SceneGraphNet: Neural Message Passing for 3D Indoor Scene Augmentation
Pith reviewed 2026-05-24 16:03 UTC · model grok-4.3
The pith
A dense graph with attention-weighted neural messages predicts object types that fit query locations in incomplete 3D indoor scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
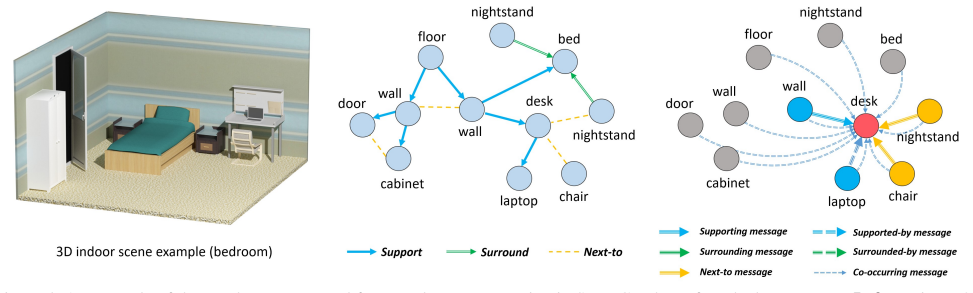
Given an input 3D scene and a query location, the method constructs a dense graph whose nodes represent the objects already present and whose edges encode spatial and structural relationships; learned messages are then passed along these edges and weighted by an attention mechanism that focuses on the most relevant context, producing a probability distribution over object types that fit the queried location.
What carries the argument
Dense graph whose nodes are scene objects and edges are spatial and structural relationships, with learned messages passed and reweighted by attention.
If this is right
- The same graph and attention process can be reused to recognize object categories from surrounding context alone.
- Repeated queries at new locations allow the model to generate complete scenes iteratively from an initial partial layout.
- Attention weights indicate which neighboring objects most influence the prediction for any given location.
- Performance gains arise specifically from the ability to focus messages on the most relevant surrounding objects rather than treating all context equally.
Where Pith is reading between the lines
- The approach could be tested on scenes with partial sensor noise to check whether attention still isolates reliable context.
- If the graph edges were restricted to only nearest-neighbor relations, one could measure how much long-range structural information the current dense connectivity supplies.
- Extending the query to also predict object orientation or scale would reveal whether the same message-passing backbone encodes those attributes.
Load-bearing premise
Spatial and structural relationships among objects in a scene are captured well enough by a dense graph and attention-weighted messages to determine which object types belong at a query location.
What would settle it
A direct comparison on SUNCG showing that the message-passing model does not achieve higher accuracy than the strongest baseline at recovering held-out objects.
Figures






read the original abstract
In this paper we propose a neural message passing approach to augment an input 3D indoor scene with new objects matching their surroundings. Given an input, potentially incomplete, 3D scene and a query location, our method predicts a probability distribution over object types that fit well in that location. Our distribution is predicted though passing learned messages in a dense graph whose nodes represent objects in the input scene and edges represent spatial and structural relationships. By weighting messages through an attention mechanism, our method learns to focus on the most relevant surrounding scene context to predict new scene objects. We found that our method significantly outperforms state-of-the-art approaches in terms of correctly predicting objects missing in a scene based on our experiments in the SUNCG dataset. We also demonstrate other applications of our method, including context-based 3D object recognition and iterative scene generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SceneGraphNet, a neural message passing model that constructs a dense graph over objects in an input (potentially incomplete) 3D indoor scene, passes learned messages along edges encoding spatial and structural relations, and uses attention to weight those messages when predicting a distribution over object categories that fit a query location. It reports that the method significantly outperforms prior approaches on missing-object prediction using the SUNCG dataset and illustrates additional uses in context-aware 3D recognition and iterative scene generation.
Significance. If the performance claims hold after verification, the work would provide evidence that attention-weighted message passing on scene graphs can capture contextual cues useful for 3D scene completion, extending graph neural network techniques to indoor augmentation tasks. The end-to-end formulation and demonstration of multiple applications are positive aspects.
major comments (2)
- [Experiments] Experiments section: the manuscript reports end-to-end outperformance on SUNCG but contains no ablation that replaces attention-weighted messages with uniform weighting, removes message passing entirely, or substitutes a simpler context aggregator while retaining the same object features and training protocol. This omission leaves the central claim—that attention-weighted messages on the dense graph are responsible for accurate type prediction—unverified.
- [Method] Method section (graph construction): the decision to use a fully dense graph over all object pairs is presented without comparison to sparser alternatives (e.g., distance-thresholded edges), so it is unclear whether full connectivity is load-bearing for the reported accuracy or merely adds computational cost and potential noise.
minor comments (2)
- [Abstract] The abstract would be strengthened by naming the concrete metrics, baselines, and dataset splits used to support the claim of significant outperformance.
- [Method] Notation for the message functions and attention weights should be introduced with explicit equations rather than prose descriptions alone.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript reports end-to-end outperformance on SUNCG but contains no ablation that replaces attention-weighted messages with uniform weighting, removes message passing entirely, or substitutes a simpler context aggregator while retaining the same object features and training protocol. This omission leaves the central claim—that attention-weighted messages on the dense graph are responsible for accurate type prediction—unverified.
Authors: We agree that the requested ablations would more directly isolate the contribution of attention-weighted message passing. While the end-to-end comparisons to prior methods provide supporting evidence, they do not control for the exact factors listed. We will add these ablations (uniform weighting, no message passing, and a simpler aggregator) to the revised manuscript while keeping the same object features and training protocol. revision: yes
-
Referee: [Method] Method section (graph construction): the decision to use a fully dense graph over all object pairs is presented without comparison to sparser alternatives (e.g., distance-thresholded edges), so it is unclear whether full connectivity is load-bearing for the reported accuracy or merely adds computational cost and potential noise.
Authors: The dense graph is chosen so that attention can learn to select relevant relations without a hand-specified sparsity threshold. We acknowledge that direct comparisons to distance-thresholded graphs would clarify whether full connectivity is necessary. We will include such comparisons in the revision. revision: yes
Circularity Check
Standard supervised GNN training with no self-referential predictions or definitional loops
full rationale
The paper defines a graph neural network that performs message passing with attention on a dense scene graph to output a distribution over object types at a query location. This architecture is trained end-to-end on SUNCG data to minimize prediction error on held-out scenes; the reported outperformance is an empirical result on test splits, not a quantity that equals its own training inputs by construction. No equations, fitted parameters, or self-citations are shown to reduce the central claim to a tautology or renaming of the input data. The method follows the ordinary supervised learning pattern for relational prediction tasks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Battaglia, R. Pascanu, M. Lai, D. J. Rezende, et al. In- teraction networks for learning about objects, relations and physics. In Advances in Neural Information Processing Sys- tems, NIPS, 2016. 1, 2
work page 2016
-
[2]
K. Chen, Y .-K. Lai, Y .-X. Wu, R. Martin, and S.-M. Hu. Automatic semantic modeling of indoor scenes from low- quality rgb-d data using contextual information. ACM Trans. Graph., 33(6), 2014. 2
work page 2014
-
[3]
M. Fisher and P. Hanrahan. Context-based search for 3d models. ACM Trans. Graph., 29(6), 2010. 2
work page 2010
- [4]
- [5]
- [6]
-
[7]
W. Hamilton, Z. Ying, and J. Leskovec. Inductive repre- sentation learning on large graphs. In Advances in Neural Information Processing Systems, NIPS, 2017. 1, 2
work page 2017
-
[8]
W. L. Hamilton, R. Ying, and J. Leskovec. Representation learning on graphs: Methods and applications. IEEE Data Eng. Bull., 40(3), 2017. 2
work page 2017
-
[9]
Automatic Generation of Constrained Furniture Layouts
P. Henderson and V . Ferrari. A generative model of 3d object layouts in apartments. CoRR, abs/1711.10939, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Z. S. Kermani, Z. Liao, P. Tan, and H. R. Zhang. Learning 3d scene synthesis from annotated RGB-D images. Computer Graph. Forum, 35(5), 2016. 2
work page 2016
-
[11]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2014. 6
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[12]
M. Li, A. G. Patil, K. Xu, S. Chaudhuri, O. Khan, A. Shamir, C. Tu, B. Chen, D. Cohen-Or, and H. Zhang. Grains: Gener- ative recursive autoencoders for indoor scenes. ACM Trans. Graph., 38(2), 2019. 2, 6, 7
work page 2019
-
[13]
Y . Li, D. Tarlow, M. Brockschmidt, and R. Zemel. Gated graph sequence neural networks. International Conference on Learning Representations, ICLR, 2015. 2
work page 2015
-
[14]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Conference on Computer Vision and Pattern Recognition, CVPR, 2017. 6
work page 2017
-
[15]
Fast and Flexible Indoor Scene Synthesis via Deep Convolutional Generative Models
D. Ritchie, K. Wang, and Y . Lin. Fast and flexible indoor scene synthesis via deep convolutional generative models. CoRR, abs/1811.12463, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini. The graph neural network model. IEEE Transactions on Neural Networks, 20(1), 2009. 2
work page 2009
-
[17]
F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini. The graph neural network model. IEEE Trans. on Neural Networks, 20(1), 2009. 2
work page 2009
-
[18]
K. T. Sch ¨utt, F. Arbabzadah, S. Chmiela, K. R. M ¨uller, and A. Tkatchenko. Quantum-chemical insights from deep ten- sor neural networks. Nature Communications, 8, 2017. 2
work page 2017
-
[19]
S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and T. Funkhouser. Semantic scene completion from a single depth image. In Conference on Computer Vision and Pattern Recognition, CVPR, 2017. 2
work page 2017
-
[20]
H. Su, S. Maji, E. Kalogerakis, and E. G. Learned-Miller. Multi-view convolutional neural networks for 3d shape recognition. In International Conferrence on Computer Vi- sion, ICCV, 2015. 2, 6, 8
work page 2015
-
[21]
K. Wang, Y .-A. Lin, B. Weissmann, M. Savva, A. X. Chang, and D. Ritchie. Planit: Planning and instantiating indoor scenes with relation graph and spatial prior networks. ACM Trans. Graph., to appear, 2019. 2
work page 2019
-
[22]
K. Wang, M. Savva, A. X. Chang, and D. Ritchie. Deep convolutional priors for indoor scene synthesis. ACM Trans. Graph., 37(4), 2018. 2, 6, 7
work page 2018
-
[23]
Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3d shapenets: A deep representation for volumet- ric shapes. In Conference on Computer Vision and Pattern Recognition, CVPR, 2015. 6
work page 2015
-
[24]
K. Xu, K. Chen, H. Fu, W.-L. Sun, and S.-M. Hu. Sketch2scene: sketch-based co-retrieval and co-placement of 3d models. ACM Trans. Graph., 32(4), 2013. 2
work page 2013
- [25]
-
[26]
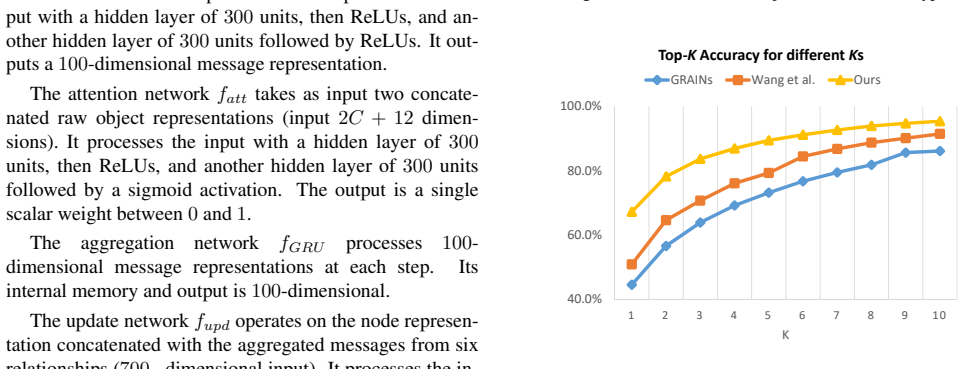
2 Supplementary Materials Neural network details. The initialization MLP finit takes as input a (C + 6)-dimensional raw object represen- tation vector, where C is the number of object categories, and the rest 6 dimensions represent the object’s 3D position p∈R 3 and scale d∈R 3. It processes the input with a hidden layer of 300 units, then ReLUs, and anot...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.