Residual Modeling for High-Fidelity Learned Compression of Scientific Data
Pith reviewed 2026-06-28 05:52 UTC · model grok-4.3
The pith
Tailored residual coders preserve learned compression advantage when correction dominates at high fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
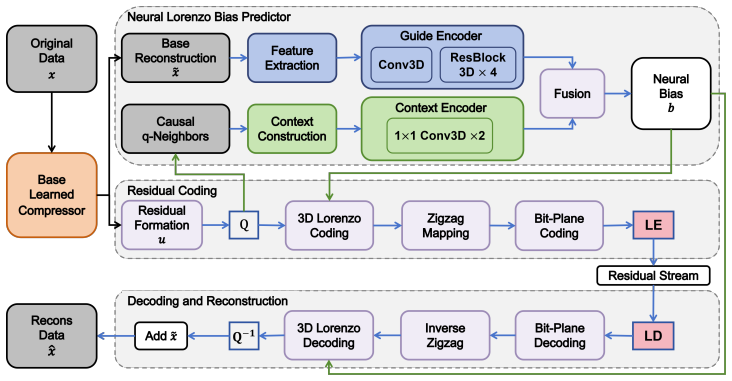
When global residual correction becomes rate-dominant in high-fidelity learned compression, residual representations tailored to learned-compressor residuals can preserve the advantage of learned compression. LBRC is a deterministic, training-free pipeline that adaptively quantizes the learned residual to the target NRMSE and losslessly encodes the resulting integer residual using 3D Lorenzo differencing, zigzag mapping, bit-plane coding, and entropy coding. NGLR adds a causal neural predictor that outputs a normalized bias for an integer-rounded Lorenzo prediction in the same deterministic integer pipeline, reducing the entropy of the remaining residual code while preserving deterministic d
What carries the argument
LBRC and NGLR residual coders that adaptively quantize and losslessly encode learned residuals via 3D Lorenzo differencing plus optional causal neural bias prediction.
If this is right
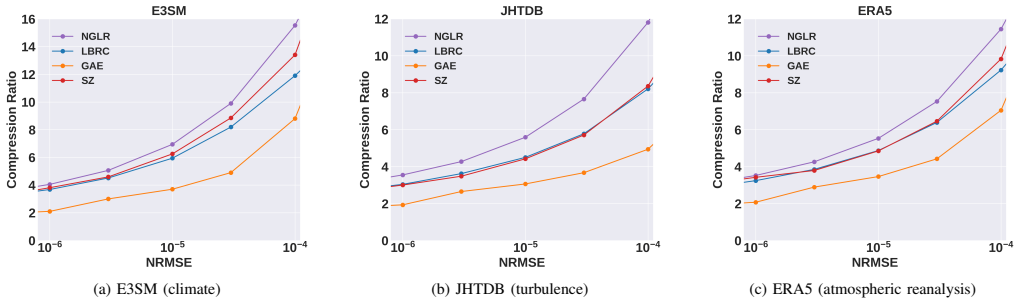
- Compression ratios improve 30-60% over GAE at block-level NRMSE targets from 10^-6 to 10^-4.
- NGLR adds a further 10-40% improvement over LBRC while remaining deterministic.
- The methods become competitive with or superior to SZ across the evaluated high-fidelity regime.
- The rate advantage of learned compressors is retained even when per-block residual correction dominates the bitstream.
Where Pith is reading between the lines
- The same residual modeling strategy could be ported to learned compressors other than GAE.
- Jointly optimizing the main compressor and the NGLR predictor might produce additional rate savings.
- The deterministic integer pipelines support reproducible scientific workflows that require exact decoding.
- The structural-difference premise could be tested directly by comparing residual statistics before and after the learned stage.
Load-bearing premise
The learned residual is structurally different from the original scientific field and therefore benefits from specialized coding pipelines such as 3D Lorenzo differencing or causal neural bias prediction.
What would settle it
If applying LBRC or NGLR to the residuals produced by GAE on the E3SM, JHTDB, and ERA5 datasets at NRMSE targets 10^-6 to 10^-4 yields no ratio improvement or underperforms standard residual correction, the claim that tailoring to learned residuals is essential would be falsified.
Figures

read the original abstract
Lossy compression is essential for massive spatiotemporal data from scientific simulations. Learned compressors can achieve high compression ratios at moderate accuracy targets, but their aggregate reconstruction losses do not guarantee accuracy for each block. Existing Guaranteed Autoencoder (GAE) methods add a per-block residual correction by retaining SVD/PCA-style coefficients until the target is met. This works at moderate tolerances, but in the high-fidelity regime with block-level NRMSE from 10^-6 to 10^-4, the number of retained coefficients grows quickly and the correction stream dominates the total rate. We propose a residual-centric view: the learned residual is structurally different from the original scientific field and should be coded with a representation designed for that residual. We introduce two residual coders. LBRC is a deterministic, training-free pipeline that adaptively quantizes the learned residual to the target NRMSE and losslessly encodes the resulting integer residual using 3D Lorenzo differencing, zigzag mapping, bit-plane coding, and entropy coding. NGLR adds a causal neural predictor that outputs a normalized bias for an integer-rounded Lorenzo prediction in the same deterministic integer pipeline, reducing the entropy of the remaining residual code while preserving deterministic decoding. The predictor weights are serialized and counted in the bitstream. Across E3SM, JHTDB, and ERA5 at block-level NRMSE targets from 10^-6 to 10^-4, LBRC improves compression ratio over GAE by 30-60% and is broadly competitive with SZ. NGLR adds a further 10-40% over LBRC and outperforms SZ in the evaluated high-fidelity regime. These results show that residual representations tailored to learned-compressor residuals can preserve the advantage of learned compression when global residual correction becomes rate-dominant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a residual-centric approach to high-fidelity learned compression of scientific spatiotemporal data. It argues that when per-block residual correction dominates the rate at tight NRMSE targets (10^{-6} to 10^{-4}), standard SVD/PCA-style correction in Guaranteed Autoencoders (GAE) becomes inefficient; instead, the learned residual should be coded with pipelines (LBRC: adaptive quantization + 3D Lorenzo differencing, zigzag, bit-plane, entropy coding; NGLR: causal neural bias predictor on top of the same integer pipeline) that exploit its structure. Experiments on E3SM, JHTDB, and ERA5 report 30-60% ratio gains for LBRC over GAE and a further 10-40% for NGLR, making it competitive with or better than SZ while preserving deterministic decoding.
Significance. If the central claim holds, the work demonstrates that learned compressors can retain their advantage in the high-fidelity regime by shifting from generic residual correction to residual-specific lossless coding; the deterministic, training-free character of LBRC and the explicit serialization of NGLR weights are concrete strengths that support reproducibility. The results are empirical rather than axiomatic, but the multi-dataset evaluation at stated NRMSE targets provides a falsifiable basis for the residual-modeling thesis.
major comments (2)
- [Abstract / Results] Abstract and results sections: the claim that 'the learned residual is structurally different from the original scientific field' and therefore benefits from LBRC/NGLR is load-bearing for the central thesis, yet the manuscript reports no control experiment that applies the identical LBRC (or NGLR) pipeline directly to the raw fields at the same per-block NRMSE targets; without this ablation the 30-60% gains over GAE could arise from the quantization-to-NRMSE step or from the integer pipeline being generally effective rather than from any property unique to autoencoder residuals.
- [Results] Results section (dataset and baseline descriptions): full configuration details for the GAE SVD/PCA correction (number of retained coefficients per block, exact NRMSE enforcement procedure) and for SZ are not provided, nor are error bars or per-dataset variance on the reported compression ratios; this weakens verification of the 'broadly competitive with SZ' and 'outperforms SZ' statements at the high-fidelity end.
minor comments (2)
- [Abstract] Notation: the abstract introduces LBRC and NGLR without an explicit forward reference to the section that defines the integer pipeline and the causal predictor; a short methods overview paragraph would improve readability.
- [Methods (NGLR)] The paper states that predictor weights are serialized and counted in the bitstream, but does not specify the exact quantization or encoding format used for those weights; this detail belongs in the NGLR description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, indicating planned revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results sections: the claim that 'the learned residual is structurally different from the original scientific field' and therefore benefits from LBRC/NGLR is load-bearing for the central thesis, yet the manuscript reports no control experiment that applies the identical LBRC (or NGLR) pipeline directly to the raw fields at the same per-block NRMSE targets; without this ablation the 30-60% gains over GAE could arise from the quantization-to-NRMSE step or from the integer pipeline being generally effective rather than from any property unique to autoencoder residuals.
Authors: The core experimental comparison is between GAE (which applies SVD/PCA correction to the identical learned residuals) and LBRC/NGLR (which applies the proposed pipelines to those same residuals). The reported 30-60% gains therefore isolate the effect of the residual coder itself rather than the quantization step or the integer pipeline in isolation. The structural difference claim is supported by the observation that autoencoder residuals exhibit lower dynamic range and altered spatial correlations compared with the original fields, which the Lorenzo-based and neural-bias pipelines are designed to exploit. A control applying LBRC directly to raw fields would evaluate a different (non-learned) compressor and is not required to substantiate the advantage of residual-specific coding within the learned-compression pipeline. We will nevertheless revise the manuscript to make this distinction explicit and to add a short discussion of the residual statistics that motivate the design choices. revision: partial
-
Referee: [Results] Results section (dataset and baseline descriptions): full configuration details for the GAE SVD/PCA correction (number of retained coefficients per block, exact NRMSE enforcement procedure) and for SZ are not provided, nor are error bars or per-dataset variance on the reported compression ratios; this weakens verification of the 'broadly competitive with SZ' and 'outperforms SZ' statements at the high-fidelity end.
Authors: We agree that these details are necessary for full reproducibility. In the revised version we will add the precise GAE configuration (number of retained SVD coefficients per block and the exact per-block NRMSE enforcement algorithm) together with the SZ parameter settings used in the comparisons. Because the methods are deterministic and the reported figures are obtained from single runs on fixed data partitions, per-run variance is not available; we will instead tabulate the per-dataset compression ratios explicitly and note the deterministic character of LBRC and NGLR. revision: yes
Circularity Check
No significant circularity; empirical methods with explicit pipelines
full rationale
The paper advances two deterministic, training-free residual coders (LBRC using 3D Lorenzo + zigzag/bit-plane, NGLR adding causal neural bias) and reports empirical compression ratios on E3SM/JHTDB/ERA5 at NRMSE 1e-6 to 1e-4. No equations, uniqueness theorems, or predictions are shown that reduce by construction to fitted parameters or self-citations. The structural-difference premise is stated as a modeling choice whose validity is tested via direct rate comparisons rather than derived from prior author work. All load-bearing claims rest on reproducible integer pipelines and external baselines (GAE, SZ), satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The learned residual is structurally different from the original scientific field
Reference graph
Works this paper leans on
-
[1]
Use Cases of Lossy Compression for Floating-Point Data in Scientific Data Sets,
F. Cappello, S. Di, S. Li, X. Liang, A. M. Gok, D. Tao, C. H. Yoon, X.-C. Wu, Y . Alexeev, and F. T. Chong, “Use Cases of Lossy Compression for Floating-Point Data in Scientific Data Sets,”The International Journal of High Performance Computing Applications, vol. 33, no. 6, pp. 1201– 1220, 2019
2019
-
[2]
Error-controlled lossy compression optimized for high compression ratios of scientific datasets,
X. Liang, S. Di, D. Tao, S. Li, S. Li, H. Guo, Z. Chen, and F. Cappello, “Error-controlled lossy compression optimized for high compression ratios of scientific datasets,” inProc. IEEE Int. Conf. Big Data, 2018, pp. 438–447
2018
-
[3]
SZ3: A modular framework for composing prediction-based error-bounded lossy compressors,
X. Liang, K. Zhao, S. Di, S. Li, R. Underwood, A. M. Gok, J. Tian, J. Deng, J. C. Calhoun, D. Tao, Z. Chen, and F. Cappello, “SZ3: A modular framework for composing prediction-based error-bounded lossy compressors,”IEEE Trans. Big Data, vol. 9, no. 2, pp. 485–498, 2023
2023
-
[4]
Fixed-rate compressed floating-point arrays,
P. Lindstrom, “Fixed-rate compressed floating-point arrays,”IEEE Trans. Vis. Comput. Graphics, vol. 20, no. 12, pp. 2674–2683, 2014
2014
-
[5]
Stability analysis of inline ZFP compression for floating-point data in iterative methods,
A. Fox, J. Diffenderfer, J. Hittinger, G. Sanders, and P. Lindstrom, “Stability analysis of inline ZFP compression for floating-point data in iterative methods,”SIAM J. Sci. Comput., vol. 42, no. 5, pp. A2701– A2730, 2020
2020
-
[6]
Multilevel techniques for compression and reduction of scientific data—The mul- tivariate case,
M. Ainsworth, O. Tugluk, B. Whitney, and S. Klasky, “Multilevel techniques for compression and reduction of scientific data—The mul- tivariate case,”SIAM J. Sci. Comput., vol. 41, no. 2, pp. A1278–A1303, 2019
2019
-
[7]
MGARD: A multigrid framework for high-performance, error-controlled data compression and refactoring,
Q. Gong, J. Chen, B. Whitney, X. Liang, V . Reshniak, T. Banerjee, J. Lee, A. Rangarajan, L. Wan, N. Vidal et al., “MGARD: A multigrid framework for high-performance, error-controlled data compression and refactoring,”SoftwareX, vol. 24, p. 101590, 2023
2023
-
[8]
FAZ: A flexible auto-tuned modular error-bounded compression framework for scientific data,
J. Liu, S. Di, K. Zhao, X. Liang, Z. Chen, and F. Cappello, “FAZ: A flexible auto-tuned modular error-bounded compression framework for scientific data,” inProc. Int. Conf. Supercomputing, 2023, pp. 1–13
2023
-
[9]
Out-of-core compression and decompression of largen-dimensional scalar fields,
L. Ibarria, P. Lindstrom, J. Rossignac, and A. Szymczak, “Out-of-core compression and decompression of largen-dimensional scalar fields,” Computer Graphics Forum, vol. 22, no. 3, pp. 343–348, 2003
2003
-
[10]
High-ratio lossy compression: Exploring the autoencoder to compress scientific data,
T. Liu, J. Wang, Q. Liu, S. Alibhai, T. Lu, and X. He, “High-ratio lossy compression: Exploring the autoencoder to compress scientific data,” IEEE Transactions on Big Data, vol. 9, no. 1, pp. 22–36, 2021
2021
-
[11]
Using neural networks for two- dimensional scientific data compression,
L. Hayne, J. Clyne, and S. Li, “Using neural networks for two- dimensional scientific data compression,” inProc. IEEE Int. Conf. Big Data, 2021, pp. 2956–2965
2021
-
[12]
Exploring autoencoder-based error-bounded compression for scientific data,
J. Liu, S. Di, K. Zhao, S. Jin, D. Tao, X. Liang, Z. Chen, and F. Cappello, “Exploring autoencoder-based error-bounded compression for scientific data,” inProc. IEEE Int. Conf. Cluster Comput., 2021, pp. 294–306
2021
-
[13]
Error-bounded learned scientific data compression with preservation of derived quantities,
J. Lee, Q. Gong, J. Choi, T. Banerjee, S. Klasky, S. Ranka, and A. Rangarajan, “Error-bounded learned scientific data compression with preservation of derived quantities,”Appl. Sci., vol. 12, no. 13, p. 6718, 2022
2022
-
[14]
Nonlinear-by-linear: Guaranteeing error bounds in compressive autoencoders,
J. Lee, A. Rangarajan, and S. Ranka, “Nonlinear-by-linear: Guaranteeing error bounds in compressive autoencoders,” inProc. 15th Int. Conf. Contemporary Computing (IC3), 2023, pp. 552–561
2023
-
[15]
Joint autoregressive and hierarchical priors for learned image compression,
D. Minnen, J. Ball ´e, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” inAdv. Neural Inf. Process. Syst., vol. 31, 2018
2018
-
[16]
Conditional image generation with PixelCNN decoders,
A. van den Oord, N. Kalchbrenner, L. Espeholt, O. Vinyals, A. Graves, et al., “Conditional image generation with PixelCNN decoders,”Advances in Neural Information Processing Systems, vol. 29, 2016
2016
-
[17]
Variational image compression with a scale hyperprior,
J. Ball ´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” inInt. Conf. Learn. Representations, 2018
2018
-
[18]
Foundation model for lossy compression of spatiotemporal scientific data,
X. Li, J. Lee, A. Rangarajan, and S. Ranka, “Foundation model for lossy compression of spatiotemporal scientific data,” inProc. Pacific-Asia Conf. Knowl. Discovery and Data Mining (PAKDD), 2025, pp. 368– 380
2025
-
[19]
Generative latent diffusion for efficient spatiotemporal data reduction,
X. Li, L. Zhu, A. Rangarajan, and S. Ranka, “Generative latent diffusion for efficient spatiotemporal data reduction,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2025, pp. 1980–1991
2025
-
[20]
CAESAR: A unified framework for foundation and generative models for efficient compression of scientific data,
X. Li, L. Zhu, J. Lee, R. Sengupta, S. Klasky, S. Ranka, and A. Ran- garajan, “CAESAR: A unified framework for foundation and generative models for efficient compression of scientific data,”Applied Sciences, vol. 15, no. 16, p. 8977, 2025
2025
-
[21]
Attention based machine learning methods for data reduction with guaranteed error bounds,
X. Li, J. Lee, A. Rangarajan, and S. Ranka, “Attention based machine learning methods for data reduction with guaranteed error bounds,” in Proc. IEEE Int. Conf. Big Data, 2024, pp. 1039–1048
2024
-
[22]
The DOE E3SM coupled model version 1: Overview and evaluation at standard resolution,
J.-C. Golaz, P. M. Caldwell, L. P. Van Roekel et al., “The DOE E3SM coupled model version 1: Overview and evaluation at standard resolution,”J. Adv. Model. Earth Syst., vol. 11, no. 7, pp. 2089–2129, 2019
2089
-
[23]
The ERA5 global reanalysis,
H. Hersbach, B. Bell, P. Berrisford et al., “The ERA5 global reanalysis,” Quarterly Journal of the Royal Meteorological Society, vol. 146, no. 730, pp. 1999–2049, 2020
1999
-
[24]
A public turbulence database cluster and applications to study Lagrangian evolution of velocity increments in turbulence,
Y . Li, E. Perlman, M. Wan, Y . Yang, C. Meneveau, R. Burns, S. Chen, A. Szalay, and G. Eyink, “A public turbulence database cluster and applications to study Lagrangian evolution of velocity increments in turbulence,”J. Turbulence, vol. 9, p. N31, 2008
2008
-
[25]
Direct numerical simulations of ignition of a leann-heptane/air mixture with temperature inhomogeneities at constant volume: Parametric study,
C. S. Yoo, T. Lu, J. H. Chen, and C. K. Law, “Direct numerical simulations of ignition of a leann-heptane/air mixture with temperature inhomogeneities at constant volume: Parametric study,”Combustion and Flame, vol. 158, no. 9, pp. 1727–1741, 2011
2011
-
[26]
LPCNet: Improving neural speech synthe- sis through linear prediction,
J.-M. Valin and J. Skoglund, “LPCNet: Improving neural speech synthe- sis through linear prediction,” inProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 5891– 5895, doi: 10.1109/ICASSP.2019.8682804
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.