AtomicMotion: Learning Human Motion From Different Human Parts
Pith reviewed 2026-05-22 06:26 UTC · model grok-4.3
The pith
AtomicMotion reconstructs full-body poses from sparse head and hand data by splitting the skeleton into five functional clusters and embedding kinematic structure into attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
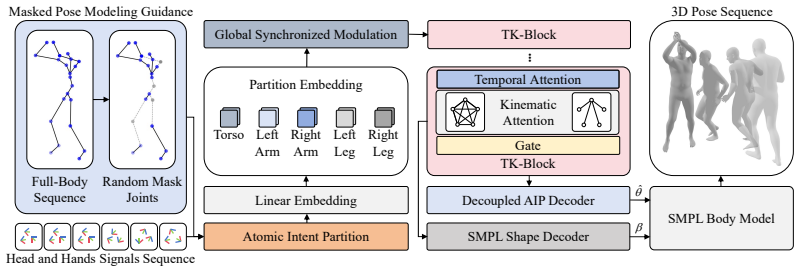
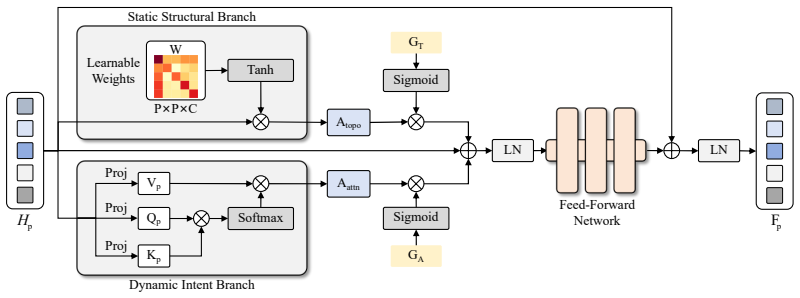
AtomicMotion decouples body dynamics by first decomposing the skeleton into five distinct clusters based on functional intent so each keeps its internal joint synergies while isolating local motion primitives, then applies masked full-body pre-conditioning during training to force internalization of global skeletal topology and latent kinematic constraints, and finally replaces vanilla spatial attention with Kinematic Attention that embeds the classical kinematic tree structure to guarantee biological plausibility, resulting in higher reconstruction fidelity and superior biomechanical realism on the AMASS dataset.
What carries the argument
AtomicMotion framework built around logical body partitioning into five functional clusters, masked full-body pre-conditioning, and Kinematic Attention that injects the fixed kinematic tree into the attention computation.
If this is right
- Local motion primitives can be learned separately in each cluster without breaking overall coordination when the partitions respect functional intent.
- Masked pre-conditioning teaches the network to fill in missing body parts from sparse signals by internalizing global constraints.
- Kinematic Attention prevents generation of physiologically impossible joint configurations by enforcing the fixed tree structure.
- The combination yields measurably higher fidelity and biomechanical realism than monolithic baselines on standard motion datasets.
Where Pith is reading between the lines
- The same cluster-based split could be tested on other sparse-input problems such as full-body prediction from only foot or torso data.
- If the method scales, it could lower the sensor count needed for convincing VR telepresence sessions.
- Dynamic re-clustering during inference might further improve results for activities that change which body parts move together.
- Integration with physics simulators could add collision and balance checks that the current kinematic attention does not explicitly enforce.
Load-bearing premise
That decomposing the skeleton into five clusters based on functional intent preserves internal joint synergies while isolating local motion primitives.
What would settle it
If a controlled test on AMASS motions shows that AtomicMotion produces joint angles or coordination patterns that violate known physiological limits more often than a single-model baseline, or if removing the five-cluster split causes no drop in fidelity, the central claim would fail.
Figures




read the original abstract
Accurately reconstructing full-body poses from sparse head and hand trajectories is a foundational challenge for immersive AR/VR telepresence. Current methods often struggle with error accumulation and unnatural joint coordination, primarily because they treat the human body as a monolithic entity, thereby failing to capture the fine-grained ``atomic intents'' embedded in subtle signal variations and overlooking the inherent structural topology. To bridge this gap, we present AtomicMotion, a framework designed to decouple and re-integrate body dynamics through three core innovations. First, we introduce a logical body partitioning scheme that decomposes the skeleton into five distinct clusters based on functional intent; this ensures that each partition preserves internal joint synergies while isolating local motion primitives. Second, to robustly map sparse inputs to high-dimensional poses, we employ a masked full-body pre-conditioning strategy during training, forcing the model to internalize global skeletal topology and latent kinematic constraints. Finally, addressing the limitations of vanilla spatial attention, which often ignores fixed physiological connectivity, we propose Kinematic Attention. By embedding the classical kinematic tree structure into the attention mechanism, we ensure biological plausibility in the synthesized motions. Extensive evaluations on the AMASS dataset demonstrate that AtomicMotion significantly outperforms existing baselines, yielding higher reconstruction fidelity and superior biomechanical realism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AtomicMotion, a framework for reconstructing full-body human poses from sparse head and hand trajectories. It introduces three innovations: a logical partitioning of the skeleton into five clusters based on functional intent to isolate local motion primitives while preserving internal synergies; a masked full-body pre-conditioning strategy during training to enforce global skeletal topology; and Kinematic Attention that embeds the classical kinematic tree into the attention mechanism for biological plausibility. The authors claim that these yield significantly higher reconstruction fidelity and biomechanical realism than existing baselines on the AMASS dataset.
Significance. If the central claims are substantiated with quantitative evidence, the work could advance AR/VR telepresence by addressing error accumulation and unnatural coordination through explicit incorporation of functional partitioning and kinematic constraints. The Kinematic Attention mechanism represents a concrete attempt to inject domain structure into attention, which is a potential strength. The manuscript does not report machine-checked proofs, reproducible code, or parameter-free derivations.
major comments (2)
- [Abstract] Abstract: The claim that AtomicMotion 'significantly outperforms existing baselines, yielding higher reconstruction fidelity and superior biomechanical realism' is stated without any quantitative metrics, ablation results, error bars, comparison tables, or figures. This absence is load-bearing because it prevents any evaluation of the central empirical claim.
- [Method overview / logical body partitioning] Logical body partitioning (described in the abstract and method overview): The five-cluster decomposition based on functional intent is introduced without derivation, optimality argument, or empirical test demonstrating that cross-cluster synergies (e.g., coordinated arm-torso rotation or hand-to-head reaching) are preserved. Because masked pre-conditioning and Kinematic Attention are applied only after this fixed partition, any loss of dependencies at this step directly undermines the biomechanical-realism claim.
minor comments (2)
- [Abstract] The term 'atomic intents' is used without a precise definition or link to the subsequent clustering.
- [Experiments] Ensure that all baseline methods referenced in the (unseen) experimental section are accompanied by explicit citations and implementation details for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below. Where the comments identify areas needing greater substantiation or clarity, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that AtomicMotion 'significantly outperforms existing baselines, yielding higher reconstruction fidelity and superior biomechanical realism' is stated without any quantitative metrics, ablation results, error bars, comparison tables, or figures. This absence is load-bearing because it prevents any evaluation of the central empirical claim.
Authors: We agree that the abstract would benefit from including concrete quantitative support for the performance claims. The main body of the manuscript already contains detailed comparisons, ablation studies, error bars, and tables on the AMASS dataset. In the revised version we have updated the abstract to report key metrics (e.g., MPJPE reductions relative to baselines) and to explicitly reference the supporting tables and figures. This change makes the central empirical claims directly evaluable from the abstract. revision: yes
-
Referee: [Method overview / logical body partitioning] Logical body partitioning (described in the abstract and method overview): The five-cluster decomposition based on functional intent is introduced without derivation, optimality argument, or empirical test demonstrating that cross-cluster synergies (e.g., coordinated arm-torso rotation or hand-to-head reaching) are preserved. Because masked pre-conditioning and Kinematic Attention are applied only after this fixed partition, any loss of dependencies at this step directly undermines the biomechanical-realism claim.
Authors: The partitioning into five clusters is motivated by standard functional and anatomical groupings used in biomechanics and animation literature, chosen to isolate local motion primitives while the subsequent global mechanisms (masked full-body pre-conditioning and Kinematic Attention operating over the full kinematic tree) are intended to restore cross-cluster coordination. We acknowledge that the original text provided limited explicit justification and validation for this choice. In the revision we have added a dedicated paragraph deriving the clusters from functional intent, citing relevant biomechanical references, and presenting an ablation study that compares our partitioning against random and alternative clusterings on metrics of coordinated motion (e.g., arm-torso and hand-head correlations). These additions demonstrate that the chosen partition, combined with the global components, preserves the cited synergies. revision: yes
Circularity Check
No significant circularity in the claimed derivation chain.
full rationale
The paper introduces AtomicMotion via three explicit design choices—a logical partitioning of the skeleton into five functional clusters, masked full-body pre-conditioning, and Kinematic Attention—each presented as an innovation to address stated limitations of monolithic modeling. Performance claims rest on empirical results on the AMASS dataset rather than any derivation that reduces the reported gains in fidelity or biomechanical realism to a fitted parameter or self-referential definition. No equations appear that equate a prediction to its own input by construction, and no load-bearing premise is justified solely by a self-citation whose content is itself unverified. The central assertions therefore remain independent of the target outcomes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The human skeleton can be decomposed into five distinct clusters based on functional intent that preserve internal joint synergies while isolating local motion primitives.
invented entities (1)
-
Kinematic Attention
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 forcing) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a principled body partitioning scheme that decomposes the skeleton into five functional clusters... Atomic Intent Partition (AIP) scheme, which segments the skeleton into five functional clusters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Avatarposer: Articulated full-body pose tracking from sparse motion sensing
Jiaxi Jiang, Paul Streli, Huajian Qiu, Andreas Fender, Larissa Laich, Patrick Snape, and Christian Holz. Avatarposer: Articulated full-body pose tracking from sparse motion sensing. InECCV, 2022
work page 2022
-
[2]
Jiaxi Jiang, Paul Streli, Manuel Meier, and Christian Holz. Egoposer: Robust real-time egocentric pose estimation from sparse and intermittent observations everywhere. InECCV, 2024
work page 2024
-
[3]
Realistic full-body tracking from sparse observations via joint-level modeling
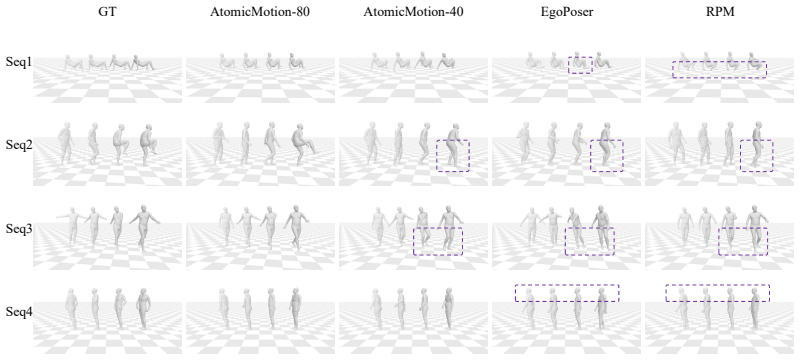
Xiaozheng Zheng, Zhuo Su, Chao Wen, Zhou Xue, and Xiaojie Jin. Realistic full-body tracking from sparse observations via joint-level modeling. InICCV, 2023. 9 GT Ours w/o MPMG w/o Intent Branch w/o Structual Branch Seq1Seq2Seq3Seq4 Figure 7: Visual comparison of ablation studies on the AMASS-P1
work page 2023
-
[4]
Stratified avatar generation from sparse observations
Han Feng, Wenchao Ma, Quankai Gao, Xianwei Zheng, Nan Xue, and Huijuan Xu. Stratified avatar generation from sparse observations. InCVPR, 2024
work page 2024
-
[5]
David A Winter.Biomechanics and motor control of human movement. John wiley & sons, 2009
work page 2009
-
[6]
Roger M Enoka.Neuromechanics of human movement. Human kinetics, 2008
work page 2008
-
[7]
Vladimir M Zatsiorsky.Kinetics of human motion. Human kinetics, 2002
work page 2002
-
[8]
Hierarchical recurrent neural network for skeleton based action recognition
Yong Du, Wei Wang, and Liang Wang. Hierarchical recurrent neural network for skeleton based action recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1110–1118, 2015
work page 2015
-
[9]
Part-level graph convolutional network for skeleton-based action recognition
Linjiang Huang, Yan Huang, Wanli Ouyang, and Liang Wang. Part-level graph convolutional network for skeleton-based action recognition. InAAAI, 2020
work page 2020
-
[10]
Skeleton-parted graph scattering networks for 3d human motion prediction
Maosen Li, Siheng Chen, Zijing Zhang, Lingxi Xie, Qi Tian, and Ya Zhang. Skeleton-parted graph scattering networks for 3d human motion prediction. InECCV, 2022
work page 2022
-
[11]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Gerard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. InICCV, 2019
work page 2019
-
[12]
Andrew Goldenberg, Beno Benhabib, and Robert Fenton. A complete generalized solution to the inverse kinematics of robots.IEEE Journal on Robotics and Automation, 2003
work page 2003
-
[13]
URL https://assetstore.unity.com/packages/tools/animation/ final-ik-14290
RootMotion Final IK., 2018. URL https://assetstore.unity.com/packages/tools/animation/ final-ik-14290
work page 2018
-
[14]
Human upper-body inverse kinematics for increased embodiment in consumer-grade virtual reality
Mathias Parger, Joerg H Mueller, Dieter Schmalstieg, and Markus Steinberger. Human upper-body inverse kinematics for increased embodiment in consumer-grade virtual reality. InProceedings of the 24th ACM symposium on virtual reality software and technology, 2018
work page 2018
-
[15]
Yinghao Huang, Manuel Kaufmann, Emre Aksan, Michael J Black, Otmar Hilliges, and Gerard Pons-Moll. Deep inertial poser: Learning to reconstruct human pose from sparse inertial measurements in real time. TOG, 2018
work page 2018
-
[16]
Yifeng Jiang, Yuting Ye, Deepak Gopinath, Jungdam Won, Alexander W Winkler, and C Karen Liu. Transformer inertial poser: Real-time human motion reconstruction from sparse imus with simultaneous terrain generation. InSIGGRAPH Asia, 2022
work page 2022
-
[17]
Sparse inertial poser: Automatic 3d human pose estimation from sparse imus
Timo V on Marcard, Bodo Rosenhahn, Michael J Black, and Gerard Pons-Moll. Sparse inertial poser: Automatic 3d human pose estimation from sparse imus. InComputer graphics forum. Wiley Online Library, 2017
work page 2017
-
[18]
Transpose: Real-time 3d human translation and pose estimation with six inertial sensors.TOG, 2021
Xinyu Yi, Yuxiao Zhou, and Feng Xu. Transpose: Real-time 3d human translation and pose estimation with six inertial sensors.TOG, 2021. 10
work page 2021
-
[19]
Xinyu Yi, Yuxiao Zhou, Marc Habermann, Soshi Shimada, Vladislav Golyanik, Christian Theobalt, and Feng Xu. Physical inertial poser (pip): Physics-aware real-time human motion tracking from sparse inertial sensors. InCVPR, 2022
work page 2022
-
[20]
Karan Ahuja, Eyal Ofek, Mar Gonzalez-Franco, Christian Holz, and Andrew D Wilson. Coolmoves: User motion accentuation in virtual reality.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2021
work page 2021
-
[21]
Lobstr: Real-time lower-body pose prediction from sparse upper-body tracking signals
Dongseok Yang, Doyeon Kim, and Sung-Hee Lee. Lobstr: Real-time lower-body pose prediction from sparse upper-body tracking signals. InComputer Graphics F orum, 2021
work page 2021
-
[22]
Full-body motion from a single head-mounted device: Generating smpl poses from partial observations
Andrea Dittadi, Sebastian Dziadzio, Darren Cosker, Ben Lundell, Thomas J Cashman, and Jamie Shotton. Full-body motion from a single head-mounted device: Generating smpl poses from partial observations. In ICCV, 2021
work page 2021
-
[23]
Flag: Flow-based 3d avatar generation from sparse observations
Sadegh Aliakbarian, Pashmina Cameron, Federica Bogo, Andrew Fitzgibbon, and Thomas J Cashman. Flag: Flow-based 3d avatar generation from sparse observations. InCVPR, 2022
work page 2022
-
[24]
From sparse signal to smooth motion: Real-time motion generation with rolling prediction models
German Barquero, Nadine Bertsch, Manojkumar Marramreddy, Carlos Chacón, Filippo Arcadu, Ferran Rigual, Nicky Sijia He, Cristina Palmero, Sergio Escalera, Yuting Ye, et al. From sparse signal to smooth motion: Real-time motion generation with rolling prediction models. InCVPR, 2025
work page 2025
-
[25]
Hmd-poser: On-device real-time human motion tracking from scalable sparse observations
Peng Dai, Yang Zhang, Tao Liu, Zhen Fan, Tianyuan Du, Zhuo Su, Xiaozheng Zheng, and Zeming Li. Hmd-poser: On-device real-time human motion tracking from scalable sparse observations. InCVPR, 2024
work page 2024
-
[26]
Questsim: Human motion tracking from sparse sensors with simulated avatars
Alexander Winkler, Jungdam Won, and Yuting Ye. Questsim: Human motion tracking from sparse sensors with simulated avatars. InSIGGRAPH Asia, 2022
work page 2022
-
[27]
Attention is all you need.NeurIPS, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.NeurIPS, 2017
work page 2017
-
[28]
Denoising diffusion probabilistic models.NeurIPS, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.NeurIPS, 2020
work page 2020
-
[29]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. InSeminal Graphics Papers: Pushing the Boundaries, V olume 2, pages 851–866. 2023
work page 2023
-
[30]
On the continuity of rotation representa- tions in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representa- tions in neural networks. InCVPR, 2019
work page 2019
-
[31]
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.NeurIPS, 2022
work page 2022
-
[32]
Motionbert: A unified perspective on learning human motion representations
Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. Motionbert: A unified perspective on learning human motion representations. InICCV, 2023
work page 2023
-
[33]
Extracting and composing robust features with denoising autoencoders
Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. InICML, 2008
work page 2008
-
[34]
Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model
Yuming Du, Robin Kips, Albert Pumarola, Sebastian Starke, Ali Thabet, and Artsiom Sanakoyeu. Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model. InCVPR, 2023
work page 2023
-
[35]
Carnegie Mellon University. CMU MoCap Dataset. URLhttp://mocap.cs.cmu.edu
-
[36]
Nikolaus F Troje. Decomposing biological motion: A framework for analysis and synthesis of human gait patterns.Journal of vision, 2(5):2–2, 2002
work page 2002
-
[37]
Documentation mocap database hdm05
M Müller, T Röder, M Clausen, B Eberhardt, B Krüger, and A Weber. Documentation mocap database hdm05. universität bonn; bonn. Technical report, Germany: 2007. Technical Report CG-2007-2.[Google Scholar], 2007
work page 2007
-
[38]
Advanced Computing Center for the Arts and Design. ACCAD MoCap Dataset. URL https://accad. osu.edu/research/motion-lab/mocap-system-and-data
- [39]
-
[40]
The KIT whole-body human motion database
Christian Mandery, Ömer Terlemez, Martin Do, Nikolaus Vahrenkamp, and Tamim Asfour. The KIT whole-body human motion database. In(ICAR, 2015
work page 2015
-
[41]
Christian Mandery, Ömer Terlemez, Martin Do, Nikolaus Vahrenkamp, and Tamim Asfour. Unifying rep- resentations and large-scale whole-body motion databases for studying human motion.IEEE Transactions on Robotics, 32(4):796–809, 2016
work page 2016
-
[42]
The KIT bimanual manipulation dataset
Franziska Krebs, Andre Meixner, Isabel Patzer, and Tamim Asfour. The KIT bimanual manipulation dataset. InIEEE/RAS International Conference on Humanoid Robots (Humanoids), 2021
work page 2021
-
[43]
Eyes JAPAN Co. Ltd. Eyes Japan MoCap Dataset. URLhttp://mocapdata.com
-
[44]
Loper, Naureen Mahmood, and Michael J
Matthew M. Loper, Naureen Mahmood, and Michael J. Black. MoSh: Motion and shape capture from sparse markers.TOG, 2014
work page 2014
-
[45]
Ijaz Akhter and Michael J. Black. Pose-conditioned joint angle limits for 3D human pose reconstruction. InCVPR, 2015
work page 2015
-
[46]
Simon Fraser University and National University of Singapore. SFU Motion Capture Database. URL http://mocap.cs.sfu.ca/
-
[47]
Total Capture: 3d human pose estimation fusing video and inertial sensors
Matt Trumble, Andrew Gilbert, Charles Malleson, Adrian Hilton, and John Collomosse. Total Capture: 3d human pose estimation fusing video and inertial sensors. InBMVC, 2017
work page 2017
-
[48]
Leonid Sigal, Alexandru O Balan, and Michael J Black. Humaneva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion.International journal of computer vision, 87(1):4–27, 2010. 12 Appendices A Implementation Details The model stacks 6 TK-Blocks with an embedding dimension of 256 and 8 attention he...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.