Humanizing Automatically Generated Unit Test Suites with LLM-Based Refactoring
Pith reviewed 2026-06-29 02:57 UTC · model grok-4.3
The pith
LLM refactoring of EvoSuite suites yields 88-98% compilation while preserving coverage and boosting readability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
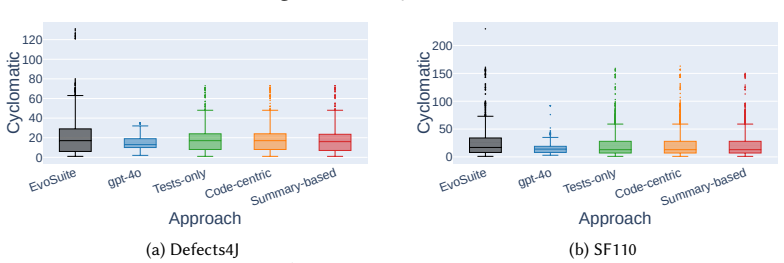
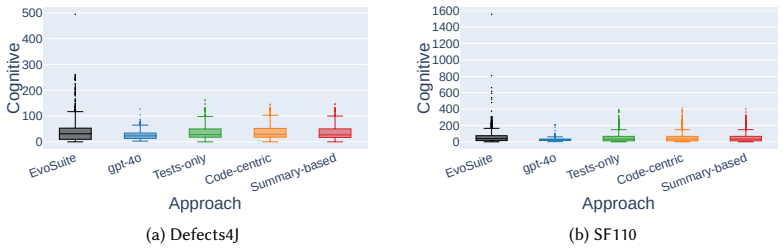
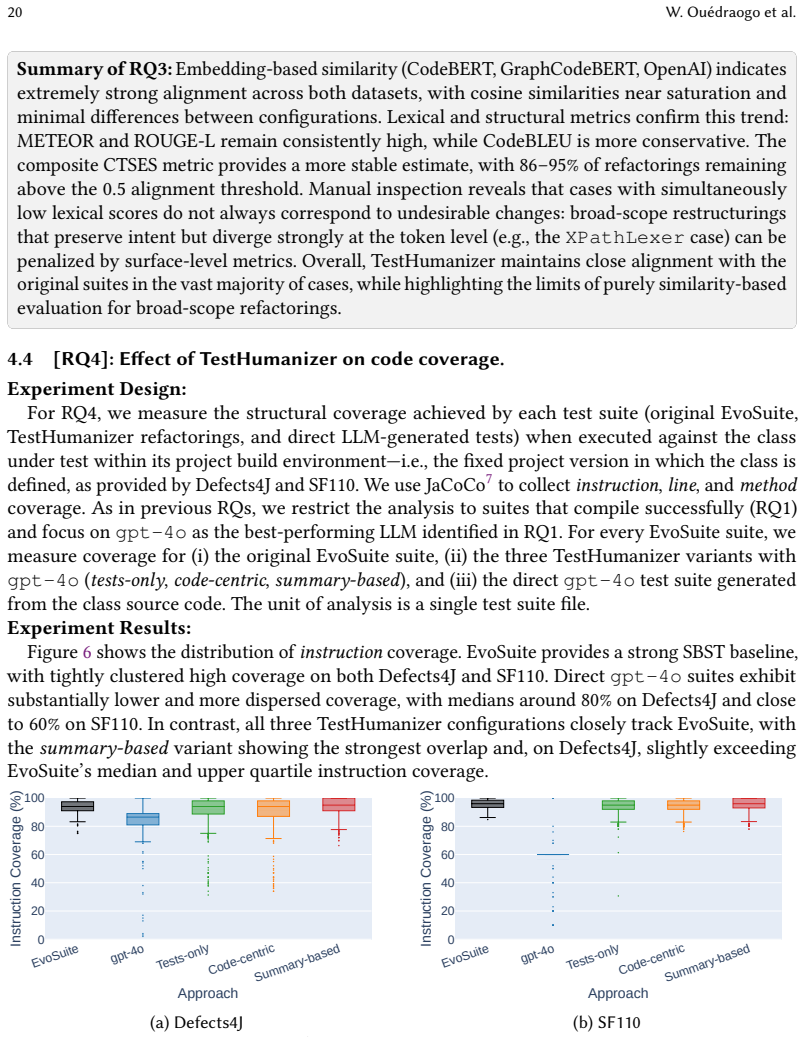
TestHumanizer reaches 88-98% compilation rates on refactored suites, close to EvoSuite's 100% baseline, with structural coverage preserved within 1-2 percentage points and 86-95% of refactorings satisfying a composite faithful-refactoring threshold, while also improving predicted readability and reducing complexity.
What carries the argument
TestHumanizer, a hybrid pipeline that applies LLMs as validation-gated refactoring layers over SBST suites under summary-based, code-centric, and other context configurations.
If this is right
- Structural coverage remains within 1-2 percentage points of the original EvoSuite suites.
- 86-95% of the produced refactorings satisfy the composite faithful-refactoring threshold.
- Refactored suites reduce control-flow complexity, cognitive complexity, and structural smells.
- The summary-based context configuration delivers the most robust trade-off between success rate and quality.
Where Pith is reading between the lines
- Standalone LLM test generation would likely need post-generation validation steps to approach the reliability of the hybrid approach.
- The same refinement layer could be applied to outputs from other search-based or random test generators.
- The results point to a general pattern in which generative models function best when gated by outputs from established automated methods.
Load-bearing premise
LLM refactoring preserves the original test semantics and intent even when only checked via compilation success and line or branch coverage.
What would settle it
A refactored test that compiles and reports matching coverage yet fails on an input where the original test passes, or passes where the original fails.
Figures


read the original abstract
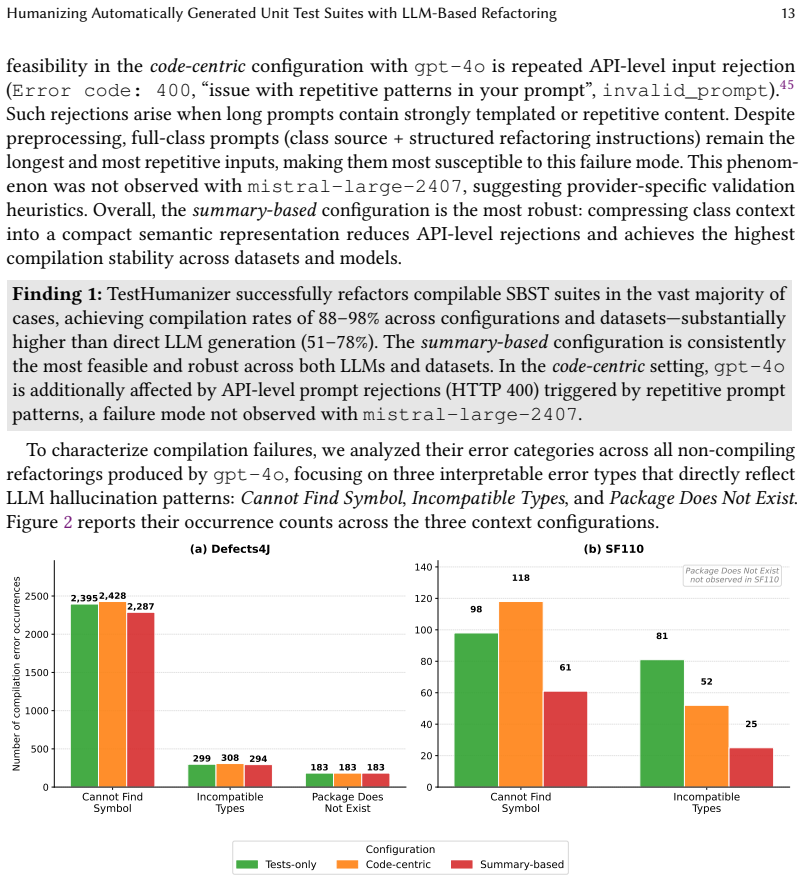
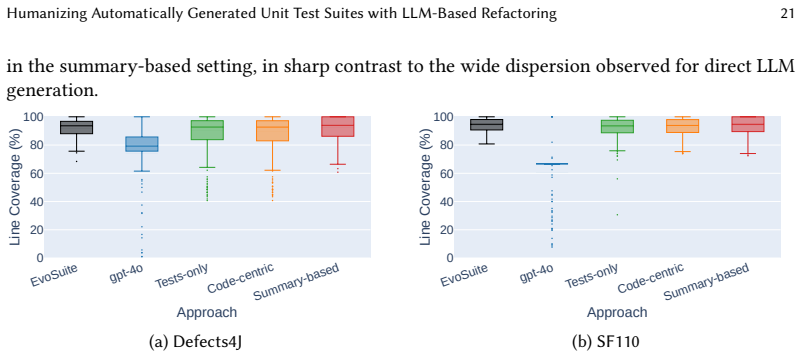
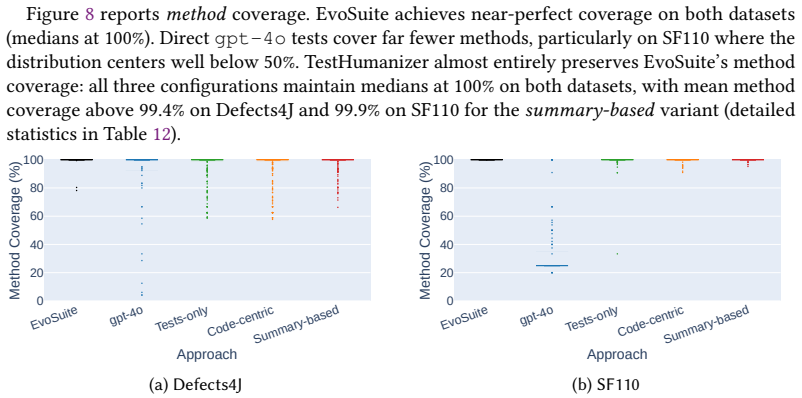
Search-based test generation tools such as EvoSuite produce compilable and high-coverage unit tests at scale, but their suites are often hard to read and maintain. LLMs can generate more natural tests, yet direct generation remains brittle, with compilation rates of only 51-78% in our study. We introduce TestHumanizer, a hybrid SBST+LLM approach that uses LLMs as controlled refactoring layers over compilable SBST suites to improve naming, structure, and developer-oriented clarity while preserving behavior and compilation validity. We evaluate TestHumanizer on 350 classes from Defects4J and SF110. EvoSuite generates 15 suites per class, and each suite is refactored under three context configurations using gpt-4o and mistral-large-2407, yielding 31,500 refactorings. TestHumanizer reaches 88-98% compilation rates, close to EvoSuite's 100% baseline and clearly above direct LLM generation. Structural coverage is largely preserved, typically within 1-2 percentage points, and 86-95% of refactorings satisfy a composite faithful-refactoring threshold. Refactored suites also improve predicted readability, reduce control-flow and cognitive complexity, and mitigate structural smells. The summary-based setting offers the most robust trade-off, while long code-centric prompts are more prone to hallucination-induced failures. A developer study on 30 classes and 444 test methods confirms significant gains in perceived readability and willingness to adopt, with Wilcoxon p less than 0.01 and substantial inter-rater agreement. Overall, LLMs are most effective not as standalone generators but as validation-gated refinement layers over robust SBST outputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
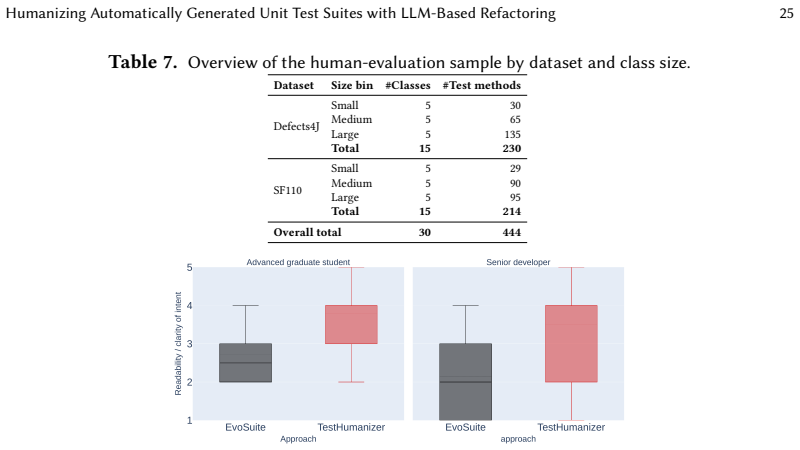
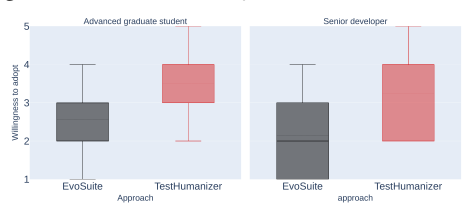
Summary. The paper introduces TestHumanizer, a hybrid SBST+LLM refactoring approach that applies LLMs (gpt-4o, mistral-large-2407) to EvoSuite-generated test suites on 350 classes from Defects4J and SF110. It generates 31,500 refactorings across three context configurations, reporting 88-98% compilation rates (vs. 51-78% for direct LLM generation), structural coverage preservation within 1-2pp, 86-95% of refactorings meeting a composite faithful-refactoring threshold, reductions in complexity/smells, and a developer study (30 classes, 444 methods) showing significant readability gains (Wilcoxon p<0.01).
Significance. If the preservation claims hold, the work demonstrates a scalable, validation-gated use of LLMs as refinement layers over robust SBST outputs rather than standalone generators. The large-scale empirical results (31,500 refactorings) plus controlled developer study with statistical tests provide concrete evidence for improved readability and adoptability of automated tests, with the summary-based configuration identified as the best trade-off.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: The headline 86-95% 'faithful-refactoring' rate rests on a composite threshold (compilation success + structural coverage within 1-2pp). This threshold is load-bearing for the central preservation claim yet appears insufficient to rule out semantic alterations to assertions, preconditions, or exception expectations, which would still satisfy line/branch coverage. No differential execution, assertion-equivalence checks, or mutation-score comparison is described.
- [Developer study] Developer study (30 classes): While Wilcoxon tests show p<0.01 for readability, the study design does not report whether participants were shown the original EvoSuite suite alongside the refactored version or whether they executed the tests; this limits the strength of the 'willingness to adopt' conclusion relative to the preservation claims.
minor comments (2)
- [Method] The three context configurations (summary-based, code-centric, long code-centric) are referenced but their exact prompt templates and token budgets should be provided in an appendix or table for reproducibility.
- [Results] Table or figure reporting per-configuration hallucination rates and failure modes would clarify why long prompts are 'more prone to hallucination-induced failures'.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below, with revisions planned where the evaluation can be strengthened or clarified without misrepresenting the current results.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The headline 86-95% 'faithful-refactoring' rate rests on a composite threshold (compilation success + structural coverage within 1-2pp). This threshold is load-bearing for the central preservation claim yet appears insufficient to rule out semantic alterations to assertions, preconditions, or exception expectations, which would still satisfy line/branch coverage. No differential execution, assertion-equivalence checks, or mutation-score comparison is described.
Authors: We acknowledge that the composite threshold (successful compilation plus structural coverage within 1-2pp) does not provide a complete guarantee against semantic changes to assertions, preconditions, or exception expectations. Coverage preservation serves as a practical proxy for behavioral similarity in a refactoring setting, but it is not equivalent to mutation analysis or differential execution. In the revised manuscript we will (1) explicitly state this limitation in the threats-to-validity section and (2) add a short discussion of why coverage was chosen as the primary metric given the scale of 31,500 refactorings. We will also report any post-hoc assertion-change statistics that can be computed from the existing data without new experiments. Full mutation-score comparisons would require substantial additional computation and are noted as future work. revision: partial
-
Referee: [Developer study] Developer study (30 classes): While Wilcoxon tests show p<0.01 for readability, the study design does not report whether participants were shown the original EvoSuite suite alongside the refactored version or whether they executed the tests; this limits the strength of the 'willingness to adopt' conclusion relative to the preservation claims.
Authors: The developer study collected ratings on readability and willingness to adopt for the refactored suites. The manuscript does not currently detail the exact presentation protocol or whether participants executed the tests. We will revise the study-design subsection to clarify that (a) participants evaluated each refactored suite after being told it was derived from an EvoSuite baseline (but were not shown the original side-by-side for every rating), and (b) the study was a perception survey and did not require test execution. These clarifications will be added to the revised version so that the strength of the adoption claims is accurately represented. revision: yes
Circularity Check
No circularity: empirical evaluation on external benchmarks
full rationale
The paper is a purely empirical study that applies LLMs as a post-processing layer to EvoSuite-generated test suites, then measures compilation success, structural coverage preservation, readability metrics, and developer perception on fixed external benchmarks (Defects4J, SF110). No equations, fitted parameters, or self-defined quantities appear; the reported percentages (88-98% compilation, 86-95% faithful refactorings) are direct counts of outcomes against independently defined criteria rather than quantities that reduce to the inputs by construction. The composite threshold is a reporting filter, not a self-referential derivation. No load-bearing self-citations or uniqueness theorems are invoked. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based refactoring preserves test behavior when compilation and structural coverage remain within small thresholds
Reference graph
Works this paper leans on
-
[1]
Toufique Ahmed and Premkumar Devanbu. 2022. Few-shot training LLMs for project-specific code-summarization. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–5
2022
-
[2]
Toufique Ahmed, Kunal Suresh Pai, Premkumar Devanbu, and Earl T Barr. 2024. Automatic semantic augmentation of language model prompts (for code summarization). In 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE).IEEE Computer Society(2024), 1004–1004
2024
-
[3]
M Moein Almasi, Hadi Hemmati, Gordon Fraser, Andrea Arcuri, and Janis Benefelds. 2017. An industrial evaluation of unit test generation: Finding real faults in a financial application. In2017 IEEE/ACM 39th International Conference on Software Engineering: Software Engineering in Practice Track (ICSE-SEIP). IEEE, 263–272
2017
-
[4]
Andrea Arcuri and Gordon Fraser. 2013. Parameter tuning or default values? An empirical investigation in search-based software engineering.Empirical Software Engineering18 (2013), 594–623
2013
-
[5]
Alberto Bacchelli, Paolo Ciancarini, and Davide Rossi. 2008. On the effectiveness of manual and automatic unit test generation. In2008 The Third International Conference on Software Engineering Advances. IEEE, 252–257
2008
-
[6]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine J. ACM, Vol. 1, No. 1, Article . Publication date: June 2026. Humanizing Automatically Generated Unit Test Suites with LLM-Based ...
2005
-
[7]
Gabriele Bavota, Abdallah Qusef, Rocco Oliveto, Andrea De Lucia, and David Binkley. 2012. An empirical analysis of the distribution of unit test smells and their impact on software maintenance. In2012 28th IEEE international conference on software maintenance (ICSM). IEEE, 56–65
2012
-
[8]
Gabriele Bavota, Abdallah Qusef, Rocco Oliveto, Andrea De Lucia, and Dave Binkley. 2015. Are test smells really harmful? an empirical study.Empirical Software Engineering20 (2015), 1052–1094
2015
-
[9]
2000.Extreme programming explained: embrace change
Kent Beck. 2000.Extreme programming explained: embrace change. addison-wesley professional
2000
-
[10]
Shreya Bhatia, Tarushi Gandhi, Dhruv Kumar, and Pankaj Jalote. 2024. Unit test generation using generative ai: A comparative performance analysis of autogeneration tools. InProceedings of the 1st International Workshop on Large Language Models for Code. 54–61
2024
-
[11]
Matteo Biagiola, Gianluca Ghislotti, and Paolo Tonella. 2025. Improving the readability of automatically generated tests using large language models. In2025 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 162–173
2025
-
[12]
Raymond PL Buse and Westley R Weimer. 2009. Learning a metric for code readability.IEEE Transactions on software engineering36, 4 (2009), 546–558
2009
-
[13]
G Ann Campbell. 2018. Cognitive complexity: An overview and evaluation. InProceedings of the 2018 international conference on technical debt. 57–58
2018
-
[14]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
Pith/arXiv arXiv 2021
-
[15]
Ermira Daka, José Campos, Gordon Fraser, Jonathan Dorn, and Westley Weimer. 2015. Modeling readability to improve unit tests. InProceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. 107–118
2015
-
[16]
Amirhossein Deljouyi, Roham Koohestani, Maliheh Izadi, and Andy Zaidman. 2024. Leveraging Large Language Models for Enhancing the Understandability of Generated Unit Tests.arXiv preprint arXiv:2408.11710(2024)
arXiv 2024
-
[17]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al . 2020. Codebert: A pre-trained model for programming and natural languages.arXiv preprint arXiv:2002.08155(2020)
Pith/arXiv arXiv 2020
-
[18]
Gordon Fraser and Andrea Arcuri. 2011. Evosuite: automatic test suite generation for object-oriented software. InProceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering. 416–419
2011
-
[19]
Gordon Fraser and Andrea Arcuri. 2014. A large-scale evaluation of automated unit test generation using evosuite. ACM Transactions on Software Engineering and Methodology (TOSEM)24, 2 (2014), 1–42
2014
-
[20]
Gordon Fraser, Matt Staats, Phil McMinn, Andrea Arcuri, and Frank Padberg. 2015. Does automated unit test generation really help software testers? a controlled empirical study.ACM Transactions on Software Engineering and Methodology (TOSEM)24, 4 (2015), 1–49
2015
-
[21]
Yi Gao, Xing Hu, Xiaohu Yang, and Xin Xia. 2024. Context-Enhanced LLM-Based Framework for Automatic Test Refactoring.arXiv preprint arXiv:2409.16739(2024)
arXiv 2024
-
[22]
Yi Gao, Xing Hu, Xiaohu Yang, and Xin Xia. 2025. Automated Unit Test Refactoring.Proceedings of the ACM on Software Engineering2, FSE (2025), 713–733
2025
-
[23]
Gregory Gay. 2023. Improving the Readability of Generated Tests Using GPT-4 and ChatGPT Code Interpreter. In International Symposium on Search Based Software Engineering. Springer, 140–146
2023
-
[24]
Giovanni Grano, Simone Scalabrino, Harald C Gall, and Rocco Oliveto. 2018. An empirical investigation on the readability of manual and generated test cases. InProceedings of the 26th Conference on Program Comprehension. 348–351
2018
-
[25]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, et al. 2020. Graphcodebert: Pre-training code representations with data flow.arXiv preprint arXiv:2009.08366 (2020)
Pith/arXiv arXiv 2020
-
[26]
Cheng-Yu Hsieh, Yung-Sung Chuang, Chun-Liang Li, Zifeng Wang, Long Le, Abhishek Kumar, James Glass, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, et al. 2024. Found in the middle: Calibrating positional attention bias improves long context utilization. InFindings of the Association for Computational Linguistics: ACL 2024. 14982–14995
2024
-
[27]
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2016. Summarizing source code using a neural attention model. In54th Annual Meeting of the Association for Computational Linguistics 2016. Association for Computational Linguistics, 2073–2083
2016
-
[28]
Gunel Jahangirova and Valerio Terragni. 2023. SBFT tool competition 2023-Java test case generation track. In2023 IEEE/ACM International Workshop on Search-Based and Fuzz Testing (SBFT). IEEE, 61–64
2023
-
[29]
René Just, Darioush Jalali, and Michael D Ernst. 2014. Defects4J: A database of existing faults to enable controlled testing studies for Java programs. InProceedings of the 2014 international symposium on software testing and analysis. J. ACM, Vol. 1, No. 1, Article . Publication date: June 2026. 34 W. Ouédraogo et al. 437–440
2014
-
[30]
Adam Kalai, Ofir Nachum, Santosh Vempala, and Edwin Zhang. 2025. Why Language Models Hallucinate. https: //doi.org/10.48550/arXiv.2509.04664
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.04664 2025
-
[31]
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K Lahiri, and Siddhartha Sen. 2023. Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 919–931
2023
-
[32]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[33]
Chin-Yew Lin and Franz Josef Och. 2004. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. InProceedings of the 42nd annual meeting of the association for computational linguistics (ACL-04). 605–612
2004
-
[34]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics 12 (2024), 157–173
2024
-
[35]
Stephan Lukasczyk and Gordon Fraser. 2022. Pynguin: Automated unit test generation for python. InProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings. 168–172
2022
-
[36]
Antonio Mastropaolo, Matteo Ciniselli, Massimiliano Di Penta, and Gabriele Bavota. 2024. Evaluating Code Summariza- tion Techniques: A New Metric and an Empirical Characterization. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[37]
Thomas J McCabe. 1976. A complexity measure.IEEE Transactions on software Engineering4 (1976), 308–320
1976
-
[38]
Rian Melo, Pedro Simões, Rohit Gheyi, Marcelo d’Amorim, Márcio Ribeiro, Gustavo Soares, Eduardo Almeida, and Elvys Soares. 2025. Agentic LMs: Hunting Down Test Smells.IEEE Software(2025)
2025
-
[39]
Delano Oliveira, Reyde Bruno, Fernanda Madeiral, Hidehiko Masuhara, and Fernando Castor. 2022. A systematic literature review on the impact of formatting elements on program understandability.A vailable at SSRN 4182156 (2022)
2022
-
[40]
Wendkûuni C Ouédraogo, Kader Kaboré, Haoye Tian, Yewei Song, Anil Koyuncu, Jacques Klein, David Lo, and Tegawendé F Bissyandé. 2024. Large-scale, Independent and Comprehensive study of the power of LLMs for test case generation.arXiv preprint arXiv:2407.00225(2024)
arXiv 2024
-
[41]
Wendkuuni C Ouedraogo, Kader Kabore, Haoye Tian, Yewei Song, Anil Koyuncu, Jacques Klein, David Lo, and Tegawende F Bissyande. 2024. Llms and prompting for unit test generation: A large-scale evaluation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 2464–2465
2024
-
[42]
Wendkûuni C Ouédraogo, Yinghua Li, Xueqi Dang, Pawel Borsukiewicz, Xin Zhou, Anil Koyuncu, Jacques Klein, David Lo, and Tegawendé F Bissyandé. 2025. Human-Aligned Code Readability Assessment with Large Language Models.arXiv preprint arXiv:2510.16579(2025)
arXiv 2025
-
[43]
Wendkûuni C Ouédraogo, Yinghua Li, Xueqi Dang, Xunzhu Tang, Anil Koyuncu, Jacques Klein, David Lo, and Tegawendé F Bissyandé. 2024. Test smells in llm-generated unit tests.arXiv preprint arXiv:2410.10628(2024)
arXiv 2024
-
[44]
Wendkûuni C Ouédraogo, Yinghua Li, Xueqi Dang, Xin Zhou, Anil Koyuncu, Jacques Klein, David Lo, and Tegawendé F Bissyandé. 2025. Beyond Surface Similarity: Evaluating LLM-Based Test Refactorings with Structural and Semantic Awareness.arXiv preprint arXiv:2506.06767(2025)
arXiv 2025
-
[45]
Wendkûuni C Ouédraogo, Yinghua Li, Xueqi Dang, Xin Zhou, Anil Koyuncu, Jacques Klein, David Lo, and Tegawendé F Bissyandé. 2025. Rethinking Cognitive Complexity for Unit Tests: Toward a Readability-Aware Metric Grounded in Developer Perception. In2025 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 797–802
2025
-
[46]
Wendkûuni C Ouédraogo, Laura Plein, Kader Kabore, Andrew Habib, Jacques Klein, David Lo, and Tegawendé F Bissyandé. 2025. Enriching automatic test case generation by extracting relevant test inputs from bug reports.Empirical Software Engineering30, 3 (2025), 85
2025
-
[47]
Fabio Palomba, Dario Di Nucci, Annibale Panichella, Rocco Oliveto, and Andrea De Lucia. 2016. On the diffusion of test smells in automatically generated test code: An empirical study. InProceedings of the 9th international workshop on search-based software testing. 5–14
2016
-
[48]
Rangeet Pan, Myeongsoo Kim, Rahul Krishna, Raju Pavuluri, and Saurabh Sinha. 2025. Aster: Natural and multi- language unit test generation with llms. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 413–424
2025
-
[49]
Annibale Panichella, Fitsum Meshesha Kifetew, and Paolo Tonella. 2017. Automated test case generation as a many- objective optimisation problem with dynamic selection of the targets.IEEE Transactions on Software Engineering44, 2 (2017), 122–158
2017
-
[50]
Annibale Panichella, Sebastiano Panichella, Gordon Fraser, Anand Ashok Sawant, and Vincent J Hellendoorn. 2020. Revisiting test smells in automatically generated tests: limitations, pitfalls, and opportunities. In2020 IEEE international J. ACM, Vol. 1, No. 1, Article . Publication date: June 2026. Humanizing Automatically Generated Unit Test Suites with L...
2020
-
[51]
Anthony Peruma, Khalid Almalki, Christian D Newman, Mohamed Wiem Mkaouer, Ali Ouni, and Fabio Palomba
-
[52]
InProceedings of the 28th ACM joint meeting on european software engineering conference and symposium on the foundations of software engineering
Tsdetect: An open source test smells detection tool. InProceedings of the 28th ACM joint meeting on european software engineering conference and symposium on the foundations of software engineering. 1650–1654
-
[53]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis.arXiv preprint arXiv:2009.10297 (2020)
Pith/arXiv arXiv 2020
-
[54]
Devjeet Roy, Ziyi Zhang, Maggie Ma, Venera Arnaoudova, Annibale Panichella, Sebastiano Panichella, Danielle Gonzalez, and Mehdi Mirakhorli. 2020. DeepTC-Enhancer: Improving the readability of automatically generated tests. InProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering. 287–298
2020
-
[55]
Simone Scalabrino, Mario Linares-Vásquez, Rocco Oliveto, and Denys Poshyvanyk. 2018. A comprehensive model for code readability.Journal of Software: Evolution and Process30, 6 (2018), e1958
2018
-
[56]
Agnia Sergeyuk, Olga Lvova, Sergey Titov, Anastasiia Serova, Farid Bagirov, and Timofey Bryksin. 2024. Assessing Consensus of Developers’ Views on Code Readability.arXiv preprint arXiv:2407.03790(2024)
arXiv 2024
-
[57]
Agnia Sergeyuk, Olga Lvova, Sergey Titov, Anastasiia Serova, Farid Bagirov, Evgeniia Kirillova, and Timofey Bryksin
-
[58]
InProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension
Reassessing Java Code Readability Models with a Human-Centered Approach. InProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. 225–235
-
[59]
Sina Shamshiri, René Just, José Miguel Rojas, Gordon Fraser, Phil McMinn, and Andrea Arcuri. 2015. Do automatically generated unit tests find real faults? an empirical study of effectiveness and challenges (t). In2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 201–211
2015
-
[60]
Jiho Shin, Nima Shiri Harzevili, Reem Aleithan, Hadi Hemmati, and Song Wang. 2024. Retrieval-augmented test generation: How far are we?arXiv preprint arXiv:2409.12682(2024)
arXiv 2024
-
[61]
O’Reilly Media, Inc
James Shore and Shane Warden. 2021.The art of agile development. " O’Reilly Media, Inc. "
2021
-
[62]
Mohammed Latif Siddiq, Joanna CS Santos, Ridwanul Hasan Tanvir, Noshin Ulfat, Fahmid Al Rifat, and Vinícius Car- valho Lopes. 2024. Using Large Language Models to Generate JUnit Tests: An Empirical Study. (2024)
2024
-
[63]
O’Reilly Media, Inc
Saleem Siddiqui. 2021.Learning Test-Driven Development. " O’Reilly Media, Inc. "
2021
-
[64]
Weisong Sun, Yun Miao, Yuekang Li, Hongyu Zhang, Chunrong Fang, Yi Liu, Gelei Deng, Yang Liu, and Zhenyu Chen. 2024. Source Code Summarization in the Era of Large Language Models. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 419–431
2024
-
[65]
Yutian Tang, Zhijie Liu, Zhichao Zhou, and Xiapu Luo. 2024. Chatgpt vs sbst: A comparative assessment of unit test suite generation.IEEE Transactions on Software Engineering(2024)
2024
-
[66]
Arie Van Deursen, Leon Moonen, Alex Van Den Bergh, and Gerard Kok. 2001. Refactoring test code. InProceedings of the 2nd international conference on extreme programming and flexible processes in software engineering (XP2001). Citeseer, 92–95
2001
-
[67]
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2024. Software testing with large language models: Survey, landscape, and vision.IEEE Transactions on Software Engineering(2024)
2024
-
[68]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171 (2022)
Pith/arXiv arXiv 2022
-
[69]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al . 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[70]
Zhiqiang Yuan, Yiling Lou, Mingwei Liu, Shiji Ding, Kaixin Wang, Yixuan Chen, and Xin Peng. 2023. No more manual tests? evaluating and improving chatgpt for unit test generation.arXiv preprint arXiv:2305.04207(2023)
arXiv 2023
-
[71]
Zhichao Zhou, Yutian Tang, Yun Lin, and Jingzhu He. 2024. An LLM-based readability measurement for unit tests’ context-aware inputs.arXiv preprint arXiv:2407.21369(2024). A Additional Tables Table 10.Test generation statistics across datasets and tools. Dataset Model #Projects #ClassesTest GenerationRate (%) CompilabilityRate (%)TokensMax TokensMin Tokens...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.