Sub-Billion, Super-Frontier: Small Language Models Rival Zero-Shot Frontier LLMs on General and Literary Relation Extraction
Pith reviewed 2026-06-26 10:14 UTC · model grok-4.3
The pith
A 0.5-billion-parameter model fine-tuned on relation extraction data outperforms zero-shot GPT-5.4 and Claude Sonnet 4.6 on general and literary benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
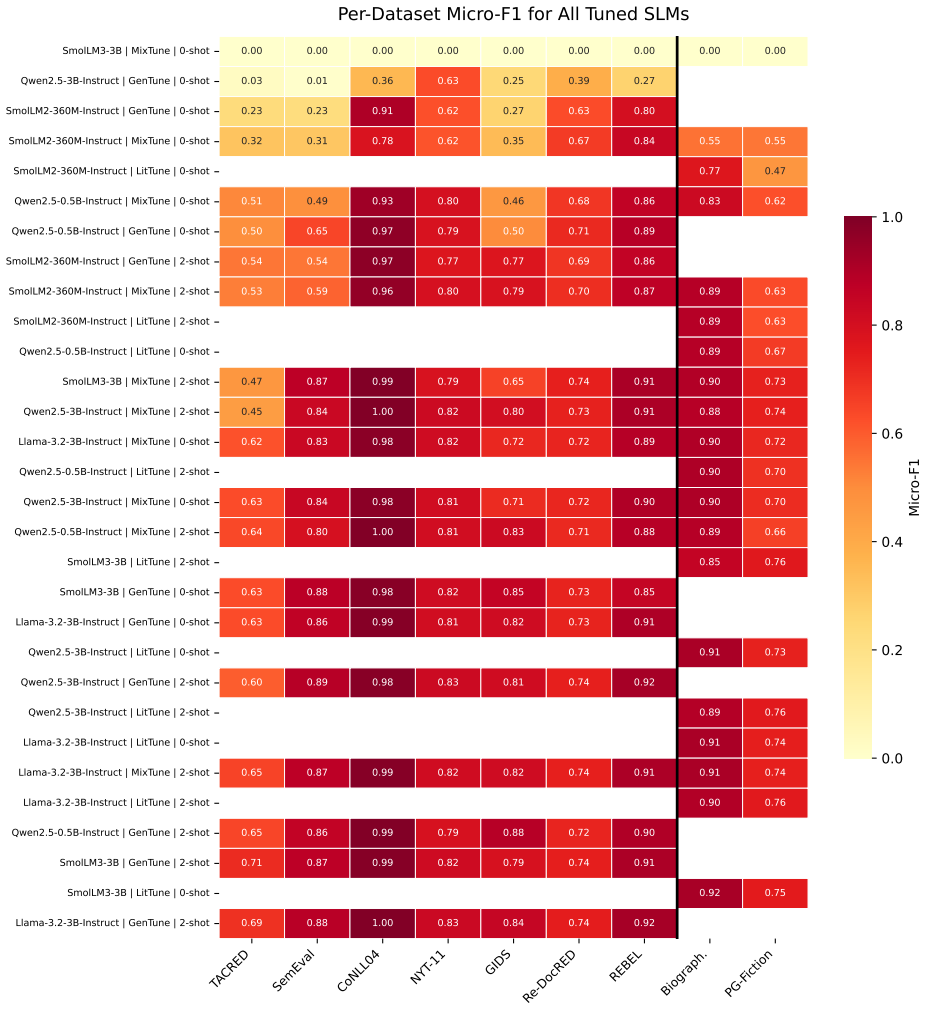
Across nine benchmarks, the best sub-billion model, Qwen2.5-0.5B fine-tuned on pooled general-domain data, achieves a general-domain positive-class micro-F1 of 0.83, versus 0.69 for GPT-5.4 and 0.66 for Claude Sonnet 4.6 evaluated zero-shot. This does not imply that SLMs are intrinsically stronger; rather, targeted task adaptation enables 4-bit models deployable on a single consumer GPU to outperform general-purpose frontier systems under this protocol. An in-domain RoBERTa baseline also exceeds both frontier models, indicating that the gain stems from task adaptation rather than generative decoding. On literary RE, tuned SLMs reach 0.92 on the human-annotated Biographical benchmark versus 0
What carries the argument
Task-specific fine-tuning of sub-billion language models on pooled general-domain data, evaluated against zero-shot prompting of frontier LLMs on the same relation extraction benchmarks.
If this is right
- Task-adapted 4-bit SLMs can be deployed on a single consumer GPU while exceeding the accuracy of zero-shot frontier LLMs on relation extraction.
- The performance advantage arises from supervised task adaptation rather than from model scale or generative decoding capabilities.
- An in-domain RoBERTa baseline surpassing the frontier models shows that the gains are not limited to generative small models.
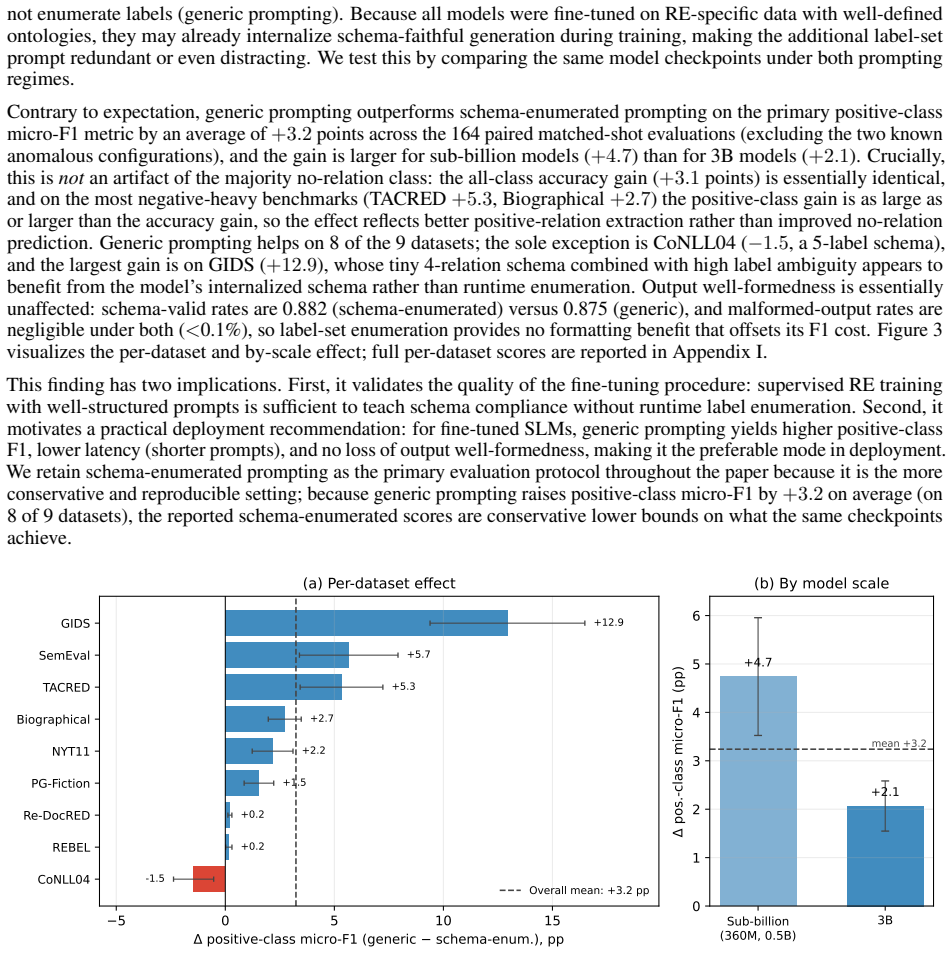
- Domain-adaptive pretraining before fine-tuning yields no practically meaningful improvement over direct supervised fine-tuning.
- Tuned SLMs achieve larger margins on literary benchmarks, reaching 0.92 F1 versus 0.83 for GPT-5.4 on the Biographical set.
Where Pith is reading between the lines
- The pattern suggests that access to task-specific labeled data can reduce dependence on large proprietary APIs for information extraction workflows.
- Domains handling sensitive text, such as biographical or literary analysis, could shift toward on-premise compact models to maintain privacy.
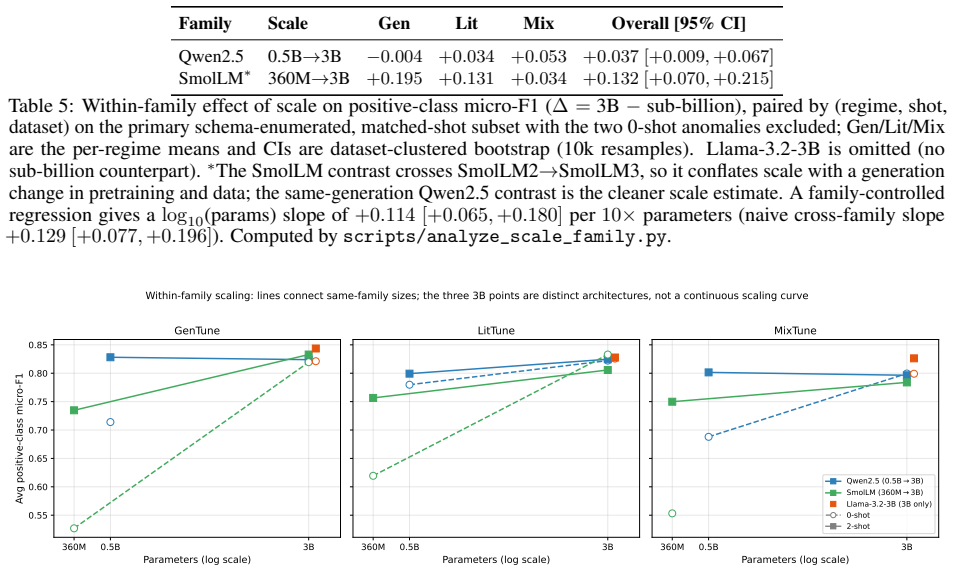
- Within-family scaling experiments showing only marginal gains imply that further size increases may offer diminishing returns once adaptation is applied.
Load-bearing premise
The zero-shot prompting protocol used for the frontier LLMs constitutes a representative and fair baseline against which task-adapted smaller models should be judged.
What would settle it
Re-evaluating GPT-5.4 or Claude Sonnet 4.6 on the same general-domain benchmarks with optimized prompts or the same fine-tuning protocol and obtaining a positive-class micro-F1 of 0.83 or higher would falsify the reported advantage.
Figures
read the original abstract
Large language models (LLMs) achieve strong relation extraction (RE), but their computational demands and reliance on proprietary APIs limit deployment in resource-constrained or privacy-sensitive settings. We investigate how far small language models (SLMs) can close this gap across general-domain and literary text. We evaluate five models from 360M to 3B parameters under three domain-composition regimes and two prompt-conditioned tuning styles (30 configurations), comparing them with zero-shot frontier LLMs and a discriminative RoBERTa baseline. Across nine benchmarks, the best sub-billion model, Qwen2.5-0.5B fine-tuned on pooled general-domain data, achieves a general-domain positive-class micro-F1 of 0.83, versus 0.69 for GPT-5.4 and 0.66 for Claude Sonnet 4.6 evaluated zero-shot. This does not imply that SLMs are intrinsically stronger; rather, targeted task adaptation enables 4-bit models deployable on a single consumer GPU to outperform general-purpose frontier systems under this protocol. An in-domain RoBERTa baseline also exceeds both frontier models, indicating that the gain stems from task adaptation rather than generative decoding. On literary RE, tuned SLMs reach 0.92 on the human-annotated Biographical benchmark versus 0.83 for GPT-5.4, and 0.833 versus 0.578 on the two-benchmark literary average. A targeted domain-adaptive pretraining case study yields no practically meaningful gain over supervised fine-tuning, while the cleanest within-family scale comparison shows only marginal improvement. These results show that, when task-specific data are available, compact task-adapted models can provide accurate, private, and hardware-efficient RE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates small language models (360M–3B parameters) on relation extraction across general-domain and literary benchmarks under three domain-composition regimes and two tuning styles (30 configurations total). It reports that Qwen2.5-0.5B fine-tuned on pooled general-domain data reaches positive-class micro-F1 of 0.83, exceeding zero-shot GPT-5.4 (0.69) and Claude Sonnet 4.6 (0.66); similar gains appear on literary tasks (e.g., 0.92 vs. 0.83 on the Biographical benchmark). The work concludes that task adaptation, rather than scale or generative decoding, drives the advantage, as an in-domain RoBERTa baseline also surpasses the frontier models, enabling efficient private deployment of 4-bit SLMs.
Significance. If the comparisons are robust, the result shows that task-adapted sub-billion models can outperform zero-shot frontier LLMs on RE when labeled data exist, with direct implications for cost, privacy, and single-GPU deployment. The finding that even a discriminative baseline exceeds the LLMs reinforces that the gains stem from supervision rather than model class. This supplies a concrete, falsifiable demonstration that targeted adaptation can close or reverse the performance gap for a well-defined NLP task.
major comments (3)
- [Abstract] Abstract and implied Experimental Setup section: the zero-shot F1 scores for GPT-5.4 (0.69) and Claude Sonnet 4.6 (0.66) are reported without the exact prompt templates, output format instructions, or any ablation on prompt variants (e.g., chain-of-thought or structured JSON). Because the central claim that the fine-tuned 0.5B model “rivals” the frontier models rests on these baselines being representative rather than a lower bound, the omission is load-bearing.
- [Abstract] Abstract and Results: the headline micro-F1 values (0.83 vs. 0.69/0.66) are given as point estimates with no run-to-run variance, standard deviations, number of seeds, or statistical significance tests, and no information on data-split details. This prevents verification that the reported gap is stable, directly affecting the soundness of the quantitative comparison.
- [Abstract] Literary RE paragraph: the two-benchmark literary average (0.833 vs. 0.578) is stated without naming the two benchmarks or describing how the average is computed, making it impossible to assess whether the reported advantage is driven by one outlier benchmark or is consistent.
minor comments (1)
- The abstract states that 30 configurations were evaluated but supplies no summary table or breakdown by regime and tuning style, which would aid readability of the experimental design.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify important gaps in reproducibility and clarity that we will address in revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and implied Experimental Setup section: the zero-shot F1 scores for GPT-5.4 (0.69) and Claude Sonnet 4.6 (0.66) are reported without the exact prompt templates, output format instructions, or any ablation on prompt variants (e.g., chain-of-thought or structured JSON). Because the central claim that the fine-tuned 0.5B model “rivals” the frontier models rests on these baselines being representative rather than a lower bound, the omission is load-bearing.
Authors: We agree that exact prompt templates and output formatting instructions are required for reproducibility and to substantiate that the zero-shot scores are representative. In the revised manuscript we will add the complete prompt templates and formatting instructions used for GPT-5.4 and Claude Sonnet 4.6 to a new appendix. Our study deliberately used standard zero-shot prompting without chain-of-thought or JSON variants; we will state this design choice explicitly and note the lack of prompt ablations as a limitation. revision: yes
-
Referee: [Abstract] Abstract and Results: the headline micro-F1 values (0.83 vs. 0.69/0.66) are given as point estimates with no run-to-run variance, standard deviations, number of seeds, or statistical significance tests, and no information on data-split details. This prevents verification that the reported gap is stable, directly affecting the soundness of the quantitative comparison.
Authors: We accept that single-point estimates without variance or seed information limit assessment of stability. The fine-tuned results reflect single runs per configuration (30 total) owing to compute constraints; zero-shot LLM calls are deterministic given fixed prompts. The full manuscript already describes the data splits; we will move key split details into the abstract or results section, explicitly report the number of seeds used, and add a short discussion of the single-run limitation. Statistical significance tests were not performed and will be noted as absent. revision: partial
-
Referee: [Abstract] Literary RE paragraph: the two-benchmark literary average (0.833 vs. 0.578) is stated without naming the two benchmarks or describing how the average is computed, making it impossible to assess whether the reported advantage is driven by one outlier benchmark or is consistent.
Authors: We agree the abstract is insufficiently precise. The two benchmarks are the Biographical benchmark and the second literary benchmark used in the study; the average is the arithmetic mean of their positive-class micro-F1 scores. In the revised abstract we will name both benchmarks and state how the average is obtained. revision: yes
Circularity Check
No circularity: purely empirical model evaluations with no derivations or self-referential predictions
full rationale
The paper consists entirely of direct experimental results: training SLMs on relation extraction benchmarks, computing micro-F1 scores, and comparing them to zero-shot frontier LLM baselines. No equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes are present in the reported claims. The central numbers (e.g., Qwen2.5-0.5B at 0.83 vs. GPT-5.4 at 0.69) are observed performance metrics, not derived quantities that reduce to their own inputs by construction. This is the expected non-finding for an empirical benchmarking study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI conference on artificial intelligence , volume=
Toward an architecture for never-ending language learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[2]
IEEE Access , volume=
Improving distantly-supervised relation extraction through bert-based label and instance embeddings , author=. IEEE Access , volume=. 2021 , publisher=
2021
-
[3]
Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Knowledge vault: A web-scale approach to probabilistic knowledge fusion , author=. Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[5]
ACM Computing Surveys , volume=
A comprehensive survey on relation extraction: Recent advances and new frontiers , author=. ACM Computing Surveys , volume=. 2024 , publisher=
2024
-
[7]
2024 , month =
The Claude 3 Model Family: Opus, Sonnet, Haiku , author =. 2024 , month =
2024
-
[9]
2025 , month = mar, url =
Koray Kavukcuoglu , title =. 2025 , month = mar, url =
2025
-
[11]
CoRR , year=
Qwen2 Technical Report , author=. CoRR , year=
-
[13]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[14]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference , author=. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
-
[15]
Proceedings of the AAAI conference on artificial intelligence , volume=
Energy and policy considerations for modern deep learning research , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[16]
Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
On the dangers of stochastic parrots: Can language models be too big? , author=. Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
2021
-
[18]
Proceedings of the 36th International Conference on Neural Information Processing Systems , pages=
Training compute-optimal large language models , author=. Proceedings of the 36th International Conference on Neural Information Processing Systems , pages=
-
[20]
International Conference on Learning Representations , year=
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations , author=. International Conference on Learning Representations , year=
-
[21]
International Conference on Learning Representations , year=
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators , author=. International Conference on Learning Representations , year=
-
[22]
Phi-4 Technical Report , institution =
Marah Abdin and Jyoti Aneja and Harkirat Behl and S. Phi-4 Technical Report , institution =. 2024 , month = dec, url =
2024
-
[23]
An annotated dataset of literary entities , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[27]
Advances in Neural Information Processing Systems , volume=
QLoRA: Efficient Finetuning of Quantized Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers , pages=
Relation classification via convolutional deep neural network , author=. Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers , pages=
2014
-
[29]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle=
-
[31]
Joshi, Mandar and Chen, Danqi and Liu, Yinhan and Weld, Daniel S and Zettlemoyer, Luke and Levy, Omer , journal=
-
[32]
Yamada, Ikuya and Asai, Akari and Shindo, Hiroyuki and Takeda, Hideaki and Matsumoto, Yuji , booktitle=
-
[33]
He, Pengcheng and Liu, Xiaodong and Gao, Jianfeng and Chen, Weizhu , booktitle=
-
[34]
Proceedings of the 24th European Conference on Artificial Intelligence (ECAI 2020) , pages=
Span-based Joint Entity and Relation Extraction with Transformer Pre-training , author=. Proceedings of the 24th European Conference on Artificial Intelligence (ECAI 2020) , pages=
2020
-
[35]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , pages=
A Frustratingly Easy Approach for Entity and Relation Extraction , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , pages=
2021
-
[36]
Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM) , pages=
Enriching Pre-trained Language Model with Entity Information for Relation Classification , author=. Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM) , pages=
-
[37]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
Don't Stop Pretraining: Adapt Language Models to Domains and Tasks , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[38]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Revisiting Relation Extraction in the era of Large Language Models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
Proceedings of the 9th International Conference on Learning Representations (ICLR) , year=
Structured Prediction as Translation between Augmented Natural Languages , author=. Proceedings of the 9th International Conference on Learning Representations (ICLR) , year=
-
[40]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
Huguet Cabot, Pere-Llu. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
2021
-
[41]
arXiv preprint , year=
From Extraction to Generation: A Survey of Generative Information Extraction , author=. arXiv preprint , year=
-
[42]
Evaluating
Li, Bo and Zhang, Gexiang and Roth, Dan , journal=. Evaluating
-
[43]
arXiv preprint , year=
Bridging Generative and Discriminative Models for Information Extraction , author=. arXiv preprint , year=
-
[44]
Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages=
Position-aware Attention and Supervised Data Improve Slot Filling , author=. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages=
2017
-
[45]
Proceedings of the 5th International Workshop on Semantic Evaluation , pages=
Hendrickx, Iris and Kim, Su Nam and Kozareva, Zornitsa and Nakov, Preslav and. Proceedings of the 5th International Workshop on Semantic Evaluation , pages=
-
[46]
Journal of Machine Learning Research , volume=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. Journal of Machine Learning Research , volume=
-
[50]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
arXiv preprint , year=
Multi-hop Relation Extraction with Chain-of-Thought Prompting , author=. arXiv preprint , year=
-
[54]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year=
Large Language Model Is Not a Good Few-Shot Information Extractor, but a Good Reranker for Hard Samples! , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , year=
2023
-
[56]
Schwartz, Roy and Dodge, Jesse and Smith, Noah A and Etzioni, Oren , journal=. Green
-
[57]
arXiv preprint , year=
Inference Energy Consumption of Large Language Models , author=. arXiv preprint , year=
-
[58]
arXiv preprint , year=
Power Consumption Benchmarks for Small Language Models , author=. arXiv preprint , year=
-
[59]
arXiv preprint , year=
Multilingual Evaluation of Large Language Models for Relation Extraction , author=. arXiv preprint , year=
-
[60]
Efeoglu, Sefika and Paschke, Adrian , booktitle=
-
[61]
Efeoglu, Sefika and Paschke, Adrian , journal=
-
[62]
Jiao, Xiaoqi and Yin, Yichun and Shang, Lifeng and Jiang, Xin and Chen, Xiao and Li, Linlin and Wang, Fang and Liu, Qun , journal=
-
[63]
arXiv preprint , year=
Small Models Approaching Large: How Far Can Small Language Models Go? , author=. arXiv preprint , year=
-
[64]
Zhang, Peiyuan and Zeng, Guangtao and Wang, Tianduo and Lu, Wei , journal=
-
[67]
Liu, Zechun and Zhao, Changlin and Iandola, Forrest and Lai, Chen and Tian, Yuandong and Fedorov, Igor and Xiong, Yunyang and Chang, Ernie and Shi, Yangyang and Krishnamoorthi, Raghuraman and others , journal=
-
[68]
Parameter-Efficient Transfer Learning for
Houlsby, Neil and Giampiccolo, Danilo and Jastrzebski, Stanislaw and Morber, Bruna and Ranzato, Marc'Aurelio and Ganguli, Deep and Borgeaud, Sebastian , booktitle=. Parameter-Efficient Transfer Learning for
-
[69]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
-
[70]
arXiv preprint , year=
Parameter-Efficient Fine-Tuning for Information Extraction: A Survey , author=. arXiv preprint , year=
-
[71]
arXiv preprint , year=
Small Language Models vs Large Language Models: A Comprehensive Survey , author=. arXiv preprint , year=
-
[72]
arXiv preprint , year=
Encoder-Based Models for Named Entity Recognition and Relation Extraction , author=. arXiv preprint , year=
-
[73]
International Journal of Computer Vision , volume=
A Survey of Quantization Methods for Efficient Neural Network Inference , author=. International Journal of Computer Vision , volume=
-
[74]
arXiv preprint , year=
A Comprehensive Survey on Quantization for Large Language Models , author=. arXiv preprint , year=
-
[75]
arXiv preprint , year=
A Survey on Quantization and Compression for Large Language Models , author=. arXiv preprint , year=
-
[76]
Liu, Zhiyuan and others , journal=
-
[77]
arXiv preprint , year=
Outlier Channels in Small Language Models and Their Impact on Quantization , author=. arXiv preprint , year=
-
[79]
arXiv preprint , year=
Mixed-Precision Quantization for Large Language Models , author=. arXiv preprint , year=
-
[80]
Frantar, Elias and Alistarh, Dan , booktitle=
-
[81]
arXiv preprint , year=
Pruning for Small Language Models , author=. arXiv preprint , year=
-
[82]
Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP , pages=
Distant Supervision for Relation Extraction without Labeled Data , author=. Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP , pages=
-
[83]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Neural Relation Extraction with Selective Attention over Instances , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[84]
Xu, Yifan and others , journal=
-
[85]
arXiv preprint , year=
Synthetic Data for Clinical Information Extraction , author=. arXiv preprint , year=
-
[86]
arXiv preprint , year=
Synthetic Data Generation for Relation Extraction , author=. arXiv preprint , year=
-
[87]
arXiv preprint , year=
Improving Synthetic Data Diversity with Direct Preference Optimization , author=. arXiv preprint , year=
-
[88]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[89]
Beltagy, Iz and Lo, Kyle and Cohan, Arman , booktitle=
-
[90]
Lee, Jinhyuk and Yoon, Wonjin and Kim, Sungdong and Kim, Donghyeon and Kim, Sunkyu and So, Chan Ho and Kang, Jaewoo , journal=
-
[91]
Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics , pages=
Extracting Social Networks from Literary Fiction , author=. Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics , pages=
-
[92]
Bamman, David and Underwood, Ted and Smith, Noah A , booktitle=. A
-
[93]
Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence , pages=
Modeling Evolving Relationships Between Characters in Literary Novels , author=. Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence , pages=
-
[94]
Proceedings of the Workshop on Natural Language Processing for Digital Humanities , year=
Named Entity Recognition and Relation Extraction on Fiction , author=. Proceedings of the Workshop on Natural Language Processing for Digital Humanities , year=
-
[95]
Proceedings of the 2021 Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL) , year=
Extracting Character Relationships from Literary Texts , author=. Proceedings of the 2021 Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL) , year=
2021
-
[96]
arXiv preprint , year=
Implicit Relation Discovery in Literary Texts , author=. arXiv preprint , year=
-
[97]
arXiv preprint , year=
Quotation Attribution for Literary Texts , author=. arXiv preprint , year=
-
[98]
arXiv preprint , year=
Graphical Reasoning for Relation Extraction , author=. arXiv preprint , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.