Buffer-Parameterized Machine Learning Surrogate Models for Cross-Technology Signal Integrity Analysis and Optimization
Pith reviewed 2026-05-20 00:38 UTC · model grok-4.3
The pith
Buffer parameters let one ML surrogate predict signal integrity across IC technologies
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating IC buffer characteristics such as clock frequency, supply voltage, rise and fall times, jitter, and internal resistors and capacitors as model inputs alongside PCB parameters, the surrogate models can predict eye height, eye width, and transient waveform features across different buffer technologies without retraining.
What carries the argument
Buffer-parameterized ML surrogate that accepts both PCB and dynamic buffer parameters as inputs, with architecture selected via benchmarking of random forests, gradient boosting, support vector regression, Gaussian process regression, and neural networks for high-dimensional inputs.
If this is right
- Cross-technology design space exploration becomes possible with one model instead of repeated retraining cycles
- Eye mask compliance checking runs at massive speedups compared to full circuit simulation
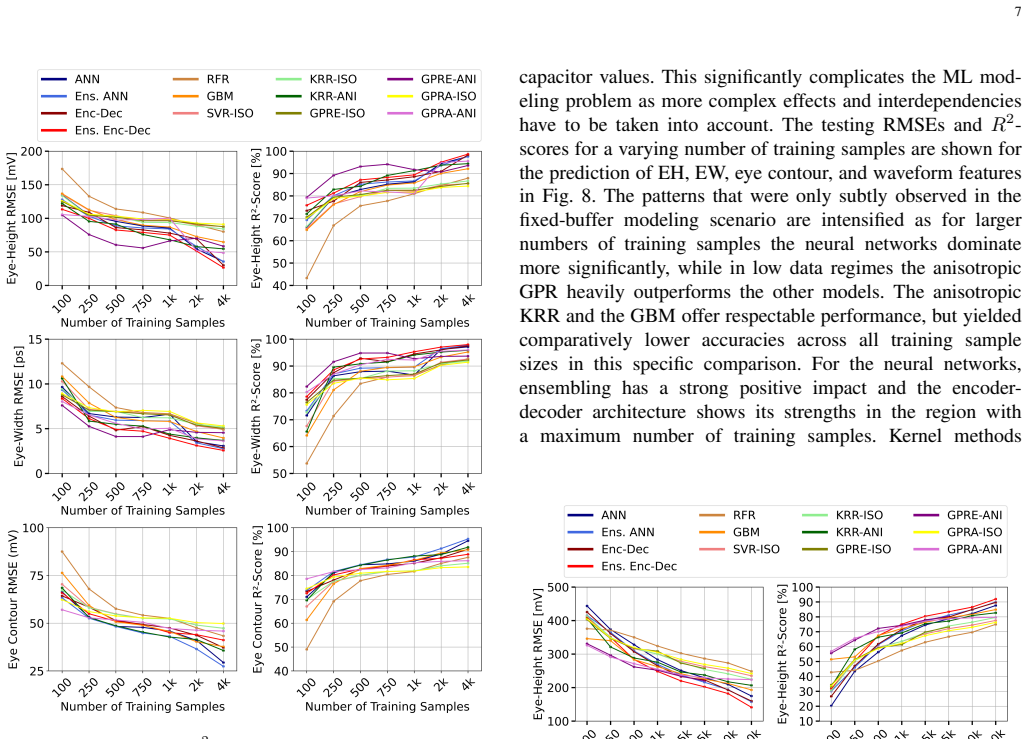
- Neural networks deliver the highest accuracy on large datasets while anisotropic Gaussian processes perform best in low-data regimes
- The same framework supports practical optimization loops that mix PCB geometry and buffer operating conditions
Where Pith is reading between the lines
- The same input-parameterization idea could reduce retraining costs in other multi-variant electronics simulations where component specifications vary
- Extending the buffer-parameter list with additional measurable effects such as temperature dependence might further widen the range of technologies handled by one model
Load-bearing premise
The listed buffer parameters together with the tested ML architectures are enough to capture the essential effects of technology changes so that one trained model stays accurate for new buffers.
What would settle it
Apply the trained model to a new buffer technology whose rise time, jitter, or internal capacitance values fall outside the ranges seen in training and check whether the predicted eye height and width errors exceed the thresholds observed on the validation set.
Figures












read the original abstract
Signal integrity (SI) analysis in printed circuit board (PCB) interconnects faces increasing complexity due to diverse integrated circuit (IC) buffer technologies, varying operating conditions, and manufacturing tolerances. Existing machine learning (ML) surrogate models for predicting SI metrics such as the inner eye contour, eye-height (EH), eye-width (EW), and transient waveform features typically rely on fixed buffer parameters, requiring costly new data generation and retraining cycles for every technology shift. This paper introduces a buffer-parameterized ML surrogate modeling methodology capable of handling cross-technology variations without retraining by treating IC buffer characteristics, e.g., clock frequency, supply voltage, rise/fall times, jitter, and internal resistors and capacitors, as dynamic model inputs alongside PCB parameters. To identify the optimal surrogate architecture for this high-dimensional space, a comprehensive benchmarking study compares tree-based methods (RFR/GBM), kernel methods (SVR/KRR), Gaussian process regression (GPR), and neural networks. The framework is subsequently validated on a complex interconnect with 44 design parameters. Results show that while anisotropic GPR excels in low-data regimes, neural networks heavily outperform other models on large datasets. Finally, the practical value of the ML surrogate models is demonstrated through a cross-technology design space exploration and optimization scenario, showcasing massive computational speedups for eye mask compliance checking compared to simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a buffer-parameterized ML surrogate modeling methodology for signal integrity analysis in PCB interconnects. By treating IC buffer characteristics (clock frequency, supply voltage, rise/fall times, jitter, internal R/C) as dynamic inputs alongside PCB parameters, the approach aims to enable generalization across buffer technologies without retraining. It benchmarks tree-based (RFR/GBM), kernel (SVR/KRR), GPR, and neural network methods, validates the framework on a 44-parameter interconnect, and demonstrates practical use in cross-technology design space exploration and optimization with reported computational speedups over simulation.
Significance. If the central claim holds, the work would offer a practical advance in SI analysis by reducing the need for repeated data generation and retraining when buffer technologies change, which is a common and costly issue in high-speed interconnect design. The benchmarking results provide useful guidance on model selection for high-dimensional parameter spaces, noting GPR strength in low-data regimes and neural networks on larger datasets. The optimization demonstration illustrates potential for massive speedups in eye-mask compliance checks.
major comments (2)
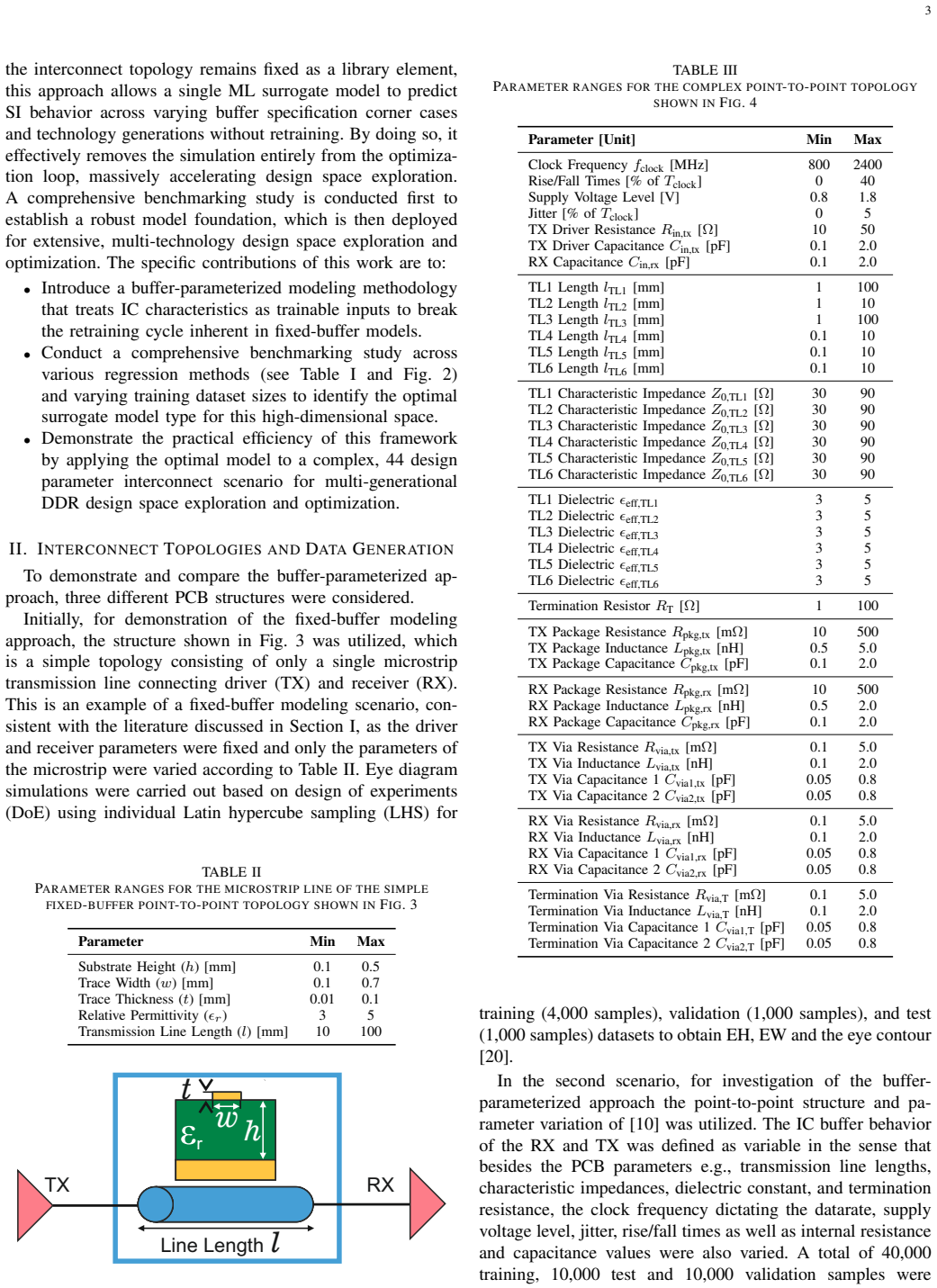
- [Validation section (44-parameter interconnect)] Validation on 44-parameter interconnect: the abstract and results description report a benchmarking study and validation but provide no quantitative error metrics (e.g., RMSE, MAE, or eye-height/width prediction accuracy), training data sizes, or explicit details on how post-training generalization across unseen buffer technologies was measured. This absence makes it impossible to assess whether the no-retraining claim is supported by the experiments.
- [Methodology and validation sections] Methodology and validation: the central claim requires that scalar buffer inputs suffice to capture cross-technology effects, yet the experiments appear to vary these scalars within a single underlying driver model family rather than substituting complete SPICE netlists from distinct foundry processes (different channel-length modulation, body-effect coefficients, or temperature-dependent mobility). If unmodeled nonlinear driver behaviors remain, systematic errors in eye contours would appear exactly where the no-retraining benefit is claimed.
minor comments (2)
- [Abstract] The abstract mentions 'massive computational speedups' but does not quantify them (e.g., speedup factor or wall-clock times) relative to full simulation; adding these numbers would strengthen the practical-value claim.
- [Methodology] Notation for the 44 design parameters and the exact list of buffer parameters used as inputs should be tabulated for clarity, especially since the high-dimensional space is central to the benchmarking.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments identify important gaps in the presentation of quantitative results and in the justification of the buffer parameterization. We address each point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Validation on 44-parameter interconnect: the abstract and results description report a benchmarking study and validation but provide no quantitative error metrics (e.g., RMSE, MAE, or eye-height/width prediction accuracy), training data sizes, or explicit details on how post-training generalization across unseen buffer technologies was measured. This absence makes it impossible to assess whether the no-retraining claim is supported by the experiments.
Authors: We agree that the current manuscript text does not present the quantitative error metrics, training-set sizes, or the precise hold-out procedure for unseen buffer technologies with sufficient clarity. The experiments did generate these quantities (RMSE/MAE on eye height/width, 5000-sample training set for the large-data regime, and a hold-out test using buffer-parameter combinations outside the training distribution), but they were only summarized rather than tabulated. We will add a new subsection in the validation section that explicitly reports these metrics, lists the training and test sizes, and describes the cross-technology generalization protocol (parameter ranges held out and resulting prediction errors). This revision will directly support the no-retraining claim. revision: yes
-
Referee: Methodology and validation: the central claim requires that scalar buffer inputs suffice to capture cross-technology effects, yet the experiments appear to vary these scalars within a single underlying driver model family rather than substituting complete SPICE netlists from distinct foundry processes (different channel-length modulation, body-effect coefficients, or temperature-dependent mobility). If unmodeled nonlinear driver behaviors remain, systematic errors in eye contours would appear exactly where the no-retraining benefit is claimed.
Authors: We acknowledge that the experiments parameterized a single base driver model family rather than swapping complete netlists from separate foundry processes. The chosen scalar inputs (rise/fall times, jitter, internal R/C, supply voltage, frequency) were extracted from multiple technology nodes and operating corners to approximate cross-technology variation; however, we did not perform full netlist substitution. We will revise the methodology section to state this scope explicitly, add a short discussion of the approximation, and note that systematic errors from unmodeled effects (e.g., body-effect or mobility temperature dependence) remain a limitation. We will also outline how the framework could be extended to full netlist inputs in future work. revision: partial
Circularity Check
No significant circularity in empirical ML surrogate methodology
full rationale
The paper presents a data-driven empirical study that benchmarks multiple independent ML architectures (tree-based, kernel, GPR, neural networks) for predicting SI metrics, treating buffer parameters as additional inputs to enable cross-technology generalization. Validation occurs on a 44-parameter interconnect against simulation data, with performance measured via direct comparison to ground-truth simulations and design optimization speedups. No equations, predictions, or first-principles results are shown to reduce by construction to fitted quantities or self-citations; the central claim rests on external benchmarking and simulation benchmarks rather than tautological definitions or renamings. This renders the approach self-contained against independent external references.
Axiom & Free-Parameter Ledger
free parameters (1)
- ML model hyperparameters
axioms (1)
- domain assumption The listed buffer parameters (frequency, voltage, rise/fall times, jitter, internal R/C) are sufficient to characterize cross-technology differences for the purpose of SI prediction.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
buffer-parameterized ML surrogate … treating IC buffer characteristics … as dynamic model inputs alongside PCB parameters … benchmarking … RFR/GBM, SVR/KRR, GPR, neural networks … 44 design parameters
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
validation on a complex interconnect with 44 design parameters … cross-technology design space exploration
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
High-Speed Channel Modeling With Machine Learning Methods for Signal Integrity Analysis,
T. Lu, J. Sun, K. Wu, and Z. Yang, “High-Speed Channel Modeling With Machine Learning Methods for Signal Integrity Analysis,”IEEE Transactions on Electromagnetic Compatibility, vol. 60, no. 6, pp. 1957– 1964, 2018
work page 1957
-
[2]
Modeling of eye diagram height in high-speed links via support vector machine,
R. Trinchero and F. G. Canavero, “Modeling of eye diagram height in high-speed links via support vector machine,” in2018 IEEE 22nd Workshop on Signal and Power Integrity (SPI), 2018, pp. 1–4
work page 2018
-
[3]
H. Ma, E.-P. Li, A. C. Cangellaris, and X. Chen, “Support Vector Regression-Based Active Subspace (SVR-AS) Modeling of High-Speed Links for Fast and Accurate Sensitivity Analysis,”IEEE Access, vol. 8, pp. 74 339–74 348, 2020
work page 2020
-
[4]
A Data-Efficient Training Model for Signal Integrity Analysis based on Transfer Learning,
T. Zhang, S. Chen, S. Wei, and J. Chen, “A Data-Efficient Training Model for Signal Integrity Analysis based on Transfer Learning,” in 2019 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), 2019, pp. 186–189
work page 2019
-
[5]
Semi-Supervised Learning Based on Hybrid Neural Network for the Signal Integrity Analysis,
S. Chen, J. Chen, T. Zhang, and S. Wei, “Semi-Supervised Learning Based on Hybrid Neural Network for the Signal Integrity Analysis,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 67, no. 10, pp. 1934–1938, 2020
work page 1934
-
[6]
D. Lhoet al., “Channel Characteristic-Based Deep Neural Network Models for Accurate Eye Diagram Estimation in High Bandwidth Mem- ory (HBM) Silicon Interposer,”IEEE Transactions on Electromagnetic Compatibility, vol. 64, no. 1, pp. 196–208, 2022
work page 2022
-
[7]
Constrained Gaussian Process for Signal Integrity applications using Variational Inference,
T. Nguyen, B. Shi, H. Ma, E.-P. Li, A. Cangellaris, and J. Schutt-Aine, “Constrained Gaussian Process for Signal Integrity applications using Variational Inference,” in2023 IEEE/MTT-S International Microwave Symposium - IMS 2023, 2023, pp. 155–158
work page 2023
-
[8]
Optimization of High-Speed Channel for Signal Integrity With Deep Genetic Algorithm,
H. H. Zhang, Z. S. Xue, X. Y . Liu, P. Li, L. Jiang, and G. M. Shi, “Optimization of High-Speed Channel for Signal Integrity With Deep Genetic Algorithm,”IEEE Transactions on Electromagnetic Compati- bility, vol. 64, no. 4, pp. 1270–1274, 2022
work page 2022
-
[9]
J. With ¨oft, W. John, E. Ecik, R. Br ¨uning, and J. G ¨otze, “Machine Learn- ing Methods for Elaborating the Feasible Region for Signal Integrity Analysis in Differential Pair PCB Structures,” in2024 International Symposium on Electromagnetic Compatibility – EMC Europe, 2024, pp. 151–156
work page 2024
-
[10]
A Machine Learning Modeling and Optimization Framework for Signal Integrity Design Support,
J. With ¨oft, W. John, E. Ecik, J. Wastian, R. Br ¨uning, and J. G ¨otze, “A Machine Learning Modeling and Optimization Framework for Signal Integrity Design Support,” in2025 Asia-Pacific International Symposium and Exhibition on Electromagnetic Compatibility (APEMC), 2025, pp. 410–413
work page 2025
-
[11]
C. H. Goay, A. Abd Aziz, N. S. Ahmad, and P. Goh, “Eye Diagram Contour Modeling Using Multilayer Perceptron Neural Networks With Adaptive Sampling and Feature Selection,”IEEE Transactions on Com- ponents, Packaging and Manufacturing Technology, vol. 9, no. 12, pp. 2427–2441, 2019
work page 2019
-
[12]
Surrogate Eye Modeling for the Statistical Assessment of a Smart Textile Interconnect,
M. Telescu, R. Trinchero, N. Tanguy, and I. S. Stievano, “Surrogate Eye Modeling for the Statistical Assessment of a Smart Textile Interconnect,” in2023 IEEE 27th Workshop on Signal and Power Integrity (SPI), 2023, pp. 1–4
work page 2023
-
[13]
Stochastic Time-Domain Mapping for Comprehensive Uncertainty As- sessment in Eye Diagrams,
M. Telescu, R. Trinchero, N. Soleimani, N. Tanguy, and I. S. Stievano, “Stochastic Time-Domain Mapping for Comprehensive Uncertainty As- sessment in Eye Diagrams,”IEEE Transactions on Electromagnetic Compatibility, vol. 65, no. 6, pp. 1930–1938, 2023
work page 1930
-
[14]
J. With ¨oft, W. John, E. Ecik, R. Br ¨uning, and J. G ¨otze, “AI Models for Supporting SI Analysis on PCB Net Structures: Comparing Linear and Non-Linear Data Sources,”Advances in Radio Science, vol. 21, pp. 77–87, 2023
work page 2023
-
[15]
E. Ecik, W. John, J. With ¨oft, and J. G ¨otze, “Anomaly Detection with Decision Trees for AI Assisted Evaluation of Signal Integrity on PCB Transmission Lines,”Advances in Radio Science, vol. 21, pp. 37–48, 2023
work page 2023
-
[16]
An Approach for SI-Compliant Parameter Space Evaluation Using a Decision Tree-Based AI Module,
E. Ecik, W. John, J. With ¨oft, R. Br¨uning, and J. G¨otze, “An Approach for SI-Compliant Parameter Space Evaluation Using a Decision Tree-Based AI Module,” in2024 Kleinheubach Conference, 2024, pp. 1–4
work page 2024
-
[17]
AI-Based SI-Compliant PCB Design Support for DDR Technology Enhanced by Transfer Learning,
J. With ¨oft, W. John, E. Ecik, and J. G¨otze, “AI-Based SI-Compliant PCB Design Support for DDR Technology Enhanced by Transfer Learning,” in2023 International Symposium on Electromagnetic Compatibility – EMC Europe, 2023, pp. 1–6
work page 2023
-
[18]
J. With ¨oft, W. John, E. Ecik, R. Br ¨uning, and J. G ¨otze, “Optimiza- tion of a Daisy Chain PCB Memory System through Reinforcement Learning under Consideration of Signal Integrity Constraints,” in2023 Kleinheubach Conference, 2023, pp. 1–4
work page 2023
-
[19]
Generic Modeling of Differential Striplines Using Machine Learning Based Regression Analysis,
S. Penugonda, S. Yong, A. Gao, K. Cai, B. Sen, and J. Fan, “Generic Modeling of Differential Striplines Using Machine Learning Based Regression Analysis,” in2020 IEEE International Symposium on Elec- tromagnetic Compatibility & Signal/Power Integrity (EMCSI), 2020, pp. 226–230
work page 2020
-
[20]
Analog Devices, “LTspice XVII,” 2016. [Online]. Available: https://www.analog.com/en/design-center/design-tools-and-calculators/ ltspice-simulator.html
work page 2016
-
[21]
L. Breiman, “Random Forests,”Machine Learning, vol. 45, no. 1, pp. 5–32, 2001
work page 2001
-
[22]
Greedy Function Approximation: A Gradient Boosting Machine,
J. H. Friedman, “Greedy Function Approximation: A Gradient Boosting Machine,”Annals of Statistics, vol. 29, no. 5, pp. 1189–1232, 2001
work page 2001
-
[23]
C. E. Rasmussen and C. K. I. Williams,Gaussian Processes for Machine Learning. Cambridge, MA, USA: MIT Press, 2006
work page 2006
-
[24]
Variational Learning of Inducing Variables in Sparse Gaus- sian Processes,
M. Titsias, “Variational Learning of Inducing Variables in Sparse Gaus- sian Processes,” inProceedings of the Twelfth International Conference on Artificial Intelligence and Statistics, vol. 5, 2009, pp. 567–574
work page 2009
-
[25]
Multi-task Gaussian Process Prediction,
E. V . Bonilla, K. M. A. Chai, and C. K. I. Williams, “Multi-task Gaussian Process Prediction,” inAdvances in Neural Information Processing Systems, vol. 20, 2007, pp. 153–160
work page 2007
-
[26]
B. Sch ¨olkopf and A. J. Smola,Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. Cambridge, MA, USA: MIT Press, 2002
work page 2002
-
[27]
Multi-step-ahead time series prediction using multiple-output support vector regression,
Y . Bao, T. Xiong, and Z. Hu, “Multi-step-ahead time series prediction using multiple-output support vector regression,”Neurocomputing, vol. 129, pp. 482–493, 2014
work page 2014
-
[28]
N. Soleimani and R. Trinchero, “Efficient Implementation of the Vector- Valued Kernel Ridge Regression for the Parametric Modeling of the Frequency-Response of a High-Speed Link,” in2023 XXXVth General Assembly and Scientific Symposium of the International Union of Radio Science (URSI GASS), 2023, pp. 1–4
work page 2023
-
[29]
I. Goodfellow, Y . Bengio, and A. Courville,Deep Learning. Cambridge, MA, USA: MIT Press, 2016
work page 2016
-
[30]
Sequence to Sequence Learning with Neural Networks,
I. Sutskever, O. Vinyals, and Q. V . Le, “Sequence to Sequence Learning with Neural Networks,” inProceedings of the 28th International Con- ference on Neural Information Processing Systems, 2014, p. 3104–3112
work page 2014
-
[31]
L. Hansen and P. Salamon, “Neural network ensembles,”IEEE Trans- actions on Pattern Analysis and Machine Intelligence, vol. 12, no. 10, pp. 993–1001, 1990
work page 1990
-
[32]
Optuna: A Next-generation Hyperparameter Optimization Framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A Next-generation Hyperparameter Optimization Framework,” inProceed- ings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2019, pp. 2623–2631
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.