A Fiber Criterion for Representation Identifiability in Supervised Learning
Pith reviewed 2026-06-28 17:40 UTC · model grok-4.3
The pith
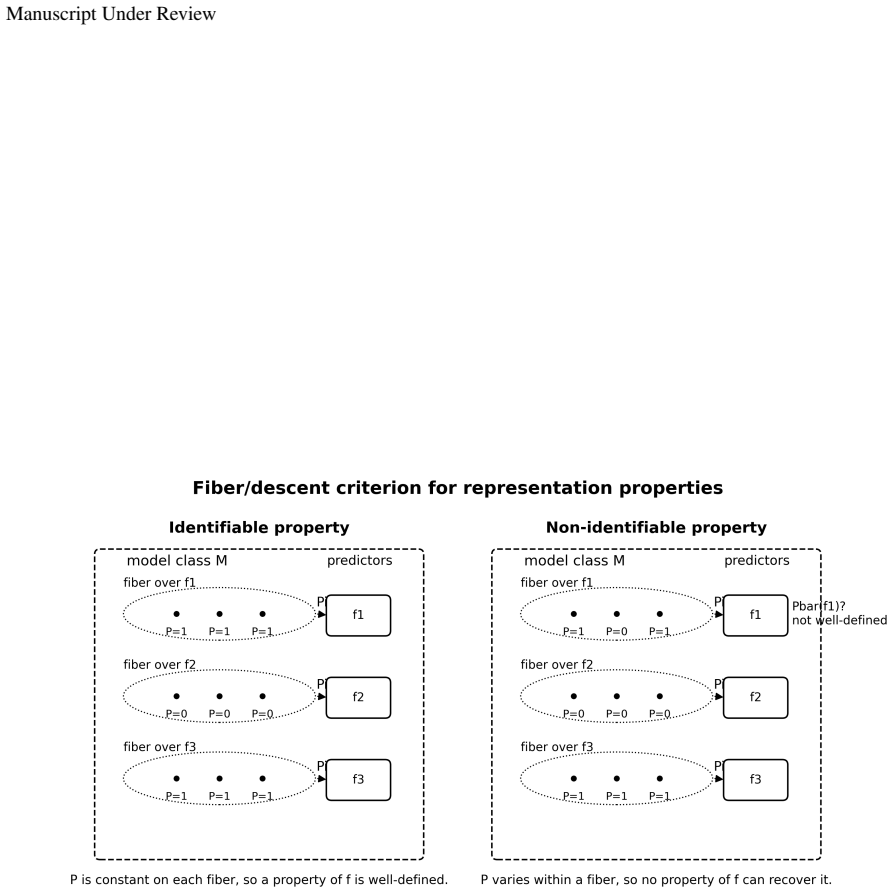
A representation property is identifiable from the induced predictor exactly when it is constant on the fibers of the projection from representation-head pairs to the composite map.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
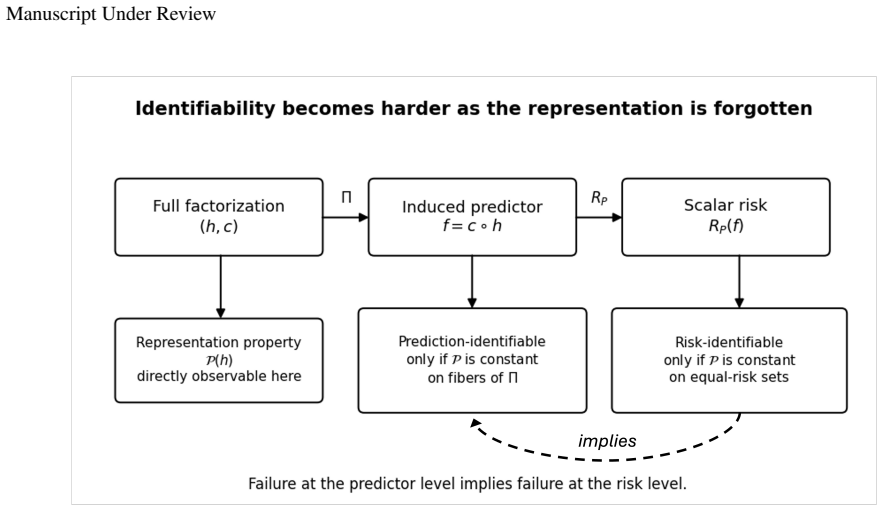
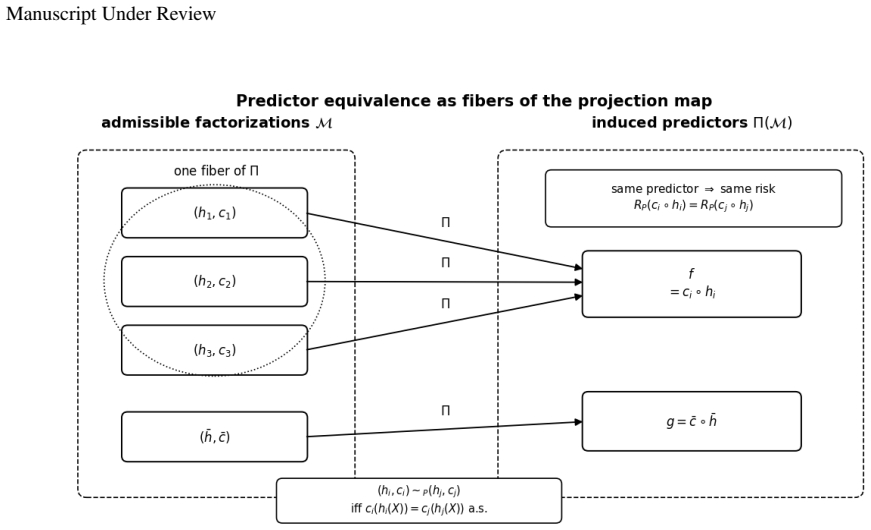
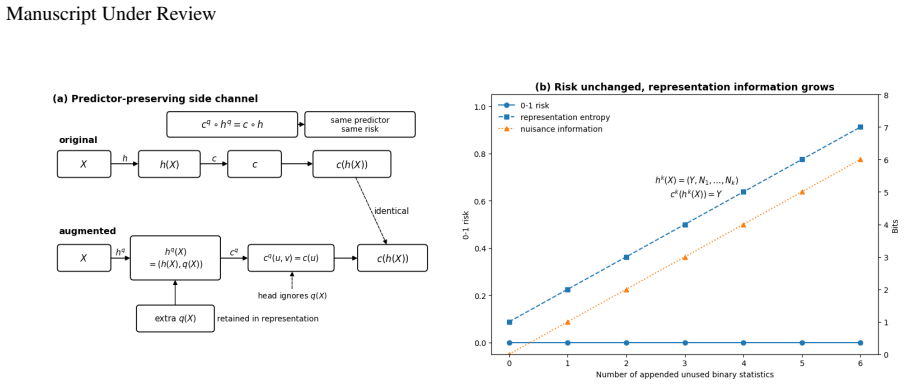
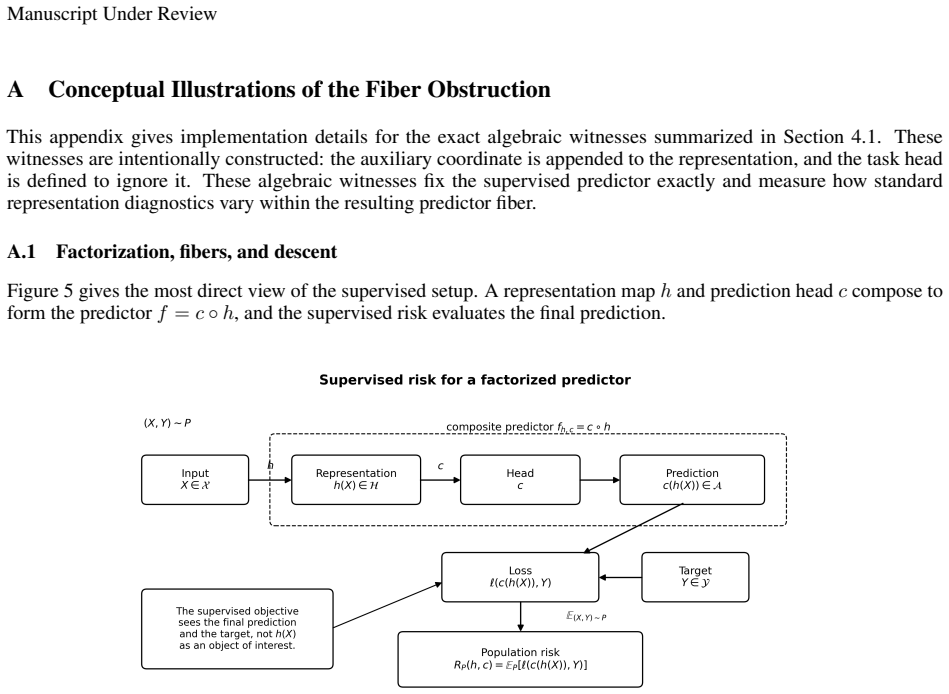
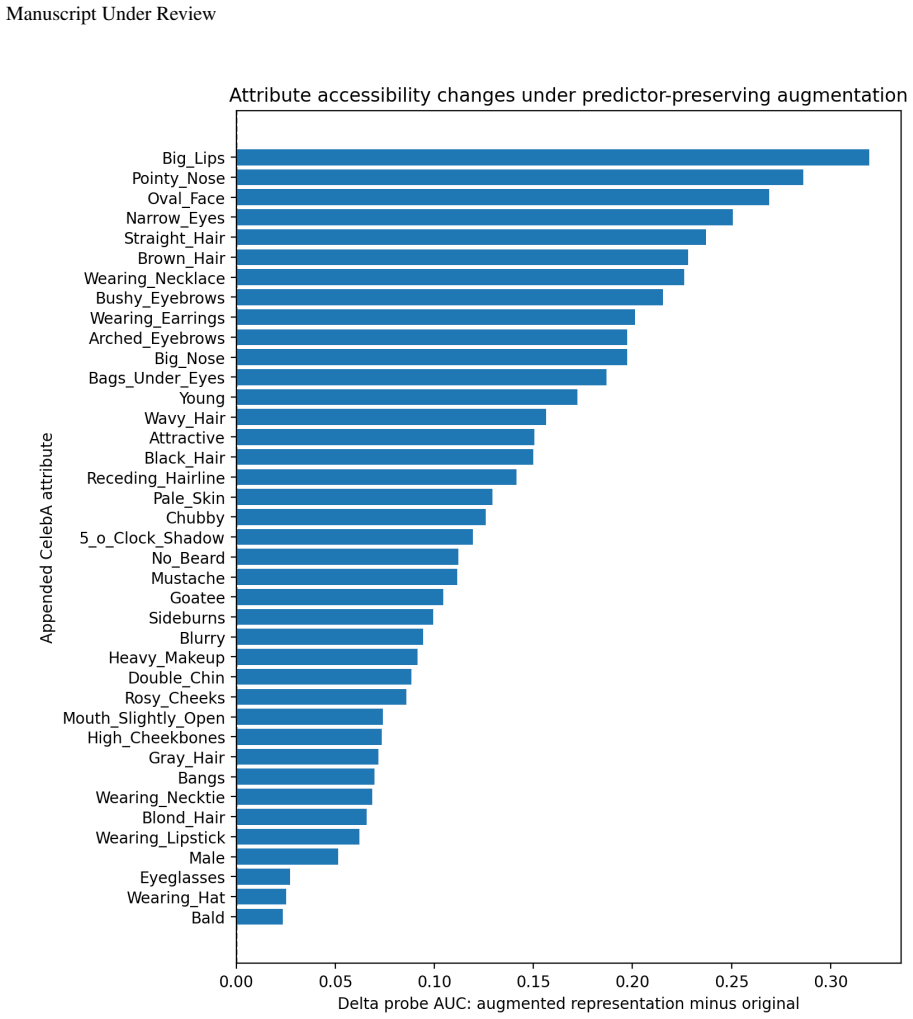
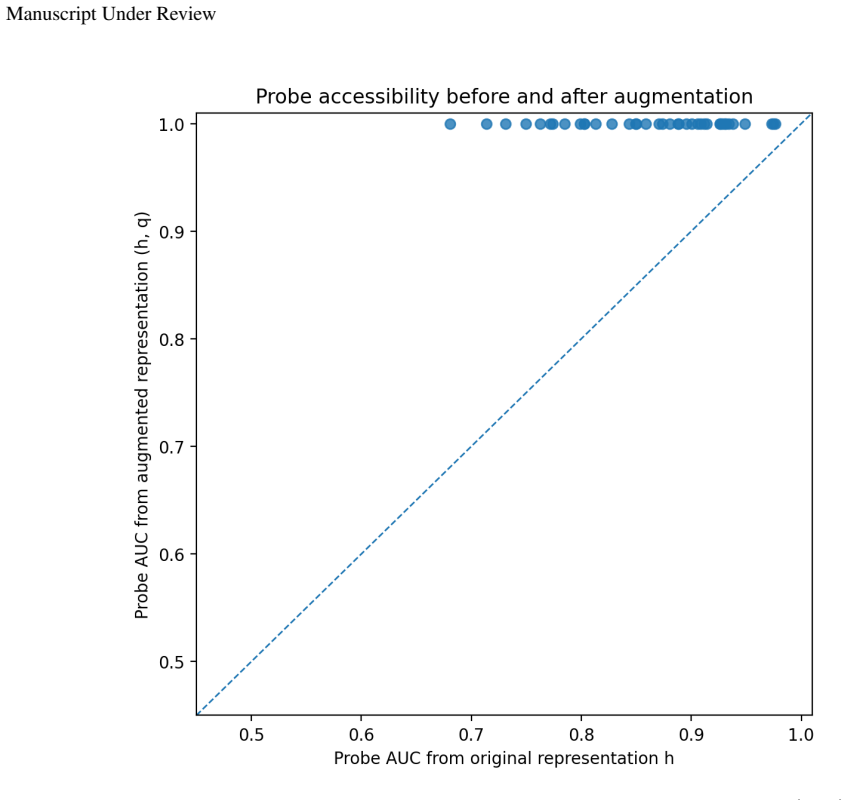
For a fixed class of admissible representation-head pairs, a representation property is identifiable from the induced predictor exactly when it is constant on the fibers of the projection (h,c)↦c∘h, equivalently when it descends to a well-defined property of the predictor. Predictor-preserving augmentation gives a canonical obstruction by appending auxiliary information to a representation while the head ignores it, leaving the predictor unchanged but altering properties such as minimality, compression, invariance, equivariance, nuisance information, or semantic accessibility.
What carries the argument
The fibers of the projection map (h,c)↦c∘h, which collect all admissible factorizations that induce identical predictors.
If this is right
- Predictor-preserving augmentation can change minimality, invariance, or semantic accessibility while the observed predictor stays identical.
- Representation-level claims in supervised settings always require modeling assumptions, objectives, or inductive biases beyond input-output behavior.
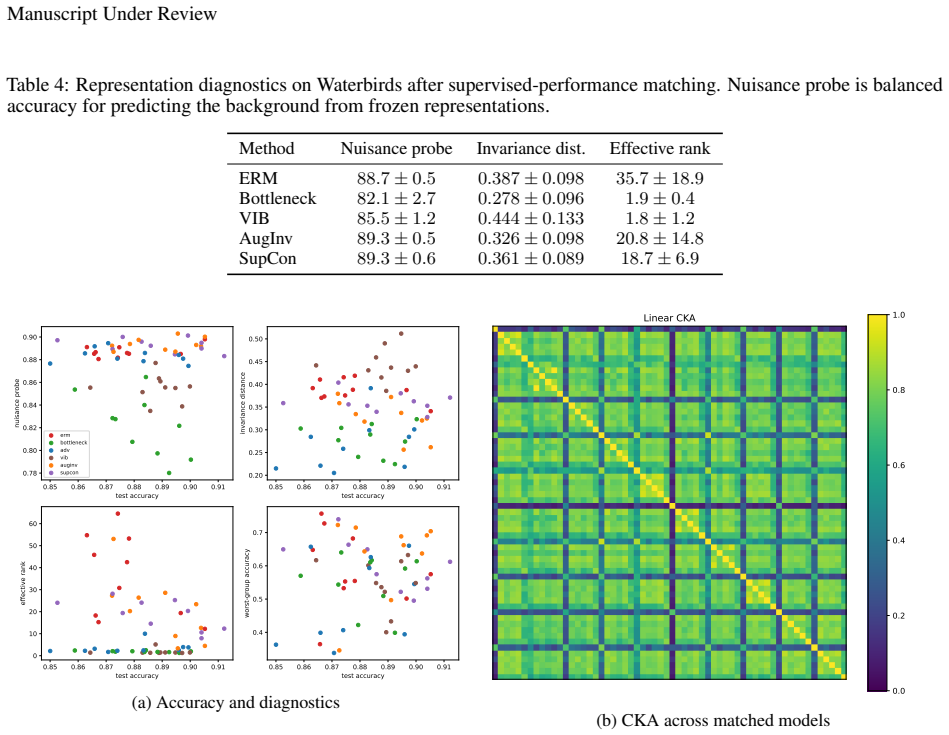
- Finite-sample diagnostics can exhibit different representations selected by different constraints even when supervised performance matches.
- Identifiability statements are relative to the chosen class of admissible pairs rather than intrinsic to the data.
Where Pith is reading between the lines
- Any claim that a learned representation is minimal or invariant must be accompanied by an explicit statement of the admissible class of heads.
- The fiber view suggests examining whether common regularizers in deep networks implicitly restrict the class enough to restore identifiability.
- The same obstruction applies to claims about disentanglement or compression that rest solely on predictive performance.
Load-bearing premise
The argument requires a fixed, explicitly stated class of admissible representation-head pairs over which the fibers are taken.
What would settle it
A concrete property of representations that varies across different (h,c) pairs producing the same predictor yet remains recoverable from supervised data alone on that class would falsify the claimed equivalence.
Figures
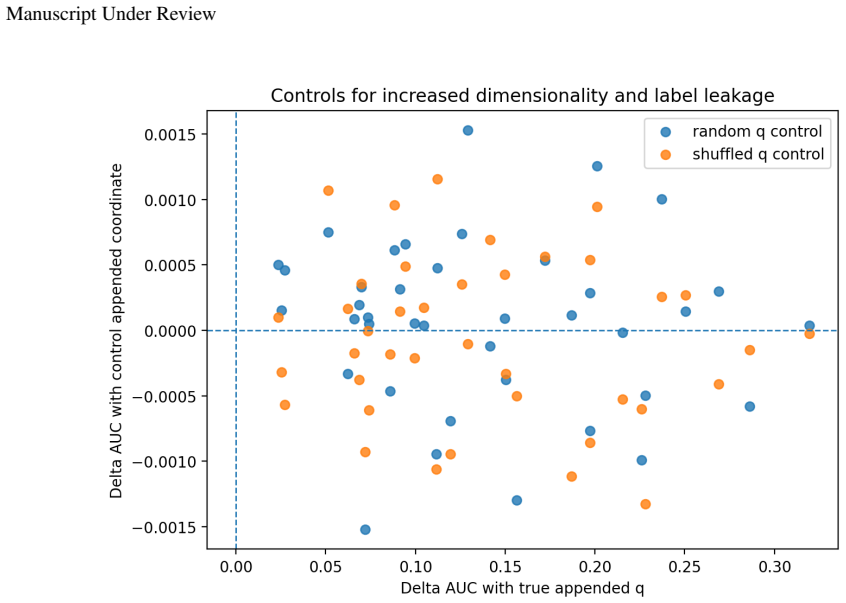
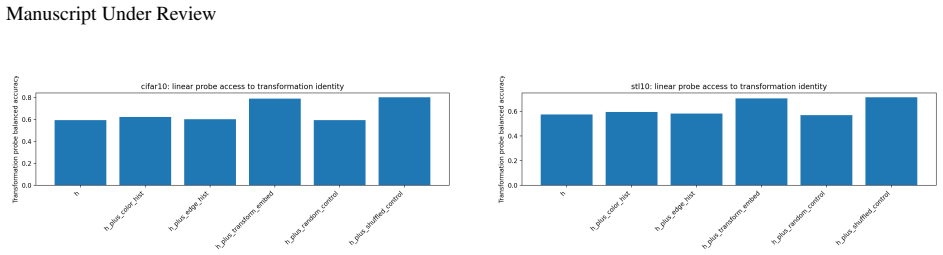
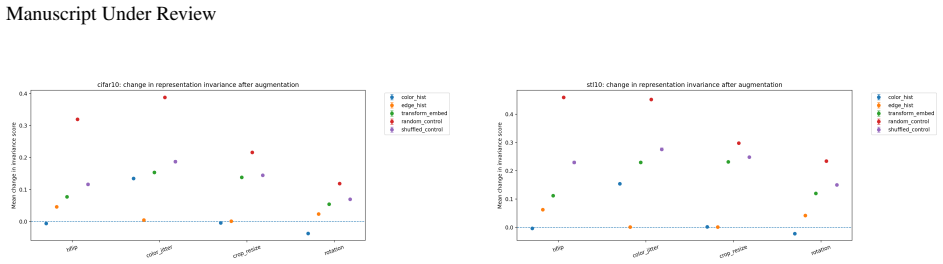

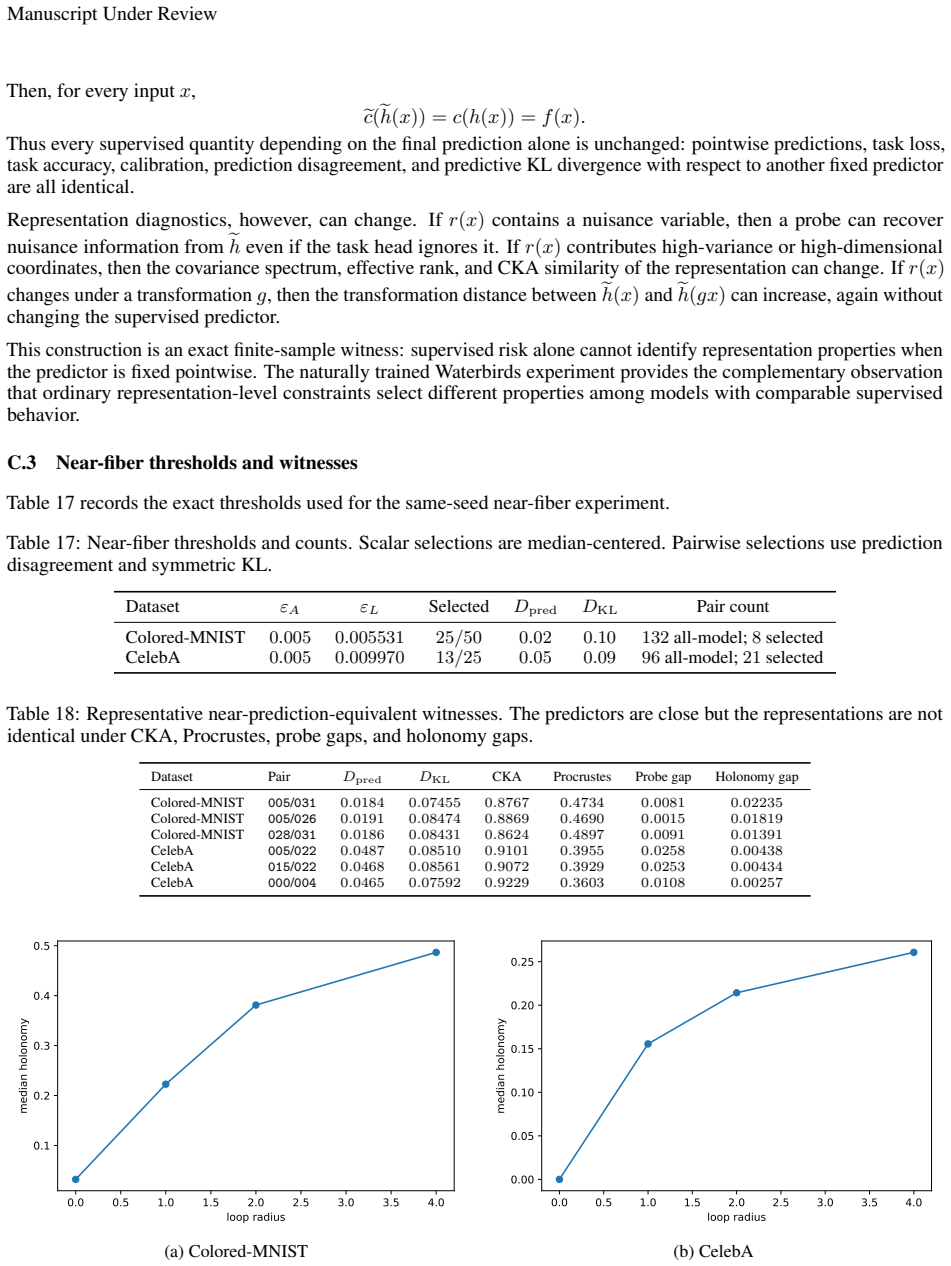
read the original abstract
Supervised learning evaluates predictors through their input-output behavior. When a predictor is implemented as a composition $f=c\circ h$, supervised evidence constrains the composite map $f$ but need not determine the representation-head factorization $(h,c)$. This paper formalizes the resulting representation-level identifiability problem: for a class of admissible representation-head pairs, a representation property is identifiable from the induced predictor exactly when it is constant on the fibers of the projection $(h,c)\mapsto c\circ h$, equivalently when it descends to a well-defined property of the predictor. Predictor-preserving augmentation gives a canonical obstruction: auxiliary information can be appended to a representation while the head ignores it, leaving the predictor unchanged but altering properties such as minimality, compression, invariance, equivariance, nuisance information, or semantic accessibility. This construction separates representation identifiability from optimization and finite-sample estimation. Finite-sample diagnostics illustrate, rather than prove, the criterion: exact algebraic witnesses hold the predictor fixed while changing representation diagnostics, and matched-performance Waterbirds models show that different constraints can select different representations at similar supervised performance. The results clarify that representation-level claims require assumptions, objectives, measurements, or inductive biases beyond supervised predictive behavior alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that, for any fixed class of admissible representation-head pairs (h, c), a representation property is identifiable from the induced predictor f = c ∘ h exactly when the property is constant on the fibers of the projection (h, c) ↦ f (equivalently, when it descends to a well-defined property of the predictor). It introduces predictor-preserving augmentation as a canonical obstruction that alters representation properties while leaving f unchanged, and uses finite-sample diagnostics (algebraic witnesses and matched-performance Waterbirds models) to illustrate that supervised evidence alone does not determine representation-level properties without further assumptions.
Significance. If the formalization holds, the fiber criterion supplies a precise, relative-to-the-class language for the well-known gap between predictor behavior and representation properties, cleanly separating identifiability questions from optimization and finite-sample estimation. The explicit framing that supervised evidence is insufficient without additional biases or measurements is consistent with the definitional result and may help organize future work on representation learning.
major comments (2)
- [fiber criterion definition (abstract and § on identifiability problem)] The central equivalence (property identifiable iff constant on fibers) is presented as a formal criterion but follows immediately from the definition of identifiability relative to the chosen class of pairs; the manuscript does not derive additional consequences or bounds that would make the statement non-tautological. This does not invalidate the framing but limits the load-bearing technical contribution to the augmentation construction and examples.
- [framework setup and conclusion] The admissible class of (h, c) pairs is treated as fixed and given, yet the paper provides no general procedure or verification method for constructing or validating this class from data or domain knowledge; without such a procedure the identifiability statement remains relative to an arbitrary modeling choice, as noted in the weakest-assumption discussion.
minor comments (2)
- [finite-sample examples] The finite-sample diagnostics (Waterbirds and algebraic witnesses) are described as illustrative rather than exhaustive; adding a brief statement on the scope of the enumeration performed would clarify their role.
- [main formal statement] Notation for the projection map and fibers is introduced clearly in the abstract but could be repeated with an explicit equation number in the main text for easier reference.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for recommending minor revision. The comments correctly identify that the central equivalence is definitional and that the admissible class is a modeling choice; we address each point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [fiber criterion definition (abstract and § on identifiability problem)] The central equivalence (property identifiable iff constant on fibers) is presented as a formal criterion but follows immediately from the definition of identifiability relative to the chosen class of pairs; the manuscript does not derive additional consequences or bounds that would make the statement non-tautological. This does not invalidate the framing but limits the load-bearing technical contribution to the augmentation construction and examples.
Authors: We agree that the equivalence follows directly from the definition of identifiability relative to a fixed class. The manuscript frames the statement as a criterion to supply a precise, relative-to-the-class test that can be applied to concrete properties (minimality, invariance, etc.). The load-bearing technical element is indeed the predictor-preserving augmentation construction, which supplies a canonical obstruction and separates representation identifiability from optimization and estimation questions. We will add a short clarifying sentence in the introduction to make the definitional character explicit while preserving the criterion language for its diagnostic utility. revision: partial
-
Referee: [framework setup and conclusion] The admissible class of (h, c) pairs is treated as fixed and given, yet the paper provides no general procedure or verification method for constructing or validating this class from data or domain knowledge; without such a procedure the identifiability statement remains relative to an arbitrary modeling choice, as noted in the weakest-assumption discussion.
Authors: The admissible class is deliberately treated as a fixed modeling primitive that encodes domain assumptions about admissible factorizations. The weakest-assumption discussion already states that identifiability claims are always relative to this choice and that no data-driven procedure can validate the class without introducing further assumptions. Because the class is part of the modeling setup rather than an object to be inferred, the paper does not supply a general construction method; this relativity is intentional and is not presented as a shortcoming. revision: no
Circularity Check
No significant circularity identified
full rationale
The paper formalizes representation identifiability relative to a fixed class of admissible (h,c) pairs as the property being constant on fibers of the projection (h,c) ↦ c∘h. This equivalence is definitional by construction of the identifiability notion itself and does not reduce any derived claim to fitted parameters, self-citations, or smuggled ansatzes. The predictor-preserving augmentation and finite-sample examples (Waterbirds, algebraic witnesses) illustrate the criterion without circular reduction. The framework is self-contained, explicitly conditioning results on the modeling choice of class rather than claiming intrinsic uniqueness or external derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption There exists a class of admissible representation-head pairs over which the projection map is defined.
- standard math Properties of representations that are constant on fibers descend to well-defined properties of the predictor.
Reference graph
Works this paper leans on
-
[1]
On the mathematical foundations of theoretical statistics,
On the Mathematical Foundations of Theoretical Statistics , author =. Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character , volume =. 1922 , publisher =. doi:10.1098/rsta.1922.0009 , url =
-
[2]
IEEE transactions on pattern analysis and machine intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
2013
-
[3]
arXiv preprint physics/0004057 , year=
The information bottleneck method , author=. arXiv preprint physics/0004057 , year=
-
[4]
International Conference on Learning Representations , year=
Deep Variational Information Bottleneck , author=. International Conference on Learning Representations , year=
-
[5]
Journal of Machine Learning Research , volume=
Emergence of Invariance and Disentanglement in Deep Representations , author=. Journal of Machine Learning Research , volume=. 2018 , url=
2018
-
[6]
IEEE transactions on pattern analysis and machine intelligence , volume=
Information dropout: Learning optimal representations through noisy computation , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2018 , publisher=
2018
-
[7]
Domain-Adversarial Training of Neural Networks , journal =
Yaroslav Ganin and Evgeniya Ustinova and Hana Ajakan and Pascal Germain and Hugo Larochelle and Fran. Domain-Adversarial Training of Neural Networks , journal =. 2016 , volume =
2016
-
[8]
2020 , eprint=
Invariant Risk Minimization , author=. 2020 , eprint=
2020
-
[9]
Proceedings of the 37th International Conference on Machine Learning , pages =
Invariant Risk Minimization Games , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[10]
Proceedings of the 38th International Conference on Machine Learning , pages =
Out-of-Distribution Generalization via Risk Extrapolation (REx) , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[11]
Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =
Does Invariant Risk Minimization Capture Invariance? , author =. Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =. 2021 , editor =
2021
-
[12]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Group Equivariant Convolutional Networks , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
2016
-
[13]
arXiv preprint arXiv:2104.13478 , year=
Geometric deep learning: Grids, groups, graphs, geodesics, and gauges , author=. arXiv preprint arXiv:2104.13478 , year=
-
[14]
Proceedings of the 37th International Conference on Machine Learning , pages=
A Simple Framework for Contrastive Learning of Visual Representations , author=. Proceedings of the 37th International Conference on Machine Learning , pages=. 2020 , series=
2020
-
[15]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[16]
Advances in neural information processing systems , volume=
Bootstrap your own latent-a new approach to self-supervised learning , author=. Advances in neural information processing systems , volume=
-
[17]
Irina Higgins and Loic Matthey and Arka Pal and Christopher Burgess and Xavier Glorot and Matthew Botvinick and Shakir Mohamed and Alexander Lerchner , booktitle=. beta-. 2017 , url=
2017
-
[18]
Proceedings of the 35th International Conference on Machine Learning , pages =
Disentangling by Factorising , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[19]
Proceedings of the 36th International Conference on Machine Learning , pages =
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[20]
Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics , pages =
Nonlinear ICA Using Auxiliary Variables and Generalized Contrastive Learning , author =. Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics , pages =. 2019 , editor =
2019
-
[21]
Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =
Variational Autoencoders and Nonlinear ICA: A Unifying Framework , author =. Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , pages =. 2020 , editor =
2020
-
[22]
2017 , url=
Understanding intermediate layers using linear classifier probes , author=. 2017 , url=
2017
-
[23]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D
Hewitt, John and Liang, Percy. Designing and Interpreting Probes with Control Tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1275
-
[24]
Probing Classifiers: Promises, Shortcomings, and Advances
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics. 2022. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Invariant information bottleneck for domain generalization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[26]
Proceedings of the IEEE , volume=
Toward causal representation learning , author=. Proceedings of the IEEE , volume=. 2021 , publisher=
2021
-
[27]
Advances in neural information processing systems , volume=
Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability , author=. Advances in neural information processing systems , volume=
-
[28]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[29]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[30]
International Conference on Learning Representations , year=
Distributionally Robust Neural Networks , author=. International Conference on Learning Representations , year=
-
[31]
Proceedings of the 38th International Conference on Machine Learning , pages =
On Linear Identifiability of Learned Representations , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[32]
ACM Computing Surveys , volume=
Similarity of neural network models: A survey of functional and representational measures , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[33]
2015 ieee information theory workshop (itw) , pages=
Deep learning and the information bottleneck principle , author=. 2015 ieee information theory workshop (itw) , pages=. 2015 , organization=
2015
-
[34]
International conference on machine learning , pages=
Disentangling by factorising , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[35]
arXiv preprint arXiv:1611.03530 , year=
Understanding deep learning requires rethinking generalization , author=. arXiv preprint arXiv:1611.03530 , year=
-
[36]
2013 , publisher=
Statistical decision theory and Bayesian analysis , author=. 2013 , publisher=
2013
-
[37]
2008 , publisher=
Statistical Decision Theory: Estimation, Testing, and Selection , author=. 2008 , publisher=
2008
-
[38]
Journal of the Italian Statistical Society , volume=
On identifiability of parametric statistical models , author=. Journal of the Italian Statistical Society , volume=. 1994 , publisher=
1994
-
[39]
Model Identifiability , booktitle =
Huang, Guan-Hua , publisher =. Model Identifiability , booktitle =. doi:https://doi.org/10.1002/9781118445112.stat06411.pub2 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/9781118445112.stat06411.pub2 , year =
-
[40]
arXiv preprint arXiv:2002.06041 , year=
A general theory of identification , author=. arXiv preprint arXiv:2002.06041 , year=
arXiv 2002
-
[41]
Journal of Statistical Mechanics: Theory and Experiment , volume=
On the information bottleneck theory of deep learning , author=. Journal of Statistical Mechanics: Theory and Experiment , volume=. 2019 , publisher=
2019
-
[42]
Causal Inference by using Invariant Prediction: Identification and Confidence Intervals , journal =
Peters, Jonas and B. Causal Inference by using Invariant Prediction: Identification and Confidence Intervals , journal =. 2016 , month =. doi:10.1111/rssb.12167 , url =
-
[43]
1998 , publisher=
Theory of point estimation , author=. 1998 , publisher=
1998
-
[44]
Regression Graphics: Ideas for Studying Regressions through Graphics , author=
-
[45]
International Conference on Machine Learning , pages=
Train Faster, Generalize Better: Stability of Stochastic Gradient Descent , author=. International Conference on Machine Learning , pages=
-
[46]
Advances in neural information processing systems , volume=
Exploring generalization in deep learning , author=. Advances in neural information processing systems , volume=
-
[47]
Journal of Machine Learning Research , volume=
The Implicit Bias of Gradient Descent on Separable Data , author=. Journal of Machine Learning Research , volume=
-
[48]
The Fourteenth International Conference on Learning Representations , year=
Gauge-invariant representation holonomy , author=. The Fourteenth International Conference on Learning Representations , year=
-
[49]
2026 , eprint=
Training Memory in Deep Neural Networks: Mechanisms, Evidence, and Measurement Gaps , author=. 2026 , eprint=
2026
-
[50]
The Fourteenth International Conference on Learning Representations , year =
Statistical and Structural Identifiability in Representation Learning , author =. The Fourteenth International Conference on Learning Representations , year =
-
[51]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =
Conditional Probing: Measuring Usable Information Beyond a Baseline , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =. 2021 , publisher =
2021
-
[52]
Advances in Neural Information Processing Systems , volume =
Improving Self-Supervised Learning by Characterizing Idealized Representations , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[53]
Journal of Machine Learning Research , volume =
Underspecification Presents Challenges for Credibility in Modern Machine Learning , author =. Journal of Machine Learning Research , volume =. 2022 , url =
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.