ShaplEIG: Bayesian Experimental Design for Shapley Value Estimation
Pith reviewed 2026-06-28 12:35 UTC · model grok-4.3
The pith
ShaplEIG improves Shapley value estimation by adaptively selecting coalitions via closed-form expected information gain from a Gaussian process surrogate of the value function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling the value function with a Gaussian process, ShaplEIG computes the expected information gain about the Shapley values in closed form due to their linearity, and selects coalitions to evaluate that maximize this gain, with an efficient polynomial-time scheme based on elementary symmetric polynomials, resulting in improved approximation accuracy under limited evaluation budgets.
What carries the argument
Expected information gain for Shapley values computed from a Gaussian process surrogate of the value function, made tractable by linearity and elementary symmetric polynomials.
If this is right
- The method achieves higher accuracy with the same number of value function evaluations compared to non-adaptive sampling.
- It applies to any setting where Shapley values are estimated from costly value function queries, such as feature attribution, data valuation, and hyperparameter importance.
- The computational scheme scales polynomially rather than exponentially with the number of players.
- Consistent improvements are observed across multiple diverse costly applications in the low-budget regime.
Where Pith is reading between the lines
- The linearity argument may extend the same closed-form treatment to other attribution scores that are linear functions of the value function.
- Replacing the Gaussian process with a different surrogate could be tested while retaining the information-gain selection rule.
- The polynomial reduction opens the door to applying the method to games with dozens of players that were previously intractable for information-gain methods.
Load-bearing premise
A Gaussian process surrogate of the value function is accurate enough that selecting coalitions by expected information gain yields better Shapley estimates than non-adaptive sampling.
What would settle it
An experiment on a real costly value function in which ShaplEIG selections produce higher Shapley estimation error than random or stratified sampling after the same small number of evaluations.
Figures
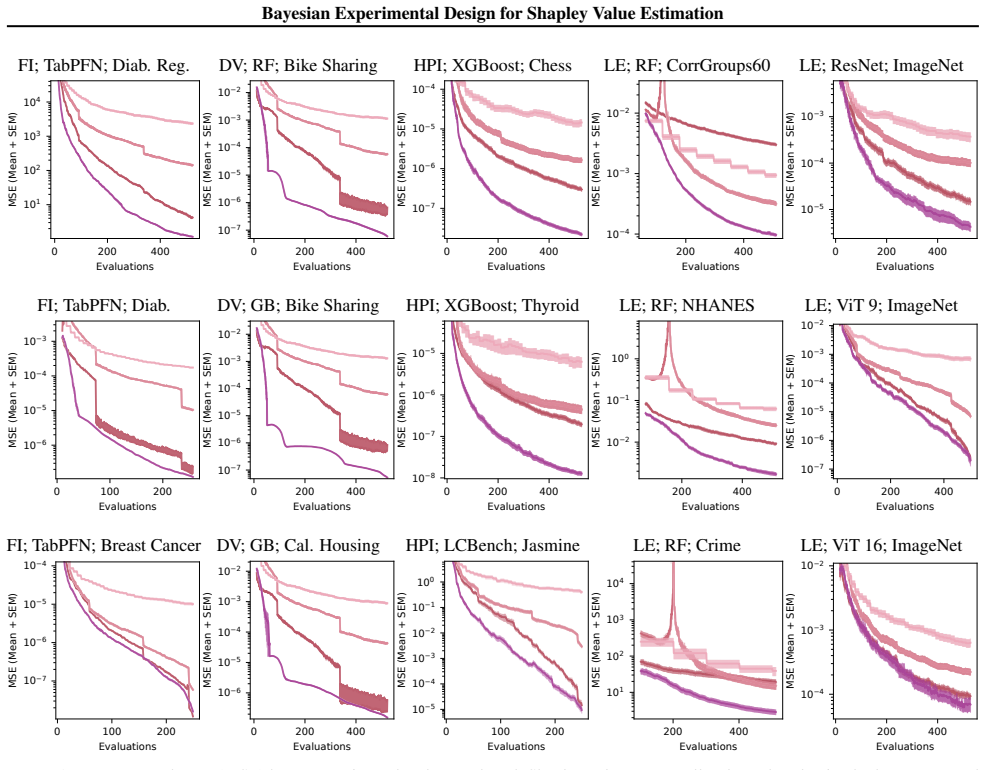

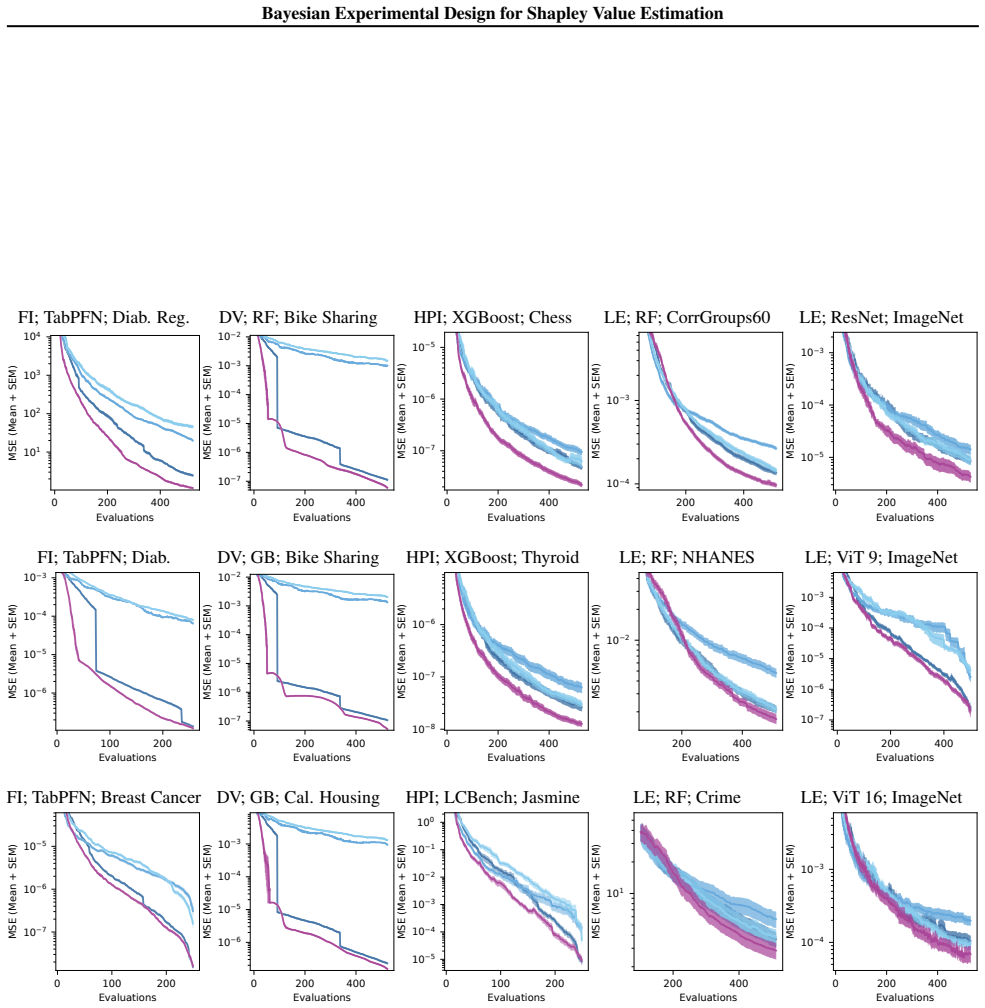
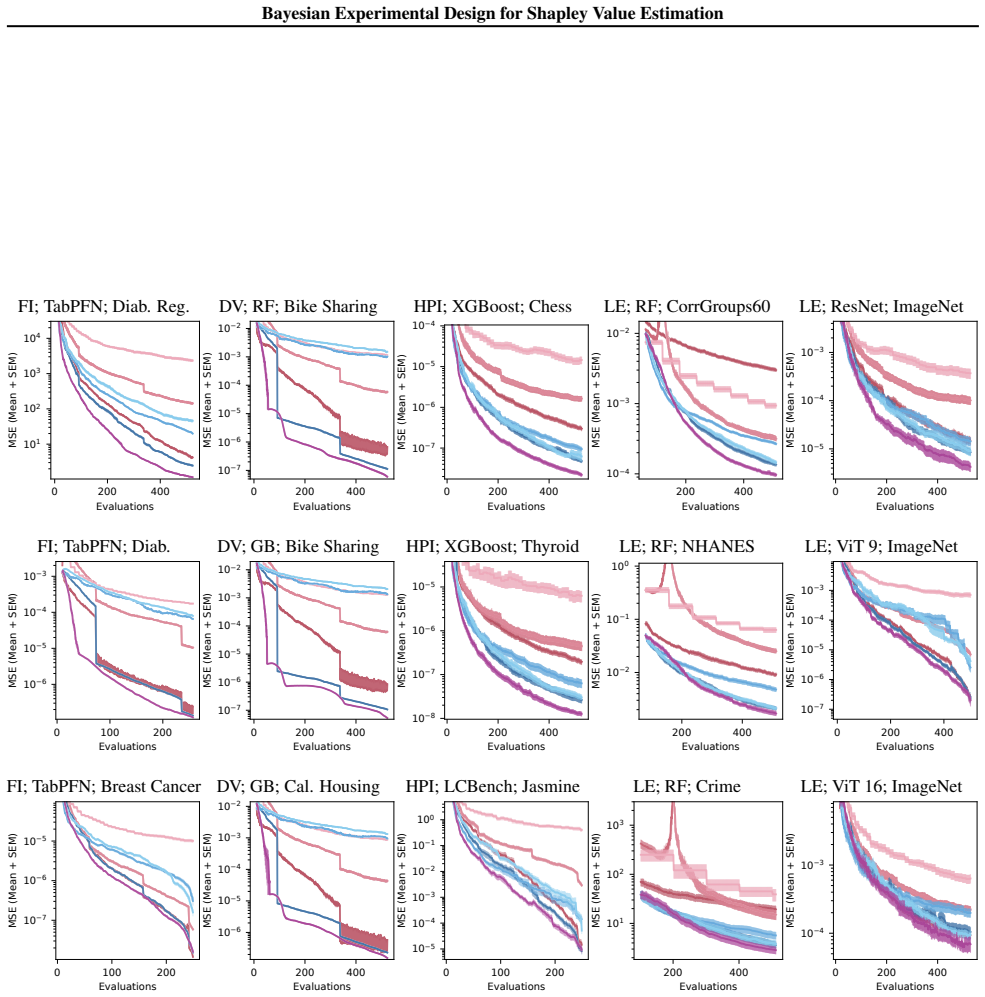
read the original abstract
Shapley values are a principled attribution measure widely used in interpretable machine learning, but their exact computation scales exponentially with the number of players, motivating a wide range of approximation methods based on value function evaluations of sampled coalitions. This raises the question of whether approximation accuracy can be improved by adaptively selecting coalitions for evaluation based on previous evaluations. This is particularly relevant in settings where the value function is costly and the number of evaluations is severely limited, such as retraining-based feature importance, data valuation, and hyperparameter importance. For this purpose, we propose ShaplEIG, a Bayesian experimental design approach that approximates the expensive value function using a Gaussian process surrogate and adaptively selects coalitions based on their expected information gain about the Shapley values. By the linearity of the Shapley values in the value function, we show that the expected information gain is available in closed form. Furthermore, we propose an efficient computation scheme that reduces the complexity from exponential to polynomial in the number of players via elementary symmetric polynomials. In extensive experiments across diverse costly applications, our method consistently improves sample efficiency in the low-budget regime over state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ShaplEIG, a Bayesian experimental design approach for approximating Shapley values under limited evaluations of a costly value function. It models the value function with a Gaussian process surrogate and adaptively selects coalitions to maximize expected information gain (EIG) about the Shapley values. The central technical claims are that linearity of Shapley values in the value function yields a closed-form EIG expression, and that elementary symmetric polynomials reduce the computational complexity from exponential to polynomial in the number of players. Experiments across costly applications are reported to show consistent gains in sample efficiency over baselines in the low-budget regime.
Significance. If the closed-form EIG derivation and the elementary-symmetric reduction hold without hidden approximations, the work provides a principled and scalable way to improve coalition selection for Shapley estimation when evaluations are expensive. The polynomial-time scheme is a concrete strength that addresses a practical barrier for larger player sets. The empirical demonstration of better low-budget performance, if supported by robust controls, would be relevant for feature attribution, data valuation, and hyperparameter importance tasks.
major comments (1)
- [Experiments (as summarized in abstract)] The headline empirical claim (consistent improvement via EIG-driven selection) is load-bearing on the assumption that the GP posterior on the value function produces predictive correlations that reliably rank coalitions better than non-adaptive designs. No calibration diagnostics, kernel sensitivity analysis, or ablation on the free GP hyperparameters are referenced, leaving open the possibility that reported gains depend on favorable surrogate mismatch rather than the EIG criterion itself.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will strengthen the empirical section accordingly.
read point-by-point responses
-
Referee: [Experiments (as summarized in abstract)] The headline empirical claim (consistent improvement via EIG-driven selection) is load-bearing on the assumption that the GP posterior on the value function produces predictive correlations that reliably rank coalitions better than non-adaptive designs. No calibration diagnostics, kernel sensitivity analysis, or ablation on the free GP hyperparameters are referenced, leaving open the possibility that reported gains depend on favorable surrogate mismatch rather than the EIG criterion itself.
Authors: We agree that the current manuscript lacks explicit calibration diagnostics, kernel sensitivity checks, and hyperparameter ablations, which leaves the source of the reported gains open to the interpretation raised. In the revised manuscript we will add: (i) posterior predictive calibration diagnostics (e.g., coverage of 95% credible intervals on held-out coalitions and PIT histograms); (ii) results under both RBF and Matérn kernels; and (iii) an ablation table varying length-scale and signal variance over a grid of plausible values while keeping the EIG acquisition fixed. These additions will demonstrate that the ranking advantage of EIG persists across reasonable GP configurations. We note that all compared methods in the experiments already share the same GP surrogate, so any systematic mismatch would affect the baselines equally; the differential performance is therefore attributable to the choice of acquisition function. revision: yes
Circularity Check
No significant circularity; derivation is self-contained.
full rationale
The paper's core derivation states that linearity of Shapley values in the value function yields closed-form EIG, with polynomial reduction via elementary symmetric polynomials. This follows directly from standard properties of Shapley values and Gaussian processes without defining the target in terms of the output or fitting parameters that are then relabeled as predictions. No self-citation chains, ansatzes smuggled via prior work, or uniqueness theorems from the same authors are invoked as load-bearing steps in the provided text. The GP surrogate assumption is external and falsifiable via experiments, not a definitional loop. This is the normal case of an independent mathematical reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gaussian process kernel hyperparameters
axioms (1)
- standard math Shapley values are linear in the value function
Reference graph
Works this paper leans on
-
[1]
Teal Witter and Christopher Musco , booktitle=
Fabian Fumagalli and R. Teal Witter and Christopher Musco , booktitle=. Poly. 2026 , url=
2026
-
[2]
Ghorbani, Amirata and Zou, James , booktitle=. Data. 2019 , organization=
2019
-
[3]
The Annals of Mathematical Statistics , volume=
On a measure of the information provided by an experiment , author=. The Annals of Mathematical Statistics , volume=. 1956 , publisher=
1956
-
[4]
1972 , publisher=
Bayesian statistics: A review , author=. 1972 , publisher=
1972
-
[5]
Statistical science , pages=
Bayesian experimental design: A review , author=. Statistical science , pages=. 1995 , publisher=
1995
-
[6]
Maximum entropy sampling and optimal
Sebastiani, Paola and Wynn, Henry P , journal=. Maximum entropy sampling and optimal. 2000 , publisher=
2000
-
[7]
A review of modern computational algorithms for
Ryan, Elizabeth G and Drovandi, Christopher C and McGree, James M and Pettitt, Anthony N , journal=. A review of modern computational algorithms for. 2016 , publisher=
2016
-
[8]
Journal of Machine Learning Research , volume=
Entropy search for information-efficient global optimization , author=. Journal of Machine Learning Research , volume=. 2012 , publisher=
2012
-
[9]
Advances in Neural Information Processing Systems , volume=
Predictive entropy search for efficient global optimization of black-box functions , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Variational,
Foster, Adam Evan , year=. Variational,
-
[11]
Rainforth, Tom and Foster, Adam and Ivanova, Desi R and Bickford Smith, Freddie , journal=. Modern. 2024 , publisher=
2024
-
[12]
Teal Witter and Yurong Liu and Christopher Musco , booktitle=
R. Teal Witter and Yurong Liu and Christopher Musco , booktitle=. Regression-adjusted
-
[13]
Approximating the
Kolpaczki, Patrick and Bengs, Viktor and Muschalik, Maximilian and H. Approximating the. Proceedings of the AAAI conference on Artificial Intelligence , volume=
-
[14]
Wang, Jiachen T and Jia, Ruoxi , booktitle=. Data. 2023 , organization=
2023
-
[15]
Rozemberczki, Benedek and Watson, Lauren and Bayer, P. The. The 31st International Joint Conference on Artificial Intelligence and the 25th European Conference on Artificial Intelligence , pages=. 2022 , organization=
2022
-
[16]
Algorithms to estimate
Chen, Hugh and Covert, Ian C and Lundberg, Scott M and Lee, Su-In , journal=. Algorithms to estimate
-
[17]
Christopher Frye and Damien de Mijolla and Tom Begley and Laurence Cowton and Megan Stanley and Ilya Feige , booktitle=
-
[18]
Wever, Marcel and Muschalik, Maximilian and Fumagalli, Fabian and Lindauer, Marius , booktitle=
-
[19]
Active Learning Literature Survey , type =
Settles, Burr , institution =. Active Learning Literature Survey , type =
-
[20]
Teal Witter , booktitle=
Christopher Musco and R. Teal Witter , booktitle=. Provably Accurate
-
[21]
Computers & Operations Research , volume = 36, number = 5, pages =
Javier Castro and Daniel G. Computers & Operations Research , volume = 36, number = 5, pages =
-
[22]
Kwon, Yongchan and Zou, James , booktitle=. Beta. 2022 , organization=
2022
-
[23]
From local explanations to global understanding with explainable
Lundberg, Scott M and Erion, Gabriel and Chen, Hugh and DeGrave, Alex and Prutkin, Jordan M and Nair, Bala and Katz, Ronit and Himmelfarb, Jonathan and Bansal, Nisha and Lee, Su-In , journal=. From local explanations to global understanding with explainable
-
[24]
Chen, Tianqi and Guestrin, Carlos , year = 2016, booktitle =
2016
-
[25]
Towards Efficient Data Valuation Based on the
Ruoxi Jia and David Dao and Boxin Wang and Frances Ann Hubis and Nick Hynes and Nezihe Merve G. Towards Efficient Data Valuation Based on the. Proceedings of the International Conference on Artificial Intelligence and Statistics
-
[26]
Acta Numerica , volume=
Optimal experimental design: Formulations and computations , author=. Acta Numerica , volume=. 2024 , publisher=
2024
-
[27]
Multilevel
Goda, Takashi and Hironaka, Tomohiko and Iwamoto, Takeru , journal=. Multilevel. 2020 , publisher=
2020
-
[28]
International Conference on Machine Learning , pages=
Bayesian algorithm execution: Estimating computable properties of black-box functions using mutual information , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[29]
Annals of statistics , pages=
Greedy function approximation: a gradient boosting machine , author=. Annals of statistics , pages=. 2001 , publisher=
2001
-
[30]
Biometrika , volume=
Bayesian adaptive designs for clinical trials , author=. Biometrika , volume=. 2005 , publisher=
2005
-
[31]
Gaussian measure in
Larkin, FM , journal=. Gaussian measure in. 1972 , publisher=
1972
-
[32]
Journal of statistical planning and inference , volume=
Bayes--hermite quadrature , author=. Journal of statistical planning and inference , volume=. 1991 , publisher=
1991
-
[33]
Sampling for inference in probabilistic models with fast
Gunter, Tom and Osborne, Michael A and Garnett, Roman and Hennig, Philipp and Roberts, Stephen J , journal=. Sampling for inference in probabilistic models with fast
-
[34]
Bayesian
Rasmussen, Carl Edward and Ghahramani, Zoubin , journal=. Bayesian. 2003 , publisher=
2003
-
[36]
Gal, Yarin and Islam, Riashat and Ghahramani, Zoubin , booktitle=. Deep. 2017 , organization=
2017
-
[37]
2023 , publisher =
Garnett, Roman , title =. 2023 , publisher =
2023
-
[38]
Williams, Christopher and Rasmussen, Carl , journal=
-
[39]
Williams, Christopher KI and Rasmussen, Carl Edward , year=
-
[40]
1953 , publisher=
A value for n-person games , author=. 1953 , publisher=
1953
-
[41]
Advances in Neural Information Processing Systems , volume=
A unified approach to interpreting model predictions , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Approximate
Csill. Approximate. Trends in ecology & evolution , volume=. 2010 , publisher=
2010
-
[43]
Near-optimal sensor placements in
Krause, Andreas and Singh, Ajit and Guestrin, Carlos , journal=. Near-optimal sensor placements in
-
[44]
Applied Crystallography , volume=
Information gain from isotopic contrast variation in neutron reflectometry on protein--membrane complex structures , author=. Applied Crystallography , volume=. 2020 , publisher=
2020
-
[45]
Machine learning proceedings 1994 , pages=
Heterogeneous uncertainty sampling for supervised learning , author=. Machine learning proceedings 1994 , pages=. 1994 , publisher=
1994
-
[46]
and Daulton, Samuel and Letham, Benjamin and Wilson, Andrew Gordon and Bakshy, Eytan , booktitle =
Balandat, Maximilian and Karrer, Brian and Jiang, Daniel R. and Daulton, Samuel and Letham, Benjamin and Wilson, Andrew Gordon and Bakshy, Eytan , booktitle =
-
[47]
Gardner, Jacob R and Pleiss, Geoff and Bindel, David and Weinberger, Kilian Q and Wilson, Andrew Gordon , booktitle=
-
[48]
Machine learning , volume=
Random forests , author=. Machine learning , volume=. 2001 , publisher=
2001
-
[49]
Patterns , volume =
Bernd Bischl and Giuseppe Casalicchio and Taniya Das and Matthias Feurer and Sebastian Fischer and Pieter Gijsbers and Subhaditya Mukherjee and Andreas C Müller and László Németh and Luis Oala and Lennart Purucker and Sahithya Ravi and Jan N van Rijn and Prabhant Singh and Joaquin Vanschoren and Jos van der Velde and Marcel Wever , title =. Patterns , vol...
2025
-
[50]
Advances in Neural Information Processing Systems , volume=
Fumagalli, Fabian and Muschalik, Maximilian and Kolpaczki, Patrick and H. Advances in Neural Information Processing Systems , volume=
-
[51]
SIAM Journal on scientific computing , volume=
A limited memory algorithm for bound constrained optimization , author=. SIAM Journal on scientific computing , volume=. 1995 , publisher=
1995
-
[52]
Goal-oriented optimal design of experiments for large-scale
Attia, Ahmed and Alexanderian, Alen and Saibaba, Arvind K , journal=. Goal-oriented optimal design of experiments for large-scale. 2018 , publisher=
2018
-
[53]
Goal-oriented
Zhong, Shijie and Shen, Wanggang and Catanach, Tommie and Huan, Xun , journal=. Goal-oriented. 2026 , publisher=
2026
-
[54]
A computational framework for infinite-dimensional
Bui-Thanh, Tan and Ghattas, Omar and Martin, James and Stadler, Georg , journal=. A computational framework for infinite-dimensional. 2013 , publisher=
2013
-
[55]
Alexanderian, Alen and Gloor, Philip J and Ghattas, Omar , year=. On. Bayesian Analysis , volume=
-
[56]
Goal-oriented optimal approximations of
Spantini, Alessio and Cui, Tiangang and Willcox, Karen and Tenorio, Luis and Marzouk, Youssef , journal=. Goal-oriented optimal approximations of. 2017 , publisher=
2017
-
[57]
siam REVIEW , volume=
Goal-oriented inference: Approach, linear theory, and application to advection diffusion , author=. siam REVIEW , volume=. 2013 , publisher=
2013
-
[58]
Nature , year=
Accurate predictions on small data with a tabular foundation model , author=. Nature , year=
-
[59]
Interpretable machine learning for
Rundel, David and Kobialka, Julius and von Crailsheim, Constantin and Feurer, Matthias and Nagler, Thomas and R. Interpretable machine learning for. World Conference on Explainable Artificial Intelligence , pages=. 2024 , organization=
2024
-
[60]
Automated configuration of algorithms for solving hard computational problems , school=
Hutter, Frank , year=. Automated configuration of algorithms for solving hard computational problems , school=
-
[61]
Proceeedings of the
Incentivizing Collaboration in Machine Learning via Synthetic Data Rewards , author =. Proceeedings of the
-
[62]
2008 , publisher=
Qian, Peter Z G and Wu, Huaiqing and Wu, CF Jeff , journal=. 2008 , publisher=
2008
-
[63]
Learning a
Platt, John and Burges, Christopher J and Swenson, Steven and Weare, Christopher and Zheng, Alice , journal=. Learning a
-
[64]
Sampling permutations for
Mitchell, Rory and Cooper, Joshua and Frank, Eibe and Holmes, Geoffrey , journal=. Sampling permutations for
-
[65]
Optimally-weighted herding is
Husz. Optimally-weighted herding is. Proceedings of the Twenty-Eighth Conference on Uncertainty in Artificial Intelligence , pages=
-
[66]
Advances in Neural Information Processing Systems , volume=
Reliable post hoc explanations: Modeling uncertainty in explainability , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
Explaining the Uncertain: Stochastic
Chau, Siu Lun and Muandet, Krikamol and Sejdinovic, Dino , booktitle =. Explaining the Uncertain: Stochastic
-
[68]
Deconditional downscaling with
Chau, Siu Lun and Bouabid, Shahine and Sejdinovic, Dino , journal=. Deconditional downscaling with
-
[69]
Advances in Neural Information Processing Systems , volume=
Bayesimp: Uncertainty quantification for causal data fusion , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
Computing Exact
Mohammadi, Majid and Chau, Siu Lun and Muandet, Krikamol , journal=. Computing Exact
-
[71]
Chau, Siu Lun and Hu, Robert and Gonzalez, Javier and Sejdinovic, Dino , journal=
-
[72]
Mohammadi, Majid and Muandet, Krikamol and Tiddi, Ilaria and Teije, Annette Ten and Chau, Siu Lun , journal=. Exact
-
[73]
Maximilian Muschalik and Hubert Baniecki and Fabian Fumagalli and Patrick Kolpaczki and Barbara Hammer and Eyke H\". shapiq:. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year =
-
[74]
2021 , organization=
Covert, Ian and Lee, Su-In , booktitle=. 2021 , organization=
2021
-
[75]
IEEE transactions on pattern analysis and machine intelligence , volume=
Auto-pytorch: Multi-fidelity metalearning for efficient and robust autodl , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
2021
-
[76]
2022 , editor =
Pfisterer, Florian and Schneider, Lennart and Moosbauer, Julia and Binder, Martin and Bischl, Bernd , booktitle =. 2022 , editor =
2022
-
[77]
and Schonlau, Matthias and Welch, William J
Jones, Donald R. and Schonlau, Matthias and Welch, William J. Efficient Global Optimization of Expensive Black-Box Functions. Journal of Global Optimization. 1998
1998
-
[78]
and Williams, Brian J
Santner, Thomas J. and Williams, Brian J. and Notz, William I. , title =
-
[79]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. International Conference on Lea...
2021
-
[80]
Deep Residual Learning for Image Recognition , year=
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , booktitle=. Deep Residual Learning for Image Recognition , year=
-
[81]
Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems , pages=
DUPRE: Data Utility Prediction for Efficient Data Valuation , author=. Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.