OTCHA: Optimal Transport-driven Confidence-aware Latent Hub Alignment for Multi-View Medical Image Classification
Pith reviewed 2026-06-26 18:18 UTC · model grok-4.3
The pith
OTCHA aligns multi-view medical image patch tokens to shared latent hub tokens via optimal transport, using token-conditional dustbins to discard irrelevant content before fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OTCHA introduces learnable latent hub tokens shared across views, computes an optimal transport plan between patch tokens and hub tokens that jointly considers feature similarity and geometry, and augments the plan with token-conditional dustbins to enable partial matching; the resulting transport plan supplies token-wise matching confidences that gate hub-mediated message passing and weight a novel optimal-transport-based representation alignment loss, thereby refining tokens prior to fusion.
What carries the argument
The OT plan between patch tokens and latent hub tokens augmented with token-conditional dustbins to produce matching confidences for gating message passing and weighting the alignment loss.
If this is right
- Direct fusion methods are outperformed because irrelevant tokens no longer contaminate the fused embedding.
- The approach remains effective across varying numbers of views and different anatomies without requiring explicit registration.
- Token-wise confidences from the transport plan both stabilize training via the alignment loss and control information flow during message passing.
- The same hub tokens serve as an intermediary that lets each view exchange information only through high-confidence matches.
Where Pith is reading between the lines
- The partial-matching mechanism may generalize to other attention-based fusion tasks where some inputs are noisy or out-of-domain.
- Learnable hub tokens could serve as a lightweight alternative to explicit cross-view registration modules in other imaging domains.
- If the dustbin formulation proves robust, similar conditional slack variables might be added to other optimal-transport applications in vision to handle partial correspondences.
Load-bearing premise
The OT plan with dustbins produces matching confidences that reliably identify and suppress irrelevant tokens without discarding diagnostically useful information.
What would settle it
Performance drops below direct-fusion baselines on a multi-view dataset engineered to contain no irrelevant tokens, or the method discards tokens that human experts later confirm are diagnostically relevant.
Figures

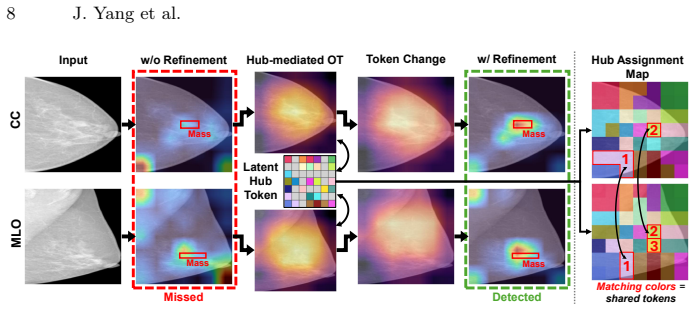

read the original abstract
Multi-view imaging, such as mammography and chest radiography, is a standard component of clinical practice. However, medical images are often unregistered and contain view-specific artifacts or irrelevant background cues that can obscure diagnostically relevant findings. Many existing methods directly fuse per-view representations, allowing such irrelevant content to contaminate the fused embedding and reducing robustness under varying view configurations. We propose OTCHA, a confidence-aware latent hub token alignment module based on optimal transport (OT) that refines patch tokens before fusion for multi-view classification. OTCHA introduces a set of learnable latent hub tokens shared across views. For each view, we compute an OT plan between patch tokens and hub tokens that jointly considers feature similarity and geometry, and augment the OT formulation with token-conditional dustbins to enable partial matching and discard irrelevant tokens. The resulting transport plan provides token-wise matching confidence, which gates hub-mediated message passing and weights a novel optimal-transport-based representation alignment loss to stabilize refinement. Experiments on three multi-view medical image datasets demonstrate consistent improvements over competing baselines across diverse anatomies and view configurations. Our code is available at https://github.com/labhai/OTCHA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OTCHA, a confidence-aware latent hub token alignment module based on optimal transport (OT) for multi-view medical image classification. It introduces learnable latent hub tokens shared across views, computes an OT plan between patch tokens and hub tokens that incorporates feature similarity and geometry, augments the formulation with token-conditional dustbins for partial matching to discard irrelevant tokens, and uses the resulting transport plan to gate hub-mediated message passing and weight a novel OT-based representation alignment loss. Experiments on three multi-view medical image datasets are reported to show consistent improvements over competing baselines across diverse anatomies and view configurations.
Significance. If the empirical gains hold under scrutiny and the OT-based confidence mechanism generalizes without discarding useful diagnostic information, the approach could provide a principled, geometry-aware way to mitigate view-specific artifacts in unregistered multi-view medical imaging, potentially strengthening fusion pipelines in clinical CV applications.
minor comments (2)
- Abstract: the description of how geometry is jointly considered with feature similarity in the OT plan is high-level; a concrete formulation or pseudocode would clarify the contribution.
- Abstract: while a code link is provided, the absence of any quantitative metrics, dataset names, or statistical tests in the summary makes the strength of the 'consistent improvements' claim difficult to gauge from the provided text alone.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for their time. The report lists no specific major comments, so we have nothing to address point-by-point. We remain available to supply further clarifications or experiments should the editor or referee request them.
Circularity Check
No significant circularity detected
full rationale
The paper proposes OTCHA as a novel module using optimal transport between patch tokens and learnable latent hub tokens, augmented with token-conditional dustbins for partial matching and confidence-gated alignment. No load-bearing step reduces by construction to fitted inputs or self-citations; the OT plan and alignment loss are defined directly from the stated goal of suppressing irrelevant tokens without reference to prior author results that would force the outcome. The central claim rests on empirical improvements across datasets rather than any renamed or self-referential derivation. This matches the expectation of a self-contained method introduction with no evident circular patterns from the provided description.
Axiom & Free-Parameter Ledger
invented entities (2)
-
learnable latent hub tokens
no independent evidence
-
token-conditional dustbins
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Black, S., Souvenir, R.: Multi-view classification using hybrid fusion and mutual distillation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 270–280 (2024)
2024
-
[2]
arXiv preprint arXiv:2110.13083 (2021)
Chen, S., Yu, T., Li, P.: Mvt: Multi-view vision transformer for 3d object recogni- tion. arXiv preprint arXiv:2110.13083 (2021)
arXiv 2021
-
[3]
Ad- vances in neural information processing systems26(2013)
Cuturi, M.: Sinkhorn distances: Lightspeed computation of optimal transport. Ad- vances in neural information processing systems26(2013)
2013
-
[4]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Dabboussi, M., Huard, M., Gousseau, Y., Gori, P.: Self-supervised multiview xray matching. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 578–588. Springer (2025)
2025
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
De Plaen, H., De Plaen, P.F., Suykens, J.A., Proesmans, M., Tuytelaars, T., Van Gool, L.: Unbalanced optimal transport: A unified framework for object de- tection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3198–3207 (2023)
2023
-
[6]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[7]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Du, Y., Chen, L., Dvornek, N.C.: Geometry-guided local alignment for multi- view visual language pre-training in mammography. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 299–310. Springer (2025)
2025
-
[8]
In: International conference on medical image computing and computer- assisted intervention
Ghosh, S., Poynton, C.B., Visweswaran, S., Batmanghelich, K.: Mammo-clip: A vi- sion language foundation model to enhance data efficiency and robustness in mam- mography. In: International conference on medical image computing and computer- assisted intervention. pp. 632–642. Springer (2024)
2024
-
[9]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Gorade,V.,Sing,A.,Mishra,D.:Otcxr:Rethinkingself-supervisedalignmentusing optimal transport for chest x-ray analysis. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 7143–7152. IEEE (2025)
2025
-
[10]
IEEE transactions on pattern analysis and machine intelligence45(2), 2551–2566 (2022)
Han, Z., Zhang, C., Fu, H., Zhou, J.T.: Trusted multi-view classification with dynamic evidential fusion. IEEE transactions on pattern analysis and machine intelligence45(2), 2551–2566 (2022)
2022
-
[11]
In: Proceedings of the AAAI conference on artificial intelligence
Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.: Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 590–597 (2019) 10 J. Yang et al
2019
-
[12]
In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition
Izquierdo, S., Civera, J.: Optimal transport aggregation for visual place recogni- tion. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 17658–17668 (2024)
2024
-
[13]
In: Proceedings of the Conference on Health, Inference, and Learning
Jain, S., Smit, A., Truong, S.Q., Nguyen, C.D., Huynh, M.T., Jain, M., Young, V.A., Ng, A.Y., Lungren, M.P., Rajpurkar, P.: Visualchexbert: addressing the dis- crepancy between radiology report labels and image labels. In: Proceedings of the Conference on Health, Inference, and Learning. pp. 105–115 (2021)
2021
-
[14]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Ji, C., Du, C., Zhang, Q., Wang, S., Ma, C., Xie, J., Zhou, Y., He, H., Shen, D.: Mammo-net: Integrating gaze supervision and interactive information in multi- view mammogram classification. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 68–78. Springer (2023)
2023
-
[15]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Le, T., Nguyen, K., Sun, S., Ho, N., Xie, X.: Integrating efficient optimal transport and functional maps for unsupervised shape correspondence learning. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23188–23198 (2024)
2024
-
[16]
Medical Image Analysis 99, 103320 (2025)
Manigrasso, F., Milazzo, R., Russo, A.S., Lamberti, F., Strand, F., Pagnani, A., Morra, L.: Mammography classification with multi-view deep learning techniques: Investigating graph and transformer-based architectures. Medical Image Analysis 99, 103320 (2025)
2025
-
[17]
Scientific Data10(1), 277 (2023)
Nguyen, H.T., Nguyen, H.Q., Pham, H.H., Lam, K., Le, L.T., Dao, M., Vu, V.: Vindr-mammo: A large-scale benchmark dataset for computer-aided diagnosis in full-field digital mammography. Scientific Data10(1), 277 (2023)
2023
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ni, J., Li, Y., Huang, Z., Li, H., Bao, H., Cui, Z., Zhang, G.: Pats: Patch area transportation with subdivision for local feature matching. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17776– 17786 (2023)
2023
-
[19]
arXiv preprint arXiv:1712.06957 (2017)
Rajpurkar, P., Irvin, J., Bagul, A., Ding, D., Duan, T., Mehta, H., Yang, B., Zhu, K., Laird, D., Ball, R.L., et al.: Mura: Large dataset for abnormality detection in musculoskeletal radiographs. arXiv preprint arXiv:1712.06957 (2017)
Pith/arXiv arXiv 2017
-
[20]
In: 2024 IEEE International Symposium on Biomedical Imaging (ISBI)
Sarker, S., Sarker, P., Bebis, G., Tavakkoli, A.: Mv-swin-t: Mammogram classifi- cation with multi-view swin transformer. In: 2024 IEEE International Symposium on Biomedical Imaging (ISBI). pp. 1–5. IEEE (2024)
2024
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning feature matching with graph neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4938–4947 (2020)
2020
-
[22]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Shaaban, M.A., Saleem, T.J., Papineni, V.R.K., Yaqub, M.: Motor: Multimodal optimal transport via grounded retrieval in medical visual question answering. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 459–469. Springer (2025)
2025
-
[23]
In: International conference on medical image computing and computer-assisted intervention
Sun, Z., Jiang, H., Ma, L., Yu, Z., Xu, H.: Transformer based multi-view network for mammographic image classification. In: International conference on medical image computing and computer-assisted intervention. pp. 46–54. Springer (2022)
2022
-
[24]
In: International Conference on Medi- cal Image Computing and Computer-Assisted Intervention
Van Tulder, G., Tong, Y., Marchiori, E.: Multi-view analysis of unregistered med- ical images using cross-view transformers. In: International Conference on Medi- cal Image Computing and Computer-Assisted Intervention. pp. 104–113. Springer (2021)
2021
-
[25]
In: Interna- tional Conference on Medical Image Computing and Computer-Assisted Interven- tion
Wan, P., Zhang, S., Shao, W., Zhao, J., Yang, Y., Kong, W., Xue, H., Zhang, D.: Correlation-adaptive multi-view ceus fusion for liver cancer diagnosis. In: Interna- tional Conference on Medical Image Computing and Computer-Assisted Interven- tion. pp. 188–197. Springer (2024) Title Suppressed Due to Excessive Length 11
2024
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu, M., Gould, S.: Temporally consistent unbalanced optimal transport for un- supervised action segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14618–14627 (2024)
2024
-
[27]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Yang, Z., Zhang, J., Wang, G., Kalra, M.K., Yan, P.: Cardiovascular disease de- tection from multi-view chest x-rays with bi-mamba. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 134–144. Springer (2024)
2024
-
[28]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Zheng, X., Chen, X., Gong, S., Griffin, X., Slabaugh, G.: Xfmamba: Cross-fusion mamba for multi-view medical image classification. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 672–682. Springer (2025)
2025
-
[29]
In: 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI)
Zhu,X.,Feng,Q.:Mvc-net:Multi-viewchestradiographclassificationnetworkwith deep fusion. In: 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI). pp. 554–558. IEEE (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.