FOGO: Forgetting-aware Orthogonalization Optimizer
Pith reviewed 2026-06-27 14:08 UTC · model grok-4.3
The pith
Dominant mini-batch gradients suppress rare directions during every training step, and FOGO resolves the resulting short-term and long-term forgetting through spectral orthogonalization plus codebook correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Forgetting occurs as a general optimization phenomenon because dominant mini-batch gradients suppress rare update directions at each step; when such knowledge is never revisited these losses compound. FOGO continuously detects and resolves gradient interference by spectrally orthogonalizing momentum updates and storing representative past directions in a random-projection codebook whose pairwise distances are provably preserved, then applies lightweight orthogonal correction and a proximal step to resolve conflicts with minimal overhead.
What carries the argument
Spectral orthogonalization of momentum updates combined with random-projection codebook memory and proximal correction to resolve gradient conflicts.
If this is right
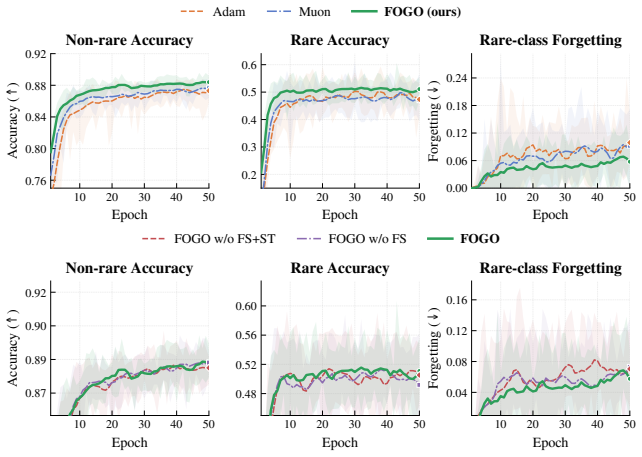
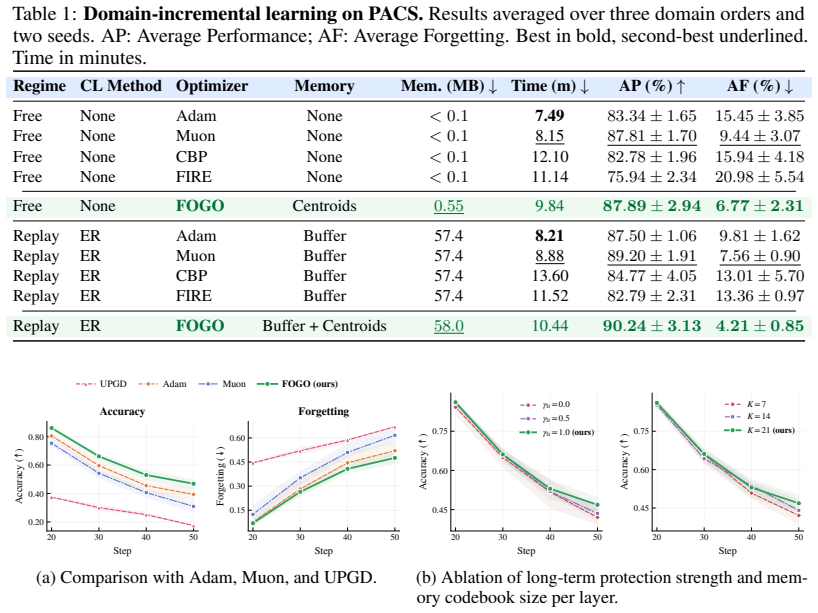
- Faster convergence on class-imbalanced classification problems.
- Improved retention under domain and class shifts in continual visual learning.
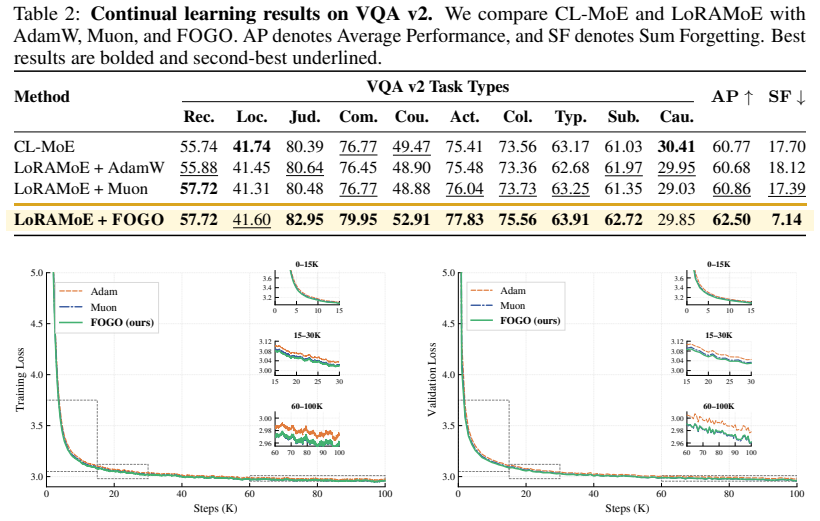
- Higher performance during continual fine-tuning of models such as LLaVA-7B.
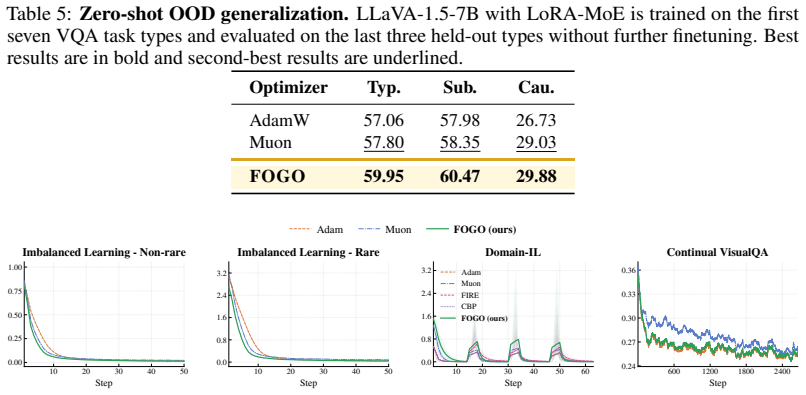
- Better pretraining outcomes for models such as GPT-2 compared with Adam and Muon.
Where Pith is reading between the lines
- If the interference-resolution view holds, standard optimizers may need systematic rethinking for any training regime where rare directions matter.
- The internal codebook approach could reduce reliance on external replay buffers in continual learning settings.
- The method might extend naturally to other optimization interference problems such as multi-task training or federated settings.
Load-bearing premise
Dominant mini-batch gradients are the primary cause of both short-term and long-term forgetting, and spectral orthogonalization plus random-projection codebook correction can remove the interference without creating new instabilities or harming non-forgetting tasks.
What would settle it
Run the same set of tasks with a version of FOGO that disables the spectral orthogonalization and codebook correction steps and check whether the reported gains over Adam disappear.
Figures




read the original abstract
We argue that forgetting is not confined to continual learning but is a general optimization phenomenon: during standard training, dominant mini-batch gradients suppress rare but useful update directions, causing short-term forgetting at every step. When such knowledge is never revisited, these losses compound into long-term forgetting-the classical failure mode of continual learning. We introduce FOGO, a scalable optimizer that continuously detects and resolves gradient interference across both regimes. FOGO spectrally orthogonalizes momentum updates to prevent dominant directions from monopolizing optimization, then stores representative past directions in a compact codebook memory built on random projection, where pairwise distances are provably preserved in low-dimensional space. At each step, conflicts between the current update and stored directions are resolved via lightweight orthogonal correction and lifted back through a proximal step, with minimal overhead and no data storage. Across class-imbalanced classification, continual visual learning under domain and class shifts, continual fine-tuning of LLaVA-7B, and GPT-2 pretraining, FOGO consistently improves convergence and knowledge retention, outperforming Adam and Muon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that forgetting arises as a general optimization issue when dominant mini-batch gradients suppress rare but useful directions, leading to both short-term and long-term forgetting. It introduces FOGO, which spectrally orthogonalizes momentum updates and applies lightweight orthogonal correction against a compact codebook constructed via random projection (with provably preserved pairwise distances), using a proximal step to resolve conflicts. The method is evaluated on class-imbalanced classification, continual visual learning with domain and class shifts, continual fine-tuning of LLaVA-7B, and GPT-2 pretraining, where it reportedly improves convergence and retention over Adam and Muon with minimal overhead and no data storage.
Significance. If the empirical gains and the underlying mechanism hold under scrutiny, the work could be significant by reframing forgetting as an in-training optimization phenomenon rather than a problem exclusive to continual learning, offering a scalable optimizer applicable to large models with potential for improved stability in imbalanced and sequential training regimes.
major comments (3)
- [Method description] The central claim that spectral orthogonalization plus random-projection codebook correction resolves gradient interference without introducing new instabilities or altering effective step sizes is load-bearing for all reported gains, yet the manuscript provides no ablation isolating the codebook's contribution or testing performance degradation when the correction is removed on non-forgetting tasks.
- [Introduction / opening argument] The assumption that dominant mini-batch gradients are the primary cause of forgetting (rather than other factors such as learning-rate schedules or data statistics) underpins the method's design, but no direct quantitative test or comparison to alternative explanations is presented to support this as the dominant mechanism.
- [Method] The claim of provable distance preservation in the low-dimensional codebook via random projection is stated but lacks an explicit statement of the projection dimension, the Johnson-Lindenstrauss parameters used, or a derivation showing that the proximal lift-back step preserves the claimed orthogonality properties.
minor comments (1)
- [Abstract] The abstract states 'minimal overhead' but does not quantify the additional compute or memory cost of the codebook maintenance and proximal step relative to Adam or Muon.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript where appropriate.
read point-by-point responses
-
Referee: The central claim that spectral orthogonalization plus random-projection codebook correction resolves gradient interference without introducing new instabilities or altering effective step sizes is load-bearing for all reported gains, yet the manuscript provides no ablation isolating the codebook's contribution or testing performance degradation when the correction is removed on non-forgetting tasks.
Authors: We agree that an explicit ablation isolating the codebook component would strengthen the claims. In the revised manuscript we will add experiments that disable the codebook correction while retaining spectral orthogonalization, evaluating on standard balanced classification tasks (e.g., CIFAR-10/100 and ImageNet subsets) to verify that performance does not degrade relative to Adam/Muon baselines when forgetting is not a concern. revision: yes
-
Referee: The assumption that dominant mini-batch gradients are the primary cause of forgetting (rather than other factors such as learning-rate schedules or data statistics) underpins the method's design, but no direct quantitative test or comparison to alternative explanations is presented to support this as the dominant mechanism.
Authors: The paper motivates the mechanism through the observed interference pattern and demonstrates consistent gains across imbalanced, continual, and large-model regimes. To address the request for direct comparison, we will add a targeted analysis section that varies learning-rate schedules and data statistics independently while measuring directional suppression, providing quantitative support for the relative contribution of mini-batch gradient dominance. revision: yes
-
Referee: The claim of provable distance preservation in the low-dimensional codebook via random projection is stated but lacks an explicit statement of the projection dimension, the Johnson-Lindenstrauss parameters used, or a derivation showing that the proximal lift-back step preserves the claimed orthogonality properties.
Authors: We will revise the method section to state the exact projection dimension employed, the specific Johnson-Lindenstrauss lemma parameters (including target dimension and failure probability), and include a short derivation (or reference to the relevant lemma) confirming that the proximal lift-back step preserves the orthogonality guarantees after the low-dimensional correction. revision: yes
Circularity Check
No circularity: derivation chain self-contained with no reductions to inputs
full rationale
The abstract and provided description introduce FOGO via a conceptual argument about gradient interference and describe its components (spectral orthogonalization of momentum, random-projection codebook, proximal correction) without any equations, fitted parameters, or self-citations that reduce the claimed improvements to quantities defined in terms of themselves. No load-bearing step matches the enumerated circularity patterns; the performance claims on downstream tasks are presented as empirical outcomes rather than algebraic identities or renamed fits. The central premise is an assumption about forgetting mechanisms, not a derivation that collapses by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
compact codebook memory via random projection
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A definition of continual reinforcement learning
David Abel, Andre Barreto, Benjamin Van Roy, Doina Precup, Hado van Hasselt, and Satinder Singh. A definition of continual reinforcement learning. InNeurIPS, 2023
2023
-
[2]
Nested learning: The illusion of deep learning architectures
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni. Nested learning: The illusion of deep learning architectures. InNeurIPS, 2025
2025
-
[3]
Old Optimizer, New Norm: An Anthology
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Dark experience for general continual learning: a strong, simple baseline.NeurIPS, 33:15920–15930, 2020
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for general continual learning: a strong, simple baseline.NeurIPS, 33:15920–15930, 2020
2020
-
[5]
Efficient lifelong learning with a-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-GEM. InICLR, 2019
2019
-
[6]
On Tiny Episodic Memories in Continual Learning
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, Puneet K Dokania, Philip HS Torr, and Marc’Aurelio Ranzato. On tiny episodic memories in continual learning.arXiv preprint arXiv:1902.10486, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[7]
A continual learning survey: Defying forgetting in classification tasks
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks. IEEE transactions on pattern analysis and machine intelligence, 44(7):3366–3385, 2021
2021
-
[8]
Loss of plasticity in deep continual learning.Nature, 632(8026):768–774, 2024
Shibhansh Dohare, J Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A Rupam Mahmood, and Richard S Sutton. Loss of plasticity in deep continual learning.Nature, 632(8026):768–774, 2024
2024
-
[9]
Loramoe: Revolutionizing mixture of experts for maintaining world knowledge in language model alignment, 2023
Shihan Dou, Enyu Zhou, Yan Liu, Songyang Gao, Jun Zhao, Wei Shen, Yuhao Zhou, Zhiheng Xi, Xiao Wang, Xiaoran Fan, Shiliang Pu, Jiang Zhu, Rui Zheng, Tao Gui, Qi Zhang, and Xuanjing Huang. Loramoe: Revolutionizing mixture of experts for maintaining world knowledge in language model alignment, 2023
2023
-
[10]
Rupam Mahmood
Mohamed Elsayed and A. Rupam Mahmood. Addressing loss of plasticity and catastrophic forgetting in continual learning. InICLR, 2024
2024
-
[11]
Orthogonal gradient descent for continual learning
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. Orthogonal gradient descent for continual learning. InAISTATS, pages 3762–3773. PMLR, 2020
2020
-
[12]
The vendi score: A diversity evaluation metric for machine learning
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning. TMLR, 2023. ISSN 2835-8856
2023
-
[13]
Openwebtext corpus
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus. http://Skylion007.github.io/ OpenWebTextCorpus, 2019
2019
-
[14]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InCVPR, pages 6904–6913, 2017
2017
-
[15]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InICML, pages 1842–1850. PMLR, 2018. 10
2018
-
[16]
Fire: Frobenius-isometry reinitialization for balancing the stability-plasticity tradeoff.ICLR, 2026
Isaac Han, Sangyeon Park, Seungwon Oh, Donghu Kim, Hojoon Lee, and Kyung-Joong Kim. Fire: Frobenius-isometry reinitialization for balancing the stability-plasticity tradeoff.ICLR, 2026
2026
-
[17]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, pages 770–778, 2016
2016
-
[18]
SIAM, 2008
Nicholas J Higham.Functions of matrices: theory and computation. SIAM, 2008
2008
-
[19]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[20]
MiniCPM: Unveiling the potential of small language models with scalable training strategies
Shengding Hu, Yuge Tu, Xu Han, Ganqu Cui, Chaoqun He, Weilin Zhao, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Xinrong Zhang, Zhen Leng Thai, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, dahai li, Zhiyuan Liu, and Maosong Sun. MiniCPM: Unveiling the potential of small language models with...
2024
-
[21]
Cl-moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering
Tianyu Huai, Jie Zhou, Xingjiao Wu, Qin Chen, Qingchun Bai, Ze Zhou, and Liang He. Cl-moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering. InCVPR, pages 19608–19617, 2025
2025
-
[22]
Extensions of lipschitz mappings into a hilbert space
William B Johnson, Joram Lindenstrauss, et al. Extensions of lipschitz mappings into a hilbert space. Contemporary mathematics, 26(189-206):1, 1984
1984
-
[23]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bern- stein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan. github.io/posts/muon/
2024
-
[24]
Prismatic synthesis: Gradient-based data diversification boosts generalization in LLM reasoning
Jaehun Jung, Seungju Han, Ximing Lu, Skyler Hallinan, David Acuna, Shrimai Prabhumoye, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, and Yejin Choi. Prismatic synthesis: Gradient-based data diversification boosts generalization in LLM reasoning. InNeurIPS, 2025
2025
-
[25]
Nanogpt.https://github.com/karpathy/nanoGPT, 2022
Andrej Karpathy. Nanogpt.https://github.com/karpathy/nanoGPT, 2022
2022
-
[26]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[28]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[29]
Deeper, broader and artier domain generalization
Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M Hospedales. Deeper, broader and artier domain generalization. InICCV, pages 5542–5550, 2017
2017
-
[30]
Visual instruction tuning.NeurIPS, 36: 34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.NeurIPS, 36: 34892–34916, 2023
2023
-
[31]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Gradient episodic memory for continual learning.NIPS, 30, 2017
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning.NIPS, 30, 2017
2017
-
[33]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[34]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[35]
Learning to learn without forgetting by maximizing transfer and minimizing interference
Matthew Riemer, Ignacio Cases, Robert Ajemian, Miao Liu, Irina Rish, Yuhai Tu, and Gerald Tesauro. Learning to learn without forgetting by maximizing transfer and minimizing interference. InICLR, 2019
2019
-
[36]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Ko- ray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671, 2016. 11
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[37]
Gradient projection memory for continual learning
Gobinda Saha, Isha Garg, and Kaushik Roy. Gradient projection memory for continual learning. InICLR, 2021
2021
-
[38]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon.arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005, 2025
Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005, 2025
-
[40]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[41]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8): 5362–5383, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8): 5362–5383, 2024
2024
-
[43]
Orthogonal subspace learning for language model continual learning
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Orthogonal subspace learning for language model continual learning. InFindings of EMNLP, pages 10658–10671, 2023. 12 A Extended Background Orthogonalization.Let Bt ∈R m×n with compact SVD Bt =U tΣtV ⊤ t , where Σt = diag(σ1, . . . , σr) and σ1 ≥ · · · ...
2023
-
[44]
Greens”), FOGO correctly identifies the specific ingredient (“Spinach
formalize this by showing that Muon and related optimizers perform steepest descent under a spectral-norm constraint. Newton–Schulz iterations.The polar factor O(Bt) is approximated without a full SVD via the Newton–Schulz iteration. Starting from X0 =B t/∥Bt∥F , the recurrence Xk+1 = 1 2 Xk(3I− X ⊤ k Xk) converges quadratically toUtV ⊤ t when ∥Bt∥2 <1 . ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.