LangMAP: A Language-Adaptive Approach to Tokenization
Pith reviewed 2026-06-26 08:24 UTC · model grok-4.3
The pith
LangMAP extends UnigramLM to produce language-specific tokenization from a single shared vocabulary, improving boundary alignment across languages without language identifiers at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
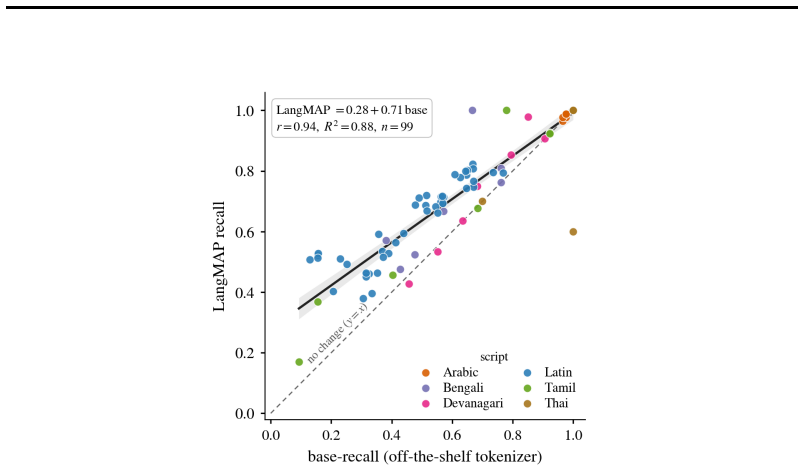
LangMAP Tokenization extends the UnigramLM algorithm to the multilingual setting, producing language-specific tokenization from a single shared vocabulary. Language labels are used only at training time, after which the method performs language-specific segmentation at inference without knowledge of the input language. Across multiple tokenizers and languages, it improves alignment with morphological boundaries and, for coding languages, with abstract syntax tree leaf boundaries.
What carries the argument
Language-adaptive Maximum a Posteriori (LangMAP) Tokenization, which modifies UnigramLM to use language-specific posterior probabilities during training for shared-vocabulary multilingual tokenization.
If this is right
- Improves morphological boundary alignment for 9 natural languages across 14 tokenizers.
- Improves alignment with AST leaf boundaries for all 9 programming languages tested.
- Can be used to adapt a pretrained model's tokenizer to languages without changing the vocabulary.
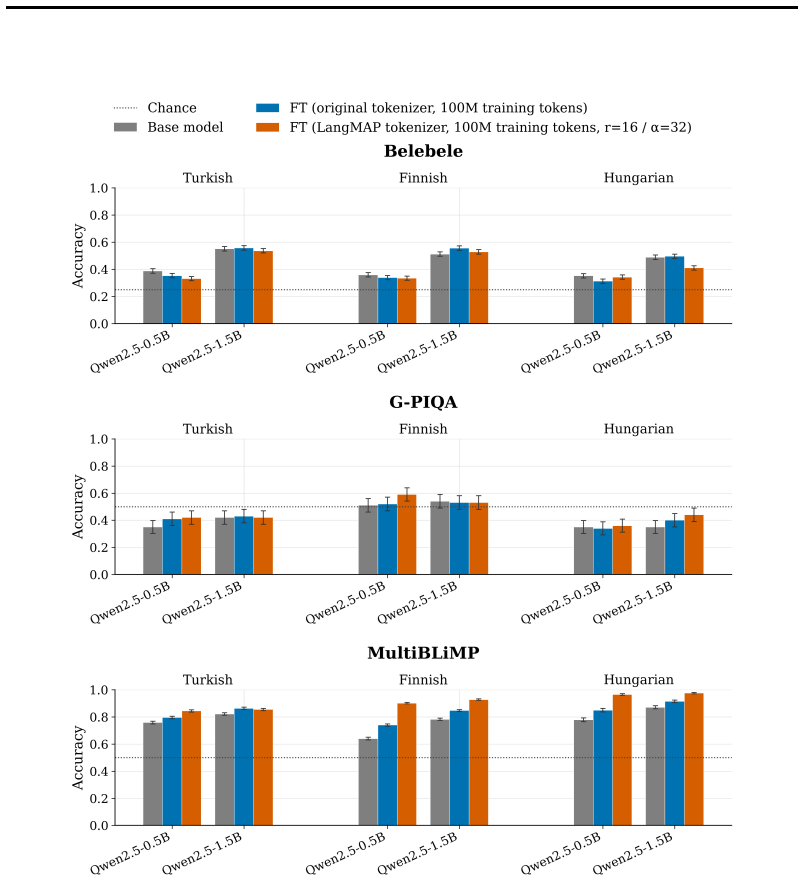
- Improves grammatical acceptability on target languages in fine-tuning experiments.
Where Pith is reading between the lines
- Models using LangMAP tokenization might achieve better performance on language-specific tasks without needing language-specific models.
- Extending this to more languages or tasks could reveal whether the alignment improvements translate to consistent gains in downstream performance.
Load-bearing premise
Language labels provided only during training are enough to learn segmentation rules that stay language-specific at inference time without any language information.
What would settle it
An experiment showing that LangMAP tokenization does not produce higher alignment scores with morphological or AST boundaries than standard UnigramLM on the same languages and data.
Figures

read the original abstract
Language-specific tokenizers improve tokenization quality and the downstream performance of models on those languages. However, using such a tokenizer comes at a cost: either a new model must be trained from scratch, or the vocabulary of an existing pretrained model must be adapted. We propose Language-adaptive Maximum a Posteriori (LangMAP) Tokenization, a tokenization scheme that extends the UnigramLM algorithm to the multilingual setting, producing language-specific tokenization from a single shared vocabulary. Notably, LangMAP can be used when training a multilingual language model from scratch or to adapt a pretrained model's tokenizer to individual languages without changing its vocabulary. While language labels are required at training time, a key feature of the algorithm is that it then performs language-specific tokenization at inference without knowledge of the input's language. Across 14 open-source tokenizers, 9 natural languages, and 9 programming languages, LangMAP improves morphological boundary alignment and, for all coding languages tested, alignment with abstract syntax tree (AST) leaf boundaries. In fine-tuning experiments, results are mixed: LangMAP improves target-language grammatical acceptability (MultiBLiMP) on the languages tested; its benefits are less consistent on knowledge-related tasks (Global-PIQA, Belebele).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LangMAP, an extension of the UnigramLM tokenization algorithm to the multilingual setting via language-adaptive maximum a posteriori estimation. This allows training a single shared vocabulary using language labels that then enables language-specific segmentation at inference time without any language identifier. The authors evaluate this on morphological boundary alignment for 9 natural languages and AST leaf boundary alignment for coding languages, claiming improvements over 14 open-source tokenizers. Downstream fine-tuning shows gains on grammatical acceptability tasks but mixed outcomes on knowledge-related tasks.
Significance. Should the central claims be verified, this work would represent a meaningful advance in multilingual tokenization by reducing the need for language-specific models or vocabulary adaptations. The approach maintains a single vocabulary while achieving adaptive behavior, which could streamline multilingual model development. The extensive evaluation across numerous tokenizers and languages provides a solid basis for assessing generalizability, although the mixed fine-tuning results indicate that benefits may vary by task type. The lack of new free parameters is a positive aspect of the derivation.
major comments (2)
- [Abstract] Abstract: The claim that language labels supplied only at training time suffice for language-specific segmentation at inference without any language identifier is load-bearing for the central contribution. The description provides no mechanism details on how the language-adaptive MAP estimation encodes distinct language modes in the shared probability distributions such that Viterbi segmentation reliably selects language-appropriate boundaries rather than a compromise solution.
- [Fine-tuning experiments] Fine-tuning experiments: The reported mixed results (improvement on MultiBLiMP but less consistent on Global-PIQA and Belebele) weaken the downstream performance claim. Without statistical tests, data split details, or controls for post-hoc choices, it is not possible to determine whether the alignment gains translate to reliable task improvements.
minor comments (1)
- The abstract would benefit from explicitly stating the total number of languages (9 natural + 9 programming) and confirming whether the 14 tokenizers include both natural and code variants.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that language labels supplied only at training time suffice for language-specific segmentation at inference without any language identifier is load-bearing for the central contribution. The description provides no mechanism details on how the language-adaptive MAP estimation encodes distinct language modes in the shared probability distributions such that Viterbi segmentation reliably selects language-appropriate boundaries rather than a compromise solution.
Authors: We agree that the mechanism requires clearer exposition. LangMAP performs language-conditioned MAP estimation during training: for each language, the posterior over token probabilities is updated using language-specific data likelihoods while sharing the vocabulary across languages. This produces a single set of token scores in which language-specific segmentation preferences are embedded as higher probabilities for language-appropriate subwords. At inference, standard Viterbi decoding on these scores selects boundaries that empirically match language-specific patterns without an explicit language ID, as the optimization avoids compromise solutions by construction. We will revise the abstract to include a concise statement of this process and add a dedicated paragraph in Section 3 explaining the encoding of language modes. revision: yes
-
Referee: [Fine-tuning experiments] Fine-tuning experiments: The reported mixed results (improvement on MultiBLiMP but less consistent on Global-PIQA and Belebele) weaken the downstream performance claim. Without statistical tests, data split details, or controls for post-hoc choices, it is not possible to determine whether the alignment gains translate to reliable task improvements.
Authors: The referee correctly identifies that the mixed downstream results and lack of statistical reporting limit the strength of any performance claims. The primary contribution of the work is the tokenization alignment improvements, which are consistent across languages and tokenizers; downstream fine-tuning serves as a secondary evaluation. We will revise the fine-tuning section to add statistical significance tests, specify data splits and random seeds, include controls for post-hoc analysis, and rephrase claims to accurately reflect task-dependent variability rather than implying broad gains. revision: yes
Circularity Check
No significant circularity in LangMAP derivation
full rationale
The paper presents LangMAP as an algorithmic extension of the established UnigramLM tokenization method, incorporating language labels solely during training to produce a shared vocabulary whose inference-time segmentation (via Viterbi or equivalent) yields language-specific boundaries without explicit language IDs. All reported gains are measured on external, independent benchmarks: morphological boundary alignment across 14 tokenizers and 9 languages, AST leaf alignment for code, and downstream task performance on MultiBLiMP, Global-PIQA, and Belebele. No derivation step equates a claimed output to a fitted parameter or self-citation by construction; the central inference behavior is an empirical property of the learned model rather than a definitional tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
2026 , eprint=
What Language is This? Ask Your Tokenizer , author=. 2026 , eprint=
2026
-
[10]
Whittington, Philip and Bachmann, Gregor and Pimentel, Tiago. Tokenisation is NP -Complete. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1365
-
[11]
The Fourteenth International Conference on Learning Representations , year=
Tokenisation over Bounded Alphabets is Hard , author=. The Fourteenth International Conference on Learning Representations , year=
-
[12]
Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
Kudo, Taku. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1007
-
[13]
Schmidt, Varshini Reddy, Haoran Zhang, Alec Alameddine, Omri Uzan, Yuval Pinter, and Chris Tanner
Schmidt, Craig W and Reddy, Varshini and Zhang, Haoran and Alameddine, Alec and Uzan, Omri and Pinter, Yuval and Tanner, Chris. Tokenization Is More Than Compression. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.40
-
[14]
Hofmann, Valentin and Schuetze, Hinrich and Pierrehumbert, Janet. An Embarrassingly Simple Method to Mitigate Undesirable Properties of Pretrained Language Model Tokenizers. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022. doi:10.18653/v1/2022.acl-short.43
-
[15]
Unpacking Tokenization: Evaluating Text Compression and its Correlation with Model Performance
Goldman, Omer and Caciularu, Avi and Eyal, Matan and Cao, Kris and Szpektor, Idan and Tsarfaty, Reut. Unpacking Tokenization: Evaluating Text Compression and its Correlation with Model Performance. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.134
-
[16]
Neural machine translation of rare words with subword units
Neural Machine Translation of Rare Words with Subword Units , author =. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , publisher =. doi:10.18653/v1/P16-1162 , url =
-
[17]
Toraman, Cagri and Yilmaz, Eyup Halit and. Impact of Tokenization on Language Models: An Analysis for. ACM Trans. Asian Low-Resour. Lang. Inf. Process. , publisher =. doi:10.1145/3578707 , issn =
-
[18]
Rust, Phillip and Pfeiffer, Jonas and Vulić, Ivan and Ruder, Sebastian and Gurevych, Iryna , year = 2021, month = aug, booktitle =. How. doi:10.18653/v1/2021.acl-long.243 , url =
-
[19]
Muckley and Karen Ullrich , booktitle=
Buu Phan and Brandon Amos and Itai Gat and Marton Havasi and Matthew J. Muckley and Karen Ullrich , booktitle=. Exact Byte-Level Probabilities from Tokenized Language Models for. 2025 , url=
2025
-
[20]
An Analysis of Tokenization:
Nived Rajaraman and Jiantao Jiao and Kannan Ramchandran , booktitle=. An Analysis of Tokenization:. 2024 , url=
2024
-
[21]
Meister, Clara , year =
-
[22]
arXiv preprint arXiv:2601.07220 , year=
The Roots of Performance Disparity in Multilingual Language Models: Intrinsic Modeling Difficulty or Design Choices? , author=. arXiv preprint arXiv:2601.07220 , year=
-
[23]
A. P. Dempster and N. M. Laird and D. B. Rubin , journal =. Maximum Likelihood from Incomplete Data via the EM Algorithm , urldate =
-
[24]
and Della Pietra, Stephen A
Brown, Peter F. and Della Pietra, Stephen A. and Della Pietra, Vincent J. and Mercer, Robert L. The Mathematics of Statistical Machine Translation: Parameter Estimation. Computational Linguistics. 1993
1993
-
[25]
Why do language models perform worse for morphologically complex languages?
Arnett, Catherine and Bergen, Benjamin. Why do language models perform worse for morphologically complex languages?. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[26]
XLM - V : Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models
Liang, Davis and Gonen, Hila and Mao, Yuning and Hou, Rui and Goyal, Naman and Ghazvininejad, Marjan and Zettlemoyer, Luke and Khabsa, Madian. XLM - V : Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.813
-
[27]
CoRR , year=
PaLM 2 Technical Report , author=. CoRR , year=
-
[28]
Retrofitting Large Language Models with Dynamic Tokenization
Feher, Darius and Vuli \'c , Ivan and Minixhofer, Benjamin. Retrofitting Large Language Models with Dynamic Tokenization. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1444
-
[29]
No Language Left Behind: Scaling Human-Centered Machine Translation , journal =
-
[30]
arXiv preprint arXiv:2305.06161 , year =
Li, Raymond and Allal, Loubna Ben and Zi, Yangtian and Muennighoff, Niklas and Kocetkov, Denis and Mou, Chenghao and Marone, Marc and Akiki, Christopher and Li, Jiawei and Chim, Jenny and others , title =. arXiv preprint arXiv:2305.06161 , year =
-
[31]
2026 , url=
Sander Land and Catherine Arnett , booktitle=. 2026 , url=
2026
-
[32]
2025 , booktitle=
Arnett, Catherine and Hudspeth, Marisa and O'Connor, Brendan , title =. 2025 , booktitle=
2025
-
[33]
U niversal D ependencies
Nivre, Joakim and Zeman, Daniel and Ginter, Filip and Tyers, Francis. U niversal D ependencies. Proceedings of the 15th Conference of the E uropean Chapter of the Association for Computational Linguistics: Tutorial Abstracts. 2017
2017
-
[34]
CoRR , volume =
Which Pieces Does Unigram Tokenization Really Need? , author=. CoRR , volume =. 2026 , eprint=
2026
-
[35]
Byte pair encoding is suboptimal for language model pretraining
Bostrom, Kaj and Durrett, Greg. Byte Pair Encoding is Suboptimal for Language Model Pretraining. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.414
-
[36]
CoRR , volume =
Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization , author=. CoRR , volume =
-
[37]
, title =
Yang, Zhilin and Dai, Zihang and Yang, Yiming and Carbonell, Jaime and Salakhutdinov, Ruslan and Le, Quoc V. , title =. Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =. 2019 , publisher =
2019
-
[38]
, title =
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2020 , issue_date =
2020
-
[39]
Rethinking Tokenization for Rich Morphology: The Dominance of Unigram over BPE and Morphological Alignment
Vemula, Saketh Reddy and Dandapat, Sandipan and Sharma, Dipti and Krishnamurthy, Parameswari. Rethinking Tokenization for Rich Morphology: The Dominance of Unigram over BPE and Morphological Alignment. The 14th International Joint Conference on Natural Language Processing and The 4th Conference of the Asia-Pacific Chapter of the Association for Computatio...
2025
-
[40]
Causal Estimation of Tokenisation Bias
Lesci, Pietro and Meister, Clara and Hofmann, Thomas and Vlachos, Andreas and Pimentel, Tiago. Causal Estimation of Tokenisation Bias. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1374
-
[41]
Length-aware Byte Pair Encoding for Mitigating Over-segmentation in K orean Machine Translation
Lee, Jungseob and Moon, Hyeonseok and Lee, Seungjun and Park, Chanjun and Eo, Sugyeong and Ko, Hyunwoong and Seo, Jaehyung and Lee, Seungyoon and Lim, Heuiseok. Length-aware Byte Pair Encoding for Mitigating Over-segmentation in K orean Machine Translation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.fin...
-
[42]
Getting the \# \# life out of living: How Adequate Are Word-Pieces for Modelling Complex Morphology?
Klein, Stav and Tsarfaty, Reut. Getting the \# \# life out of living: How Adequate Are Word-Pieces for Modelling Complex Morphology?. Proceedings of the 17th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology. 2020. doi:10.18653/v1/2020.sigmorphon-1.24
-
[43]
Hofmann, Valentin and Pierrehumbert, Janet and Sch. Superbizarre Is Not Superb: Derivational Morphology Improves BERT ' s Interpretation of Complex Words. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.1...
-
[44]
Tokenization and the Noiseless Channel
Zouhar, Vil \'e m and Meister, Clara and Gastaldi, Juan and Du, Li and Sachan, Mrinmaya and Cotterell, Ryan. Tokenization and the Noiseless Channel. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.284
-
[45]
A Peek into Token Bias: L arge Language Models Are Not Yet Genuine Reasoners
Jiang, Bowen and Xie, Yangxinyu and Hao, Zhuoqun and Wang, Xiaomeng and Mallick, Tanwi and Su, Weijie J and Taylor, Camillo Jose and Roth, Dan. A Peek into Token Bias: L arge Language Models Are Not Yet Genuine Reasoners. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.272
-
[46]
Smith , booktitle=
Orevaoghene Ahia and Sachin Kumar and Hila Gonen and Valentin Hofmann and Tomasz Limisiewicz and Yulia Tsvetkov and Noah A. Smith , booktitle=. 2024 , url=
2024
-
[47]
Do All Languages Cost the Same? T okenization in the Era of Commercial Language Models
Ahia, Orevaoghene and Kumar, Sachin and Gonen, Hila and Kasai, Jungo and Mortensen, David and Smith, Noah and Tsvetkov, Yulia. Do All Languages Cost the Same? T okenization in the Era of Commercial Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.614
-
[48]
and Bibi, Adel , title =
Petrov, Aleksandar and Malfa, Emanuele La and Torr, Philip H.S. and Bibi, Adel , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[49]
Limisiewicz, Tomasz and Balhar, Ji r \'i and Mare c ek, David. Tokenization Impacts Multilingual Language Modeling: A ssessing Vocabulary Allocation and Overlap Across Languages. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.350
-
[50]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[51]
B y T 5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models
Xue, Linting and Barua, Aditya and Constant, Noah and Al-Rfou, Rami and Narang, Sharan and Kale, Mihir and Roberts, Adam and Raffel, Colin. B y T 5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00461
-
[52]
and Blevins, Terra and Goldfine, Nora and Steinert-Threlkeld, Shane
Downey, C.m. and Blevins, Terra and Goldfine, Nora and Steinert-Threlkeld, Shane. Embedding Structure Matters: Comparing Methods to Adapt Multilingual Vocabularies to New Languages. Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL). 2023. doi:10.18653/v1/2023.mrl-1.20
-
[53]
BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training
Chizhov, Pavel and Arnett, Catherine and Korotkova, Elizaveta and Yamshchikov, Ivan P. BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.925
-
[54]
Fran. Trans-Tokenization and Cross-lingual Vocabulary Transfers: Language Adaptation of LLMs for Low-Resource. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2408.04303 , eprinttype =. 2408.04303 , timestamp =
-
[55]
Tokens, the oft-overlooked appetizer: Large language models, the distributional hypothesis, and meaning , doi =
Zimmerman, Julia and Hudon, Denis and Cramer, Kathryn and Ruiz, Alejandro and Beauregard, Calla and Fehr, Ashley and Fudolig, Mikaela and Demarest, Bradford and Bird, Yoshi and Trujillo, Milo and Danforth, Christopher and Dodds, Peter , year =. Tokens, the oft-overlooked appetizer: Large language models, the distributional hypothesis, and meaning , doi =....
2024
-
[56]
You should evaluate your language model on marginal likelihood over tokenisations
Cao, Kris and Rimell, Laura. You should evaluate your language model on marginal likelihood over tokenisations. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.161
-
[57]
Transactions of the Association for Computational Linguistics , volume=
Multiblimp 1.0: A massively multilingual benchmark of linguistic minimal pairs , author=. Transactions of the Association for Computational Linguistics , volume=. 2026 , publisher=
2026
-
[58]
arXiv preprint arXiv:2510.24081 , year=
Global piqa: Evaluating physical commonsense reasoning across 100+ languages and cultures , author=. arXiv preprint arXiv:2510.24081 , year=
-
[59]
The Belebele Benchmark : a Parallel Reading Comprehension Dataset in 122 Language Variants
Bandarkar, Lucas and Liang, Davis and Muller, Benjamin and Artetxe, Mikel and Shukla, Satya Narayan and Husa, Donald and Goyal, Naman and Krishnan, Abhinandan and Zettlemoyer, Luke and Khabsa, Madian. The B elebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants. Proceedings of the 62nd Annual Meeting of the Association for Co...
-
[60]
arXiv preprint arXiv:2506.20920 , year=
FineWeb2: One Pipeline to Scale Them All--Adapting Pre-Training Data Processing to Every Language , author=. arXiv preprint arXiv:2506.20920 , year=
-
[61]
arXiv preprint arXiv:2402.19173 , year=
Starcoder 2 and the stack v2: The next generation , author=. arXiv preprint arXiv:2402.19173 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.