Rethinking the Multilingual Reasoning Gap with Layer Swap
Pith reviewed 2026-06-29 17:53 UTC · model grok-4.3
The pith
Transferring middle layers from English reasoning models closes most of the native-language chain-of-thought gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
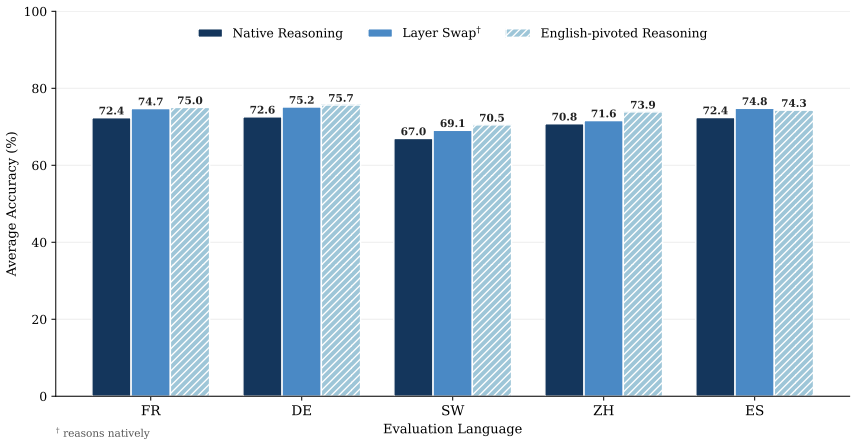
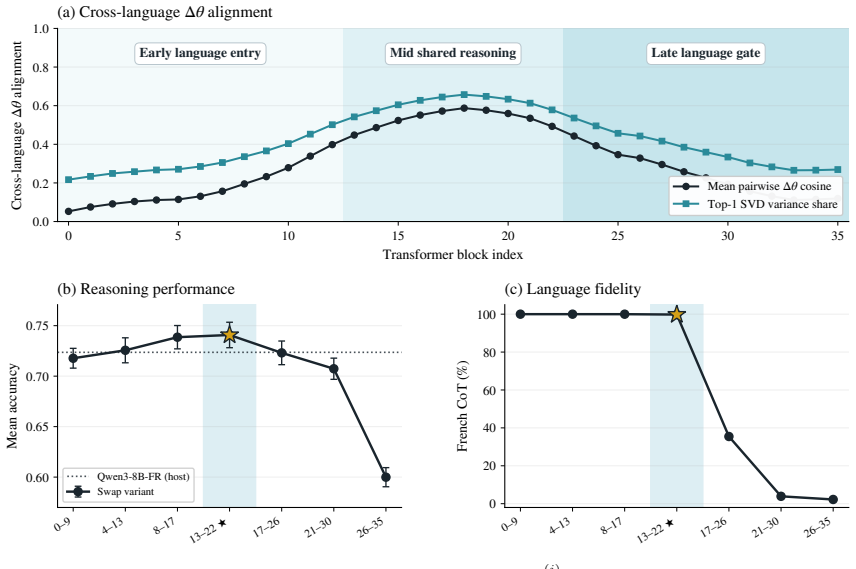
When native and English-pivoted reasoning specialists are fine-tuned under comparable supervision, the native reasoning gap averages 1.9--3.5% across non-English languages. The middle layers show aligned updates, indicating a language-agnostic reasoning core, while outer layers diverge. Layer swap of these mid-layers from English to native specialists closes most of the gap while preserving target-language chain-of-thought.
What carries the argument
Layer Swap, the transfer of mid-layer weights from an English-pivoted specialist into a native-language specialist to combine strong reasoning with native output language.
If this is right
- The reasoning gap is small when training data quality is matched across languages.
- Middle layers contain the core reasoning computations shared across languages.
- Outer layers primarily handle language-specific processing.
- Layer swap improves native reasoning without changing the chain-of-thought language.
Where Pith is reading between the lines
- Models could be built with a single reasoning core and multiple language adapters for efficiency.
- The finding may apply to other capabilities like planning or tool use beyond reasoning.
- It reduces reliance on creating large native-language reasoning corpora.
Load-bearing premise
The long multilingual reasoning datasets provide equivalent supervision quality and topic coverage whether constructed natively or via English pivot.
What would settle it
Retraining the specialists on independently verified native-language reasoning examples of matched difficulty and measuring whether the native-English performance difference exceeds 4 percentage points.
Figures




read the original abstract
Recent reasoning Large Language Models produce a chain-of-thought (CoT) predominantly in English, even when prompted in non-English languages. Prior work suggests that forcing the CoT to remain in the input language (\emph{native reasoning}) substantially degrades performance relative to allowing the model to reason in English before answering in the input language (\emph{English-pivoted reasoning}). However, most studies of this native reasoning gap rely on inference-time interventions or limited native-language training data. We revisit this comparison at a larger scale and under comparable supervision. We construct long multilingual reasoning datasets across six languages (English, French, German, Spanish, Chinese and Swahili); fine-tune specialists in both native and English-pivoted regimes on top of \texttt{Qwen/Qwen3-8B-Base}, and evaluate across mathematics, science, general knowledge, and code. In this setting, the average native reasoning gap shrinks to 1.9--3.5\% across the five non-English languages, considerably smaller than previously reported. Weight-space analysis of the native specialists reveals aligned fine-tuning updates in the middle layers and divergence in the outer layers. This points to a largely language-agnostic reasoning core surrounded by language-specific layers. Exploiting this structure, we introduce a Layer Swap: transferring the English specialist's stronger reasoning mid-layers into each native specialist, closing most of the native reasoning gap across the five non-English languages while preserving CoT in the target language. We release all models and datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the native reasoning gap in LLMs (where CoT in the input language underperforms English-pivoted reasoning) is much smaller than previously reported when using long multilingual reasoning datasets under comparable supervision. Fine-tuning Qwen3-8B-Base specialists on datasets across English, French, German, Spanish, Chinese, and Swahili yields an average gap of only 1.9--3.5% across the five non-English languages. Weight-space analysis shows aligned updates in middle layers (suggesting a language-agnostic reasoning core) and divergence in outer layers. A Layer Swap method transfers the English specialist's mid-layers into native specialists, closing most of the gap while preserving target-language CoT. All models and datasets are released.
Significance. If the results hold under verified data equivalence, the work would be significant for showing that multilingual reasoning gaps are smaller than thought and that a language-agnostic core exists in mid-layers, enabling targeted interventions like layer swap for better native-language performance. Releasing models and datasets is a clear strength for reproducibility and further research.
major comments (2)
- [Dataset construction] Dataset construction section: The central attribution of the 1.9--3.5% gap (and the success of layer swap) to language rather than supervision mismatch rests on the unverified claim of 'comparable supervision' between native and English-pivoted datasets. Explicit comparative statistics on token counts, average reasoning chain lengths, step complexity, topic coverage, and quality metrics per language (especially Swahili) are required to substantiate this load-bearing assumption.
- [Evaluation and results] Evaluation and results sections: The reported gap sizes, layer alignments, and layer-swap improvements lack supporting details such as exact per-language/per-task accuracies, number of evaluation examples, variance across runs, or statistical tests. Without these, it is not possible to assess whether the small gap and improvements are robust or artifacts of evaluation setup.
minor comments (1)
- [Abstract and introduction] The abstract and introduction would benefit from a brief table summarizing the six languages, dataset sizes, and high-level performance numbers to orient readers before the detailed claims.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on our manuscript. The feedback highlights key areas where additional details can strengthen our claims about the multilingual reasoning gap and the effectiveness of layer swap. We address each major comment below and commit to revisions that provide the requested evidence and statistics.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: The central attribution of the 1.9--3.5% gap (and the success of layer swap) to language rather than supervision mismatch rests on the unverified claim of 'comparable supervision' between native and English-pivoted datasets. Explicit comparative statistics on token counts, average reasoning chain lengths, step complexity, topic coverage, and quality metrics per language (especially Swahili) are required to substantiate this load-bearing assumption.
Authors: We thank the referee for this valuable observation. Our dataset construction aimed for comparability by using the same set of reasoning problems translated and adapted across languages, maintaining similar lengths and complexities. However, we recognize that explicit metrics were not provided. In the revised manuscript, we will include detailed comparative statistics, including token counts, average reasoning chain lengths, measures of step complexity, topic coverage, and quality assessments for each language, with focused analysis on Swahili. This addition will substantiate the claim of comparable supervision. revision: yes
-
Referee: [Evaluation and results] Evaluation and results sections: The reported gap sizes, layer alignments, and layer-swap improvements lack supporting details such as exact per-language/per-task accuracies, number of evaluation examples, variance across runs, or statistical tests. Without these, it is not possible to assess whether the small gap and improvements are robust or artifacts of evaluation setup.
Authors: We agree that providing more detailed evaluation metrics is essential for demonstrating robustness. The current version reports aggregated results. We will revise the evaluation and results sections to include exact per-language and per-task accuracies, the precise number of evaluation examples, variance or standard deviations across multiple runs, and appropriate statistical tests to compare the performance differences. These additions will allow for a better assessment of whether the observed gaps and improvements are statistically significant and reliable. revision: yes
Circularity Check
No circularity; claims rest on empirical fine-tuning, evaluation, and weight analysis.
full rationale
The paper constructs long multilingual reasoning datasets, fine-tunes native and English-pivoted specialists on Qwen/Qwen3-8B-Base, evaluates performance gaps across tasks, analyzes weight updates in middle vs. outer layers, and applies layer swapping. All central claims derive from these direct empirical steps rather than any equation, fitted parameter, or self-citation that reduces the reported gap or layer alignment to a definitional identity. No self-definitional, fitted-input, or uniqueness-imported patterns appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Qwen/Qwen3-8B-Base model possesses sufficient capacity to support effective multilingual reasoning fine-tuning
Reference graph
Works this paper leans on
-
[1]
Lucas Bandarkar and Nanyun Peng
Layer swapping for zero-shot cross-lingual transfer in large language models.arXiv preprint arXiv:2410.01335. Lucas Bandarkar and Nanyun Peng. 2025. The unrea- sonable effectiveness of model merging for cross- lingual transfer in llms. InProceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025), pages 131–148. Josh Barua, Seun Eis...
-
[2]
arXiv preprint arXiv:2508.14828
Long chain-of-thought reasoning across lan- guages.arXiv preprint arXiv:2508.14828. Julen Etxaniz, Gorka Azkune, Aitor Soroa, Oier Lopez de Lacalle, and Mikel Artetxe. 2024. Do multilingual 9 language models think better in english? InProceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Lin- guistics: Hum...
-
[3]
Beyond english-centric training: How rein- forcement learning improves cross-lingual reasoning in llms.arXiv preprint arXiv:2509.23657. Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Worts- man, Suchin Gururangan, Ludwig Schmidt, Han- naneh Hajishirzi, and Ali Farhadi. 2023. Editing models with task arithmetic. InThe Eleventh Inter- national Conference on...
-
[4]
Language Models are Multilingual Chain-of-Thought Reasoners
Language models are multilingual chain-of- thought reasoners.arXiv preprint arXiv:2210.03057. Shivalika Singh, Angelika Romanou, Clémentine Four- rier, David I. Adelani, Jian Gang Ngui, Daniel Vila-Suero, Peerat Limkonchotiwat, Kelly Marchi- sio, Wei Qi Leong, Yosephine Susanto, Raymond Ng, Shayne Longpre, Wei-Yin Ko, Madeline Smith, Antoine Bosselut, Ali...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Global mmlu: Understanding and addressing cultural and linguistic biases in multilingual evalua- tion.Preprint, arXiv:2412.03304. Guijin Son, Donghun Yang, Hitesh Laxmichand Patel, Amit Agarwal, Hyunwoo Ko, Chanuk Lim, Srikant Panda, Minhyuk Kim, Nikunj Drolia, Dasol Choi, and 1 others. 2025. Pushing on multilingual reason- ing models with language-mixed ...
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Xue Zhang, Yunlong Liang, Fandong Meng, Songming Zhang, Kaiyu Huang, Yufeng Chen, Jinan Xu, and Jie Zhou. 2025. Think natively: Unlocking multilingual reasoning with consistency-enhanced reinforcement learning.arXiv preprint arXiv:2510.07300. Yiran Zhao, Wenxuan Zhang, Guizhen Chen, Kenji Kawaguchi, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.