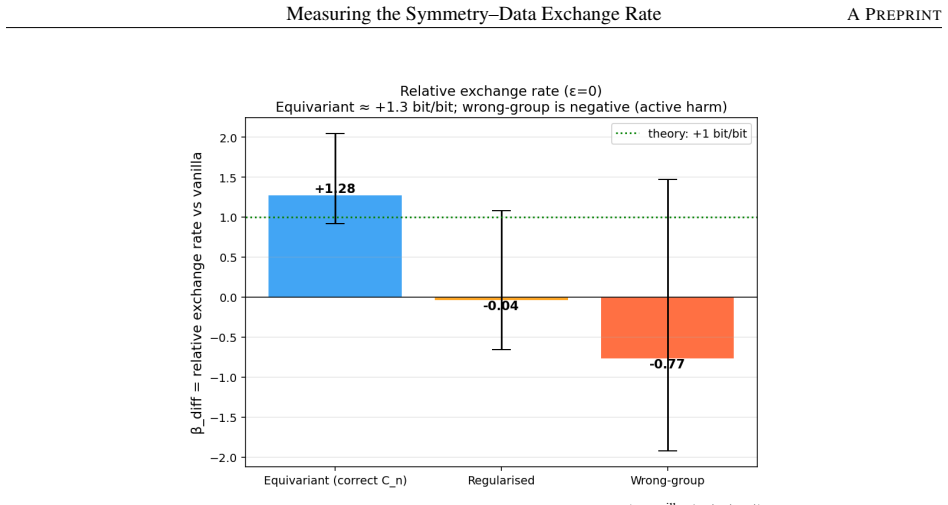
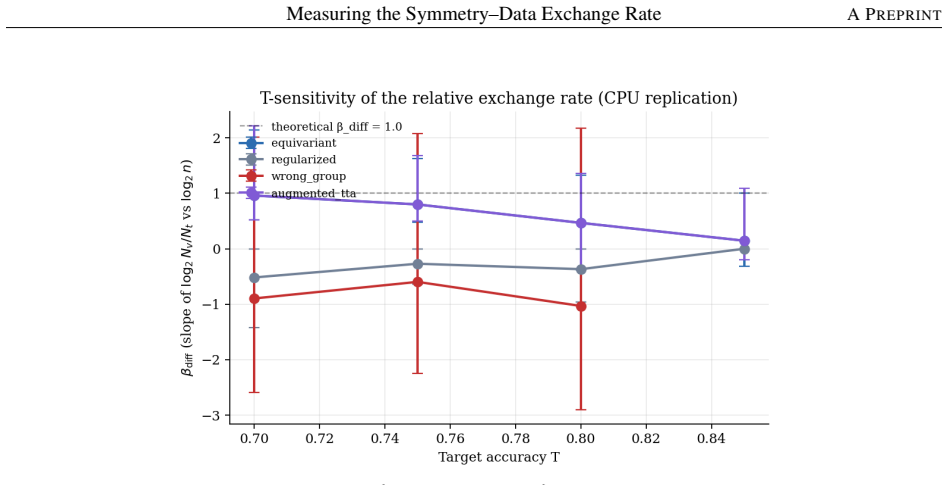
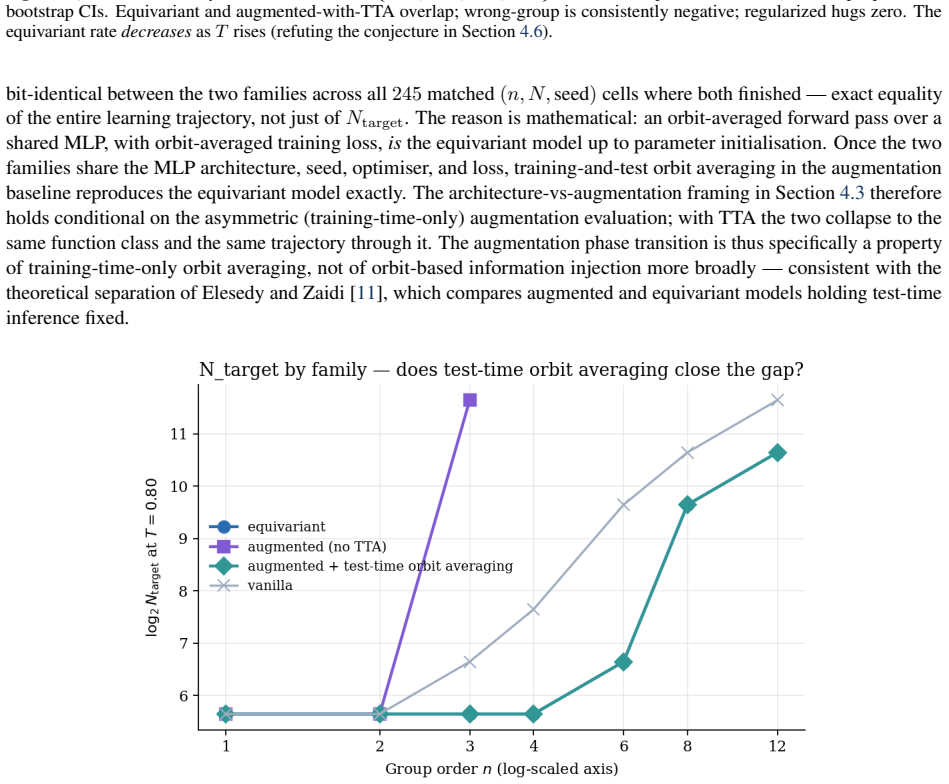
On a C_n-symmetric task a wrong-group control with identical orbit size is worse than no constraint, with the joint pairwise confidence interval excluding zero and robust across estimators. An augmentation baseline equipped with test-time orbit averaging produces bit-identical per-epoch validation curves to the equivariant model. The relative exchange rate beta_diff equals 1.28, consistent in sign and order of magnitude with the theoretical value of 1.0 under the single-level interval, while the more conservative two-level bootstrap includes zero.
What carries the argument
The relative-rate estimator beta_diff, formed as the difference in slopes of performance versus data size across group sizes, that cancels the shared task-difficulty confound.
If this is right
- Misaligned symmetry constraints are actively harmful rather than merely unhelpful.
- Architecture-versus-augmentation gaps disappear once test-time computation is equalized by orbit averaging.
- The relative-rate estimator, wrong-group control, and failure taxonomy transfer to any inductive bias whose strength can be parameterized by a group size.
- The exchange rate can be measured even when absolute difficulty varies across group sizes.
Where Pith is reading between the lines
- The same wrong-group control design could be applied to test whether other misaligned priors, such as incorrect invariance or sparsity patterns, are actively detrimental.
- If the exchange-rate method generalizes, it supplies a quantitative way to compare the data efficiency of different parameterizable biases on the same task.
- A pre-registered replication with external seeds would convert the current exploratory measurement into a confirmatory result.
Load-bearing premise
The post-hoc beta_diff estimator isolates the symmetry-data exchange rate on the coarse grid without residual confounds from the controlled task setup.
What would settle it
A fresh-seed replication on a finer sqrt(2)-spaced grid of group sizes in which the OLS slope for beta_diff lies well outside the reported interval or the wrong-group confidence interval includes zero.
Figures



read the original abstract
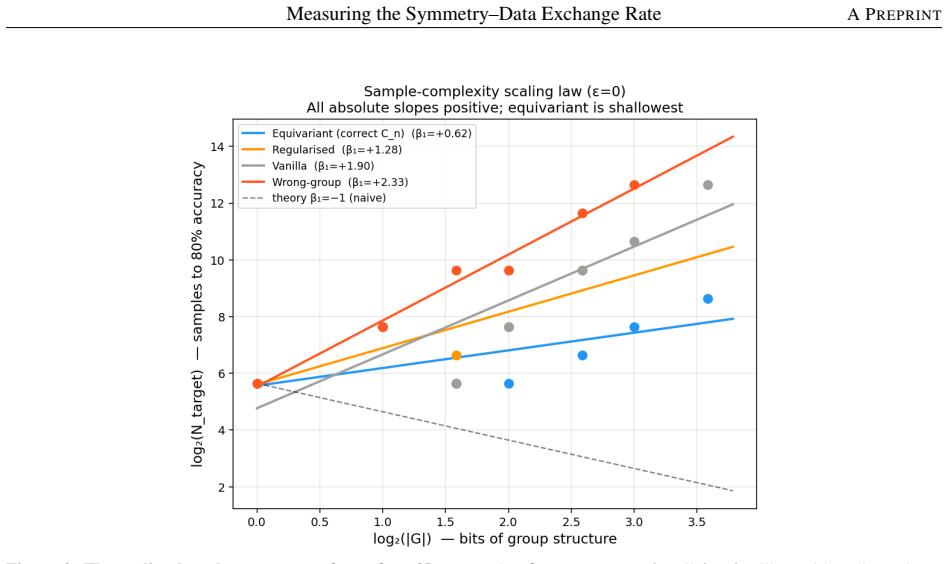
Equivariance theory predicts that an architectural symmetry prior reduces sample complexity by a factor of |G|; this is widely cited but rarely measured as a scaling law with controls that separate the prior from its confounds. On a controlled C_n-symmetric task, we report three findings. First, a wrong-group control with identical orbit size and matched compute is worse than no constraint (joint pairwise CI [+0.79, +3.26] excludes zero, robust across estimators); misaligned constraint is actively harmful, not merely unhelpful. Second, an augmentation baseline equipped with test-time orbit averaging matches the equivariant model exactly -- bit-identical per-epoch validation curves across matched cells -- so the architecture-vs-augmentation gap is conditional on asymmetric test-time computation, not unconditional. Third, the relative exchange rate beta_diff = 1.28 is consistent in sign and order of magnitude with the theoretical 1.0 (single-level CI [+0.92, +2.05]); the more conservative two-level bootstrap (seeds x group sizes) widens this to [-0.63, +1.72], including zero, and a finer-N replication on a sqrt(2)-spaced grid is inconclusive (point estimate -0.82). The methodological contributions -- the relative-rate estimator that cancels the shared-difficulty confound, the wrong-group control, and a pre-specified failure taxonomy -- transfer to any inductive bias whose strength can be parameterised. Honest scoping: the primary estimator beta_diff was adopted post-hoc after the initial analysis revealed a positive-slope identifiability problem; the design was never externally pre-registered; and the headline number rests on an OLS slope over seven group sizes on a coarse N grid. This is an exploratory study, not a confirmatory measurement; the wrong-group result is the cleanest finding and the one we report with the most confidence. A registered replication on fresh seeds is future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically measures the symmetry-data exchange rate on a controlled C_n-symmetric task. It reports three main findings: (1) a wrong-group control with identical orbit size and matched compute is actively harmful relative to no constraint (joint pairwise CI [+0.79, +3.26] excludes zero, robust across estimators); (2) an augmentation baseline with test-time orbit averaging produces bit-identical validation curves to the equivariant model; (3) the relative exchange rate beta_diff equals 1.28 (single-level CI [+0.92, +2.05]), consistent in sign and magnitude with the theoretical value of 1.0, though the conservative two-level bootstrap widens to [-0.63, +1.72] (includes zero) and a finer-N replication is inconclusive. The study is explicitly scoped as exploratory, with post-hoc adoption of beta_diff after an identifiability issue, no external pre-registration, and reliance on OLS over seven coarse grid points.
Significance. If the wrong-group harm result holds under the stated controls, it supplies direct empirical evidence that misaligned inductive biases can increase sample complexity rather than merely failing to reduce it, with clear implications for equivariance theory and inductive-bias design. The relative-rate estimator (which cancels shared-difficulty confounds) and the wrong-group control are transferable methodological contributions to any parameterized inductive bias. The manuscript's explicit honesty about its exploratory status, post-hoc estimator choice, and inconclusive replication strengthens its credibility as a methods contribution in stat.ME.
major comments (2)
- [Abstract] Abstract and results on beta_diff: the primary estimator was adopted post-hoc after the initial analysis revealed a positive-slope identifiability problem; the reported consistency with theory therefore rests on an OLS slope fitted to seven points on a coarse N grid, and the more conservative two-level bootstrap CI includes zero while the sqrt(2)-spaced replication yields -0.82. This makes the exchange-rate claim load-bearing only under the acknowledged exploratory framing and requires explicit discussion of residual confounds from the controlled task setup.
- [Methods] Methods and results on beta_diff: the claim that beta_diff validly isolates the symmetry-data exchange rate assumes the post-hoc OLS specification over the coarse grid has no residual confounds from orbit-size matching or compute equalization; the paper does not provide a pre-specified sensitivity analysis or alternative estimators that were ruled out before seeing the data.
minor comments (2)
- [Abstract] The abstract states that the methodological contributions transfer to any inductive bias whose strength can be parameterised; a short paragraph illustrating one additional example (e.g., sparsity or invariance) would clarify scope without lengthening the paper.
- The pre-specified failure taxonomy is mentioned but not detailed; a brief enumeration or reference to supplementary material would aid reproducibility.
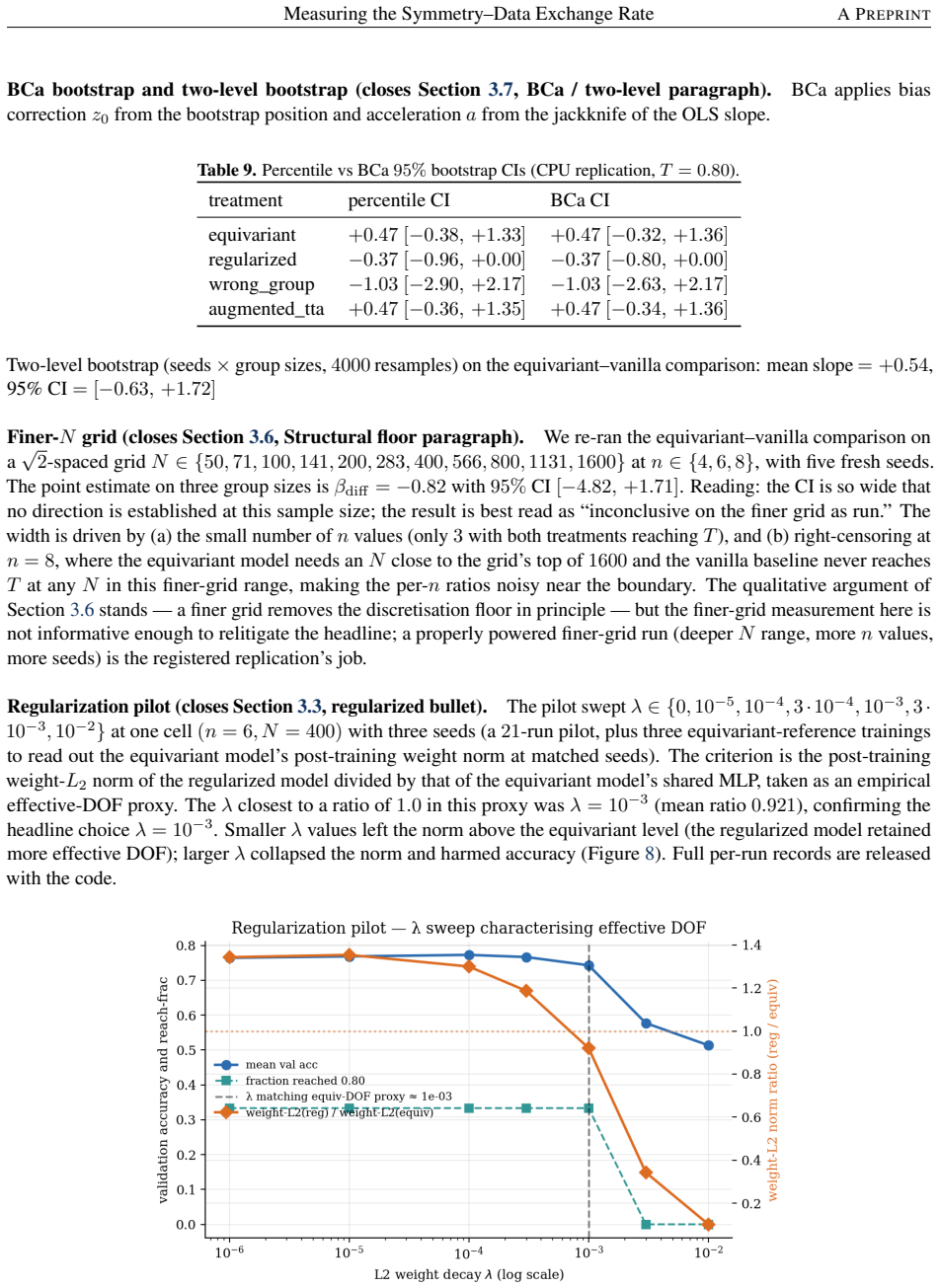
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the need for explicit discussion of the exploratory framing around beta_diff. We agree that the post-hoc adoption of the estimator and lack of pre-specification warrant additional caveats on potential confounds, and we will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract and results on beta_diff: the primary estimator was adopted post-hoc after the initial analysis revealed a positive-slope identifiability problem; the reported consistency with theory therefore rests on an OLS slope fitted to seven points on a coarse N grid, and the more conservative two-level bootstrap CI includes zero while the sqrt(2)-spaced replication yields -0.82. This makes the exchange-rate claim load-bearing only under the acknowledged exploratory framing and requires explicit discussion of residual confounds from the controlled task setup.
Authors: We agree. The manuscript already flags the post-hoc adoption, exploratory status, and inconclusive replication, but we will revise the abstract to add an explicit sentence on residual confounds (e.g., from orbit-size matching and compute equalization) and to qualify the consistency claim more narrowly as holding only under the exploratory framing. revision: yes
-
Referee: [Methods] Methods and results on beta_diff: the claim that beta_diff validly isolates the symmetry-data exchange rate assumes the post-hoc OLS specification over the coarse grid has no residual confounds from orbit-size matching or compute equalization; the paper does not provide a pre-specified sensitivity analysis or alternative estimators that were ruled out before seeing the data.
Authors: We acknowledge the absence of pre-specification as a genuine limitation of the study. In revision we will insert a short methods subsection that (a) states the OLS choice was post-hoc, (b) lists the sensitivity checks performed after seeing the data, and (c) explicitly notes that no pre-specified analysis plan existed. We will not claim the estimator is free of all residual confounds. revision: yes
Circularity Check
No significant circularity; empirical measurements with explicit exploratory scoping
full rationale
The manuscript reports direct empirical estimates (OLS slopes, bootstrap CIs, pairwise comparisons) from controlled experiments on a C_n-symmetric task rather than any derivation chain. Quantities such as beta_diff are fitted from observed validation curves on a coarse N grid; the paper does not claim these reduce to theoretical inputs by construction or rename a fitted parameter as an independent prediction. The text explicitly flags the post-hoc adoption of the primary estimator, the lack of external pre-registration, and the inconclusive finer-N replication. No self-definitional equations, load-bearing self-citations, uniqueness theorems, or ansatz smuggling are present. The strongest claim (wrong-group harm) rests on a joint CI excluding zero from matched-compute controls, which is an experimental outcome, not a reduction to prior inputs. This is the most common honest finding for an empirical measurement study.
Axiom & Free-Parameter Ledger
free parameters (1)
- beta_diff =
1.28
axioms (1)
- domain assumption The experimental task is exactly C_n-symmetric and controls isolate the symmetry prior from compute and orbit-size confounds
Reference graph
Works this paper leans on
-
[1]
Cormorant: Covariant molecular neural networks
Brandon Anderson, Truong-Son Hy, and Risi Kondor. Cormorant: Covariant molecular neural networks. In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[2]
Jonathan Bac, Evgeny M. Mirkes, Alexander N. Gorban, Ivan Tyukin, and Andrei Zinovyev. Scikit-dimension: A Python package for intrinsic dimension estimation.Entropy, 23(10):1368, 2021. doi:10.3390/e23101368
-
[3]
Mailoa, Mordechai Kornbluth, Nicola Molinari, Tess E
Simon Batzner, Albert Musaelian, Lixin Sun, Mario Geiger, Jonathan P. Mailoa, Mordechai Kornbluth, Nicola Molinari, Tess E. Smidt, and Boris Kozinsky. E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials.Nature Communications, 13(1):2453, 2022. doi:10.1038/s41467-022-29939-5
-
[4]
A model of inductive bias learning.Journal of Artificial Intelligence Research, 12:149–198,
Jonathan Baxter. A model of inductive bias learning.Journal of Artificial Intelligence Research, 12:149–198,
-
[5]
doi:10.1613/jair.731
-
[6]
On the sample complexity of learning under geometric stability
Alberto Bietti, Luca Venturi, and Joan Bruna. On the sample complexity of learning under geometric stability. In Advances in Neural Information Processing Systems 34 (NeurIPS), 2021
2021
-
[7]
Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c
Michael M. Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021
Pith/arXiv arXiv 2021
-
[8]
Cohen and Max Welling
Taco S. Cohen and Max Welling. Group equivariant convolutional networks. InProceedings of the 33rd International Conference on Machine Learning (ICML), 2016. 16 Measuring the Symmetry–Data Exchange RateA PREPRINT
2016
-
[9]
Convolutional neural networks on graphs with fast localized spectral filtering
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. InAdvances in Neural Information Processing Systems (NIPS), 2016
2016
-
[10]
Multiple comparisons among means.Journal of the American Statistical Association, 56(293): 52–64, 1961
Olive Jean Dunn. Multiple comparisons among means.Journal of the American Statistical Association, 56(293): 52–64, 1961
1961
-
[11]
Tibshirani.An Introduction to the Bootstrap
Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Chapman & Hall, 1993
1993
-
[12]
Provably strict generalisation benefit for equivariant models
Bryn Elesedy and Sheheryar Zaidi. Provably strict generalisation benefit for equivariant models. InProceedings of the 38th International Conference on Machine Learning (ICML), volume 139 ofProceedings of Machine Learning Research, pages 2959–2969, 2021
2021
-
[13]
Elena Facco, Maria d’Errico, Alex Rodriguez, and Alessandro Laio. Estimating the intrinsic dimension of datasets by a minimal neighborhood information.Scientific Reports, 7:12140, 2017. doi:10.1038/s41598-017-11873-y
-
[14]
The Garden of Forking Paths
Andrew Gelman and Eric Loken. The statistical crisis in science.American Scientist, 102(6):460–465, 2014. Published version of the 2013 working paper “The Garden of Forking Paths”
2014
-
[15]
On the generalization of equivariance and convolution in neural networks to the action of compact groups
Risi Kondor and Shubhendu Trivedi. On the generalization of equivariance and convolution in neural networks to the action of compact groups. InProceedings of the 35th International Conference on Machine Learning (ICML), 2018
2018
-
[16]
Elizaveta Levina and Peter J. Bickel. Maximum likelihood estimation of intrinsic dimension. InAdvances in Neural Information Processing Systems 17 (NIPS), pages 777–784, 2004
2004
-
[17]
Learning with invariances in random features and kernel models
Song Mei, Theodor Misiakiewicz, and Andrea Montanari. Learning with invariances in random features and kernel models. InProceedings of the 34th Conference on Learning Theory (COLT), volume 134 ofProceedings of Machine Learning Research, 2021
2021
-
[18]
PyTorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. PyTorch: An imperative style, high-performance deep learning library. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[19]
Scikit-learn: Machine learning in Python
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[20]
Nathaniel Thomas, Tess Smidt, Steven Kearnes, Lusann Yang, Li Li, Kai Kohlhoff, and Patrick Riley. Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds.arXiv preprint arXiv:1802.08219, 2018
Pith/arXiv arXiv 2018
-
[21]
General E(2)-equivariant steerable CNNs
Maurice Weiler and Gabriele Cesa. General E(2)-equivariant steerable CNNs. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[22]
David H. Wolpert. The lack of a priori distinctions between learning algorithms.Neural Computation, 8(7): 1341–1390, 1996. doi:10.1162/neco.1996.8.7.1341
-
[23]
untested
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabás Póczos, Ruslan Salakhutdinov, and Alexander J. Smola. Deep sets. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. A. HYPERPARAMETERS AND SOFTWARE ENVIRONMENT Hidden width 32; two hidden ReLU layers plus a linear output; Adam at learning rate 10−3; batch size 64; up to 500 epoch...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.