Score Broadcast and Decorrelation: A General Framework for Broadcast-Based Credit Assignment
Pith reviewed 2026-06-29 08:25 UTC · model grok-4.3
The pith
An orthogonality principle between output scores and hidden activations unifies broadcast-based credit assignment for general differentiable losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the orthogonality between the output score (the gradient of the loss with respect to the final-layer output) and hidden-layer activations, which follows from the optimal score having conditional mean zero, supplies the theoretical grounding for broadcast-based credit assignment across standard differentiable-loss families. The framework derives the cross-entropy case explicitly, characterizes the admissible loss class, and introduces score vector expansion to enrich the broadcast signal while preserving the orthogonality framework.
What carries the argument
The orthogonality principle between the output score and hidden-layer activations.
If this is right
- The same orthogonality unifies broadcast credit assignment for cross-entropy, Bregman divergences, proper scoring rules, and exponential-family negative log-likelihoods.
- It grounds the three-factor learning rule with the neuromodulatory factor derived as the broadcast loss score.
- Score vector expansion enriches the broadcast signal while preserving the orthogonality framework.
- The resulting method substantially improves performance over existing broadcast approaches on CIFAR-10 and Tiny ImageNet.
Where Pith is reading between the lines
- The framework could apply directly to other differentiable losses that satisfy the conditional mean zero property even if they are not listed.
- The same orthogonality check might serve as a diagnostic for whether a given loss family admits broadcast credit assignment.
- Score vector expansion could be combined with other decorrelation objectives outside the broadcast setting.
- Empirical verification of the conditional mean zero property on trained networks would test a key step in the derivation.
Load-bearing premise
The optimal score has conditional mean zero given the input.
What would settle it
An observation that the optimal score lacks conditional mean zero for a loss in the claimed class, or that the broadcast rule derived from the orthogonality fails to produce the expected decorrelation on a cross-entropy task.
Figures

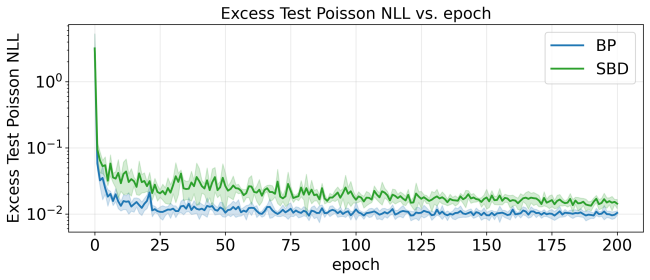
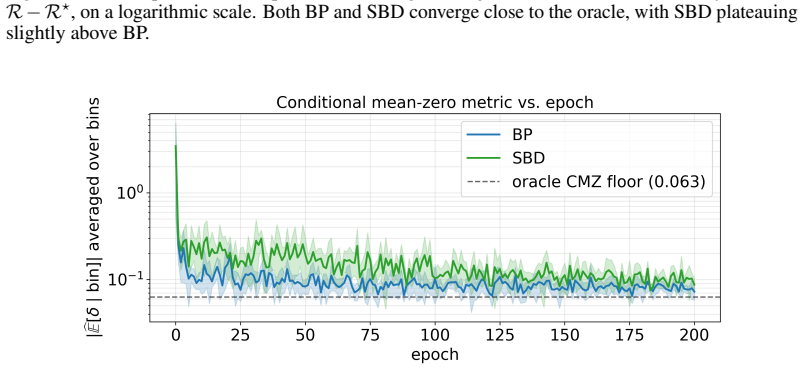
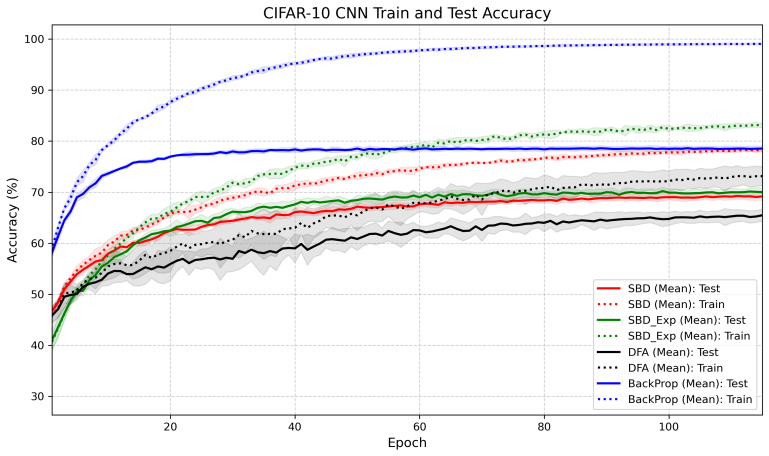
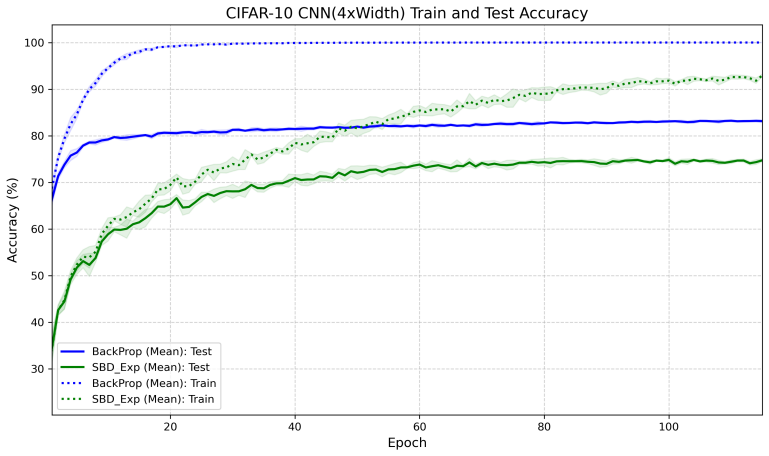
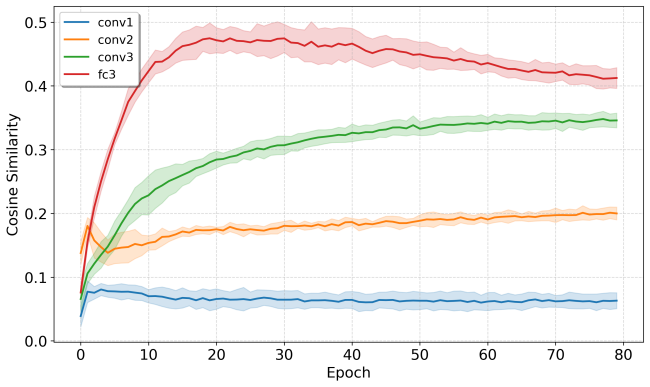
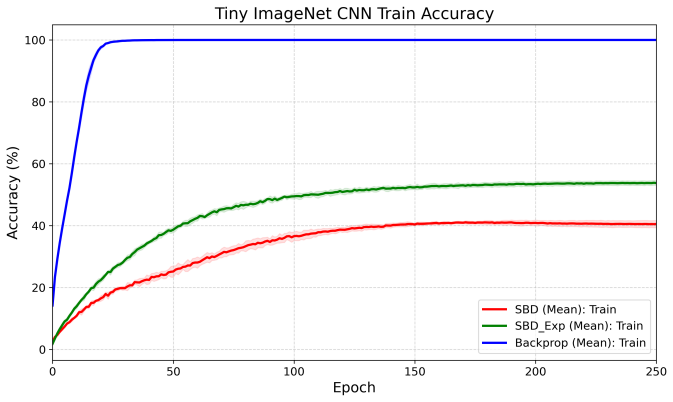


read the original abstract
We introduce Score Broadcast and Decorrelation (SBD), a principled framework for broadcast-based credit assignment for general families of differentiable losses. Error broadcast is a biologically plausible alternative to backpropagation that sends output information to hidden layers without weight transport. The Error Broadcast and Decorrelation (EBD) framework, recently introduced for the mean-squared-error (MSE) setting, grounded this mechanism in the stochastic orthogonality of optimal estimators, under which the optimal residual is orthogonal to functions of the input. We generalize that foundation by introducing an orthogonality principle between the output score (the gradient of loss with respect to the final-layer output) and hidden-layer activations, which holds whenever the optimal score has conditional mean zero. This single principle unifies broadcast-based credit assignment across the standard differentiable-loss families, including cross-entropy, Bregman divergences, proper scoring rules, and exponential-family negative log-likelihoods. The framework supplies a theoretical grounding for the three-factor learning rule under general losses, with the neuromodulatory factor derived as the broadcast loss score. We derive the cross-entropy case explicitly, characterize the admissible loss class, and introduce a score vector expansion technique that enriches the broadcast signal while preserving the orthogonality framework. Experiments on CIFAR-10 and Tiny ImageNet show that SBD substantially improves over existing broadcast approaches, with score vector expansion delivering further gains. Overall, this work identifies the loss score as the signal to broadcast, supplies the orthogonality theory and theoretical grounding for the three-factor learning rule from neuroscience, and shows how score vector expansion enriches the decorrelation directions of the resulting objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Score Broadcast and Decorrelation (SBD) as a generalization of the Error Broadcast and Decorrelation (EBD) framework from the MSE setting to arbitrary differentiable losses. It posits a single orthogonality principle between the output score (gradient of the loss w.r.t. the final output) and hidden-layer activations, which is claimed to hold whenever the optimal score has conditional mean zero given the input. This principle is asserted to unify broadcast-based credit assignment across cross-entropy, Bregman divergences, proper scoring rules, and exponential-family negative log-likelihoods; the paper derives the cross-entropy case explicitly, characterizes the admissible loss class, introduces a score-vector expansion technique that preserves orthogonality, supplies a theoretical grounding for the three-factor learning rule, and reports that SBD with score-vector expansion yields substantial gains on CIFAR-10 and Tiny ImageNet.
Significance. If the orthogonality derivation and unification hold without additional assumptions, the work supplies a principled, loss-agnostic foundation for biologically plausible credit assignment that extends beyond MSE-specific results. The explicit identification of the loss score as the broadcast signal and the score-vector expansion method would constitute a concrete advance for both theoretical understanding of three-factor rules and practical algorithm design in settings that forbid weight transport.
minor comments (2)
- The abstract asserts that experiments demonstrate substantial improvement and further gains from score-vector expansion, yet supplies neither quantitative deltas, baseline comparisons, nor statistical details; the results section should include these to allow readers to assess the magnitude and reliability of the reported gains.
- The admissible loss class is characterized in the manuscript; a brief explicit statement of the necessary and sufficient conditions (e.g., in terms of the conditional-mean-zero property) would improve clarity for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance of the orthogonality principle, and recommendation of minor revision. No specific major comments were provided in the report, so we have no individual points to rebut. We will address any minor editorial or clarification suggestions in the revised version.
Circularity Check
No significant circularity in derivation chain
full rationale
The central orthogonality principle follows from the law of total expectation once E[score|x]=0 is granted at optimality; this is a standard property of optimal estimators for cross-entropy, Bregman divergences, proper scoring rules, and exponential-family NLL, and is not obtained by fitting inside the paper or by self-citation. The unification across loss families and the three-factor rule grounding are direct consequences of this external statistical fact rather than any reduction to the paper's own inputs. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided derivation outline.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The optimal score has conditional mean zero given the input.
Reference graph
Works this paper leans on
-
[1]
Rumelhart, Geoffrey E
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning representations by back-propagating errors. Nature, 323:533--536, 1986
1986
-
[2]
The recent excitement about neural networks
Francis Crick. The recent excitement about neural networks. Nature, 337:129--132, 1989
1989
-
[3]
Lillicrap, Adam Santoro, Luke Marris, Colin J
Timothy P. Lillicrap, Adam Santoro, Luke Marris, Colin J. Akerman, and Geoffrey Hinton. Backpropagation and the brain. Nature Reviews Neuroscience, 21(6):335--346, 2020
2020
-
[4]
Humphreys, Timothy Lillicrap, and Douglas Tweed
Mohamed Akrout, Collin Wilson, Peter C. Humphreys, Timothy Lillicrap, and Douglas Tweed. Deep learning without weight transport. In Advances in Neural Information Processing Systems 32 (NeurIPS) , pages 974--982, 2019
2019
-
[5]
James C. R. Whittington and Rafal Bogacz. Theories of error back-propagation in the brain. Trends in Cognitive Sciences, 23(3):235--250, 2019
2019
-
[6]
Golkar, T
S. Golkar, T. Tesileanu, Y. Bahroun, A. Sengupta, and D. Chklovskii. Constrained predictive coding as a biologically plausible model of the cortical hierarchy. Advances in Neural Information Processing Systems 35 (NeurIPS) , pages 14155--14169, 2022
2022
-
[7]
Error Broadcast and Decorrelation as a Potential Artificial and Natural Learning Mechanism
Mete Erdogan, Cengiz Pehlevan, and Alper Tunga Erdogan. Error Broadcast and Decorrelation as a Potential Artificial and Natural Learning Mechanism. In Advances in Neural Information Processing Systems 38 (NeurIPS), 2025
2025
-
[8]
Neuromodulated spike-timing-dependent plasticity, and theory of three-factor learning rules
Nicolas Fr \'e maux and Wulfram Gerstner. Neuromodulated spike-timing-dependent plasticity, and theory of three-factor learning rules. Frontiers in Neural Circuits , 9:85, 2016
2016
-
[9]
Eligibility traces and plasticity on behavioral time scales: experimental support of neo- H ebbian three-factor learning rules
Wulfram Gerstner, Marco Lehmann, Vasiliki Liakoni, Dane Corneil, and Johanni Brea. Eligibility traces and plasticity on behavioral time scales: experimental support of neo- H ebbian three-factor learning rules. Frontiers in Neural Circuits , 12:53, 2018
2018
-
[10]
Learning with three factors: modulating H ebbian plasticity with errors
ukasz Ku \'s mierz, Takuya Isomura, and Taro Toyoizumi. Learning with three factors: modulating H ebbian plasticity with errors. Current Opinion in Neurobiology , 46:170--177, 2017
2017
-
[11]
Predictive reward signal of dopamine neurons
Wolfram Schultz. Predictive reward signal of dopamine neurons. Journal of Neurophysiology , 80(1):1--27, 1998
1998
-
[12]
Self-Supervised Learning with an Information Maximization Criterion
Serdar Ozsoy, Shadi Hamdan, Sercan Arik, Deniz Yuret, and Alper Erdogan. Self-Supervised Learning with an Information Maximization Criterion. In Advances in Neural Information Processing Systems 35 (NeurIPS), pages 35240--35253, 2022
2022
-
[13]
Bariscan Bozkurt, Cengiz Pehlevan, and Alper T. Erdogan. Correlative Information Maximization: A Biologically Plausible Approach to Supervised Deep Neural Networks without Weight Symmetry. In Advances in Neural Information Processing Systems 36 (NeurIPS), pages 34928--34941, 2023
2023
-
[14]
Bariscan Bozkurt, Ate s \.I sfendiyaro g lu, Cengiz Pehlevan, and Alper T. Erdogan. Correlative Information Maximization Based Biologically Plausible Neural Networks for Correlated Source Separation. In International Conference on Learning Representations (ICLR), 2023
2023
-
[15]
Equilibrium Propagation: Bridging the Gap between Energy-Based Models and Backpropagation
Benjamin Scellier and Yoshua Bengio. Equilibrium Propagation: Bridging the Gap between Energy-Based Models and Backpropagation. Frontiers in Computational Neuroscience, 11:24, 2017
2017
-
[16]
Equivalence of equilibrium propagation and recurrent backpropagation
Benjamin Scellier and Yoshua Bengio. Equivalence of equilibrium propagation and recurrent backpropagation. Neural Computation , 31(2):312--329, 2019
2019
-
[17]
How Auto-Encoders Could Provide Credit Assignment in Deep Networks via Target Propagation
Yoshua Bengio. How Auto-Encoders Could Provide Credit Assignment in Deep Networks via Target Propagation. CoRR, abs/1407.7906, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
Difference Target Propagation
Dong-Hyun Lee, Saizheng Zhang, Asja Fischer, and Yoshua Bengio. Difference Target Propagation. In Machine Learning and Knowledge Discovery in Databases, pages 498--515, 2015
2015
- [19]
-
[20]
Rajesh P. N. Rao and Dana H. Ballard. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nature Neuroscience, 2:79--87, 1999
1999
-
[21]
James C. R. Whittington and Rafal Bogacz. An Approximation of the Error Backpropagation Algorithm in a Predictive Coding Network with Local Hebbian Synaptic Plasticity. Neural Computation, 29(5):1229--1262, 2017
2017
-
[22]
Contrastive Similarity Matching for Supervised Learning
Shanshan Qin, Nayantara Mudur, and Cengiz Pehlevan. Contrastive Similarity Matching for Supervised Learning. Neural Computation, 33(5):1300--1328, 2021
2021
-
[23]
Lillicrap, Daniel Cownden, Douglas B
Timothy P. Lillicrap, Daniel Cownden, Douglas B. Tweed, and Colin J. Akerman. Random synaptic feedback weights support error backpropagation for deep learning. Nature Communications, 7:13276, 2016
2016
-
[24]
Direct Feedback Alignment Provides Learning in Deep Neural Networks
Arild N kland. Direct Feedback Alignment Provides Learning in Deep Neural Networks. In Advances in Neural Information Processing Systems 29 (NeurIPS), pages 1037--1045, 2016
2016
-
[25]
Hinton, and Timothy Lillicrap
Sergey Bartunov, Adam Santoro, Blake Richards, Luke Marris, Geoffrey E. Hinton, and Timothy Lillicrap. Assessing the Scalability of Biologically-Motivated Deep Learning Algorithms and Architectures. In Advances in Neural Information Processing Systems 31 (NeurIPS), 2018
2018
-
[26]
Efficient Convolutional Neural Network Training with Direct Feedback Alignment
Donghyeon Han and Hoi-jun Yoo. Efficient Convolutional Neural Network Training with Direct Feedback Alignment. CoRR, abs/1901.01986, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[27]
Principled Training of Neural Networks with Direct Feedback Alignment
Julien Launay, Iacopo Poli, and Florent Krzakala. Principled Training of Neural Networks with Direct Feedback Alignment. CoRR, abs/1906.04554, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[28]
Direct Feedback Alignment Scales to Modern Deep Learning Tasks and Architectures
Julien Launay, Iacopo Poli, François Boniface, and Florent Krzakala. Direct Feedback Alignment Scales to Modern Deep Learning Tasks and Architectures. In Advances in Neural Information Processing Systems 33 (NeurIPS), 2020
2020
-
[29]
The Influence of Learning Rule on Representation Dynamics in Wide Neural Networks
Blake Bordelon and Cengiz Pehlevan. The Influence of Learning Rule on Representation Dynamics in Wide Neural Networks. In International Conference on Learning Representations (ICLR), 2023
2023
-
[30]
Clark, L
David G. Clark, L. F. Abbott, and SueYeon Chung. Credit Assignment Through Broadcasting a Global Error Vector. In Advances in Neural Information Processing Systems 34 (NeurIPS), 2021
2021
-
[31]
Analysis synthesis telephony based on the maximum likelihood method
Fumitada Itakura and Satoshi Saito. Analysis synthesis telephony based on the maximum likelihood method. In Proceedings of the 6th International Congress on Acoustics, pages C--17--C--20. IEEE, 1968
1968
-
[32]
F\' e votte, N
C. F\' e votte, N. Bertin, and J.-L. Durrieu. Nonnegative matrix factorization with the Itakura-Saito divergence: With application to music analysis. Neural Computation, 21(3):793--830, 2009
2009
-
[33]
L. M. Bregman. The relaxation method of finding the common points of convex sets and its application to the solution of problems in convex programming. USSR Computational Mathematics and Mathematical Physics, 7(3):200--217, 1967
1967
-
[34]
Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association , 102(477):359--378, 2007
2007
-
[35]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An Imperative Style, High-Perfo...
2019
-
[36]
Learning Multiple Layers of Features from Tiny Images
Alex Krizhevsky. Learning Multiple Layers of Features from Tiny Images. Technical Report, University of Toronto, 2009
2009
-
[37]
Tiny ImageNet Visual Recognition Challenge
Ya Le and Xuan Yang. Tiny ImageNet Visual Recognition Challenge. CS 231N course project report, Stanford University, 2015
2015
-
[38]
Friedman
Jerome H. Friedman. Multivariate adaptive regression splines. The Annals of Statistics , 19(1):1--67, 1991
1991
-
[39]
Experiment tracking with Weights and Biases
Lukas Biewald. Experiment tracking with Weights and Biases. Software available from wandb.com, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.