Random Neural Network Expressivity for Non-Linear Partial Differential Equations
Pith reviewed 2026-06-29 23:44 UTC · model grok-4.3
The pith
Random neural networks achieve dimension-free error bounds of rate 1/2 when approximating solutions to nonlinear PDEs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Error bounds are derived for RaNN approximations to time-dependent Sobolev functions, yielding a dimension-free approximation rate of 1/2 for sufficiently regular functions. The same bounds are applied to two classes of nonlinear PDEs, showing that RaNNs can efficiently approximate solutions to porous medium equations and compressible Navier-Stokes equations.
What carries the argument
Error bounds on RaNN approximations to time-dependent Sobolev functions that deliver a dimension-free rate of 1/2.
If this is right
- RaNNs are capable of efficiently approximating solutions to porous medium equations.
- RaNNs are capable of efficiently approximating solutions to compressible Navier-Stokes equations.
- The convergence rates obtained extend beyond the exact setting analyzed in the theorems.
Where Pith is reading between the lines
- The same style of bound could be tested on other nonlinear evolution equations whose solutions remain sufficiently regular.
- RaNNs might be combined with standard time-stepping schemes to produce practical high-dimensional PDE solvers.
- The dimension-free character suggests that the method remains competitive even when the spatial dimension grows.
Load-bearing premise
The target solutions belong to time-dependent Sobolev spaces with enough regularity for the dimension-free rate of 1/2 to apply.
What would settle it
A concrete calculation or numerical test in which the approximation error for a regular time-dependent Sobolev function decays slower than rate 1/2, or in which RaNNs fail to reach the predicted accuracy on the porous medium or Navier-Stokes solutions.
Figures

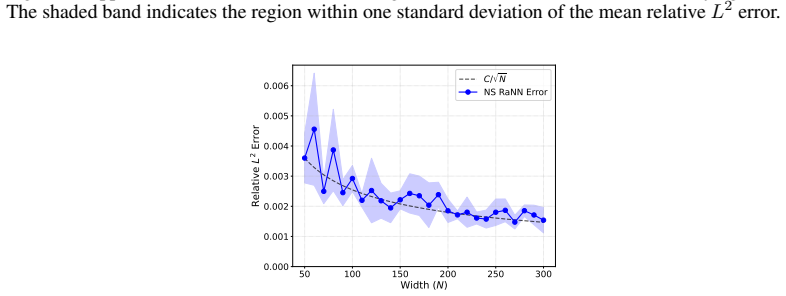
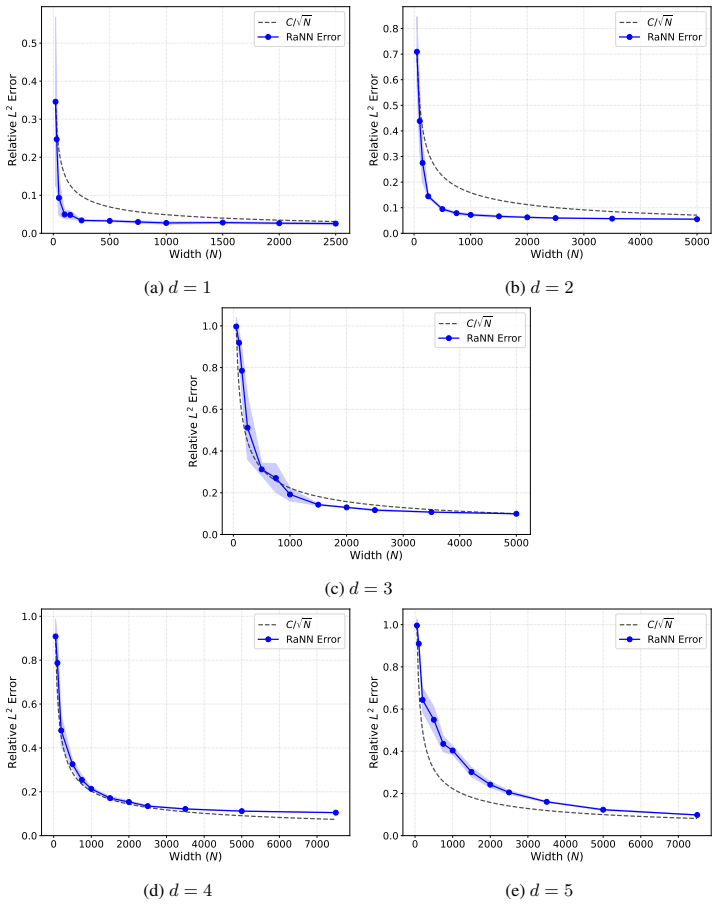




read the original abstract
Neural networks with randomly generated hidden weights (RaNNs) have been extensively studied, both as a standalone learning method and as an initialization for fully trainable deep learning methods. In this work, we study RaNN expressivity for learning solutions to non-linear partial differential equations (PDEs). Despite their widespread use in practical applications, a rigorous theoretical understanding of the approximation properties of RaNNs in this context remains limited. Here, we derive error bounds for RaNN approximations to time-dependent Sobolev functions and obtain a dimension-free approximation rate $\frac{1}{2}$ for sufficiently regular functions. We apply our results to two important classes of non-linear PDEs: Porous Medium Equations and Compressible Navier-Stokes Equations, showing that RaNNs are capable of efficiently approximating solutions to these complex, non-linear PDEs. Our theoretical analysis is supported by numerical experiments, showing that the obtained convergence rates extend beyond the considered setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives error bounds for random neural network (RaNN) approximations to time-dependent Sobolev functions, obtaining a dimension-free approximation rate of 1/2 under sufficient regularity. It applies these bounds to the Porous Medium Equation and the Compressible Navier-Stokes Equations to conclude that RaNNs efficiently approximate solutions to these nonlinear PDEs, with the theoretical results supported by numerical experiments demonstrating the convergence rates.
Significance. If the error bounds are rigorously derived without hidden parameter dependencies and the numerical experiments confirm the rates, the work provides a concrete theoretical foundation for RaNN expressivity in nonlinear PDE settings. The dimension-free rate of 1/2 for regular time-dependent Sobolev functions, if achieved, would be a notable contribution to neural approximation theory for evolution equations.
major comments (1)
- [Abstract and CNS application section] Abstract and applications to Compressible Navier-Stokes: the claim that RaNNs are capable of efficiently approximating solutions to the Compressible Navier-Stokes Equations rests on the target solutions possessing the time-dependent Sobolev regularity needed for the dimension-free 1/2 rate. Global-in-time existence of solutions with this regularity in three space dimensions is an open question, so the derived bounds cannot be unconditionally invoked for general solutions of the PDE class.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable comments on our manuscript. We address the major comment below and agree that revisions are needed to clarify the conditional nature of the CNS application.
read point-by-point responses
-
Referee: [Abstract and CNS application section] Abstract and applications to Compressible Navier-Stokes: the claim that RaNNs are capable of efficiently approximating solutions to the Compressible Navier-Stokes Equations rests on the target solutions possessing the time-dependent Sobolev regularity needed for the dimension-free 1/2 rate. Global-in-time existence of solutions with this regularity in three space dimensions is an open question, so the derived bounds cannot be unconditionally invoked for general solutions of the PDE class.
Authors: We agree with the referee that the approximation results for the Compressible Navier-Stokes Equations are conditional upon the solutions possessing the requisite time-dependent Sobolev regularity. While global existence of such regular solutions remains an open problem in 3D, our theoretical bounds apply to any solution that satisfies these regularity assumptions, and local-in-time existence of smooth solutions is known. We will revise the abstract and the CNS application section to explicitly state that RaNNs efficiently approximate solutions to the CNS that possess the time-dependent Sobolev regularity required for the dimension-free rate of 1/2. This clarification ensures the claims are accurate and conditional where appropriate. For the Porous Medium Equation, the required regularity is established for global weak solutions under standard assumptions. revision: yes
Circularity Check
No circularity: derivation of approximation bounds is self-contained
full rationale
The paper derives error bounds for RaNN approximations of time-dependent Sobolev functions, obtaining a dimension-free rate of 1/2 under sufficient regularity, then applies the bounds conditionally to solutions of Porous Medium Equations and Compressible Navier-Stokes. No quoted step reduces a prediction or result to a fitted input by construction, renames a known result, or relies on a load-bearing self-citation chain. The central claims rest on explicit assumptions about function regularity rather than tautological definitions or imported uniqueness theorems. The applicability concern for 3D Navier-Stokes regularity is a correctness issue outside the circularity analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alejo, Lucrezia Cossetti, Luca Fanelli, Claudio Muñoz, and Nicolás Valenzuela
Miguel A. Alejo, Lucrezia Cossetti, Luca Fanelli, Claudio Muñoz, and Nicolás Valenzuela. Error bounds for Physics Informed Neural Networks in Nonlinear Schrödinger equations placed on unbounded domains.arXiv:2409.17938, page 31 pages, 2024
-
[2]
Breaking the curse of dimensionality with convex neural networks.Journal of Machine Learning Research, 18(19):1–53, 2017
Francis Bach. Breaking the curse of dimensionality with convex neural networks.Journal of Machine Learning Research, 18(19):1–53, 2017
2017
-
[3]
Universal approximation bounds for superpositions of a sigmoidal function
Andrew R Barron. Universal approximation bounds for superpositions of a sigmoidal function. IEEE Transactions on Information theory, 39(3):930–945, 1993
1993
-
[4]
Andrew R. Barron. Approximation and estimation bounds for artificial neural networks.Ma- chine Learning, 14:115–133, 1994
1994
-
[5]
Approximation and Estimation for High-Dimensional Deep Learning Networks
Andrew R. Barron and Jason M. Klusowski. Approximation and estimation for high-dimensional deep learning networks.Preprint, arXiv 1809.03090, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Christian Beck, Martin Hutzenthaler, Arnulf Jentzen, and Benno Kuckuck. An overview on deep learning-based approximation methods for partial differential equations.arXiv preprint arXiv:2012.12348, 2020
-
[7]
Sampling weights of deep neural networks
Erik L Bolager, Iryna Burak, Chinmay Datar, Qing Sun, and Felix Dietrich. Sampling weights of deep neural networks. InAdvances in Neural Information Processing Systems, volume 36, pages 63075–63116. Curran Associates, Inc., 2023
2023
-
[8]
Convergence rates for shallow neural networks learned by gradient descent.Bernoulli, 30(1):475–502, 2024
Alina Braun, Michael Kohler, Sophie Langer, and Harro Walk. Convergence rates for shallow neural networks learned by gradient descent.Bernoulli, 30(1):475–502, 2024
2024
-
[9]
Physics-informed neural networks (PINNs) for fluid mechanics: a review.Acta Mech
Shengze Cai, Zhiping Mao, Zhicheng Wang, Minglang Yin, and George Em Karniadakis. Physics-informed neural networks (PINNs) for fluid mechanics: a review.Acta Mech. Sin., 37(12):1727–1738, 2021
2021
-
[10]
Harmonic analysis of neural networks.Applied and Computational Harmonic Analysis, 6(2):197–218, 1999
Emmanuel J Candès. Harmonic analysis of neural networks.Applied and Computational Harmonic Analysis, 6(2):197–218, 1999
1999
-
[11]
Ridgelets: A key to higher-dimensional intermit- tency?Philosophical Transactions of the Royal Society of London
Emmanuel J Candès and David L Donoho. Ridgelets: A key to higher-dimensional intermit- tency?Philosophical Transactions of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences, 357(1760):2495–2509, 1999
1999
-
[12]
PhD thesis
Emmanuel Jean Candes.Ridgelets: theory and applications. PhD thesis. Stanford University, 1998
1998
-
[13]
Learning with sgd and random features
Luigi Carratino, Alessandro Rudi, and Lorenzo Rosasco. Learning with sgd and random features. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[14]
Jingrun Chen, Xurong Chi, Weinan E, and Zhouwang Yang. Bridging traditional and machine learning-based algorithms for solving pdes: The random feature method.arXiv preprint arXiv:2207.13380, 2022
-
[15]
A theoretical analysis of the test error of finite-rank kernel ridge regression
Tin Sum Cheng, Aurelien Lucchi, Anastasis Kratsios, Ivan Dokmani´c, and David Belius. A theoretical analysis of the test error of finite-rank kernel ridge regression. InAdvances in Neural Information Processing Systems, volume 36, pages 4767–4798. Curran Associates, Inc., 2023
2023
-
[16]
Compressible fluids and active potentials
Peter Constantin, Theodore D Drivas, Huy Q Nguyen, and Federico Pasqualotto. Compressible fluids and active potentials. InAnnales de l’Institut Henri Poincaré C, Analyse non linéaire, volume 37, pages 145–180. Elsevier, 2020
2020
-
[17]
Scientific machine learning through physics-informed neural networks: where we are and what’s next.J
Salvatore Cuomo, Vincenzo Schiano Di Cola, Fabio Giampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli. Scientific machine learning through physics-informed neural networks: where we are and what’s next.J. Sci. Comput., 92(3):Paper No. 88, 62, 2022
2022
-
[18]
Existence and stability of partially congested propagation fronts in a one-dimensional navier-stokes model.Communications in Mathematical Sciences, 2020
Anne-Laure Dalibard and Charlotte Perrin. Existence and stability of partially congested propagation fronts in a one-dimensional navier-stokes model.Communications in Mathematical Sciences, 2020. 10
2020
-
[19]
Local and global well-posedness of one-dimensional free-congested equations.Annales Henri Lebesgue, 2024
Anne-Laure Dalibard and Charlotte Perrin. Local and global well-posedness of one-dimensional free-congested equations.Annales Henri Lebesgue, 2024
2024
-
[20]
Fast training of accurate physics- informed neural networks without gradient descent.ICLR Oral, 2026
Chinmay Datar, Taniya Kapoor, Abhishek Chandra, Qing Sun, Erik Lien Bolager, Iryna Burak, Anna Veselovska, Massimo Fornasier, and Felix Dietrich. Fast training of accurate physics- informed neural networks without gradient descent.ICLR Oral, 2026
2026
-
[21]
T De Ryck, S Mishra, Y Shang, and F Wang. Approximation theory and applications of ran- domized neural networks for solving high-dimensional pdes.arXiv preprint arXiv:2501.12145, 2025
-
[22]
Numerical analysis of physics-informed neural networks and related models in physics-informed machine learning.Acta Numer., 33:633–713, 2024
Tim De Ryck and Siddhartha Mishra. Numerical analysis of physics-informed neural networks and related models in physics-informed machine learning.Acta Numer., 33:633–713, 2024
2024
-
[23]
Schmidt, and Geoffrey I
Angus Dempster, Daniel F. Schmidt, and Geoffrey I. Webb. Hydra: competing convolutional kernels for fast and accurate time series classification.Data Mining and Knowledge Discovery, 37(5):1779–1805, Sep 2023
2023
-
[24]
Ridge functions and orthonormal ridgelets.Journal of Approximation Theory, 111(2):143–179, 2001
David L Donoho. Ridge functions and orthonormal ridgelets.Journal of Approximation Theory, 111(2):143–179, 2001
2001
-
[25]
Physics informed extreme learning machine (pielm)–a rapid method for the numerical solution of partial differential equations.Neurocomputing, 391:96–118, 2020
Vikas Dwivedi and Balaji Srinivasan. Physics informed extreme learning machine (pielm)–a rapid method for the numerical solution of partial differential equations.Neurocomputing, 391:96–118, 2020
2020
-
[26]
W. E and B. Yu. The Deep Ritz method: A deep learning-based numerical algorithm for solving variational problems.arXiv:1710.00211, page 14 pages, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations.Commun
Weinan E, Jiequn Han, and Arnulf Jentzen. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations.Commun. Math. Stat., 5(4):349–380, 2017
2017
-
[28]
Randnet-parareal: a time-parallel pde solver using random neural networks.Advances in Neural Information Processing Systems, 37:94993–95025, 2024
Guglielmo Gattiglio, Lyudmila Grigoryeva, and Massimiliano Tamborrino. Randnet-parareal: a time-parallel pde solver using random neural networks.Advances in Neural Information Processing Systems, 37:94993–95025, 2024
2024
-
[29]
Maximilien Germain, Huyên Pham, and Xavier Warin. Neural networks-based algorithms for stochastic control and PDEs in finance.arXiv:2101.08068, page 27 pages, 2021
-
[30]
Random feature neural networks learn black-scholes type pdes without curse of dimensionality.Journal of Machine Learning Research, 24(189):1–51, 2023
Lukas Gonon. Random feature neural networks learn black-scholes type pdes without curse of dimensionality.Journal of Machine Learning Research, 24(189):1–51, 2023
2023
-
[31]
Approximation bounds for random neural networks and reservoir systems.The Annals of Applied Probability, 33(1):28–69, 2023
Lukas Gonon, Lyudmila Grigoryeva, and Juan-Pablo Ortega. Approximation bounds for random neural networks and reservoir systems.The Annals of Applied Probability, 33(1):28–69, 2023
2023
-
[32]
Lukas Gonon, Arnulf Jentzen, Benno Kuckuck, Siyu Liang, Adrian Riekert, and Philippe von Wurstemberger. An overview on machine learning methods for partial differential equations: from physics informed neural networks to deep operator learning.arXiv:2408.13222, page 59 pages, 2024
-
[33]
Tackling the curse of dimensionality with physics-informed neural networks.Neural Networks, 176:106369, 2024
Zheyuan Hu, Khemraj Shukla, George Em Karniadakis, and Kenji Kawaguchi. Tackling the curse of dimensionality with physics-informed neural networks.Neural Networks, 176:106369, 2024
2024
-
[34]
Extreme learning machine: theory and applications.Neurocomputing, 70(1-3):489–501, 2006
Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew. Extreme learning machine: theory and applications.Neurocomputing, 70(1-3):489–501, 2006
2006
-
[35]
Stability of isentropic navier–stokes shocks in the high-mach number limit.Communications in Mathematical Physics, 293(1):1–36, 2010
Jeffrey Humpherys, Olivier Lafitte, and Kevin Zumbrun. Stability of isentropic navier–stokes shocks in the high-mach number limit.Communications in Mathematical Physics, 293(1):1–36, 2010
2010
-
[36]
Representation of functions by superpositions of a step or sigmoid function and their applications to neural network theory.Neural Networks, 4(3):385–394, 1991
Yoshifusa Ito. Representation of functions by superpositions of a step or sigmoid function and their applications to neural network theory.Neural Networks, 4(3):385–394, 1991. 11
1991
-
[37]
Random neural networks for rough volatility.arXiv preprint arXiv:2305.01035, 2023
Antoine Jacquier and Zan Zuric. Random neural networks for rough volatility.arXiv preprint arXiv:2305.01035, 2023
-
[38]
Samuel Lanthaler and Nicholas H. Nelsen. Error bounds for learning with vector-valued random features. InAdvances in Neural Information Processing Systems, volume 36, pages 71834–71861. Curran Associates, Inc., 2023
2023
-
[39]
Jiale Linghu, Weifeng Gao, Hao Dong, Fei Wang, and Yufeng Nie. Higher-order multi-scale physics-informed randomized neural network method for efficient and high-accuracy simulation of dynamic thermo-mechanical coupling problems.Mathematics and Mechanics of Solids, 0(0):10812865251362165, 2025
2025
-
[40]
Stability of large-amplitude viscous shock profiles of hyperbolic-parabolic systems.Archive for rational mechanics and analysis, 172(1):93–131, 2004
Corrado Mascia and Kevin Zumbrun. Stability of large-amplitude viscous shock profiles of hyperbolic-parabolic systems.Archive for rational mechanics and analysis, 172(1):93–131, 2004
2004
-
[41]
Song Mei and Andrea Montanari. The generalization error of random features regression: Precise asymptotics and double descent curve.Preprint, arXiv 1908.05355, 2019
-
[42]
Estimates on the generalization error of physics- informed neural networks for approximating a class of inverse problems for PDEs.IMA J
Siddhartha Mishra and Roberto Molinaro. Estimates on the generalization error of physics- informed neural networks for approximating a class of inverse problems for PDEs.IMA J. Numer. Anal., 42(2):981–1022, 2022
2022
-
[43]
Estimates on the generalization error of physics- informed neural networks for approximating PDEs.IMA J
Siddhartha Mishra and Roberto Molinaro. Estimates on the generalization error of physics- informed neural networks for approximating PDEs.IMA J. Numer. Anal., 43(1):1–43, 2023
2023
-
[44]
An integral representation of functions using three-layered networks and their approximation bounds.Neural Networks, 9(6):947–956, 1996
Noboru Murata. An integral representation of functions using three-layered networks and their approximation bounds.Neural Networks, 9(6):947–956, 1996
1996
-
[45]
Nelsen and Andrew M
Nicholas H. Nelsen and Andrew M. Stuart. The random feature model for input-output maps between banach spaces.SIAM Journal on Scientific Computing, 43(5):A3212–A3243, 2021
2021
-
[46]
Ariel Neufeld and Philipp Schmocker. Universal approximation property of banach space-valued random feature models including random neural networks.arXiv preprint arXiv:2312.08410, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Full error analysis of the random deep splitting method for nonlinear parabolic pdes and pides.Communications in Nonlinear Science and Numerical Simulation, 143:108556, 2025
Ariel Neufeld, Philipp Schmocker, and Sizhou Wu. Full error analysis of the random deep splitting method for nonlinear parabolic pdes and pides.Communications in Nonlinear Science and Numerical Simulation, 143:108556, 2025
2025
-
[48]
Greg Ongie, Rebecca Willett, Daniel Soudry, and Nathan Srebro. A function space view of bounded norm infinite width relu nets: The multivariate case.arXiv preprint arXiv:1910.01635, 2019
-
[49]
Ameya Prabhu, Shiven Sinha, Ponnurangam Kumaraguru, Philip Torr, Ozan Sener, and Puneet K. Dokania. Random representations outperform online continually learned representations. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[50]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
2019
-
[51]
Random features for large-scale kernel machines.Advances in neural information processing systems, 20, 2007
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines.Advances in neural information processing systems, 20, 2007
2007
-
[52]
Uniform approximation of functions with random bases
Ali Rahimi and Benjamin Recht. Uniform approximation of functions with random bases. In2008 46th annual allerton conference on communication, control, and computing, pages 555–561. IEEE, 2008
2008
-
[53]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
2019
-
[54]
Generalization properties of learning with random features
Alessandro Rudi and Lorenzo Rosasco. Generalization properties of learning with random features. InAdvances in Neural Information Processing Systems, pages 3215–3225, 2017. 12
2017
-
[55]
Randomized neural networks with petrov–galerkin methods for solving linear elasticity and navier–stokes equations.Journal of Engineering Mechanics, 150(4):04024010, 2024
Yong Shang and Fei Wang. Randomized neural networks with petrov–galerkin methods for solving linear elasticity and navier–stokes equations.Journal of Engineering Mechanics, 150(4):04024010, 2024
2024
-
[56]
Yong Shang, Fei Wang, and Jingbo Sun. Randomized neural network with petrov–galerkin methods for solving linear and nonlinear partial differential equations.Communications in Nonlinear Science and Numerical Simulation, 127:107518, 2023
2023
-
[57]
Siegel and Jinchao Xu
Jonathan W. Siegel and Jinchao Xu. Approximation rates for neural networks with general activation functions.Neural Networks, 128:313–321, 2020
2020
-
[58]
DGM: A deep learning algorithm for solving partial differential equations
J. Sirignano and K. Spiliopoulos. DGM: A deep learning algorithm for solving partial differential equations.arXiv:1708.07469, page 31 pages, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[59]
Neural network with unbounded activation functions is universal approximator.Applied and Computational Harmonic Analysis, 43(2):233–268, 2017
Sho Sonoda and Noboru Murata. Neural network with unbounded activation functions is universal approximator.Applied and Computational Harmonic Analysis, 43(2):233–268, 2017
2017
-
[60]
Number 30 in 1
Elias M Stein.Singular integrals and differentiability properties of functions. Number 30 in 1. Princeton university press, 1970
1970
-
[61]
Local randomized neural networks with discontinu- ous galerkin methods for partial differential equations.Journal of Computational and Applied Mathematics, 445:115830, 2024
Jingbo Sun, Suchuan Dong, and Fei Wang. Local randomized neural networks with discontinu- ous galerkin methods for partial differential equations.Journal of Computational and Applied Mathematics, 445:115830, 2024
2024
-
[62]
On the approximation properties of random relu features.arXiv preprint arXiv:1810.04374, 2018
Yitong Sun, Anna Gilbert, and Ambuj Tewari. On the approximation properties of random relu features.arXiv preprint arXiv:1810.04374, 2018
-
[63]
Fourier features let networks learn high frequency functions in low dimensional domains.Advances in neural information processing systems, 33:7537–7547, 2020
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains.Advances in neural information processing systems, 33:7537–7547, 2020
2020
-
[64]
Ridges, neural networks, and the radon transform.Journal of Machine Learning Research, 24(37):1–33, 2023
Michael Unser. Ridges, neural networks, and the radon transform.Journal of Machine Learning Research, 24(37):1–33, 2023
2023
-
[65]
Nonlinear stability of viscous shock wave to one-dimensional compressible isentropic Navier–Stokes equations with density dependent viscous coefficient
Alexis F Vasseur and Lei Yao. Nonlinear stability of viscous shock wave to one-dimensional compressible isentropic Navier–Stokes equations with density dependent viscous coefficient. Communications in Mathematical Sciences, 14(8):2215–2228, 2016
2016
-
[66]
Oxford university press, 2007
Juan Luis Vázquez.The porous medium equation: mathematical theory. Oxford university press, 2007
2007
-
[67]
Sifan Wang, Shyam Sankaran, and Paris Perdikaris. Respecting causality is all you need for training physics-informed neural networks.arXiv preprint arXiv:2203.07404, 2022
-
[68]
An expert’s guide to training physics-informed neural networks.arXiv preprint arXiv:2308.08468, 2023
Sifan Wang, Shyam Sankaran, Hanwen Wang, and Paris Perdikaris. An expert’s guide to training physics-informed neural networks.arXiv preprint arXiv:2308.08468, 2023
-
[69]
An extreme learning machine-based method for computa- tional pdes in higher dimensions.Computer Methods in Applied Mechanics and Engineering, 418:116578, 2024
Yiran Wang and Suchuan Dong. An extreme learning machine-based method for computa- tional pdes in higher dimensions.Computer Methods in Applied Mechanics and Engineering, 418:116578, 2024
2024
-
[70]
Zhi-Qin John Xu, Yaoyu Zhang, Tao Luo, Yanyang Xiao, and Zheng Ma. Frequency principle: Fourier analysis sheds light on deep neural networks.arXiv preprint arXiv:1901.06523, 2019
-
[71]
Jinyong Ying, Jingying Hu, Zuoshunhua Shi, and Jiao Li. An accurate and efficient continuity- preserved method based on randomized neural networks for elliptic interface problems.SIAM Journal on Scientific Computing, 46(5):C633–C657, 2024
2024
-
[72]
Random feature representation boosting
Nikita Zozoulenko, Thomas Cass, and Lukas Gonon. Random feature representation boosting. InForty-second International Conference on Machine Learning, 2025. 13 A Proofs A.1 Proof of Proposition 3.2 Proof. Fix m≥0 and an arbitrary ψ∈ S(R) . Using the definition of the ridgelet transform from [59], we have for anys≥0, Rψu(τ,a, b) := Z Rd+1 u(t,x)ψ(τ t+a·x−b)...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.