REVIEW 2 major objections 2 minor 2 cited by
A multi-agent system turns one user sentence into a paced and spatially consistent short drama video.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-22 06:48 UTC pith:JOGDCZKZ
load-bearing objection This paper puts together a multi-agent pipeline for one-sentence short dramas with targeted fixes for pacing and consistency, plus a new benchmark, but the human ratings lack basic reporting that would make the gains convincing. the 2 major comments →
One Sentence, One Drama: Personalized Short-Form Drama Generation via Multi-Agent Systems
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present a hierarchical multi-agent framework that converts a single-sentence idea into a fully produced short drama through three components: debate-based story generation that enforces pacing and coherence, a 3D-grounded first-frame mechanism that supplies a shared spatial reference across clips, and multi-stage reviewer loops that detect and revise errors in script, visuals, and video.
What carries the argument
The multi-agent debate-based story generation module working together with the 3D-grounded first-frame generation mechanism to enforce pacing and maintain consistent character and scene positions across clips.
Load-bearing premise
That multi-agent debate reliably enforces short-drama pacing and narrative coherence while 3D grounding keeps spatial consistency across generated clips.
What would settle it
Generate videos from the same single-sentence prompts with both the proposed system and existing pipelines, then compare their scores on narrative quality and cross-clip consistency using the Short-Drama-Bench metrics.
If this is right
- Stories acquire stronger hooks, escalation, and endings suited to short formats.
- Character positions and scene layouts stay aligned without drifting between clips.
- Fewer manual corrections are required because automated loops catch script and visual errors.
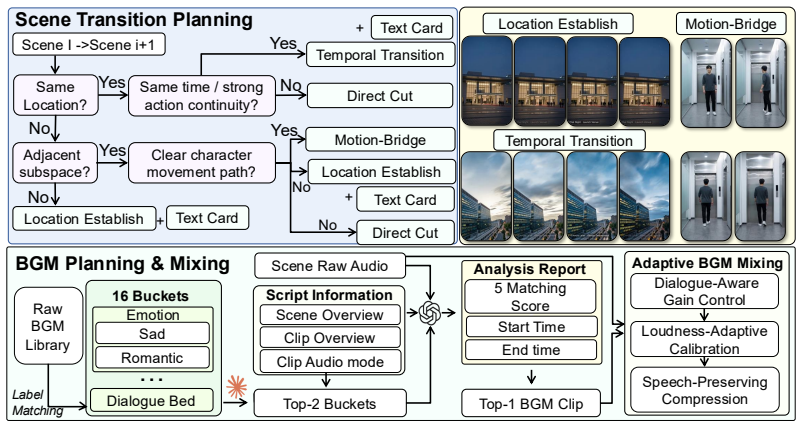
- Background music and scene transitions are matched automatically to increase immersion.
Where Pith is reading between the lines
- The consistency mechanisms could support longer video series if the 3D references scale across many clips.
- Repeated use might allow the agents to learn user-specific preferences for more tailored dramas.
- Adding direct user input into the reviewer loops could reduce remaining quality gaps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents 'One Sentence, One Drama', a hierarchical multi-agent framework that converts a single user sentence into a complete short drama. Key components include a debate-based story generation module to enforce pacing and coherence, a 3D-grounded first-frame mechanism for spatial consistency across clips, multi-stage reviewer loops for error detection and revision, plus scene-level BGM matching and transition planning. The authors introduce Short-Drama-Bench for evaluation and report that their method outperforms existing pipelines on narrative quality, cross-clip consistency, and viewing experience.
Significance. If the experimental claims hold after proper validation, the work offers a structured multi-agent solution to longstanding issues in automated short-drama production such as weak narrative pacing and visual drift. The introduction of Short-Drama-Bench, which augments standard video metrics with drama-specific criteria, provides a useful resource for the community. The 3D-grounding and iterative review mechanisms represent concrete engineering advances that could be adapted to related generative video tasks.
major comments (2)
- [Experiments] Experiments section: The headline claim of significant outperformance rests on human ratings of narrative quality, cross-clip consistency, and viewing experience, yet the manuscript supplies no information on evaluator count, selection criteria, blinding, rating scale anchors, inter-rater reliability (e.g., Fleiss' kappa or ICC), or statistical tests (p-values, confidence intervals, multiple-comparison correction). Without these details the reported gains cannot be distinguished from rater bias or prompt sensitivity.
- [Ablation Studies] §4 (or equivalent ablation subsection): The causal contribution of the multi-agent debate module and the 3D-grounded first-frame mechanism to the measured improvements is not isolated; the paper describes these components but does not present controlled ablations that remove each module while holding others fixed.
minor comments (2)
- [Abstract] The abstract states outperformance without any numerical values or baseline names; adding a concise quantitative summary would strengthen the opening.
- [Method] Notation for agent roles and reviewer loops is introduced without a compact diagram or table summarizing the information flow; a single overview figure would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will incorporate the suggested improvements into the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline claim of significant outperformance rests on human ratings of narrative quality, cross-clip consistency, and viewing experience, yet the manuscript supplies no information on evaluator count, selection criteria, blinding, rating scale anchors, inter-rater reliability (e.g., Fleiss' kappa or ICC), or statistical tests (p-values, confidence intervals, multiple-comparison correction). Without these details the reported gains cannot be distinguished from rater bias or prompt sensitivity.
Authors: We agree that these methodological details are necessary to substantiate the human evaluation results. In the revised manuscript we will expand the Experiments section to report the evaluator count, selection criteria, blinding procedures, explicit rating scale anchors, inter-rater reliability (Fleiss' kappa), and statistical analysis including p-values, confidence intervals, and multiple-comparison corrections. These additions will be placed in a dedicated subsection on evaluation protocol. revision: yes
-
Referee: [Ablation Studies] §4 (or equivalent ablation subsection): The causal contribution of the multi-agent debate module and the 3D-grounded first-frame mechanism to the measured improvements is not isolated; the paper describes these components but does not present controlled ablations that remove each module while holding others fixed.
Authors: We acknowledge that the current manuscript does not contain controlled ablation experiments that isolate the individual contributions of the multi-agent debate module and the 3D-grounded first-frame mechanism. We will add a new ablation subsection that presents quantitative results for ablated variants in which each of these components is removed while all other modules remain fixed, thereby clarifying their causal impact on narrative quality and consistency metrics. revision: yes
Circularity Check
No circularity: system design and benchmark evaluation are independent
full rationale
The paper describes an engineering pipeline (multi-agent debate for story pacing, 3D-grounded first-frame for spatial consistency, reviewer loops for refinement) that transforms a one-sentence prompt into a short drama. Claims of superiority rest on comparative experiments against existing pipelines using the newly introduced Short-Drama-Bench, which extends standard metrics with drama-specific criteria. No equations, fitted parameters, or first-principles derivations appear; nothing reduces by construction to the inputs or to self-citations. The evaluation protocol, while potentially under-specified on human-rater details, is an external measurement step rather than a definitional loop. This is a standard self-contained systems paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
read the original abstract
Existing approaches for digital short-drama production typically rely on one-shot LLM generated scripts and loosely coupled pipelines, which fail to satisfy three key requirements of short-drama generation: (1) narrative pacing, resulting in weak hooks, insufficient escalation, and unattractive endings; (2) spatial consistency, leading to drifting scene layouts and inconsistent character positions across clips; and (3) production-level quality control, requiring extensive manual review and correction across script and visual stages. We present One Sentence, One Drama, a hierarchical multi-agent framework that transforms a user's single-sentence idea into a fully produced short drama through structured intermediate modules and iterative refinement. Our approach is built upon three key components: (1) a multi-agent debate-based story generation module that enforces short-drama pacing and narrative coherence; (2) a 3D-grounded first-frame generation mechanism that establishes a shared spatial reference for consistent character positioning and scene layout across clips; and (3) multi-stage reviewer loops that perform comprehensive error detection and targeted revision across script, visual, and video generation stages. We also introduce scene-level BGM matching and scene transition planning to improve the audience's immersive experience. To systematically evaluate this task, we introduce Short-Drama-Bench, a benchmark that extends standard video quality metrics with short-drama-specific criteria. Experimental results demonstrate that our method significantly outperforms existing pipelines in narrative quality, cross-clip consistency, and overall viewing experience.
Figures













Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a hierarchical multi-agent framework that transforms a user's single-sentence idea into a fully produced short drama through structured intermediate modules and iterative refinement... multi-agent debate-based story generation module... 3D-grounded first-frame generation mechanism
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
3D-grounded first-frame generation... reconstruct a scene-level 3D world W using Marble... register generated clips and the human mesh into the shared coordinate system
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Short-Drama-Bench... narrative quality, cross-clip consistency, and overall viewing experience
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
FilmWorld: Agentic Novel-to-Film Generation through Dynamic Cinematic World Modeling
FilmWorld generates multi-scene films from novels by materializing an explicit evolving world-state trajectory and rendering shots in parallel, beating five agents on its own FilmEval benchmark.
-
Training Skills Like Parameters via Self-Supervised Semantic Diffusion
Screenwriting skills can be learned from human scripts alone by compressing and reconstructing them, storing the lessons as text cards that improve generation without changing model weights.
Reference graph
Works this paper leans on
-
[1]
https://www.dramaland.com/, 2026
Dramaland short drama creator service platform. https://www.dramaland.com/, 2026. Accessed: 2026-05-06. Public platform quotation for Hongguo short-drama production tiers: A-level 2000 CNY/min, S-level 3000 CNY/min, and S+-level 5000 CNY/min
work page 2026
-
[2]
Onestory: Coherent multi-shot video generation with adaptive memory,
Zhaochong An, Menglin Jia, Haonan Qiu, Zijian Zhou, Xiaoke Huang, Zhiheng Liu, Weiming Ren, Kumara Kahatapitiya, Ding Liu, Sen He, Chenyang Zhang, Tao Xiang, Fanny Yang, Serge Belongie, and Tian Xie. Onestory: Coherent multi-shot video generation with adaptive memory,
- [3]
-
[4]
Anthropic. Claude Opus 4.6 System Card. https://www-cdn.anthropic.com/ 14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf, February 2026. System card
work page 2026
-
[5]
arXiv preprint arXiv:2412.07750 (2024)
Yuval Atzmon, Rinon Gal, Yoad Tewel, Yoni Kasten, and Gal Chechik. Multi-shot character consistency for text-to-video generation.arXiv preprint arXiv:2412.07750, 2024
-
[6]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024. URL https://openai.com/research/ video-generation-models-as-world-simulators
work page 2024
-
[8]
ByteDance. Xiao yun que ai agent. https://xyq.jianying.com, 2026. Closed-source commercial product built on Seedance 2.0. Accessed: 2026-04-22
work page 2026
-
[9]
ByteDance Seed Team. Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity.https://seed.bytedance.com/en/seed2, 2026. Model card
work page 2026
-
[10]
Gengchen Cao, Tianke He, Yixuan Liu, and RAY LC. Audience in the loop: Viewer feedback- driven content creation in micro-drama production on social media. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems, pages 1–25, 2026
work page 2026
-
[11]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, Weiming Xiong, Wei Wang, Nuo Pang, Kang Kang, Zhiheng Xu, Yuzhe Jin, Yupeng Liang, Yubing Song, Peng Zhao, Boyuan Xu, Di Qiu, Debang Li, Zhengcong Fei, Yang Li, and Yahui Zhou. Skyreels-v2: Infinite-length film generative model...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation, 2025. URLhttps://arxiv.org/abs/2510.02283. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Mohamed Elmoghany, Liangbing Zhao, Xiaoqian Shen, Subhojyoti Mukherjee, Yang Zhou, Gang Wu, Viet Dac Lai, Seunghyun Yoon, Ryan Rossi, Abdullah Rashwan, Puneet Mathur, Varun Manjunatha, Daksh Dangi, Chien Nguyen, Nedim Lipka, Trung Bui, Krishna Kumar Singh, Ruiyi Zhang, Xiaolei Huang, Jaemin Cho, Yu Wang, Namyong Park, Zhengzhong Tu, Hongjie Chen, Hoda Eld...
-
[16]
Google AI for Developers. Gemini 3 pro image preview. https://ai.google.dev/ gemini-api/docs/models/gemini-3-pro-image-preview , 2026. Accessed: 2026-04- 24
work page 2026
-
[17]
Google DeepMind. Veo 3 technical report. https://storage.googleapis.com/ deepmind-media/veo/Veo-3-Tech-Report.pdf, 2025. Technical report
work page 2025
-
[18]
End-to-End Training for Autoregressive Video Diffusion via Self-Resampling
Yuwei Guo, Ceyuan Yang, Hao He, Yang Zhao, Meng Wei, Zhenheng Yang, Weilin Huang, and Dahua Lin. End-to-end training for autoregressive video diffusion via self-resampling, 2025. URLhttps://arxiv.org/abs/2512.15702
work page internal anchor Pith review arXiv 2025
-
[19]
Long context tuning for video generation
Yuwei Guo, Ceyuan Yang, Ziyan Yang, Zhibei Ma, Zhijie Lin, Zhenheng Yang, Dahua Lin, and Lu Jiang. Long context tuning for video generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17281–17291, 2025
work page 2025
-
[20]
Toonflow.https://github.com/HBAI-Ltd/Toonflow-app, 2026
HBAI Ltd. Toonflow.https://github.com/HBAI-Ltd/Toonflow-app, 2026. Open-source project under AGPL-3.0 license. Accessed: 2026-04-22
work page 2026
-
[21]
StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration
Panwen Hu, Jin Jiang, Jianqi Chen, Mingfei Han, Shengcai Liao, Xiaojun Chang, and Xiaodan Liang. Storyagent: Customized storytelling video generation via multi-agent collaboration. arXiv preprint arXiv:2411.04925, 2024
work page Pith review arXiv 2024
-
[22]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench: Comprehensive benchmark suite for video generative models, 2023. URLhttps://arxiv.org/abs/2311.17982
-
[24]
Hunyuanvideo: A systematic framework for large video generative models,
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, ...
-
[25]
URLhttps://arxiv.org/abs/2412.03603
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Kling ai.https://klingai.com, 2024
Kuaishou Technology. Kling ai.https://klingai.com, 2024. Accessed: 2026-04-22
work page 2024
-
[27]
Haodong Li, Shaoteng Liu, Zhe Lin, and Manmohan Chandraker. Rolling sink: Bridging limited-horizon training and open-ended testing in autoregressive video diffusion, 2026. URL https://arxiv.org/abs/2602.07775. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
arXiv preprint arXiv:2309.15091 , year =
Han Lin, Abhay Zala, Jaemin Cho, and Mohit Bansal. Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning.arXiv preprint arXiv:2309.15091, 2023
-
[29]
Videostudio: Generating consistent-content and multi-scene videos
Fuchen Long, Zhaofan Qiu, Ting Yao, and Tao Mei. Videostudio: Generating consistent-content and multi-scene videos. InEuropean Conference on Computer Vision, pages 468–485. Springer, 2024
work page 2024
-
[30]
Yihao Meng, Hao Ouyang, Yue Yu, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Hanlin Wang, Yixuan Li, Cheng Chen, Yanhong Zeng, Yujun Shen, and Huamin Qu. Holocine: Holistic generation of cinematic multi-shot long video narratives, 2025. URL https://arxiv.org/ abs/2510.20822
-
[31]
Chenyu Mu, Xin He, Qu Yang, Wanshun Chen, Jiadi Yao, Huang Liu, Zihao Yi, Bo Zhao, Xingyu Chen, Ruotian Ma, Fanghua Ye, Erkun Yang, Cheng Deng, Zhaopeng Tu, Xiaolong Li, and Linus. The script is all you need: An agentic framework for long-horizon dialogue-to- cinematic video generation, 2026. URLhttps://arxiv.org/abs/2601.17737
work page internal anchor Pith review arXiv 2026
-
[32]
GPT-Audio API Documentation, 2026
OpenAI. GPT-Audio API Documentation, 2026. URL https://platform.openai.com/ docs/models/gpt-audio. Accessed: 2026-04-30
work page 2026
-
[33]
Intensifying competition in the short-drama market poses challenges for long-form video platforms
Shiya Pi. Intensifying competition in the short-drama market poses challenges for long-form video platforms. Sina Finance, March 2025. URL https://finance.sina.com.cn/roll/ 2025-03-06/doc-inensrzt1029804.shtml . Accessed: 2026-05-06. The article reports that common short-drama production costs are about 10,000 CNY per minute
work page 2025
-
[34]
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, Mojie Chi, Xuyan Chi, Jian Cong, Qinpeng Cui, Fei Ding, Qide Dong, Yujiao Du, Haojie Duanmu, Junliang Fan, Jiarui Fang, Jing Fang, Zetao Fang, Chengjian Feng, Yu Gao, Diandian Gu, Dong Guo, Hanzhong Guo, Qiushan Guo, Boyang Hao, Hon...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Pvchat: Personalized video chat with one-shot learning
Yufei Shi, Weilong Yan, Gang Xu, Yumeng Li, Yucheng Chen, Zhenxi Li, Fei Yu, Ming Li, and Si Yong Yeo. Pvchat: Personalized video chat with one-shot learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 23321–23331, October 2025
work page 2025
-
[36]
Skyreels v1: Human-centric video foundation model
SkyReels-AI. Skyreels v1: Human-centric video foundation model. https://github.com/ SkyworkAI/SkyReels-V1, 2025
work page 2025
-
[37]
Training diffusion language models for black-box optimization.arXiv preprint arXiv:2603.17919, 2026
Zipeng Sun, Can Chen, Ye Yuan, Haolun Wu, Jiayao Gu, Christopher Pal, and Xue Liu. Training diffusion language models for black-box optimization.arXiv preprint arXiv:2603.17919, 2026. 13
work page internal anchor Pith review arXiv 2026
-
[38]
Qwen3.5-omni technical report, 2026
Qwen Team. Qwen3.5-omni technical report, 2026. URL https://arxiv.org/abs/2604. 15804
work page 2026
-
[39]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[41]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
work page 2025
-
[42]
Marble: A multimodal world model
World Labs. Marble: A multimodal world model. https://www.worldlabs.ai/blog/ marble-world-model, 2026. Accessed: 2026-04-24
work page 2026
-
[43]
Automated Movie Generation via Multi-Agent CoT Planning
Weijia Wu, Zeyu Zhu, and Mike Zheng Shou. Automated movie generation via multi-agent cot planning.arXiv preprint arXiv:2503.07314, 2025
work page Pith review arXiv 2025
-
[44]
Zhiyu Xu, Weilong Yan, Yufei Shi, Xin Meng, Tao He, Huiping Zhuang, Ming Li, and Hehe Fan. Scieducator: Scientific video understanding and educating via deming-cycle multi-agent system.arXiv preprint arXiv:2511.17943, 2025
-
[45]
Tan, Bing Zeng, and Shuaicheng Liu
Weilong Yan, Robby T. Tan, Bing Zeng, and Shuaicheng Liu. Deep homography mixture for single image rolling shutter correction. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9868–9877, October 2023
work page 2023
-
[46]
Weilong Yan, Ming Li, Haipeng Li, Shuwei Shao, and Robby T. Tan. Synthetic-to-real self- supervised robust depth estimation via learning with motion and structure priors. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 21880–21890, June 2025
work page 2025
-
[47]
Weilong Yan, Haipeng Li, Hao Xu, Nianjin Ye, Yihao Ai, Shuaicheng Liu, and Jingyu Hu. LaS-Comp: Zero-shot 3D Completion with Latent-Spatial Consistency.arXiv preprint arXiv:2602.18735, 2026
-
[48]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, Song Han, and Yukang Chen. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
arXiv preprint arXiv:2602.15989 (2026)
Xitong Yang, Devansh Kukreja, Don Pinkus, Anushka Sagar, Taosha Fan, Jinhyung Park, Soyong Shin, Jinkun Cao, Jiawei Liu, Nicolas Ugrinovic, Matt Feiszli, Jitendra Malik, Piotr Dollar, and Kris Kitani. Sam 3d body: Robust full-body human mesh recovery, 2026. URL https://arxiv.org/abs/2602.15989
-
[50]
Support-Proximity Augmented Diffusion Estimation for Offline Black-Box Optimization
Yonghan Yang, Ye Yuan, Zipeng Sun, Linfeng Du, Bowei He, Haolun Wu, Can Chen, and Xue Liu. Support-proximity augmented diffusion estimation for offline black-box optimization. arXiv preprint arXiv:2605.11246, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer, 2025. URLhttps://arxiv.org/abs/2408.06072. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Freeman, Frédo Durand, Eli Shechtman, and Xun Huang
Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Freeman, Frédo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[53]
Storymem: Multi-shot long video storytelling with memory
Kaiwen Zhang, Liming Jiang, Angtian Wang, Jacob Zhiyuan Fang, Tiancheng Zhi, Qing Yan, Hao Kang, Xin Lu, and Xingang Pan. Storymem: Multi-shot long video storytelling with memory.arXiv preprint arXiv:2512.19539, 2025
-
[54]
Xindan Zhang, Weilong Yan, Yufei Shi, Xuerui Qiu, Tao He, Ying Li, Ming Li, and Hehe Fan. 4dpc2hat: Towards dynamic point cloud understanding with failure-aware bootstrapping.arXiv preprint arXiv:2602.03890, 2026
work page internal anchor Pith review arXiv 2026
-
[55]
Zengqun Zhao, Yanzuo Lu, Ziquan Liu, Jifei Song, Jiankang Deng, and Ioannis Patras. Relax forcing: Relaxed kv-memory for consistent long video generation, 2026. URL https:// arxiv.org/abs/2603.21366
-
[56]
arXiv preprint arXiv:2412.02259 (2024) 5, 14, 17, 19
Mingzhe Zheng, Yongqi Xu, Haojian Huang, Xuran Ma, Yexin Liu, Wenjie Shu, Yatian Pang, Feilong Tang, Qifeng Chen, Harry Yang, and Ser-Nam Lim. Videogen-of-thought: Step-by-step generating multi-shot video with minimal manual intervention, 2025. URL https://arxiv.org/abs/2412.02259
-
[57]
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffusion: Consistent self-attention for long-range image and video generation.Advances in Neural Information Processing Systems, 37:110315–110340, 2024
work page 2024
-
[58]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video generation, 2026. URLhttps://arxiv.org/abs/2602.02214
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
Vistorybench: Comprehensive benchmark suite for story visualization,
Cailin Zhuang, Ailin Huang, Yaoqi Hu, Jingwei Wu, Wei Cheng, Jiaqi Liao, Hongyuan Wang, Xinyao Liao, Weiwei Cai, Hengyuan Xu, Xuanyang Zhang, Xianfang Zeng, Zhewei Huang, Gang Yu, and Chi Zhang. Vistorybench: Comprehensive benchmark suite for story visualization,
-
[60]
URLhttps://arxiv.org/abs/2505.24862. 15 Appendix Overview This appendix provides additional details for the related work, generation pipeline, benchmark construction, evaluation protocol, implementation settings, prompts, and responsible-use discussion. • Appendix A: Broader Impacts.Potential positive impacts on creative access and production cost, as wel...
-
[61]
appears to rely on one-shot LLM expansion, leading to weak hooks and brittle narrative logic. On the visual side, keyframes are generated independently from a few reference images, causing spatial drift and inconsistent character placement across clips. They also depend on manual inspection for quality control, and neither model scene-level audio or trans...
-
[62]
After Being Abandoned at the Wedding, She Returned as an Investor Capable of Buying the Groom’s Empire 25 Category Subcategory Specific Topics
-
[63]
The Day the Divorce Papers Were Signed, His Ex-Wife’s Company Went Public
-
[64]
The Humiliated Stable Boy Turns Out to Be the Long-Lost Heir to the Kingdom
The Daughter-in-Law Kicked Out by Her Mother-in-Law Became the New Owner of Her Company Three Years Later Hidden Identity 1. The Humiliated Stable Boy Turns Out to Be the Long-Lost Heir to the Kingdom
-
[65]
The Security Guard Everyone in the Company Looks Down On Has Five World Leaders’ Private Numbers in His Phone
-
[66]
The Transfer Student Mocked by Classmates Whose Father Is Their School’s Chairman of the Board Career Comeback 1. The designer’s wife, who was accused of steal- ing her boss’s manuscript, was confronted by her husband who had been secretly married. With a single phone call, the CEO was summoned
-
[67]
The Intern Publicly Humiliated by the Director Was Sitting in the Director’s Chair a Year Later
-
[68]
The Woman Fired for Being Pregnant Returned as the Company’s Biggest Client
The Designer Reduced to Tears by a Client Went On to Win an International Design Award Social Realism Workplace Injustice 1. The Woman Fired for Being Pregnant Returned as the Company’s Biggest Client
-
[69]
The Middle Manager ‘Optimized Out’ at 35 Built a Startup Team from an Unemployment Group Chat
-
[70]
The Night the Hospital Refused Her Surgery, She Livestreamed Everything
The Engineer Forced to Sign a Non-Compete Discovered the Boss Had Already Violated His Own Medical & Survival 1. The Night the Hospital Refused Her Surgery, She Livestreamed Everything
-
[71]
Her Father’s Life-Saving Pill Costs 700 Yuan Each, So the Daughter Went to India to Find the Manufacturer Herself
-
[72]
When the Mother Who Favored Sons Over Daughters Fell Ill, Only the Neglected Daughter Came
In the Three Months She Was Misdiagnosed with Cancer, She Saw Everyone Around Her for Who They Really Are Family Ethics 1. When the Mother Who Favored Sons Over Daughters Fell Ill, Only the Neglected Daughter Came
-
[73]
The Parents Gave the House to Their Son but Left the Debt to Their Daughter
-
[74]
The Whole Family Pooled Money for the Brother to Study Abroad, but the Sister Got Into a Better School on Her Own Ancient Court In- trigue Harem Power Strug- gle
-
[75]
The Abandoned Consort in the Cold Palace Is Determined to Put the Crown Prince on the Throne
-
[76]
Sentenced to Death on Her First Day in the Palace, She Traded a Bowl of Poison for the Em- press’s Secret
-
[77]
The Poisoned Princess Married the Enemy Prince Only to Burn the Empire from Within
She Pretended to Be Out of Favor for Three Years While Secretly Building a Shadow Guard That Answers Only to Her 26 Category Subcategory Specific Topics Court Conspiracy 1. The Poisoned Princess Married the Enemy Prince Only to Burn the Empire from Within
-
[78]
Everyone Believed the Chancellor Was Loyal — Only the Crown Prince Knew He Killed the Late Emperor
-
[79]
The Exiled General’s Daughter Returns with Her Father’s Former Army Women Breaking the Rules
-
[80]
She Disguised Herself as a Man to Top the Imperial Exam, Only to Be Exposed in the Golden Hall
-
[81]
The Princess Who Knew No Martial Arts Talked Down a Hundred Thousand Rebels with Words Alone
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.