Generating Logically Consistent Synthetic Supply Chain Data with LLM-Driven Knowledge Graph Reasoning
Pith reviewed 2026-06-29 18:36 UTC · model grok-4.3
The pith
TabKG uses a validated Column Relationship Knowledge Graph to generate synthetic supply chain data that is logically consistent by construction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
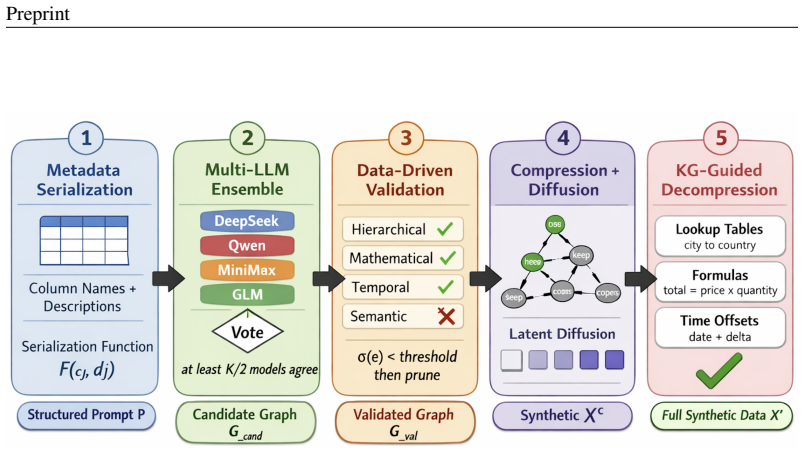
The paper presents TabKG, a knowledge-graph-guided framework for generating logically consistent synthetic supply chain tabular data. It builds a Column Relationship Knowledge Graph (CR-KG) to represent operational dependencies, employs a multi-LLM ensemble with majority voting to propose candidate relationships from metadata, validates these against real data to remove hallucinated or unsupported edges, and uses the validated CR-KG to guide generation: independent columns are produced with a latent diffusion model while dependent columns are deterministically reconstructed to satisfy the discovered relationships, enforcing logical consistency by construction.
What carries the argument
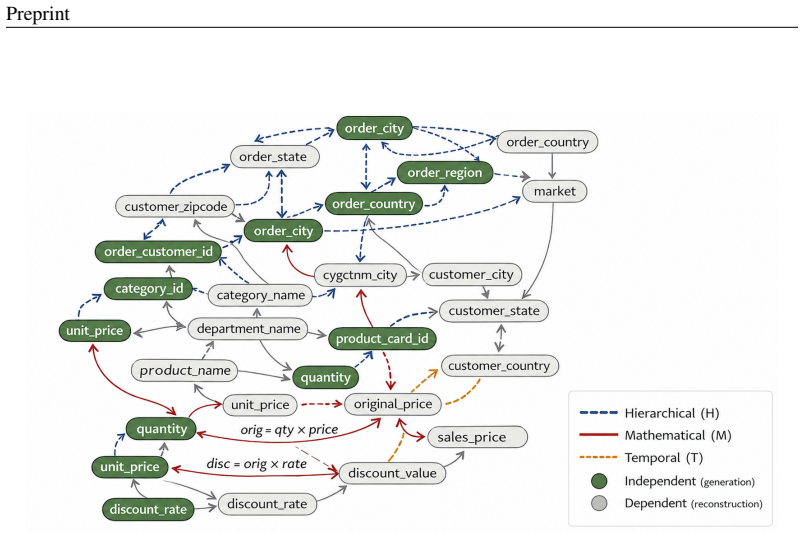
The Column Relationship Knowledge Graph (CR-KG), which encodes operational dependencies between columns and directs the deterministic reconstruction of dependent columns after independent-column generation.
If this is right
- Synthetic records will satisfy all validated operational dependencies by design.
- The method separates statistical generation of independent columns from rule-based reconstruction of dependent columns.
- Validation against real data removes hallucinated relationships proposed by the LLM ensemble.
- The resulting data supports operational simulation and decision-making without violating process constraints.
Where Pith is reading between the lines
- If the validation step misses a dependency, generated records may still violate unrepresented operational rules in practice.
- The CR-KG construction approach could transfer to other tabular domains with strong relational constraints, such as financial or healthcare records.
- Incremental updates to the CR-KG as new real data arrives might allow the framework to adapt over time without full re-validation.
- Pairing TabKG with differential privacy mechanisms could further improve utility for sensitive supply chain datasets.
Load-bearing premise
The multi-LLM ensemble with majority voting plus validation against real data will identify a sufficiently complete and accurate set of operational relationships without missing critical dependencies or retaining hallucinated edges.
What would settle it
Generating synthetic records and finding that a non-negligible fraction violates a known operational dependency that the validated CR-KG failed to capture, or that an edge retained after validation has no supporting evidence in the real data.
Figures



read the original abstract
Synthetic data offers a promising solution to two persistent barriers in supply chain analytics: data scarcity and data privacy. However, for synthetic data to support operational simulation and decision-making, it must do more than reproduce the statistical distributions of real records, and also preserve the \emph{operational logic} that governs supply chain processes, including the temporal orderings, mathematical dependencies, hierarchical taxonomies, and conditional rules that make a record operationally plausible. We consider this logic as the ``physics'' of supply chain data. Existing tabular generative models are primarily optimized for distributional fidelity and downstream predictive utility, and therefore often generate records that appear statistically realistic but violate fundamental operational constraints. This paper introduces \textbf{\textit{TabKG}}, a knowledge-graph-guided framework for logically consistent synthetic supply chain tabular data generation. TabKG constructs a \textbf{\textit{Column Relationship Knowledge Graph (CR-KG)}} to represent data operational dependencies. It uses a multi-LLM ensemble with majority voting to propose candidate relationships from column metadata, validates these relationships against real data to remove hallucinated or unsupported edges, and then uses the validated CR-KG to guide generation. Specifically, TabKG compresses the original table into independent columns, generates these columns using a latent diffusion model, and deterministically reconstructs dependent columns according to the validated relationships, enforcing logical consistency by construction with respect to the discovered operational rules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TabKG, a knowledge-graph-guided framework for generating logically consistent synthetic supply chain tabular data. It builds a Column Relationship Knowledge Graph (CR-KG) by using a multi-LLM ensemble with majority voting to propose candidate relationships from column metadata, validates these against real data to remove unsupported edges, generates independent columns using a latent diffusion model, and deterministically reconstructs dependent columns based on the validated CR-KG to enforce operational logic including temporal orderings, mathematical dependencies, and conditional rules by construction.
Significance. If the method successfully captures the operational rules, it would represent a meaningful advance over standard tabular generative models that focus only on distributional fidelity, enabling synthetic data suitable for operational simulation and decision-making in supply chains. The integration of LLM-driven knowledge graph construction with validation and deterministic reconstruction is a promising direction for incorporating domain logic into synthetic data generation.
major comments (1)
- [Abstract] Abstract: The central claim that logical consistency is enforced 'by construction' with respect to the discovered operational rules assumes the validated CR-KG contains every relevant dependency (temporal orderings, conditional rules, mathematical dependencies, taxonomies). The pipeline only validates LLM-proposed candidates against real data to remove unsupported edges; no mechanism is described for detecting or adding missing edges (e.g., via exhaustive enumeration, expert review, or held-out constraint checking). This is load-bearing, as an incomplete CR-KG would permit the independent-column diffusion step to generate values that violate unrepresented rules after deterministic reconstruction.
minor comments (1)
- [Abstract] The abstract states that the table is 'compressed' into independent columns but does not specify the selection criteria or algorithm for partitioning columns into independent vs. dependent sets.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comment correctly identifies a key scoping issue in how the method's guarantees are presented. We address it directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that logical consistency is enforced 'by construction' with respect to the discovered operational rules assumes the validated CR-KG contains every relevant dependency (temporal orderings, conditional rules, mathematical dependencies, taxonomies). The pipeline only validates LLM-proposed candidates against real data to remove unsupported edges; no mechanism is described for detecting or adding missing edges (e.g., via exhaustive enumeration, expert review, or held-out constraint checking). This is load-bearing, as an incomplete CR-KG would permit the independent-column diffusion step to generate values that violate unrepresented rules after deterministic reconstruction.
Authors: We agree with the observation. The current pipeline proposes candidate edges via the LLM ensemble, then removes those unsupported by real data; it contains no procedure for identifying or incorporating missing edges. Consequently, the CR-KG is not guaranteed to be complete with respect to all operational rules that may exist in the domain. The abstract's phrasing ('with respect to the discovered operational rules') is therefore technically accurate but could be misread as implying broader coverage. We will (1) revise the abstract to emphasize that consistency holds only for relationships present in the validated CR-KG, (2) add an explicit Limitations paragraph discussing the dependence on LLM-proposed candidates and the absence of exhaustive or expert-driven rule discovery, and (3) note this as an avenue for future work. These changes will be made in the next revision. revision: yes
Circularity Check
No circularity: consistency enforced from externally validated rules
full rationale
The derivation chain extracts candidate relationships via LLM ensemble on metadata, validates support against real data (removing unsupported edges), then uses the resulting CR-KG only for deterministic reconstruction after independent-column diffusion. Logical consistency is defined relative to this externally validated graph rather than being fitted to or defined by the generation target itself. No self-definitional loops, no fitted parameters renamed as predictions, no load-bearing self-citations, and no ansatz or uniqueness claims imported from prior author work appear in the provided text. The method is self-contained against the real-data validation step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Supply chain data is governed by operational logic consisting of temporal orderings, mathematical dependencies, hierarchical taxonomies, and conditional rules.
invented entities (2)
-
Column Relationship Knowledge Graph (CR-KG)
no independent evidence
-
TabKG framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
Evaluating Inter-Column Logical Relationships in Synthetic Tabular Data Generation
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page internal anchor Pith review doi:10.48550/arxiv.2502.04055 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.