Beyond Compression: Quantifying Spectral Accessibility in Vision Representations
Pith reviewed 2026-06-28 10:41 UTC · model grok-4.3
The pith
Vision representations make frequency information most linearly recoverable at intermediate layers rather than at the output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
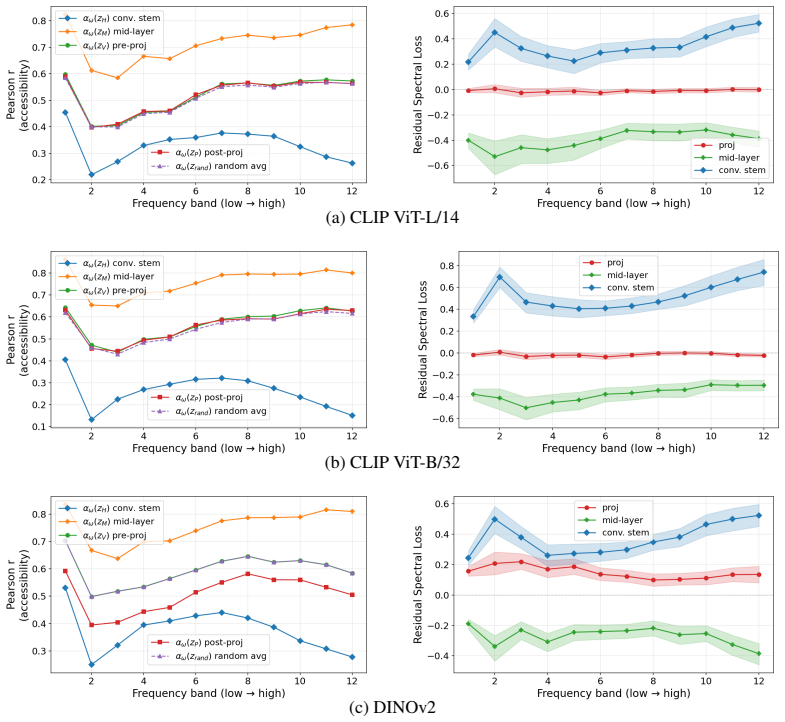
Spectral accessibility follows a non-monotonic trajectory across depth, peaking at intermediate layers before decreasing toward the output representation. The final transformation differs across architectures: CLIP's learned projection is spectrally neutral, with changes explained by compression, whereas DINOv2's [CLS] pooling induces a structured loss across the spectrum.
What carries the argument
Residual Spectral Loss (RSL), which quantifies changes in the linear recoverability of band-limited Fourier energy from representation vectors relative to a dimension-matched random projection baseline.
If this is right
- Intermediate layers retain more recoverable frequency content than the final output and may therefore suit tasks that need high-frequency detail.
- Pooling operations such as [CLS] token aggregation produce frequency-dependent losses that are not explained by compression alone.
- Learned projections in models like CLIP mainly reduce dimension without imposing additional structured spectral bias.
- Primary drivers of spectral change in modern vision encoders are layer depth and the final pooling or projection step.
Where Pith is reading between the lines
- Feature extraction for frequency-sensitive downstream tasks could be improved by selecting activations from the peak-accessibility layer instead of the final embedding.
- New pooling or projection designs could be evaluated by whether they avoid the structured spectral losses observed with class-token aggregation.
Load-bearing premise
Linear recoverability of band-limited Fourier energy from the representation vectors measures spectral accessibility without being confounded by dataset statistics or the choice of frequency bands.
What would settle it
If the same models on the same images show monotonic decline or flat recoverability when the frequency bands or the linear probe are altered, the reported non-monotonic pattern would not hold.
Figures

read the original abstract
Vision-language models map visual features into a shared embedding space through learned projection layers, yet it remains unclear how these transformations alter the structure of visual information. This study examines changes in representation through spatial-frequency accessibility, measured by the linear recoverability of band-limited Fourier energy from model representations. To isolate effects beyond dimensionality reduction, we introduce Residual Spectral Loss (RSL), which evaluates changes relative to a dimension-matched random projection baseline. To reduce confounding effects from optimization, the analysis uses pretrained models with all parameters frozen. The experimental results show consistent frequency-dependent changes in accessibility across CLIP and DINOv2 on ImageNet and MS-COCO datasets. Spectral accessibility follows a non-monotonic trajectory across depth, peaking at intermediate layers before decreasing toward the output representation. The final transformation differs across architectures: CLIP's learned projection is spectrally neutral, with changes explained by compression, whereas DINOv2's [CLS] pooling induces a structured loss across the spectrum. These findings identify intermediate layers and pooling mechanisms as primary drivers of spectral transformation in modern vision encoders.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Residual Spectral Loss (RSL) to quantify changes in spectral accessibility of visual information in frozen pretrained vision encoders (CLIP, DINOv2) beyond dimensionality reduction. Accessibility is operationalized as the linear recoverability (R²) of band-limited Fourier energy from representation vectors, evaluated relative to a dimension-matched random-projection baseline on ImageNet and MS-COCO. Results indicate a non-monotonic depth trajectory (peaking at intermediate layers) and architecture-specific final-layer effects: CLIP's projection is spectrally neutral (changes attributable to compression), while DINOv2's [CLS] pooling produces structured spectral loss.
Significance. If the RSL measure proves unconfounded, the work supplies a concrete, reproducible diagnostic for how pooling and projection stages reshape spatial-frequency content in modern vision backbones. The frozen-model protocol and explicit random-projection control are strengths that allow isolation of architectural effects; the non-monotonic depth finding, if robust, would directly inform layer selection for tasks sensitive to high-frequency detail.
major comments (2)
- [Methods (RSL definition and experimental setup)] The central claim that RSL isolates intrinsic spectral transformations (rather than dataset-specific correlations) rests on the assumption that linear probe performance for band-limited energy is independent of the empirical power spectrum of the probe images and the chosen frequency-band partitioning. No ablation is described that varies band definitions or substitutes a dataset with different frequency statistics while holding the representations fixed; without such a control the reported non-monotonic trajectories and CLIP-vs-DINOv2 distinction could be artifacts of the ImageNet/MS-COCO statistics.
- [§4 (baseline construction)] The random-projection baseline is presented as parameter-free and architecture-independent, yet the paper does not report whether the baseline R² itself varies systematically with the depth or pooling operation under study. If the baseline already encodes depth-dependent spectral bias (e.g., via the statistics of the frozen feature maps), then the residual RSL values may not cleanly separate compression from structured loss.
minor comments (2)
- Notation for the frequency bands and the exact linear-probe formulation (ridge parameter, train/test split) should be stated explicitly rather than left to supplementary material.
- Figure captions should include the precise number of frequency bands, the dimensionality of each representation, and error-bar definition (e.g., std over seeds or images).
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting potential confounds in the RSL definition and baseline. We respond point-by-point below and commit to revisions that directly address the concerns while preserving the core contributions.
read point-by-point responses
-
Referee: [Methods (RSL definition and experimental setup)] The central claim that RSL isolates intrinsic spectral transformations (rather than dataset-specific correlations) rests on the assumption that linear probe performance for band-limited energy is independent of the empirical power spectrum of the probe images and the chosen frequency-band partitioning. No ablation is described that varies band definitions or substitutes a dataset with different frequency statistics while holding the representations fixed; without such a control the reported non-monotonic trajectories and CLIP-vs-DINOv2 distinction could be artifacts of the ImageNet/MS-COCO statistics.
Authors: We acknowledge the value of explicit controls for band partitioning and dataset frequency statistics. The current experiments already evaluate the same frozen representations on two datasets with materially different frequency content (object-centric natural images in ImageNet versus more varied scene content in MS-COCO), and the non-monotonic depth trajectories are qualitatively consistent across both. Nevertheless, we did not vary the frequency-band definitions themselves. In the revision we will add an ablation that re-partitions the spectrum using different numbers of bands and cutoff frequencies while holding all representations fixed, and we will report whether the reported trajectories and architecture distinctions remain stable. This addition will directly test the independence assumption. revision: yes
-
Referee: [§4 (baseline construction)] The random-projection baseline is presented as parameter-free and architecture-independent, yet the paper does not report whether the baseline R² itself varies systematically with the depth or pooling operation under study. If the baseline already encodes depth-dependent spectral bias (e.g., via the statistics of the frozen feature maps), then the residual RSL values may not cleanly separate compression from structured loss.
Authors: The random-projection baseline is formed by applying a single random linear matrix directly to the preprocessed input image pixels to produce a vector whose dimension exactly matches the target layer output; the matrix is drawn once per dimension and is never applied to any intermediate feature map. Consequently the baseline R² depends only on input statistics and target dimension, not on depth, pooling, or any frozen-model representation. Because the construction is deliberately input-based, it cannot inherit depth-dependent spectral biases from the encoder. We will revise §4 to state this construction explicitly, add a supplementary figure showing baseline R² as a function of dimension only, and confirm that residual RSL therefore isolates structured loss beyond compression. revision: yes
Circularity Check
No circularity; derivation uses independent random-projection baseline on frozen models
full rationale
The paper defines RSL as linear recoverability of band-limited Fourier energy relative to a dimension-matched random projection baseline, then applies the measure to frozen pretrained CLIP and DINOv2 models. No equation or claim reduces the reported non-monotonic depth trajectory or final-layer differences to a fitted constant or self-citation by construction. The baseline is parameter-independent and external to the models under test, so the central empirical observations remain non-tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Band-limited Fourier energy can be linearly recovered from representation vectors to quantify accessibility
invented entities (1)
-
Residual Spectral Loss (RSL)
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Understanding intermediate layers using linear classifier probes
URLhttps://arxiv.org/abs/1610.01644. Anonymous Authors. Anonymous repository for “beyond compression: Quantifying spec- tral accessibility in vision representations”. https://anonymous.4open.science/r/vlm_ insight-8106/,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Vision Transformers Need Registers
URL https://arxiv.org/abs/2309.16588. Sanjoy Dasgupta and Anupam Gupta. An elementary proof of a theorem of Johnson and Lindenstrauss. Random Structures & Algorithms, 22(1):60–65,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URLhttps://ieeexplore.ieee.org/document/5206848. Alexey Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR,
-
[6]
arXiv preprint arXiv:1811.12231 , year=
URL https://arxiv.org/abs/1811.12231. Fredric J. Harris. On the use of windows for harmonic analysis with the discrete fourier trans- form.Proceedings of the IEEE, 66(1):51–83,
- [7]
-
[8]
Microsoft COCO: Common Objects in Context
URLhttps://arxiv.org/abs/1405.0312. Muzammal Naseer, Kanchana Ranasinghe, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Intriguing properties of vision transformers. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URLhttps://arxiv.org/abs/2105.10497. Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nico- las Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu,...
-
[10]
URLhttps://arxiv.org/pdf/2304.07193. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine L...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Learning Transferable Visual Models From Natural Language Supervision
URL https://arxiv. org/pdf/2103.00020. Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks?arXiv preprint arXiv:2108.08810,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
10 Katja Schwarz, Yiyi Liao, and Andreas Geiger
URLhttps://arxiv.org/abs/2108.08810. 10 Katja Schwarz, Yiyi Liao, and Andreas Geiger. On the frequency bias of generative models. InAd- vances in Neural Information Processing Systems,
-
[13]
cc/paper_files/paper/2021/file/96bf57c6ff19504ff145e2a32991ea96-Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/96bf57c6ff19504ff145e2a32991ea96-Paper.pdf. Antonio Torralba and Aude Oliva. Statistics of natural image categories.Network: Computation in Neural Systems, 14(3):391–412,
2021
-
[14]
Peihao Wang, Wenqing Zheng, Tianlong Chen, and Zhangyang Wang
URLhttps://arxiv.org/abs/1905.13545. Peihao Wang, Wenqing Zheng, Tianlong Chen, and Zhangyang Wang. Anti-oversmoothing in deep vision transformers via the fourier domain analysis: From theory to practice. InInternational Conference on Learning Representations,
-
[15]
URLhttps://arxiv.org/abs/2203.05962. Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Ru...
-
[16]
Dong Yin, Raphael Gontijo Lopes, Jonathon Shlens, Ekin D
URL https://proceedings.neurips.cc/paper/2021/hash/ ff1418e8cc993fe8abcfe3ce2003e5c5-Abstract.html. Dong Yin, Raphael Gontijo Lopes, Jonathon Shlens, Ekin D. Cubuk, and Justin Gilmer. A fourier perspective on model robustness in computer vision. InAdvances in Neu- ral Information Processing Systems,
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.