A Single-Loop Regularized Newton Method for Nonconvex-Strongly-Concave Minimax Optimization
Pith reviewed 2026-06-27 21:30 UTC · model grok-4.3
The pith
A single-loop regularized Newton method achieves the optimal global complexity for nonconvex-strongly-concave minimax problems while attaining local superlinear convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors propose a single-loop framework for smooth nonconvex-strongly-concave minimax problems via an equivalent regularized minimization reformulation. Using a new adaptive cubic-quadratic majorization to dynamically absorb non-Lipschitz components of the reformulated Hessian, they obtain a regularized Newton method with O(ε^{-1.5}) global iteration complexity and automatic local superlinear rate in the deterministic setting, and O(ε^{-3}) gradient plus O(ε^{-2}) Hessian complexities in the stochastic setting via recursive variance reduction, improving prior double-loop results by O(ε^{-0.5}) factors.
What carries the argument
The adaptive cubic-quadratic majorization applied to the Hessian of the regularized minimization reformulation, which enables the single-loop structure without inner-loop bottlenecks.
If this is right
- Matches the O(ε^{-1.5}) global iteration complexity of existing double-loop second-order methods for deterministic problems.
- Automatically achieves a local superlinear convergence rate unavailable in double-loop approaches due to inner-loop accuracy requirements.
- Achieves O(ε^{-3}) gradient and O(ε^{-2}) Hessian complexities in stochastic settings, improving double-loop methods by O(ε^{-0.5}) factors.
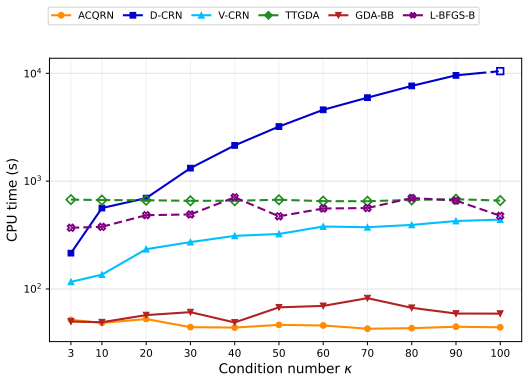
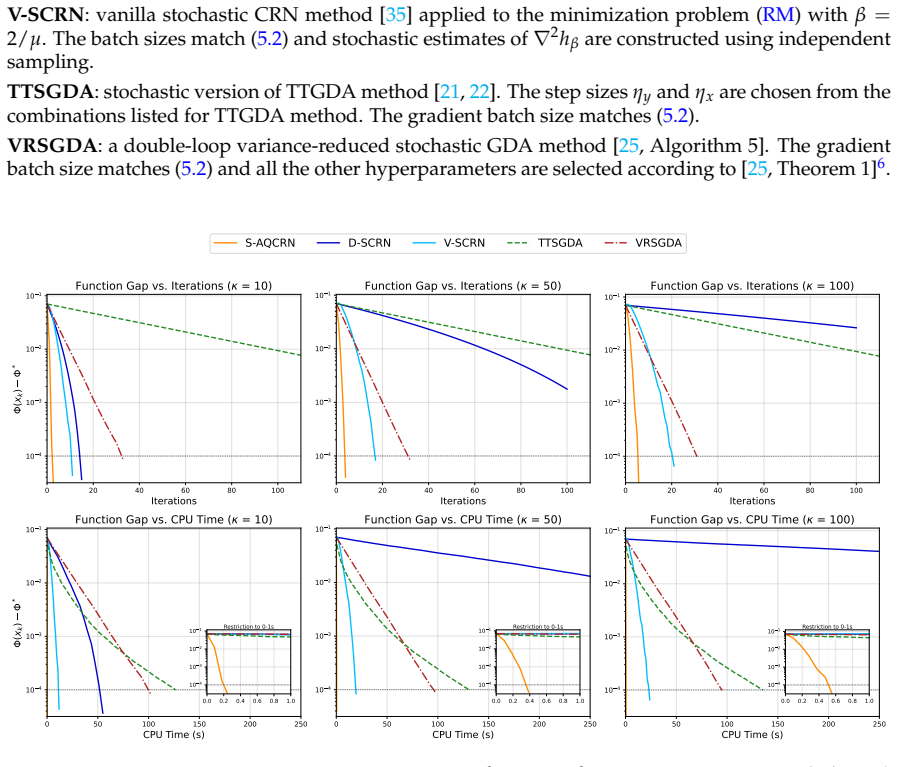
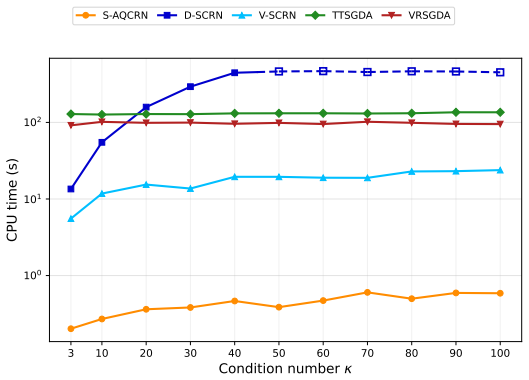
- Significantly outperforms benchmark methods in both deterministic and stochastic experiments, including under mild conditioning.
- Closes a gap in stochastic second-order methods for nonconvex minimization as a byproduct.
Where Pith is reading between the lines
- The single-loop design may allow second-order methods to handle more ill-conditioned minimax problems without first-order inner solvers.
- The reformulation technique could be adapted to other classes of minimax or saddle-point problems beyond strong concavity.
- The variance reduction integration suggests potential for similar improvements in other stochastic second-order optimization algorithms.
- Experimental speedups indicate practical advantages for large-scale applications where double-loop overhead is costly.
Load-bearing premise
The nonconvex-strongly-concave minimax problem admits an equivalent regularized minimization reformulation whose Hessian can be dynamically majorized by an adaptive cubic-quadratic model without changing the solution set or adding new stationary points.
What would settle it
An instance of a nonconvex-strongly-concave minimax problem where applying the regularized reformulation either alters the stationary points or where the method's iteration count exceeds O(ε^{-1.5}) on deterministic instances.
Figures

read the original abstract
For smooth nonconvex-strongly-concave minimax problems, existing second-order methods share a common double-loop structure where the inner maximization is solved to sufficiently high accuracy before each second-order step. First-order methods are often adopted in the inner loops for scalability, but they also undermine the condition-insensitivity of second-order methods, limiting these methods to instances with mild conditioning. To resolve this issue, we propose a novel single-loop framework based on an equivalent regularized minimization reformulation of the original problem. By deriving a new adaptive cubic-quadratic majorization to dynamically absorb the non-Lipschitz components of the reformulated Hessian, we establish a regularized Newton method with robust theoretical guarantees across multiple settings. For deterministic problems, our single-loop method matches the $\mathcal{O}(\varepsilon^{-1.5})$ global iteration complexity of the existing double-loop second-order methods, while automatically achieving a local superlinear rate that is unavailable in existing works due to the inner-loop bottleneck. For the stochastic setting, we achieve $\mathcal{O}(\varepsilon^{-3})$ gradient and $\mathcal{O}(\varepsilon^{-2})$ Hessian complexities by integrating a recursive variance reduction, strictly improving those of the double-loop methods by $\mathcal{O}(\varepsilon^{-0.5})$ factors. In both deterministic and stochastic experiments, our methods significantly outperform the benchmarks, offering substantial speedups over the double-loop methods even under mildly conditioned instances. As a byproduct of our analysis, we close a gap in stochastic second-order methods for nonconvex minimization, where the best known result contains a nontrivial technical issue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a single-loop regularized Newton method for smooth nonconvex-strongly-concave minimax optimization. It introduces an equivalent regularized minimization reformulation of the original problem, derives a new adaptive cubic-quadratic majorization to handle the non-Lipschitz components of the reformulated Hessian, and develops a regularized Newton algorithm with global iteration complexity O(ε^{-1.5}) in the deterministic setting (matching existing double-loop second-order methods) and O(ε^{-3}) gradient / O(ε^{-2}) Hessian complexity in the stochastic setting (improving double-loop methods by O(ε^{-0.5}) factors), plus an automatic local superlinear rate. Experiments show practical speedups.
Significance. If the reformulation equivalence and majorization validity hold without introducing extraneous stationary points, the result would be significant: it removes the inner-loop bottleneck of prior second-order minimax methods while preserving condition-insensitive rates and adding superlinear local convergence, and closes a noted gap in stochastic second-order nonconvex minimization. The single-loop structure and variance-reduced stochastic extension are technically novel contributions.
major comments (3)
- [§3] §3 (Regularized Reformulation): The central claim that the regularized minimization problem is exactly equivalent to the original minimax problem (same stationary points, no new critical points introduced by the regularization parameter) is load-bearing for all complexity transfers. The manuscript asserts this equivalence but the provided derivation does not explicitly verify that the stationarity condition ∇_x L_λ(x,y*) = 0 coincides with the original minimax stationarity (e.g., via explicit KKT equivalence or showing that any critical point of the regularized objective satisfies the original saddle-point condition for the chosen λ).
- [§4] §4 (Adaptive Majorization): The adaptive cubic-quadratic majorization is claimed to dynamically absorb non-Lipschitz terms of the reformulated Hessian while preserving the critical-point condition. The error bound between the majorizing model and the true Hessian must be shown to vanish at stationary points without altering the Newton direction's descent property for the original (non-regularized) objective; the current argument appears to rely on the strong-concavity parameter but lacks an explicit verification that the majorization constant choice does not bias the stationary set.
- [Theorem 5.1] Theorem 5.1 / Corollary 5.2 (Deterministic Complexity): The O(ε^{-1.5}) global rate and local superlinear rate are derived under the reformulation; if the equivalence in §3 fails to hold exactly, these rates apply only to the auxiliary regularized problem and do not transfer to the original minimax instance, undermining the comparison to double-loop baselines.
minor comments (2)
- [Algorithm 1] Notation for the regularization parameter λ is introduced without an explicit range or selection rule in the main algorithm statement; clarify whether λ is fixed or adapted and how it interacts with the strong-concavity modulus.
- [§6] The stochastic variance-reduction analysis cites a recursive estimator but does not include a self-contained lemma bounding the bias introduced by the majorization under stochastic Hessian estimates.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive feedback on the equivalence and majorization arguments. We address each major comment below with clarifications and commit to strengthening the explicit verifications in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Regularized Reformulation): The central claim that the regularized minimization problem is exactly equivalent to the original minimax problem (same stationary points, no new critical points introduced by the regularization parameter) is load-bearing for all complexity transfers. The manuscript asserts this equivalence but the provided derivation does not explicitly verify that the stationarity condition ∇_x L_λ(x,y*) = 0 coincides with the original minimax stationarity (e.g., via explicit KKT equivalence or showing that any critical point of the regularized objective satisfies the original saddle-point condition for the chosen λ).
Authors: We appreciate this observation. The equivalence follows because the regularization is applied only to the x-variable and is constructed so that its gradient vanishes identically at any point where the original minimax stationarity condition holds (due to the strong-concavity-induced relation between y* and x). Any critical point of the regularized problem therefore satisfies the original first-order saddle-point condition, and conversely. To make this fully explicit we will insert a dedicated lemma (with KKT-style verification) in §3 of the revision. revision: yes
-
Referee: [§4] §4 (Adaptive Majorization): The adaptive cubic-quadratic majorization is claimed to dynamically absorb non-Lipschitz terms of the reformulated Hessian while preserving the critical-point condition. The error bound between the majorizing model and the true Hessian must be shown to vanish at stationary points without altering the Newton direction's descent property for the original (non-regularized) objective; the current argument appears to rely on the strong-concavity parameter but lacks an explicit verification that the majorization constant choice does not bias the stationary set.
Authors: The adaptive choice of the cubic and quadratic coefficients is made precisely so that the modeling error is proportional to the distance to stationarity and therefore vanishes at any stationary point; the strong-concavity parameter enters only the adaptation rule and does not shift the location of critical points. The descent property is inherited by the original objective because the majorizer is used only to generate the Newton step while the actual line search is performed on the regularized (hence equivalent) objective. We will add an explicit paragraph after the majorization definition proving that the stationary sets coincide and that the error term is zero at stationarity. revision: yes
-
Referee: [Theorem 5.1] Theorem 5.1 / Corollary 5.2 (Deterministic Complexity): The O(ε^{-1.5}) global rate and local superlinear rate are derived under the reformulation; if the equivalence in §3 fails to hold exactly, these rates apply only to the auxiliary regularized problem and do not transfer to the original minimax instance, undermining the comparison to double-loop baselines.
Authors: Once the equivalence lemma requested in comment 1 is added, the complexity statements transfer verbatim to the original problem. The local superlinear rate likewise carries over because the Newton step is taken on an objective whose critical points are identical to those of the original minimax problem. No change to the theorem statements themselves is required beyond the supporting lemma in §3. revision: no
Circularity Check
No circularity: derivation relies on explicit reformulation and majorization analysis
full rationale
The paper constructs its single-loop method from an explicit regularized minimization reformulation of the minimax problem together with a derived adaptive cubic-quadratic majorization of the Hessian. The claimed iteration complexities follow from standard analysis of this construction rather than from any fitted parameter, self-citation chain, or definitional renaming. No equation or claim in the abstract reduces the stated rates or the equivalence property to quantities defined by the outputs themselves. The equivalence is asserted as a property of the reformulation and is not shown to be tautological within the given text.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization parameter
axioms (1)
- domain assumption The minimax objective is smooth, nonconvex in the minimization variable and strongly concave in the maximization variable.
Reference graph
Works this paper leans on
-
[1]
On the convergence of the proximal algorithm for nonsmooth functions involving analytic features.Math
Hedy Attouch and J ´erˆome Bolte. On the convergence of the proximal algorithm for nonsmooth functions involving analytic features.Math. Program., 116(1-2, Ser. B):5–16, 2009
2009
-
[2]
Proximal alternating min- imization and projection methods for nonconvex problems: an approach based on the Kurdyka- Łojasiewicz inequality.Math
H ´edy Attouch, J´erˆome Bolte, Patrick Redont, and Antoine Soubeyran. Proximal alternating min- imization and projection methods for nonconvex problems: an approach based on the Kurdyka- Łojasiewicz inequality.Math. Oper. Res., 35(2):438–457, 2010
2010
-
[3]
Convergence of descent methods for semi- algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods.Math
Hedy Attouch, J ´erˆome Bolte, and Benar Fux Svaiter. Convergence of descent methods for semi- algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods.Math. Program., 137(1-2, Ser. A):91–129, 2013
2013
-
[4]
Beaton and John W
Albert E. Beaton and John W. Tukey. The fitting of power series, meaning polynomials, illus- trated on band-spectroscopic data.Technometrics, 16(2):147–185, 1974
1974
-
[5]
Proximal alternating linearized minimization for nonconvex and nonsmooth problems.Math
J ´erˆome Bolte, Shoham Sabach, and Marc Teboulle. Proximal alternating linearized minimization for nonconvex and nonsmooth problems.Math. Program., 146(1-2, Ser. A):459–494, 2014
2014
-
[6]
D. L. Burkholder, B. J. Davis, and R. F. Gundy. Integral inequalities for convex functions of operators on martingales. InProceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability (Univ. California, Berkeley, Calif., 1970/1971), Vol. II: Probability theory, pages 223– 240, 1972
1970
-
[7]
Sharp inequalities for martingales and stochastic integrals.Ast´ erisque, 157(158):75–94, 1988
Donald L Burkholder. Sharp inequalities for martingales and stochastic integrals.Ast´ erisque, 157(158):75–94, 1988. 26
1988
-
[8]
convex until proven guilty
Yair Carmon, John C Duchi, Oliver Hinder, and Aaron Sidford. “convex until proven guilty”: Dimension-free acceleration of gradient descent on non-convex functions. InInternational confer- ence on machine learning, pages 654–663. PMLR, 2017
2017
-
[9]
Adaptive cubic regularisation methods for unconstrained optimization
Coralia Cartis, Nicholas IM Gould, and Philippe L Toint. Adaptive cubic regularisation methods for unconstrained optimization. part i: motivation, convergence and numerical results.Math. Program., 127(2):245–295, 2011
2011
-
[10]
Adaptive cubic regularisation methods for unconstrained optimization
Coralia Cartis, Nicholas IM Gould, and Philippe L Toint. Adaptive cubic regularisation methods for unconstrained optimization. part ii: worst-case function-and derivative-evaluation complex- ity.Math. Program., 130(2):295–319, 2011
2011
-
[11]
Improving stochastic cubic newton with momentum
El Mahdi Chayti, Nikita Doikov, and Martin Jaggi. Improving stochastic cubic newton with momentum. InProceedings of The 28th International Conference on Artificial Intelligence and Statistics. PMLR, 2025
2025
-
[12]
Jia-Hao Chen, Zi Xu, and Hui-Ling Zhang. A homogeneous second-order descent ascent algo- rithm for nonconvex-strongly concave minimax problems.arXiv preprint arXiv:2602.14058, 2026
arXiv 2026
-
[13]
Near-optimal nonconvex-strongly-convex bilevel optimization with fully first-order oracles.Journal of Machine Learning Research, 26(109):1–56, 2025
Lesi Chen, Yaohua Ma, and Jingzhao Zhang. Near-optimal nonconvex-strongly-convex bilevel optimization with fully first-order oracles.Journal of Machine Learning Research, 26(109):1–56, 2025
2025
-
[14]
A cubic regularization approach for finding local minimax points in nonconvex minimax optimization.Trans
Ziyi Chen, Zhengyang Hu, Qunwei Li, Zhe Wang, and Yi Zhou. A cubic regularization approach for finding local minimax points in nonconvex minimax optimization.Trans. Mach. Learn. Res., 2023
2023
-
[15]
Generative adversarial networks.Commun
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commun. ACM, 63(11):139–144, 2020
2020
-
[16]
On gradients of functions definable in o-minimal structures.Ann
Krzysztof Kurdyka. On gradients of functions definable in o-minimal structures.Ann. Inst. Fourier (Grenoble), 48(3):769–783, 1998
1998
-
[17]
A fully first-order method for stochastic bilevel optimization
Jeongyeol Kwon, Dohyun Kwon, Stephen Wright, and Robert D Nowak. A fully first-order method for stochastic bilevel optimization. InInternational Conference on Machine Learning, pages 18083–18113. PMLR, 2023
2023
-
[18]
Ching-pei Lee and Stephen J. Wright. Inexact variable metric stochastic block-coordinate descent for regularized optimization.J. Optim. Theory Appl., 185(1):151–187, 2020
2020
-
[19]
Guoyin Li, Boris Mordukhovich, and Jiangxing Zhu. Generalized metric subregularity with applications to high-order regularized newton methods.arXiv preprint arXiv:2406.13207, 2024
arXiv 2024
-
[20]
Tiada: A time-scale adaptive algorithm for nonconvex minimax optimization
Xiang Li, Junchi Yang, and Niao He. Tiada: A time-scale adaptive algorithm for nonconvex minimax optimization. InThe Eleventh International Conference on Learning Representations (ICLR 2023), 2023
2023
-
[21]
On gradient descent ascent for nonconvex-concave minimax problems
Tianyi Lin, Chi Jin, and Michael Jordan. On gradient descent ascent for nonconvex-concave minimax problems. InInternational conference on machine learning, pages 6083–6093. PMLR, 2020
2020
-
[22]
Two-timescale gradient descent ascent algorithms for nonconvex minimax optimization.J
Tianyi Lin, Chi Jin, and Michael I Jordan. Two-timescale gradient descent ascent algorithms for nonconvex minimax optimization.J. Mach. Learn. Res., 26(11):1–45, 2025
2025
-
[23]
Institut des Hautes Etudes Scientifiques, 1965
Stanislaw Łojasiewicz.Ensembles semi-analytiques. Institut des Hautes Etudes Scientifiques, 1965
1965
-
[24]
Finding second-order stationary points in nonconvex- strongly-concave minimax optimization.Adv
Luo Luo, Yujun Li, and Cheng Chen. Finding second-order stationary points in nonconvex- strongly-concave minimax optimization.Adv. Neural Inf. Process. Syst., 35:36667–36679, 2022. 27
2022
-
[25]
Stochastic recursive gradient descent ascent for stochastic nonconvex-strongly-concave minimax problems.Advances in neural infor- mation processing systems, 33:20566–20577, 2020
Luo Luo, Haishan Ye, Zhichao Huang, and Tong Zhang. Stochastic recursive gradient descent ascent for stochastic nonconvex-strongly-concave minimax problems.Advances in neural infor- mation processing systems, 33:20566–20577, 2020
2020
-
[26]
Line-search and adaptive step sizes for nonconvex- strongly-concave minimax optimization, 2026
Bohao Ma, Nachuan Xiao, and Junyu Zhang. Line-search and adaptive step sizes for nonconvex- strongly-concave minimax optimization, 2026
2026
-
[27]
Tight analysis of extra- gradient and optimistic gradient methods for nonconvex minimax problems.Adv
Pouria Mahdavinia, Yuyang Deng, Haochuan Li, and Mehrdad Mahdavi. Tight analysis of extra- gradient and optimistic gradient methods for nonconvex minimax problems.Adv. Neural Inf. Process. Syst., 35:31213–31225, 2022
2022
-
[28]
Cubic regularization of newton method and its global per- formance.Mathematical programming, 108(1):177–205, 2006
Yurii Nesterov and Boris T Polyak. Cubic regularization of newton method and its global per- formance.Mathematical programming, 108(1):177–205, 2006
2006
-
[29]
Sarah: A novel method for ma- chine learning problems using stochastic recursive gradient
Lam M Nguyen, Jie Liu, Katya Scheinberg, and Martin Tak ´aˇc. Sarah: A novel method for ma- chine learning problems using stochastic recursive gradient. InInternational conference on machine learning, pages 2613–2621. PMLR, 2017
2017
-
[30]
Regularization properties of adversarially-trained linear regression.Adv
Antonio Ribeiro, Dave Zachariah, Francis Bach, and Thomas Sch ¨on. Regularization properties of adversarially-trained linear regression.Adv. Neural Inf. Process. Syst., 36:23658–23670, 2023
2023
-
[31]
A newton-cg algorithm with complex- ity guarantees for smooth unconstrained optimization.Math
Cl ´ement W Royer, Michael O’Neill, and Stephen J Wright. A newton-cg algorithm with complex- ity guarantees for smooth unconstrained optimization.Math. Program., 180(1):451–488, 2020
2020
-
[32]
Distribution- ally robust logistic regression.Adv
Soroosh Shafieezadeh Abadeh, Peyman M Mohajerin Esfahani, and Daniel Kuhn. Distribution- ally robust logistic regression.Adv. Neural Inf. Process. Syst., 28, 2015
2015
-
[33]
Aman Sinha, Hongseok Namkoong, Riccardo Volpi, and John Duchi. Certifying some distribu- tional robustness with principled adversarial training.arXiv preprint arXiv:1710.10571, 2017
arXiv 2017
-
[34]
A globally convergent newton method for solving strongly monotone variational inequalities.Mathematical programming, 58(1):369–383, 1993
Kouichi Taji, Masao Fukushima, and Toshihide Ibaraki. A globally convergent newton method for solving strongly monotone variational inequalities.Mathematical programming, 58(1):369–383, 1993
1993
-
[35]
Stochastic cubic regularization for fast nonconvex optimization.Advances in neural information processing systems, 31, 2018
Nilesh Tripuraneni, Mitchell Stern, Chi Jin, Jeffrey Regier, and Michael I Jordan. Stochastic cubic regularization for fast nonconvex optimization.Advances in neural information processing systems, 31, 2018
2018
-
[36]
Gradient norm regularization second-order algorithms for solving nonconvex-strongly concave minimax problems.Journal of Scientific Computing, 105(2):41, 2025
Junlin Wang and Zi Xu. Gradient norm regularization second-order algorithms for solving nonconvex-strongly concave minimax problems.Journal of Scientific Computing, 105(2):41, 2025
2025
-
[37]
Efficient first order method for saddle point problems with higher order smoothness.SIAM J
Nuozhou Wang, Junyu Zhang, and Shuzhong Zhang. Efficient first order method for saddle point problems with higher order smoothness.SIAM J. Optim., 34(4):3342–3370, 2024
2024
-
[38]
Stochastic variance-reduced cubic regu- larization for nonconvex optimization
Zhe Wang, Yi Zhou, Yingbin Liang, and Guanghui Lan. Stochastic variance-reduced cubic regu- larization for nonconvex optimization. InThe 22nd International Conference on Artificial Intelligence and Statistics, pages 2731–2740. PMLR, 2019
2019
-
[39]
A unified single-loop alternating gradient projection algorithm for nonconvex–concave and convex–nonconcave minimax problems.Math
Zi Xu, Huiling Zhang, Yang Xu, and Guanghui Lan. A unified single-loop alternating gradient projection algorithm for nonconvex–concave and convex–nonconcave minimax problems.Math. Program., 201(1):635–706, 2023
2023
-
[40]
Sheng Yang, Chengchang Liu, Lesi Chen, and John Lui. Second-order bilevel optimization with accelerated convergence rates.arXiv preprint arXiv:2605.06431, 2026
Pith/arXiv arXiv 2026
-
[41]
Yiming Yang, Chuan He, Xiao Wang, and Zheng Peng. Faster stochastic cubic regularized new- ton methods with momentum.arXiv preprint arXiv:2507.13003, 2025
arXiv 2025
-
[42]
A homogeneous second-order descent method for nonconvex optimization.Mathematics of Operations Research, 2025
Chuwen Zhang, Chang He, Yuntian Jiang, Chenyu Xue, Bo Jiang, Dongdong Ge, and Yinyu Ye. A homogeneous second-order descent method for nonconvex optimization.Mathematics of Operations Research, 2025. 28
2025
-
[43]
Adaptive stochastic variance reduction for sub- sampled newton method with cubic regularization.INFORMS Journal on Optimization, 4(1):45– 64, 2022
Junyu Zhang, Lin Xiao, and Shuzhong Zhang. Adaptive stochastic variance reduction for sub- sampled newton method with cubic regularization.INFORMS Journal on Optimization, 4(1):45– 64, 2022
2022
-
[44]
Stochastic recursive variance-reduced cubic regularization methods
Dongruo Zhou and Quanquan Gu. Stochastic recursive variance-reduced cubic regularization methods. InInternational conference on artificial intelligence and statistics, pages 3980–3990. PMLR, 2020. 29
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.