LooseControlVideo: Directorial Video Control using Spatial Blocking
Pith reviewed 2026-06-26 21:03 UTC · model grok-4.3
The pith
Sparse oriented 3D boxes let video models infer realistic occlusions and dynamics from high-level trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
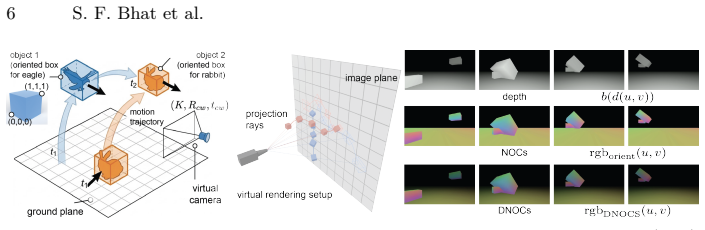
Oriented 3D boxes function as an effective blocking proxy: after fine-tuning on DNOCS-annotated videos, the model generates plausible occlusions, dynamics, and interactions directly from sparse 3D size, orientation, and depth-order inputs without requiring dense guidance.
What carries the argument
DNOCS encoding of 3D size, orientation and depth-ordered occlusions, applied as annotation for fine-tuning the generative backbone so that sparse boxes suffice as control signals.
If this is right
- Users can author multi-object trajectories and layouts with far less manual effort than dense depth or flow maps require.
- Small local edits to a single object's path or contact can be applied while the rest of the scene stays coherent.
- The same sparse-box interface yields measurable gains in trajectory accuracy, rigid-motion consistency, and occlusion correctness on the reported benchmarks.
Where Pith is reading between the lines
- The approach could be tested on longer clips or scenes with deformable objects to check whether the geometric prior continues to suffice.
- Similar sparse 3D annotations might be applied to other video backbones to see if the control benefit transfers.
- The method suggests a route toward directorial tools that combine 3D blocking with natural-language instructions for hybrid authoring.
Load-bearing premise
Fine-tuning on videos labeled with the new 3D encoding will enable the model to produce realistic occlusions and interactions when given only sparse oriented boxes.
What would settle it
Generate videos from 3D-box sequences whose occlusion patterns or interaction timings fall outside the annotated training distribution and check whether depth ordering or contact events remain correct.
Figures




read the original abstract
Precise 3D spatial orchestration in text-to-video generation remains a significant challenge, particularly for multi-object scenes where semantic layout and temporal dynamics are often entangled. While existing depth-conditioned models achieve good structural fidelity, they necessitate dense, frame-accurate guidance that is labor-intensive to author for dynamic events involving deformable objects. We present LooseControlVideo, a framework that enables intuitive and expressive control by using sparse, oriented 3D boxes as a "blocking" proxy. This allows users to author high-level layout and trajectory while leveraging a video generative model to generate realistic occlusions, dynamics and interactions. We achieve this by fine-tuning a Wan 2.2 backbone on a video dataset annotated with DNOCS, a novel encoding for 3D size, orientation and depth-ordered occlusions. Furthermore, our method allows for localized refinement, such as adjusting a jump trajectory or adding an interaction, with minimal disruption to the global scene context. Extensive evaluations on the nuScenes, HO-3D, and BEHAVE benchmarks demonstrate that LooseControlVideo significantly outperforms existing 2D-box and flow-based baselines. Our findings indicate a 1.2x to 3x improvement in Trajectory Error; 2x improvement in Rigid Motion Consistency; and a 1.5x to 2x increase in Occlusion Accuracy over current state-of-the-art layout-conditioned models, demonstrating that oriented 3D primitives provide good geometric prior for complex, multi-agent video authoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LooseControlVideo, a framework for text-to-video generation that uses sparse oriented 3D boxes as a blocking proxy for high-level layout and trajectory control. It fine-tunes a Wan 2.2 backbone on video data annotated with a novel DNOCS encoding (for 3D size, orientation, and depth-ordered occlusions) to generate realistic dynamics, occlusions, and interactions without dense guidance. The central claim is that this yields 1.2x–3x gains in Trajectory Error, 2x in Rigid Motion Consistency, and 1.5x–2x in Occlusion Accuracy over 2D-box and flow-based baselines on the nuScenes, HO-3D, and BEHAVE benchmarks.
Significance. If the empirical claims hold after proper verification of baselines and ablations, the work would demonstrate that oriented 3D primitives supply a useful geometric prior for multi-agent video authoring, reducing the authoring burden relative to dense depth conditioning while supporting localized edits.
major comments (2)
- [Abstract] Abstract: the central empirical claim of outperformance (1.2x–3x Trajectory Error, etc.) is stated without any description of baseline implementations, training details, statistical significance, or ablation studies on the DNOCS encoding; this renders the quantitative results unverifiable from the provided text.
- [Abstract] Abstract: the DNOCS encoding is introduced as novel but never defined or formalized; without its explicit construction or how it encodes depth-ordered occlusions, it is impossible to assess whether the fine-tuning step actually enables inference from sparse inputs as claimed.
minor comments (1)
- [Abstract] The abstract refers to 'Wan 2.2 backbone' and 'DNOCS' without prior definition or citation, which hinders immediate readability.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We agree that the abstract can be made more self-contained to improve verifiability of the claims and to provide a high-level definition of DNOCS. We will revise the abstract accordingly while ensuring it remains concise; detailed explanations remain in the main text and supplementary material.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of outperformance (1.2x–3x Trajectory Error, etc.) is stated without any description of baseline implementations, training details, statistical significance, or ablation studies on the DNOCS encoding; this renders the quantitative results unverifiable from the provided text.
Authors: We acknowledge the abstract's conciseness limits immediate verifiability. The main manuscript (Sections 4.1–4.3 and 5) specifies the baselines as 2D-box methods adapted from prior layout-conditioned video models and flow-based approaches, with training on the Wan 2.2 backbone using the DNOCS-annotated dataset; statistical significance is assessed via multiple random seeds and reported with standard deviations. Ablations on the DNOCS components appear in Section 5.2. To address the concern, we will add one sentence to the abstract briefly naming the baseline categories and noting that full implementation and ablation details are in the experiments section. revision: yes
-
Referee: [Abstract] Abstract: the DNOCS encoding is introduced as novel but never defined or formalized; without its explicit construction or how it encodes depth-ordered occlusions, it is impossible to assess whether the fine-tuning step actually enables inference from sparse inputs as claimed.
Authors: The abstract provides a brief description ('a novel encoding for 3D size, orientation and depth-ordered occlusions'), but we agree a more explicit high-level formalization would help. Section 3.1 of the manuscript defines DNOCS as a per-frame representation that augments oriented 3D bounding boxes with explicit depth ordering to encode occlusions. We will revise the abstract to include a short clause such as 'DNOCS, which parameterizes oriented 3D boxes with size, rotation, and depth-ordered occlusion masks' to clarify its role in enabling sparse control during fine-tuning. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on empirical benchmark results (nuScenes, HO-3D, BEHAVE) comparing trajectory error, motion consistency, and occlusion accuracy against external baselines after fine-tuning on DNOCS-annotated data. No equations, parameter fits presented as predictions, self-citation load-bearing premises, or ansatz smuggling appear in the abstract or described derivation. The method is self-contained via standard training and evaluation procedures without internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
DNOCS encoding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bhat, S.F., Mitra, N., Wonka, P.: Loosecontrol: Lifting controlnet for generalized depthconditioning.In:ACMSIGGRAPH2024ConferencePapers.pp.1–11(2024) 3, 4
2024
-
[2]
In: CVPR (2022) 3, 10, 13, 14
Bhatnagar, B.L., Xie, X., Petrov, I., Sminchisescu, C., Theobalt, C., Pons-Moll, G.: BEHAVE: dataset and method for tracking human object interactions. In: CVPR (2022) 3, 10, 13, 14
2022
-
[3]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brack, M., Friedrich, F., Kornmeier, K., Tsaban, L., Schramowski, P., Kersting, K., Passos, A.: Ledits++: Limitless image editing using text-to-image models. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8861–8870 (2024) 3
2024
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18392–18402 (2023) 3
2023
-
[5]
OpenAI Blog (2024) 1, 4
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Lecomte, J., Sukhum, A., Senpuru, D., et al.: Video generation models as world simulators. OpenAI Blog (2024) 1, 4
2024
-
[6]
In: CVPR (2020) 3, 9, 12, 14
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: CVPR (2020) 3, 9, 12, 14
2020
-
[7]
In: CVPR (2025) 8, 12
Chen, S., Guo, H., Zhu, S., Zhang, F., Huang, Z., Feng, J., Kang, B.: Video depth anything: Consistent depth estimation for super-long videos. In: CVPR (2025) 8, 12
2025
-
[8]
Google Tech- nical Report (2024) 1, 4
DeepMind, G.: Veo: Google’s most capable generative video model. Google Tech- nical Report (2024) 1, 4
2024
-
[9]
Gu, Z., Yan, R., Lu, J., Li, P., Dou, Z., Si, C., Dong, Z., Liu, Q., Lin, C., Liu, Z., Wang, W., Liu, Y.: Diffusion as shader: 3d-aware video diffusion for versatile video generation control (2025) 4
2025
-
[10]
In: CVPR (2020) 3, 10, 13
Hampali, S., Rad, M., Oberweger, M., Lepetit, V.: Honnotate: A method for 3d annotation of hand and object poses. In: CVPR (2020) 3, 10, 13
2020
-
[11]
In: ICLR (2025) 4
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: Enabling camera control for video diffusion models. In: ICLR (2025) 4
2025
-
[12]
Advances in neural information processing systems33, 6840–6851 (2020) 3
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 3
2020
-
[13]
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. pp. 8633–8646 (2022) 4
2022
-
[14]
In: CVPR (2024) 12, 14
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench: Comprehensive benchmark suite for video generative models. In: CVPR (2024) 12, 14
2024
-
[15]
In: CVPR (2025) 5
Jeong, H., Huang, C.H.P., Ye, J.C., Mitra, N., Ceylan, D.: Track4gen: Teaching video diffusion models to track points improves video generation. In: CVPR (2025) 5
2025
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17191–17202 (2025) 8
2025
-
[17]
In: CVPR (2026) 4 16 S
Kizil, M.B., Sanli, E., Mitra, N.J., Erdem, E., Erdem, A., Ceylan, D.: Lamp: Language-assisted motion planning for controllable video generation. In: CVPR (2026) 4 16 S. F. Bhat et al
2026
-
[18]
In: CVPR (2026) 4
Lee, Y.C., Zhang, Z., Huang, J., Wang, J.H., Lee, J.Y., Huang, J.B., Shechtman, E., Li, Z.: Generative video motion editing with 3d point tracks. In: CVPR (2026) 4
2026
-
[19]
In: European Conference on Computer Vision
Li, R., Zheng, C., Rupprecht, C., Vedaldi, A.: Dragapart: Learning a part-level motion prior for articulated objects. In: European Conference on Computer Vision. pp. 165–183. Springer (2024) 3
2024
-
[20]
ACM TOG30(4), 52:1–52:12 (2011) 8
Li, Y., Wu, X., Chrysanthou, Y., Sharf, A., Cohen-Or, D., Mitra, N.J.: Globfit: Consistently fitting primitives by discovering global relations. ACM TOG30(4), 52:1–52:12 (2011) 8
2011
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li,Y.,Liu,H.,Wu,Q.,Mu,F.,Yang,J.,Gao,J.,Li,C.,Lee,Y.J.:Gligen:Open-set grounded text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22511–22521 (2023) 3, 4
2023
-
[22]
In: COLM (2024) 4
Lin, H., Zala, A., Cho, J., Bansal, M.: Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning. In: COLM (2024) 4
2024
-
[23]
In: ECCV (2023) 8
Liu,S.,Zuo,Z.,Hou,J.,Peng,H.,Li,H.,Hui,J.,Huang,J.,Li,F.,Zhang,L.,etal.: Grounding dino: Marrying dino with grounded pre-training for open-vocabulary object detection. In: ECCV (2023) 8
2023
- [24]
-
[25]
Mou, C., Wang, X., Xie, L., Zhang, J., Qi, Z., Shan, Y., Qie, X.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Peebles, W., Xie, S.: Scalable diffusion models with transformers (2023) 4
2023
-
[27]
In: CVPR (2016) 2, 10
Perazzi, F., Pont-Tuset, J., McWilliams, B., Gool, L.V., Gross, M., Sorkine- Hornung, A.: A benchmark dataset and evaluation methodology for video object segmentation. In: CVPR (2016) 2, 10
2016
-
[28]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024) 8, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Reid, M., Savinov, N., Teplyashin, D., Coppin, D., Mumtaz, A., Ma, S., Paduraru, C., Paquet, U., Hayes, P., et al.: Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
In: CVPR (2025) 4
Ren,X.,Shen,T.,Huang,J.,Ling,H.,Lu,Y.,Nimier-David,M.,Müller,T.,Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video generation with precise camera control. In: CVPR (2025) 4
2025
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 3
2022
-
[32]
Saha, O., Krs, V., Mech, R., Maji, S., Blackburn-Matzen, K., Gadelha, M.: Sigma- gen: Structure and identity guided multi-subject assembly for image generation (2025) 14
2025
-
[33]
Advances in Neural Information Processing Systems35, 36479–36494 (2022) 3
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems35, 36479–36494 (2022) 3
2022
-
[34]
Shi, Y., Xue, C., Liew, J.H., Pan, J., Yan, H., Zhang, W., Tan, V.Y., Bai, S.: Dragdiffusion: Harnessing diffusion models for interactive point-based image edit- ing.In:ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPattern Recognition. pp. 8839–8849 (2024) 3 LCV: Directorial Video Control using Spatial Blocking 17
2024
-
[35]
In: ICLR (2022) 4
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., Parikh, D., Gupta, S., Taigman, Y.: Make-a-video: Text-to- video generation without text-video data. In: ICLR (2022) 4
2022
-
[36]
Team, W.: Wan: Open and high-quality video generation with 3d-aware transform- ers,https://arxiv.org/abs/2503.203141, 4
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
In: ECCV (2020) 12
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: ECCV (2020) 12
2020
-
[38]
In: ACM SIGGRAPH 2023 Conference Proceedings
Voynov, A., Aberman, K., Cohen-Or, D.: Sketch-guided text-to-image diffusion models. In: ACM SIGGRAPH 2023 Conference Proceedings. pp. 1–11 (2023) 3
2023
-
[39]
In: CVPR (June 2019) 6
Wang, H., Sridhar, S., Huang, J., Valentin, J., Song, S., Guibas, L.J.: Normalized object coordinate space for category-level 6d object pose and size estimation. In: CVPR (June 2019) 6
2019
-
[40]
arXiv preprint arXiv:2402.01566 (2024),https://arxiv.org/abs/2402.015664
Wang, J., Zhang, Y., Zou, J., Zeng, Y., Wei, G., Yuan, L., Li, H.: Boxima- tor: Generating rich and controllable motions for video synthesis. arXiv preprint arXiv:2402.01566 (2024),https://arxiv.org/abs/2402.015664
-
[41]
arXiv preprint arXiv:2205.12952 (2022) 3
Wang, T., Zhang, T., Zhang, B., Ouyang, H., Chen, D., Chen, Q., Wen, F.: Pretraining is all you need for image-to-image translation. arXiv preprint arXiv:2205.12952 (2022) 3
-
[42]
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation (2023) 4
2023
-
[43]
Yang, S., Hou, L., Huang, H., Ma, C., Wan, P., Zhang, D., Chen, X., Liao, J.: Direct-a-video: Customized video generation with user-directed camera movement and object motion (2024) 4
2024
-
[44]
In: ICLR (2025) 4
Yang, Z., et al.: Cogvideox: Text-to-video diffusion models with an expert trans- former. In: ICLR (2025) 4
2025
-
[45]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3836–3847 (2023) 3
2023
-
[46]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023) 8
2023
- [47]
-
[48]
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all (2024),https: //arxiv.org/abs/2412.204044
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Zhu, H., He, T., Tang, A., Guo, J., Chen, Z., Bian, J.: Compositional 3d-aware video generation with llm director (2024) 4 18 S. F. Bhat et al. Supplementary Material A User Study T able A1:Overall completed-session pairwise preference matrix. Each cell reports the percentage of votes preferring the row method over the column method (64 votes per method p...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.