CAR-SAM: Cross-Attention Reconstruction for Post-Training Quantization of the Segment Anything Model
Pith reviewed 2026-05-19 21:24 UTC · model grok-4.3
The pith
CAR-SAM enables effective 4-bit post-training quantization of the Segment Anything Model by fixing decoder attention issues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
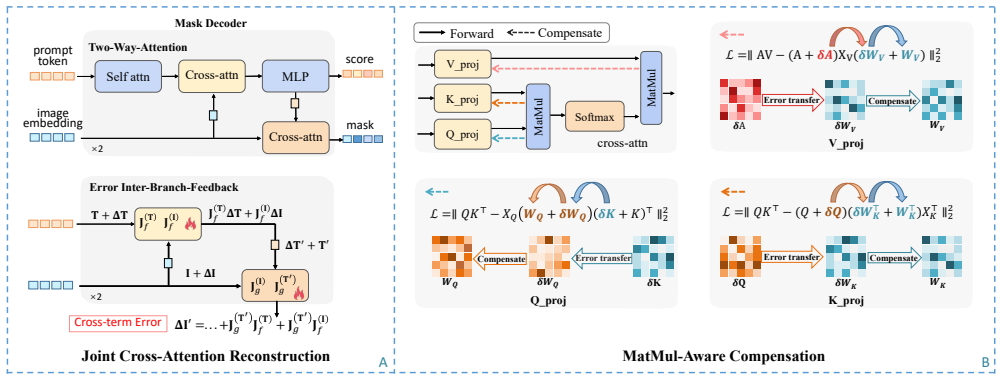
CAR-SAM shows that attention dissipation in the SAM decoder under quantization can be mitigated by shifting activation errors to linear weights through MatMul-Aware Compensation, and that reconstruction oscillation can be reduced by jointly optimizing the coupled cross-attention branches with Joint Cross-Attention Reconstruction, leading to superior 4-bit performance.
What carries the argument
MatMul-Aware Compensation (MAC) that transfers quantization errors from activations to weights, and Joint Cross-Attention Reconstruction (JCAR) that optimizes both branches of the two-way transformer simultaneously.
If this is right
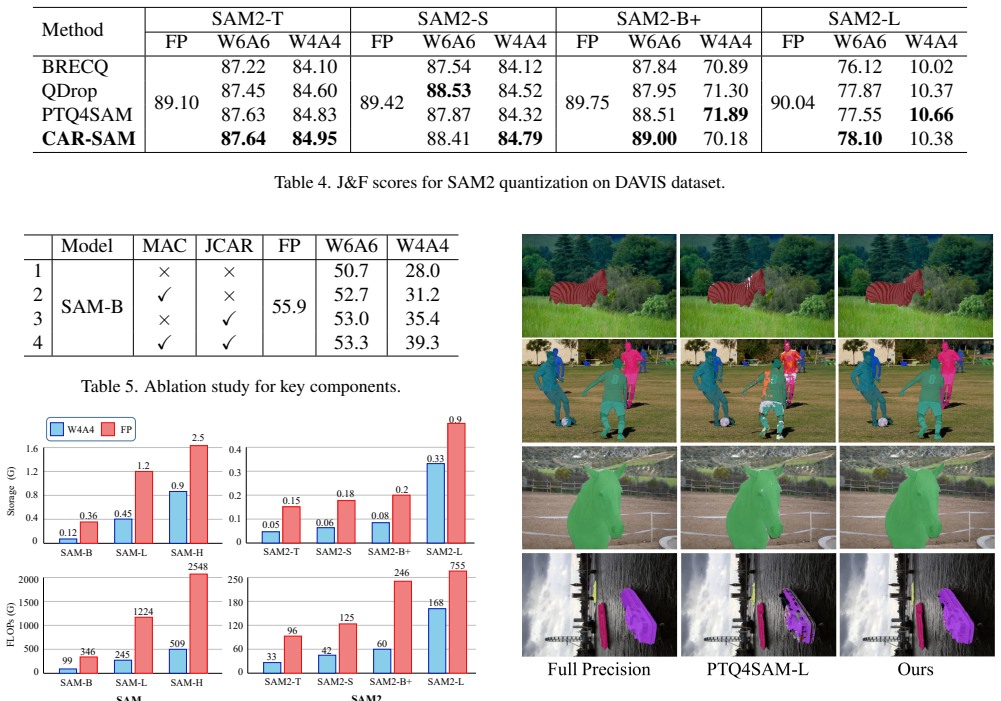
- SAM can be quantized to 4 bits with mAP gains of 14.6% on SAM-B and 6.6% on SAM-L over prior PTQ methods.
- The approach avoids the need for retraining or fine-tuning the model after quantization.
- It specifically targets the cross-attention structure unique to the SAM decoder.
- Results hold for both the base and large versions of the model.
Where Pith is reading between the lines
- This mechanism might extend to other models using similar two-way or cross-attention transformers in vision tasks.
- Lower precision could lead to faster inference and lower power use on mobile and embedded systems.
- Testing the method on additional vision foundation models could reveal if the oscillation problem is widespread.
Load-bearing premise
That attention dissipation and reconstruction oscillation are the primary reasons existing PTQ methods underperform on SAM, and that the proposed MAC and JCAR directly resolve them without new problems.
What would settle it
An experiment that applies 4-bit quantization to SAM with and without the MAC mechanism and measures whether the attention maps retain clear object boundaries or become diffuse.
Figures




read the original abstract
Segment Anything Models (SAMs) are extensively used in computer vision for universal image segmentation, but deploying them on resource-constrained devices is challenging due to their high computational and memory demands. Post-Training Quantization (PTQ) is a widely used technique for model compression and acceleration. However, existing PTQ methods fail to consider the cross-attention architecture in the SAM decoder. This degradation primarily stems from the unique challenges posed by SAMs: (1) Attention dissipation, where the attention information in the decoder, which is crucial for representing segmentation masks, collapses into a diffuse and non-semantic form under low-bit quantization; and (2) Reconstruction oscillation, where bidirectional coupling within the two-way transformer introduces cross-branch error interference and destabilizes convergence. To tackle these issues, we propose CAR-SAM, a unified quantization framework tailored for SAMs. Firstly, to mitigate attention dissipation, we introduce MatMul-Aware Compensation (MAC) mechanism that transfers activation-induced quantization errors from MatMul to preceding linear weights. Secondly, to mitigate oscillation in decoder optimization, we develop a Joint Cross-Attention Reconstruction (JCAR) strategy that jointly reconstructs coupled attention branches, suppressing oscillatory behavior and promoting stable convergence. Extensive experiments show that CAR-SAM robustly quantizes SAM models down to 4-bit precision, surpassing existing methods by 14.6% and 6.6% mAP on SAM-B and SAM-L respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CAR-SAM, a post-training quantization framework for Segment Anything Models (SAM). It identifies attention dissipation in cross-attention MatMuls and reconstruction oscillation from bidirectional coupling in the two-way transformer decoder as primary sources of degradation under low-bit PTQ. To address these, it proposes a MatMul-Aware Compensation (MAC) mechanism that shifts activation quantization errors into preceding linear weights and a Joint Cross-Attention Reconstruction (JCAR) strategy that jointly optimizes the coupled attention branches for stable convergence. Experiments claim that CAR-SAM enables robust 4-bit quantization of SAM-B and SAM-L, outperforming prior PTQ methods by 14.6% and 6.6% mAP respectively.
Significance. If the empirical gains hold under rigorous controls, the work would be significant for practical deployment of SAM on resource-limited hardware, as it provides an architecture-aware PTQ solution rather than generic quantization. Credit is given for explicitly diagnosing SAM-specific challenges in the decoder and for introducing targeted mechanisms (MAC and JCAR) that aim to preserve cross-attention information without retraining. The approach could influence future quantization of other vision transformers with coupled branches.
major comments (3)
- [§4] §4 (Experiments): The central claim of 14.6% and 6.6% mAP gains on SAM-B and SAM-L at 4-bit precision is presented without reported details on calibration-set size, baseline implementations, ablation configurations, or error bars across multiple runs. This absence makes it impossible to determine whether the improvements are robust or attributable to the proposed MAC/JCAR mechanisms versus unablated factors such as optimizer schedule or data selection.
- [§3.2] §3.2 (MAC mechanism): The assertion that MAC mitigates attention dissipation by relocating MatMul activation errors into preceding linear weights lacks supporting diagnostics. No attention-map visualizations, attention-sharpness metrics, or before/after quantization comparisons are provided to confirm that the mechanism actually restores semantic attention structure rather than merely improving overall accuracy through other means.
- [§3.3] §3.3 (JCAR strategy): The claim that JCAR suppresses oscillatory behavior in the bidirectional decoder branches is not directly validated. Absence of per-iteration mask-variance curves, convergence diagnostics, or controlled ablations isolating JCAR from standard reconstruction leaves open the possibility that reported stability and mAP gains arise from generic optimization choices rather than the joint cross-attention formulation.
minor comments (2)
- The abstract would be strengthened by briefly stating the evaluation datasets and the precise bit-width configurations used for the reported mAP numbers.
- [§3] Notation for the two-way transformer branches and the MatMul operations should be introduced with a single consistent diagram or equation set early in §3 to aid readability.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed feedback. The comments highlight important aspects of experimental rigor and mechanistic validation that we have addressed in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: §4 (Experiments): The central claim of 14.6% and 6.6% mAP gains on SAM-B and SAM-L at 4-bit precision is presented without reported details on calibration-set size, baseline implementations, ablation configurations, or error bars across multiple runs. This absence makes it impossible to determine whether the improvements are robust or attributable to the proposed MAC/JCAR mechanisms versus unablated factors such as optimizer schedule or data selection.
Authors: We agree that these details are essential for assessing robustness and reproducibility. In the revised manuscript we have expanded §4 with the following: the calibration set comprises 1024 images randomly sampled from the COCO training set; all baselines were re-implemented from their official codebases using identical hyper-parameters and the same calibration data; ablation tables now explicitly isolate the contribution of MAC and JCAR; and we report mean mAP together with standard deviation over five independent runs that vary the random seed for both data sampling and optimizer initialization. The added statistics confirm that the reported gains remain consistent and are attributable to the proposed components rather than unablated factors. revision: yes
-
Referee: §3.2 (MAC mechanism): The assertion that MAC mitigates attention dissipation by relocating MatMul activation errors into preceding linear weights lacks supporting diagnostics. No attention-map visualizations, attention-sharpness metrics, or before/after quantization comparisons are provided to confirm that the mechanism actually restores semantic attention structure rather than merely improving overall accuracy through other means.
Authors: While the ablation results in the original submission already demonstrate the necessity of MAC for preserving performance, we acknowledge the value of direct mechanistic evidence. The revised manuscript now includes new figures showing side-by-side cross-attention maps from the decoder for the full-precision model, the 4-bit model without MAC, and the 4-bit model with MAC. We additionally report quantitative diagnostics: average attention-map entropy and cosine similarity to the full-precision attention maps. These visualizations and metrics confirm that MAC reduces dissipation and restores semantic focus beyond what generic accuracy improvements would produce. revision: yes
-
Referee: §3.3 (JCAR strategy): The claim that JCAR suppresses oscillatory behavior in the bidirectional decoder branches is not directly validated. Absence of per-iteration mask-variance curves, convergence diagnostics, or controlled ablations isolating JCAR from standard reconstruction leaves open the possibility that reported stability and mAP gains arise from generic optimization choices rather than the joint cross-attention formulation.
Authors: We agree that explicit convergence diagnostics would strengthen the claim. In the revision we have added per-iteration loss and mask-variance curves for the two decoder branches, comparing standard separate reconstruction against JCAR under otherwise identical optimization settings. The plots show markedly lower oscillation and faster stabilization with JCAR. We have also included a controlled ablation that isolates the joint reconstruction formulation while freezing all other hyper-parameters; this ablation yields both higher final mAP and lower mask variance, indicating that the stability benefit stems from the joint cross-attention formulation itself. revision: yes
Circularity Check
No circularity: empirical validation of proposed mechanisms on external benchmarks
full rationale
The paper identifies attention dissipation and reconstruction oscillation as degradation sources in SAM PTQ, then introduces MAC (transferring MatMul errors to linear weights) and JCAR (joint branch reconstruction) as targeted fixes. Performance gains (14.6% / 6.6% mAP) are reported via direct comparison to prior PTQ methods on SAM-B and SAM-L using standard calibration and evaluation protocols. No step equates a claimed prediction to its own fitted inputs, self-citation chain, or definitional renaming; the central results remain falsifiable against independent baselines and do not reduce by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uniform quantization is applied to weights and activations in the SAM decoder.
invented entities (2)
-
MatMul-Aware Compensation (MAC) mechanism
no independent evidence
-
Joint Cross-Attention Reconstruction (JCAR) strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lsq+: Improving low-bit quantization through learnable offsets and better initializa- tion
Yash Bhalgat, Jinwon Lee, Markus Nagel, Tijmen Blankevoort, and Nojun Kwak. Lsq+: Improving low-bit quantization through learnable offsets and better initializa- tion. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition workshops, pages 696– 697, 2020. 3
work page 2020
-
[2]
Slimsam: 0.1% data makes segment anything slim
Zigeng Chen, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Slimsam: 0.1% data makes segment anything slim. Advances in Neural Information Processing Systems, 37: 39434–39461, 2024. 2
work page 2024
-
[3]
Steven K Esser, Jeffrey L McKinstry, Deepika Bablani, Rathinakumar Appuswamy, and Dharmendra S Modha. Learned step size quantization.arXiv preprint arXiv:1902.08153, 2019. 3
-
[4]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 1
work page 2023
-
[6]
Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junxian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, and Song Han. Svdquant: Absorbing outliers by low- rank components for 4-bit diffusion models.arXiv preprint arXiv:2411.05007, 2024. 3
-
[7]
Brecq: Pushing the limit of post-training quantization by block reconstruction
Yuhang Li, Ruihao Gong, Xu Tan, Yang Yang, Peng Hu, Qi Zhang, Fengwei Yu, Wei Wang, and Shi Gu. Brecq: Pushing the limit of post-training quantization by block reconstruc- tion.arXiv preprint arXiv:2102.05426, 2021. 1, 3
-
[8]
Yuhang Li, Ruokai Yin, Donghyun Lee, Shiting Xiao, and Priyadarshini Panda. Gptaq: Efficient finetuning-free quantization for asymmetric calibration.arXiv preprint arXiv:2504.02692, 2025. 3
-
[9]
Yang Lin, Tianyu Zhang, Peiqin Sun, Zheng Li, and Shuchang Zhou. Fq-vit: Post-training quantization for fully quantized vision transformer.arXiv preprint arXiv:2111.13824, 2021. 3
-
[10]
Pq-sam: Post-training quantization for segment any- thing model
Xiaoyu Liu, Xin Ding, Lei Yu, Yuanyuan Xi, Wei Li, Zhi- jun Tu, Jie Hu, Hanting Chen, Baoqun Yin, and Zhiwei Xiong. Pq-sam: Post-training quantization for segment any- thing model. InEuropean Conference on Computer Vision, pages 420–437. Springer, 2024. 1
work page 2024
-
[11]
Ptq4sam: Post-training quantization for seg- ment anything
Chengtao Lv, Hong Chen, Jinyang Guo, Yifu Ding, and Xi- anglong Liu. Ptq4sam: Post-training quantization for seg- ment anything. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 15941– 15951, 2024. 1
work page 2024
-
[12]
Solving oscillation problem in post-training quantiza- tion through a theoretical perspective
Yuexiao Ma, Huixia Li, Xiawu Zheng, Xuefeng Xiao, Rui Wang, Shilei Wen, Xin Pan, Fei Chao, and Rongrong Ji. Solving oscillation problem in post-training quantiza- tion through a theoretical perspective. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7950–7959, 2023. 5
work page 2023
-
[13]
Outlier-aware slicing for post-training quantization in vision transformer
Yuexiao Ma, Huixia Li, Xiawu Zheng, Feng Ling, Xuefeng Xiao, Rui Wang, Shilei Wen, Fei Chao, and Rongrong Ji. Outlier-aware slicing for post-training quantization in vision transformer. InForty-first International Conference on Ma- chine Learning, 2024. 5
work page 2024
-
[14]
Up or down? adap- tive rounding for post-training quantization
Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Chris- tos Louizos, and Tijmen Blankevoort. Up or down? adap- tive rounding for post-training quantization. InInternational conference on machine learning, pages 7197–7206. PMLR,
-
[15]
Mix-qsam: Mixed- precision quantization of the segment anything model
Navin Ranjan and Andreas Savakis. Mix-qsam: Mixed- precision quantization of the segment anything model. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 3280–3290, 2025. 1
work page 2025
-
[16]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Tinysam: Pushing the envelope for efficient segment any- thing model
Han Shu, Wenshuo Li, Yehui Tang, Yiman Zhang, Yi- hao Chen, Houqiang Li, Yunhe Wang, and Xinghao Chen. Tinysam: Pushing the envelope for efficient segment any- thing model. InProceedings of the AAAI Conference on Ar- tificial Intelligence, pages 20470–20478, 2025. 2
work page 2025
-
[19]
Xiuying Wei, Ruihao Gong, Yuhang Li, Xianglong Liu, and Fengwei Yu. Qdrop: Randomly dropping quantization for extremely low-bit post-training quantization.arXiv preprint arXiv:2203.05740, 2022. 1, 3
-
[20]
Dominic Williams, Fraser Macfarlane, and Avril Britten. Leaf only sam: A segment anything pipeline for zero-shot automated leaf segmentation.Smart Agricultural Technol- ogy, 8:100515, 2024. 2
work page 2024
-
[21]
Zhuguanyu Wu, Jiayi Zhang, Jiaxin Chen, Jinyang Guo, Di Huang, and Yunhong Wang. Aphq-vit: Post-training quan- tization with average perturbation hessian based reconstruc- tion for vision transformers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9686– 9695, 2025. 1
work page 2025
-
[22]
Qwt: Retrospective and new applications
Yi Xu, Xiaokang Yang, Li Song, Leonardo Traversoni, and Wei Lu. Qwt: Retrospective and new applications. InGe- ometric Algebra Computing: in Engineering and Computer Science, pages 249–273. Springer, 2010. 3
work page 2010
-
[23]
Sam3d: Segment anything in 3d scenes.arXiv preprint arXiv:2306.03908, 2023
Yunhan Yang, Xiaoyang Wu, Tong He, Hengshuang Zhao, and Xihui Liu. Sam3d: Segment anything in 3d scenes.arXiv preprint arXiv:2306.03908, 2023. 2
-
[24]
Ptq4vit: Post-training quantization for vision transformers with twin uniform quantization
Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, and Guangyu Sun. Ptq4vit: Post-training quantization for vision transformers with twin uniform quantization. InEuropean conference on computer vision, pages 191–207. Springer,
-
[25]
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. Faster segment anything: Towards lightweight sam for mo- bile applications.arXiv preprint arXiv:2306.14289, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Erq: Error reduction for post-training quan- tization of vision transformers
Yunshan Zhong, Jiawei Hu, You Huang, Yuxin Zhang, and Rongrong Ji. Erq: Error reduction for post-training quan- tization of vision transformers. InForty-first International Conference on Machine Learning, 2024. 3
work page 2024
-
[27]
Chong Zhou, Xiangtai Li, Chen Change Loy, and Bo Dai. Edgesam: Prompt-in-the-loop distillation for on-device de- ployment of sam.arXiv preprint arXiv:2312.06660, 2023. 2
-
[28]
Zhuyun Zhou, Zongwei Wu, R ´emi Boutteau, Fan Yang, and Dominique Ginhac. Dsec-mos: Segment any moving object with moving ego vehicle.arXiv preprint arXiv:2305.00126, 3(6), 2023. 2
-
[29]
arXiv preprint arXiv:2408.00874 (2024)
Jiayuan Zhu, Abdullah Hamdi, Yunli Qi, Yueming Jin, and Junde Wu. Medical sam 2: Segment medical images as video via segment anything model 2.arXiv preprint arXiv:2408.00874, 2024. 2 CAR-SAM: Cross-Attention Reconstruction for Post-Training Quantization of the Segment Anything Model Supplementary Material A. The Derivation of Matmul Compensation A.1. Prop...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.