Exploring Multimodal LMMs for Online Episodic Memory Question Answering on the Edge
Pith reviewed 2026-05-15 19:02 UTC · model grok-4.3
The pith
Multimodal large language models can run real-time episodic memory question answering on edge devices with accuracy close to cloud services.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
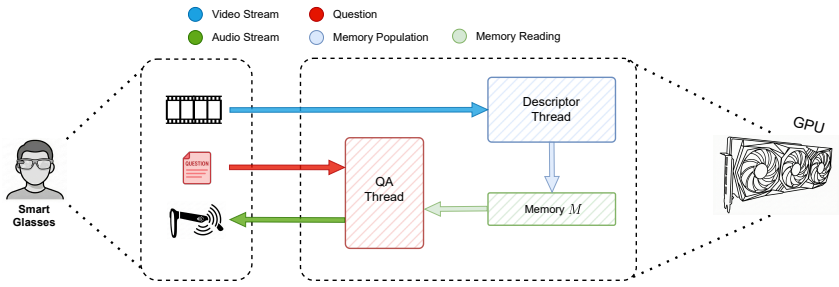
The authors demonstrate that an asynchronous two-thread architecture, consisting of a descriptor thread generating lightweight textual memory from video and a QA thread reasoning over it with MLLMs, enables effective online episodic memory question answering on resource-constrained edge devices, achieving competitive accuracy and low latency on the QAEgo4D-Closed benchmark compared to cloud-based alternatives.
What carries the argument
The two-thread pipeline where the Descriptor Thread continuously converts video into lightweight textual memory and the QA Thread answers queries based on that memory.
If this is right
- Running on consumer-grade 8GB GPUs yields 51.76% accuracy with 0.41s TTFT.
- Enterprise servers achieve 54.40% accuracy with 0.88s TTFT.
- Cloud solutions reach 56.00% accuracy, indicating edge performance is viable.
- Such systems support privacy-preserving wearable assistants for real-time memory retrieval.
Where Pith is reading between the lines
- Similar pipelines could extend to other real-time video understanding tasks on mobile devices.
- Improving the descriptor to retain more temporal details might further close the accuracy gap to cloud.
- Deployment on wearables could enable always-available personal memory aids without cloud dependency.
Load-bearing premise
The lightweight textual memory from the descriptor thread preserves sufficient visual and temporal information for the QA thread to answer questions accurately.
What would settle it
Measuring accuracy when feeding full video frames directly to the QA model instead of the textual memory and finding if the drop is minimal would confirm or refute the sufficiency of the textual representation.
Figures


read the original abstract
We investigate the feasibility of using Multimodal Large Language Models (MLLMs) for real-time online episodic memory question answering. While cloud offloading is common, it raises privacy and latency concerns for wearable assistants, hence we investigate implementation on the edge. We integrated streaming constraints into our question answering pipeline, which is structured into two asynchronous threads: a Descriptor Thread that continuously converts video into a lightweight textual memory, and a Question Answering (QA) Thread that reasons over the textual memory to answer queries. Experiments on the QAEgo4D-Closed benchmark analyze the performance of Multimodal Large Language Models (MLLMs) within strict resource boundaries, showing promising results also when compared to clound-based solutions. Specifically, an end-to-end configuration running on a consumer-grade 8GB GPU achieves 51.76% accuracy with a Time-To-First-Token (TTFT) of 0.41s. Scaling to a local enterprise-grade server yields 54.40% accuracy with a TTFT of 0.88s. In comparison, a cloud-based solution obtains an accuracy of 56.00%. These competitive results highlight the potential of edge-based solutions for privacy-preserving episodic memory retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a two-thread architecture for online episodic memory question answering using Multimodal Large Language Models (MLLMs) on edge devices. A Descriptor Thread processes streaming video into a compact textual memory, while a QA Thread performs reasoning over this memory to answer questions. Experiments on the QAEgo4D-Closed benchmark demonstrate that an 8GB GPU setup achieves 51.76% accuracy with 0.41s TTFT, an enterprise server reaches 54.40% with 0.88s TTFT, compared to 56.00% for a cloud-based approach.
Significance. If validated, the results indicate that edge-deployed MLLMs can provide near-competitive performance for privacy-sensitive applications like wearable episodic memory assistants, with significantly lower latency than cloud offloading. The work contributes concrete latency and accuracy metrics under resource constraints, highlighting the potential for on-device solutions.
major comments (2)
- [Descriptor Thread description] Descriptor Thread section: The construction of the lightweight textual memory is described at a high level but lacks specifics on implementation details such as video frame sampling rates, description prompts, or summarization strategy. This is load-bearing for the central claim because the reported 51.76% accuracy depends on the assumption that key episodic details survive conversion to text without substantial loss.
- [Results section] Results and Experiments section: The accuracies (51.76%, 54.40%, 56.00%) and TTFT values are reported without baselines, error analysis, or breakdown of question types on QAEgo4D-Closed. This undermines verification of whether the edge-cloud gap is meaningful or benchmark-specific, as the abstract provides no such details.
minor comments (2)
- [Abstract] Typo in abstract: 'clound-based' should read 'cloud-based'.
- [Title and abstract] Terminology inconsistency: title refers to 'LMMs' while abstract uses 'MLLMs'; standardize throughout to Multimodal Large Language Models (MLLMs).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below and have incorporated revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Descriptor Thread description] Descriptor Thread section: The construction of the lightweight textual memory is described at a high level but lacks specifics on implementation details such as video frame sampling rates, description prompts, or summarization strategy. This is load-bearing for the central claim because the reported 51.76% accuracy depends on the assumption that key episodic details survive conversion to text without substantial loss.
Authors: We agree that the original description was insufficiently detailed. In the revised manuscript, we have expanded the Descriptor Thread section with the exact video frame sampling rate (1 FPS with keyframe selection), the full description generation prompt template, and the summarization strategy (periodic buffer compression via a 30-second sliding window with scene-change detection). These additions directly address how episodic details are retained in the textual memory and support the reported accuracy. revision: yes
-
Referee: [Results section] Results and Experiments section: The accuracies (51.76%, 54.40%, 56.00%) and TTFT values are reported without baselines, error analysis, or breakdown of question types on QAEgo4D-Closed. This undermines verification of whether the edge-cloud gap is meaningful or benchmark-specific, as the abstract provides no such details.
Authors: We acknowledge this limitation in the original presentation. The revised Results section now includes additional baselines (e.g., comparisons to non-LLM retrieval methods and prior QAEgo4D works), a detailed error analysis of failure modes, and a per-question-type accuracy breakdown (what/where/when/who) in a new table. These elements allow better assessment of the edge-cloud performance gap and its generalizability. revision: yes
Circularity Check
No circularity: purely empirical benchmark measurements
full rationale
The paper describes an asynchronous two-thread pipeline (Descriptor Thread producing textual memory from video, QA Thread answering over it) and reports direct accuracy and TTFT measurements on the external QAEgo4D-Closed benchmark for edge, server, and cloud configurations. No equations, fitted parameters, predictions derived from inputs, or self-citations are invoked to justify any central result; all numbers are measured outcomes against an independent benchmark. The derivation chain is therefore self-contained and contains no reductions by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bärmann, L. and Waibel, A. (2022). Where did i leave my keys? — episodic-memory-based ques- tion answering on egocentric videos. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR W), pages 1559–1567
work page 2022
-
[2]
Q., Song, C., Gao, D., Liu, J.-W., Gao, Z., Mao, D., and Shou, M
Chen, J., Lv, Z., Wu, S., Lin, K. Q., Song, C., Gao, D., Liu, J.-W., Gao, Z., Mao, D., and Shou, M. Z. (2024). Videollm-online: Online video large language model for streaming video. In CVPR
work page 2024
-
[3]
Dao, T. (2023). Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Di, S. and Xie, W. (2024). Grounded question- answering in long egocentric videos. In CVPR
work page 2024
-
[5]
Cheng, H., Li, B., He, W., Shu, F., and Jiang, H. (2025). Streaming video question-answering with in-context video kv-cache retrieval. arXiv preprint. arXiv:2503.00540. Ego4D Consortium (2022). Ego4d: Around the world in 3,000 hours of egocentric video. Gemini Team (2025). Gemini: A family of highly capable multimodal models
-
[7]
Lando, G., Forte, R., Farinella, G. M., and Furnari, A. (2025). How far can off-the-shelf mul- timodal large language models go in online episodic memory question answering? CoRR, abs/2506.16450
-
[8]
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Li, Y., Liu, Z., and Li, C. (2024). Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326. Qwen Team (2025a). Qwen2.5 technical report. arXiv:2412.15115. Qwen Team (2025b). Qwen3-vl technical report. arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Shen, J., Dudley, J. J., and Kristensson, P. O. (2024). Encode-store-retrieve: Augmenting hu- man memory through language-encoded egocen- tric perception. In 2024 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pages 923–931. IEEE
work page 2024
- [10]
- [11]
-
[12]
Xu, R., Xiao, G., Chen, Y., He, L., Peng, K., Lu, Y., and Han, S. (2025). Streamingvlm: Real-time understanding for infinite video streams. arXiv preprint. arXiv:2510.09608
work page internal anchor Pith review arXiv 2025
- [13]
-
[14]
Ouyang, K., Wang, L., Li, S., Li, S., et al. (2025). Timechat-online: 80% visual tokens are natu- rally redundant in streaming videos. In Proceed- ings of the 33rd ACM International Conference on Multimedia, pages 10807–10816
work page 2025
-
[15]
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., Jin, P., Zhang, W., Wang, F., Bing, L., and Zhao, D. (2025). Videollama 3: Frontier multimodal foundation models for image and video under- standing
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.