A Causally Grounded Taxonomy for Image Degradation Robustness Evaluation
Pith reviewed 2026-05-20 19:03 UTC · model grok-4.3
The pith
A dual-axis taxonomy groups image degradations by causal source in the imaging pipeline and by perceptual effect, with a measurement layer that quantifies severity comparably across backends.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Each degradation is described along two orthogonal axes: its dominant causal source (environment, sensor/optics, ISP/renderer/codec, or transfer/system) and its resulting perceptual effect. This dual-axis abstraction produces a compact taxonomy that covers algorithmic corruptions, perceptual distortions, and physically motivated imaging artifacts. Severity is made observable and comparable by computing PSNR, SSIM, and LPIPS values for every native severity level supplied by an existing backend, leaving those native parameterizations unchanged.
What carries the argument
Dual orthogonal axes (causal source in the imaging pipeline and perceptual effect) together with a lightweight severity measurement layer that applies full-reference image quality metrics to native parameter settings.
If this is right
- Robustness scores obtained on synthetic corruption benchmarks become directly comparable with scores from perceptual-quality or camera-failure studies.
- The same native degradation implementations can be reused while their effective strengths are reported on a common numerical scale.
- Gaps in coverage of the taxonomy become visible, guiding the addition of new test cases without redefining existing parameter spaces.
- Object-detector evaluations can be conducted under a single aligned set of conditions that mixes algorithmic, perceptual, and physical degradations.
Where Pith is reading between the lines
- The taxonomy could serve as a checklist when designing new robustness datasets, ensuring each quadrant of the two axes receives representative test cases.
- If the severity layer correlates with downstream task error rates, it may allow calibration of benchmark difficulty across entirely different vision tasks.
- Extending the causal axis to video pipelines or multi-sensor systems would require only the addition of new source labels while preserving the existing perceptual axis.
Load-bearing premise
The four causal-source categories are exhaustive, mutually exclusive, and remain orthogonal to the perceptual-effect axis.
What would settle it
A collection of real or synthetic degradations that cannot be assigned to exactly one causal-source category without overlap or omission, or for which the chosen quality metrics produce inconsistent ordering of severity levels across different backends.
Figures







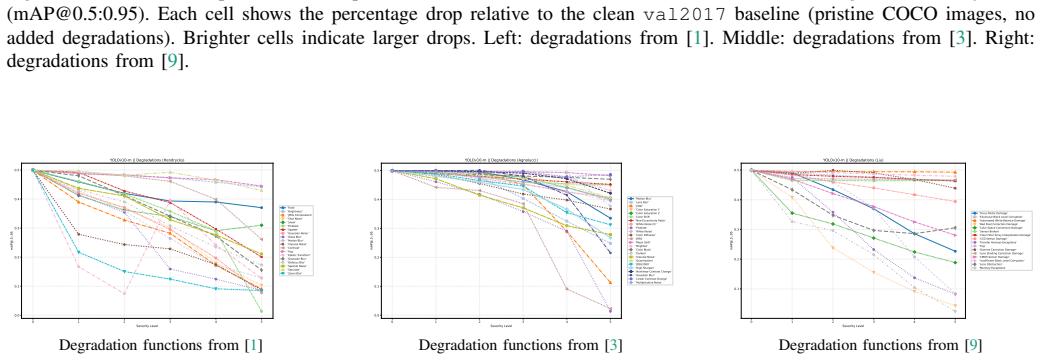
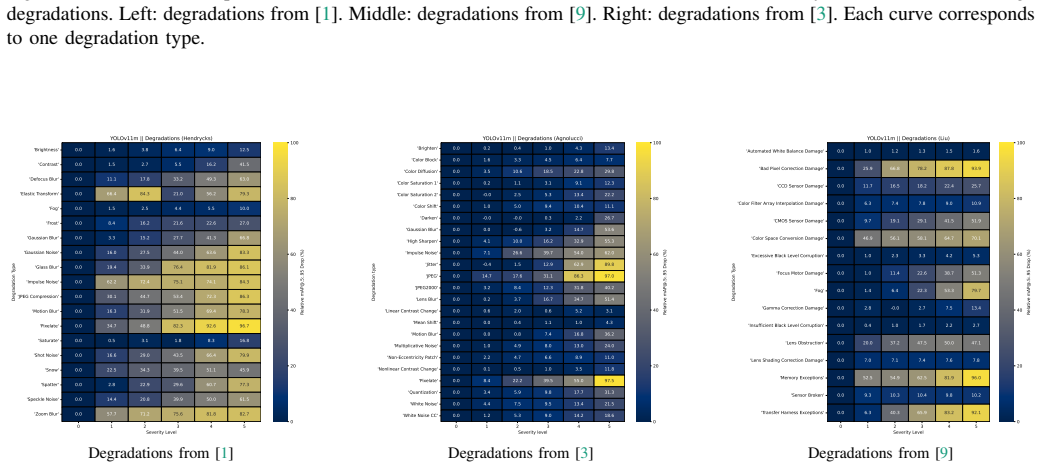








read the original abstract
Image degradations can occur during acquisition, processing, and transmission, altering visual appearance and affecting downstream vision tasks. They are studied in several communities, including synthetic corruption benchmarks for robustness evaluation, perceptual image quality assessment, and physically grounded analyses of imaging systems or real camera failures. Although these areas address closely related phenomena, they often use incompatible grouping schemes and backend specific severity definitions, making results difficult to compare across datasets, degradation sources, and tasks. We propose a causally grounded framework for organizing and interpreting image degradations across these settings. Instead of introducing new degradations or redefining existing benchmarks, we provide an interpretive representation and measurement layer that makes implicit assumptions explicit. Each degradation is described along two orthogonal axes: its dominant causal source in the imaging pipeline (environment, sensor/optics, ISP/renderer/codec, or transfer/system), and its resulting perceptual effect. This dual axis abstraction yields a compact taxonomy spanning algorithmic corruptions, perceptual distortions, and physically motivated imaging artifacts. To address inconsistent severity semantics without changing existing implementations, we introduce a lightweight severity measurement layer. For every degradation and each native severity level of a given backend, we quantify degradation strength using full reference image quality metrics: PSNR, SSIM, and LPIPS. This makes severity observable and comparable across sources while preserving native parameterizations. We demonstrate the framework through COCO Degradation, a taxonomy aligned benchmark for evaluating object detector robustness under diverse imaging conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a causally grounded framework for organizing image degradations across communities studying synthetic corruptions, perceptual quality assessment, and physical imaging artifacts. Degradations are classified along two orthogonal axes: dominant causal source in the imaging pipeline (environment, sensor/optics, ISP/renderer/codec, or transfer/system) and resulting perceptual effect. A lightweight severity layer quantifies strength for each native severity level using PSNR, SSIM, and LPIPS to enable cross-source comparability without altering existing implementations. The framework is demonstrated via the COCO Degradation benchmark for object detector robustness evaluation.
Significance. If the taxonomy is shown to be exhaustive and free of overlaps while the severity metrics yield consistent, interpretable comparisons, the work could help unify robustness evaluations that currently use incompatible groupings and severity definitions. The decision to provide an interpretive layer rather than new degradations or benchmarks is a constructive strength that supports integration with existing datasets and tasks.
major comments (1)
- [Abstract] Abstract and framework description: The central claim that the four causal source categories form an exhaustive, mutually exclusive partition orthogonal to the perceptual-effect axis underpins the taxonomy's compactness and cross-source comparability. Degradations such as motion blur (potentially environment or sensor/optics) and JPEG artifacts (potentially ISP/renderer/codec or transfer/system) have ambiguous or multi-source origins. The manuscript must supply an explicit assignment procedure or boundary-case handling; absent this, the orthogonality premise risks overlaps that weaken the promised interpretive representation and severity observability.
minor comments (1)
- [Abstract] The abstract would benefit from a concise statement of how the COCO Degradation benchmark specifically differs from prior corruption suites in its use of the taxonomy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the framework's potential to unify robustness evaluations. We address the major comment on causal source assignment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and framework description: The central claim that the four causal source categories form an exhaustive, mutually exclusive partition orthogonal to the perceptual-effect axis underpins the taxonomy's compactness and cross-source comparability. Degradations such as motion blur (potentially environment or sensor/optics) and JPEG artifacts (potentially ISP/renderer/codec or transfer/system) have ambiguous or multi-source origins. The manuscript must supply an explicit assignment procedure or boundary-case handling; absent this, the orthogonality premise risks overlaps that weaken the promised interpretive representation and severity observability.
Authors: We agree that an explicit assignment procedure strengthens the taxonomy. The manuscript already relies on the notion of 'dominant causal source' to resolve multi-source cases, but we will add a dedicated subsection in the revised Section 3 with a decision procedure and boundary-case examples. Motion blur will be assigned to environment when driven by scene or object motion and to sensor/optics for camera-induced effects such as shake or defocus. JPEG artifacts will be placed under ISP/renderer/codec because they arise during encoding and compression, while transfer/system covers post-encoding transmission losses. These rules, illustrated with concrete examples, preserve orthogonality to the perceptual-effect axis and make the framework easier to apply consistently. revision: yes
Circularity Check
No circularity: interpretive taxonomy and severity layer are self-contained
full rationale
The paper introduces a dual-axis framework (causal source categories and perceptual effects) plus a severity layer based on standard metrics (PSNR, SSIM, LPIPS) applied to existing backends. No equations, fitted parameters, or derivations are shown that reduce the taxonomy, orthogonality claim, or severity measures back to the paper's own inputs by construction. The four source categories are posited as an organizing premise rather than derived from prior self-citations or self-referential definitions. The work is presented as an independent interpretive layer over existing benchmarks, with no load-bearing self-citation chains or renaming of known results as new derivations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Image degradations have a dominant causal source that can be categorized into one of four stages: environment, sensor/optics, ISP/renderer/codec, or transfer/system.
- domain assumption Full-reference image quality metrics (PSNR, SSIM, LPIPS) can quantify degradation strength for each native severity level while preserving the original backend parameterizations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (J-cost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a lightweight severity measurement layer... quantify degradation strength using full reference image quality metrics: PSNR, SSIM, and LPIPS
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Benchmarking neural network robustness to common corruptions and perturbations,
D. Hendrycks and T. Dietterich, “Benchmarking neural network robustness to common corruptions and perturbations,” inInternational Conference on Learning Representations, 2019. [Online]. Available: https://openreview.net/forum?id=HJz6tiCqYm
work page 2019
-
[2]
Benchmarking robustness in object detection: Autonomous driving when winter is coming,
C. Michaelis, B. Mitzkus, R. Geirhos, E. Rusak, O. Bringmann, A. S. Ecker, M. Bethge, and W. Brendel, “Benchmarking robustness in object detection: Autonomous driving when winter is coming,” inMachine Learning for Autonomous Driving (NeurIPS Workshop), 2019
work page 2019
-
[3]
Arniqa: Learn- ing distortion manifold for image quality assessment,
L. Agnolucci, L. Galteri, M. Bertini, and A. Del Bimbo, “Arniqa: Learn- ing distortion manifold for image quality assessment,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 189–198
work page 2024
-
[4]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean conference on computer vision (ECCV). Springer, 2014, pp. 740–755
work page 2014
-
[5]
Image quality assess- ment: from error visibility to structural similarity,
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality assess- ment: from error visibility to structural similarity,”IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004
work page 2004
-
[6]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in CVPR, 2018
work page 2018
-
[7]
K. Oksuz, T. Joy, and P. K. Dokania, “Towards building self-aware object detectors via reliable uncertainty quantification and calibration,” inConference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[8]
Kadid-10k: A large-scale artificially distorted iqa database,
H. Lin, V . Hosu, and D. Saupe, “Kadid-10k: A large-scale artificially distorted iqa database,” in2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), 2019, pp. 1–3
work page 2019
-
[9]
Benchmarking object detection robustness against real-world corruptions,
J. Liu, Z. Wang, L. Ma, C. Fang, T. Bai, X. Zhang, J. Liu, and Z. Chen, “Benchmarking object detection robustness against real-world corruptions,”International Journal of Computer Vision, vol. 132, no. 10, pp. 4398–4416, Oct 2024. [Online]. Available: https://doi.org/10.1007/s11263-024-02096-6
-
[10]
YOLOv10: Real-time end-to-end object detection,
A. Wang, H. Chen, L. Liu, K. CHEN, Z. Lin, J. Han, and G. Ding, “YOLOv10: Real-time end-to-end object detection,” inThe Thirty- eighth Annual Conference on Neural Information Processing Systems,
-
[11]
Available: https://openreview.net/forum?id=tz83Nyb71l
[Online]. Available: https://openreview.net/forum?id=tz83Nyb71l
-
[12]
Yolov9: Learning what you want to learn using programmable gradient information,
C.-Y . Wang, I.-H. Yeh, and H.-Y . M. Liao, “Yolov9: Learning what you want to learn using programmable gradient information,” inEuropean Conference on Computer Vision (ECCV). Cham: Springer Nature Switzerland, 2024, pp. 1–21
work page 2024
-
[13]
G. Jocher and J. Qiu, “Ultralytics YOLO11,” 2024. [Online]. Available: https://github.com/ultralytics/ultralytics
work page 2024
-
[14]
DETRs Beat YOLOs on Real-time Object Detection,
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, and J. Chen, “DETRs Beat YOLOs on Real-time Object Detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 16 965–16 974
work page 2024
-
[15]
Quality-aware pre- trained models for blind image quality assessment,
K. Zhao, K. Yuan, M. Sun, M. Li, and X. Wen, “Quality-aware pre- trained models for blind image quality assessment,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 22 302–22 313
work page 2023
-
[16]
Wise-od: Benchmarking robustness in infrared object detection,
H. R. Medeiros, A. Belal, M. Aminbeidokhti, E. Granger, and M. Pedersoli, “Wise-od: Benchmarking robustness in infrared object detection,” 2025. [Online]. Available: https://arxiv.org/abs/2507.18925
-
[17]
ImageNet: A Large-Scale Hierarchical Image Database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A Large-Scale Hierarchical Image Database,” inCVPR09, 2009
work page 2009
-
[18]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” Tech. Rep., 2009
work page 2009
-
[19]
The pascal visual object classes (voc) challenge,
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisser- man, “The pascal visual object classes (voc) challenge,”International journal of computer vision, vol. 88, pp. 303–338, 2010
work page 2010
-
[20]
The cityscapes dataset for semantic urban scene understanding,
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benen- son, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” inProc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[21]
Objects365: A large-scale, high-quality dataset for object detection,
S. Shao, Z. Li, T. Zhang, C. Peng, G. Yu, J. Li, X. Zhang, and J. Sun, “Objects365: A large-scale, high-quality dataset for object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 8425–8434
work page 2019
-
[22]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning,
F. Yu, H. Chen, X. Wang, W. Xian, Y . Chen, F. Liu, V . Madhavan, and T. Darrell, “Bdd100k: A diverse driving dataset for heterogeneous multitask learning,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[23]
Benchmarking robustness of 3d object detection to common corruptions in autonomous driving,
Y . Dong, C. Kang, J. Zhang, Z. Zhu, Y . Wang, X. Yang, H. Su, X. Wei, and J. Zhu, “Benchmarking robustness of 3d object detection to common corruptions in autonomous driving,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 1022– 1032
work page 2023
-
[24]
Vision meets robotics: The kitti dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,”International Journal of Robotics Research (IJRR), 2013
work page 2013
-
[25]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Kr- ishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inCVPR, 2020
work page 2020
-
[26]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, V . Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y . Zhang, J. Shlens, Z. Chen, and D. Anguelov, “Scalability in perception for autonomous driving: Waymo open dataset,” inProceedings of the IEEE/CV...
work page 2020
-
[27]
3d common corruptions and data augmentation,
O. F. Kar, T. Yeo, A. Atanov, and A. Zamir, “3d common corruptions and data augmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 963–18 974
work page 2022
-
[28]
Multispectral fusion for object detection with cyclic fuse-and-refine blocks
H. Zhang, E. Fromont, S. Lef `evre, and B. Avignon, “Multispectral fusion for object detection with cyclic fuse-and-refine blocks.” [Online]. Available: https://hal.archives-ouvertes.fr/hal-02872132
-
[29]
Free flir thermal dataset for algorithm training,
FLIR (V2), “Free flir thermal dataset for algorithm training,” 2022,Available at https://www.flir.com/oem/adas/dataset/ european-regional-thermal-dataset/
work page 2022
-
[30]
Llvip: A visible-infrared paired dataset for low-light vision,
X. Jia, C. Zhu, M. Li, W. Tang, and W. Zhou, “Llvip: A visible-infrared paired dataset for low-light vision,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3496–3504
work page 2021
-
[31]
A. Beghdadi, M. Mallem, and L. Beji, “Benchmarking performance of object detection under image distortions in an uncontrolled environ- ment,” in2022 IEEE International Conference on Image Processing (ICIP), 2022, pp. 2071–2075
work page 2022
-
[32]
On interaction between augmentations and corruptions in natural corruption robustness,
E. Mintun, A. Kirillov, and S. Xie, “On interaction between augmentations and corruptions in natural corruption robustness,” in Advances in Neural Information Processing Systems, M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., vol. 34. Curran Associates, Inc., 2021, pp. 3571–3583. [Online]. Available: https://proceedings.neurip...
work page 2021
-
[33]
CCC: Continuously changing corruptions,
O. Press, S. Schneider, M. Kuemmerer, and M. Bethge, “CCC: Continuously changing corruptions,” inICML 2022 Shift Happens Workshop, 2022. [Online]. Available: https://openreview.net/forum?id= iK3ry72nCz8
work page 2022
-
[34]
Coco- o: A benchmark for object detectors under natural distribution shifts,
X. Mao, Y . Chen, Y . Zhu, D. Chen, H. Su, R. Zhang, and H. Xue, “Coco- o: A benchmark for object detectors under natural distribution shifts,” Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[35]
Generalized out-of-distribution detection: A survey,
J. Yang, K. Zhou, Y . Li, and Z. Liu, “Generalized out-of-distribution detection: A survey,”International Journal of Computer Vision, Jun
-
[36]
[Online]. Available: https://doi.org/10.1007/s11263-024-02117-4
-
[37]
The robustness of computer vision models against common corruptions: a survey,
S. Wang, R. Veldhuis, and N. Strisciuglio, “The robustness of computer vision models against common corruptions: a survey,” 2023
work page 2023
-
[38]
Multiscale structural similarity for image quality assessment,
Z. Wang, E. Simoncelli, and A. Bovik, “Multiscale structural similarity for image quality assessment,” inThe Thrity-Seventh Asilomar Con- ference on Signals, Systems and Computers, 2003, vol. 2, 2003, pp. 1398–1402 V ol.2
work page 2003
-
[39]
Fsim: A feature similarity index for image quality assessment,
L. Zhang, L. Zhang, X. Mou, and D. Zhang, “Fsim: A feature similarity index for image quality assessment,”IEEE Transactions on Image Processing, vol. 20, no. 8, pp. 2378–2386, 2011
work page 2011
-
[40]
No-reference image quality assessment in the spatial domain,
A. Mittal, A. K. Moorthy, and A. C. Bovik, “No-reference image quality assessment in the spatial domain,”IEEE Transactions on Image Processing, vol. 21, pp. 4695–4708, 2012. [Online]. Available: https://api.semanticscholar.org/CorpusID:2927709
work page 2012
-
[41]
A. Mittal, R. Soundararajan, and A. C. Bovik, “Making a “completely blind” image quality analyzer,”IEEE Signal Processing Letters, vol. 20, no. 3, pp. 209–212, 2013
work page 2013
-
[42]
Blind image quality evaluation using perception based features,
V . N, P. D, M. C. Bh, S. S. Channappayya, and S. S. Medasani, “Blind image quality evaluation using perception based features,” in 2015 Twenty First National Conference on Communications (NCC), 2015, pp. 1–6
work page 2015
-
[43]
Blind image quality assessment: From natural scene statistics to perceptual quality,
A. K. Moorthy and A. C. Bovik, “Blind image quality assessment: From natural scene statistics to perceptual quality,”IEEE Transactions on Image Processing, vol. 20, no. 12, pp. 3350–3364, 2011
work page 2011
-
[44]
Musiq: Multi-scale image quality transformer,
J. Ke, Q. Wang, Y . Wang, P. Milanfar, and F. Yang, “Musiq: Multi-scale image quality transformer,” in2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 5128–5137
work page 2021
-
[45]
Image quality assess- ment: Unifying structure and texture similarity,
K. Ding, K. Ma, S. Wang, and E. P. Simoncelli, “Image quality assess- ment: Unifying structure and texture similarity,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 5, pp. 2567– 2581, 2022
work page 2022
-
[46]
A survey on image quality assessment: Insights, analysis, and future outlook,
C. Ma, Z. Shi, Z. Lu, S. Xie, F. Chao, and Y . Sui, “A survey on image quality assessment: Insights, analysis, and future outlook,” 2025. [Online]. Available: https://arxiv.org/abs/2502.08540
-
[47]
Blind image quality assessment: A brief survey,
M. Wang, “Blind image quality assessment: A brief survey,” 2023
work page 2023
-
[48]
Image database tid2013: Peculiarities, results and perspectives,
N. Ponomarenko, L. Jin, O. Ieremeiev, V . Lukin, K. Egiazarian, J. Astola, B. V ozel, K. Chehdi, M. Carli, F. Battisti, and C.-C. Jay Kuo, “Image database tid2013: Peculiarities, results and perspectives,” Signal Processing: Image Communication, vol. 30, pp. 57–77, 2015. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0923596514001490
work page 2015
-
[49]
Uhd- iqa benchmark database: Pushing the boundaries of blind photo quality assessment,
V . Hosu, L. Agnolucci, O. Wiedemann, D. Iso, and D. Saupe, “Uhd- iqa benchmark database: Pushing the boundaries of blind photo quality assessment,” inComputer Vision – ECCV 2024 Workshops, A. Del Bue, C. Canton, J. Pont-Tuset, and T. Tommasi, Eds. Cham: Springer Nature Switzerland, 2025, pp. 467–482
work page 2024
-
[50]
Going the extra mile in face image quality assessment: A novel database and model,
S. Su, H. Lin, V . Hosu, O. Wiedemann, J. Sun, Y . Zhu, H. Liu, Y . Zhang, and D. Saupe, “Going the extra mile in face image quality assessment: A novel database and model,”IEEE Transactions on Multimedia, 2023
work page 2023
-
[51]
P. Bijl and J. M. Valeton, “Triangle orientation discrimination: the alternative to minimum resolvable temperature difference and minimum resolvable contrast,”Optical Engineering, vol. 37, no. 7, pp. 1976 – 1983, 1998. [Online]. Available: https://doi.org/10.1117/1.601904
-
[52]
J. M. Lloyd,Thermal Imaging Systems. Plenum Press, 1975
work page 1975
-
[53]
Impact of motion blur on recognition rates of CNN-based TOD classifier models,
D. Wegner and S. Keßler, “Impact of motion blur on recognition rates of CNN-based TOD classifier models,” inElectro-Optical and Infrared Systems: Technology and Applications XX, D. L. Hickman, H. B ¨ursing, G. W. Kamerman, and O. Steinvall, Eds., vol. 12737, International Society for Optics and Photonics. SPIE, 2023, p. 127370L. [Online]. Available: https...
-
[54]
D. Wegner, M. Wiehn, and S. Keßler, “Thermal imager performance evaluation with recorded infrared images: Triangle Orientation Discrimination (TOD) classifier versus You Only Look Once (YOLO),” inElectro-Optical and Infrared Systems: Technology and Applications XXII, D. L. Hickman, H. B ¨ursing, O. Steinvall, and P. J. Soan, Eds., vol. 13674, Internationa...
-
[55]
Semantic foggy scene understanding with synthetic data,
C. Sakaridis, D. Dai, and L. Van Gool, “Semantic foggy scene understanding with synthetic data,”International Journal of Computer Vision, vol. 126, no. 9, pp. 973–992, Sep 2018. [Online]. Available: https://doi.org/10.1007/s11263-018-1072-8
-
[56]
Hazydet: Open-source benchmark for drone-view object detec- tion with depth-cues in hazy scenes,
C. Feng, Z. Chen, X. Li, C. Wang, J. Yang, M.-M. Cheng, Y . Dai, and Q. Fu, “Hazydet: Open-source benchmark for drone-view object detec- tion with depth-cues in hazy scenes,”arXiv preprint arXiv:2409.19833, 2025. APPENDIX SUPPLEMENTARYMATERIAL This supplementary material collects content that was omitted from the main paper for space reasons while remaini...
-
[57]
(ImageNet-C/P)hendrycks/robustnessApache-2.0 License reported by repository meta- data
-
[58]
(Augmentation–Corruption)augmentation-corruptionMIT Repository states MIT license
-
[59]
(COCO-C variant)robust-detection-benchmarkMIT Repository states MIT license
-
[60]
(COCO-C variant)asharakeh/probdetApache-2.0 Repository states Apache-2.0 license
-
[61]
(Real-camera corruptions)real-world-benchmarkingn/adataset license CC BY 4.0; reposi- tory/license info not clearly stated on site
-
[62]
(3D Corruptions AD)3D Corruptions ADMIT Repository states MIT license
-
[63]
(3DCommonCorruptions)3DCommonCorruptionsAttribution- NonCommercial 4.0 International Repository states Attribution- NonCommercial 4.0 International license
-
[64]
(WiSE-OD)heitorrapela/wiseodn/ano license information
-
[65]
(EasyRobust / COCO-O)easyrobustApache-2.0 Repository states Apache-2.0 license. SUPPLEMENTARYMATERIAL: EXAMPLEUSAGE(I M G D E GLIBRARY): CALIBRATION ANDCANONICALDEGRADATION Theimdeglibrary separatesseverity calibrationfromdegradation application. Calibration maps backend-native severity levels to measured distortion strength, while degradation application...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.