People-Centred Medical Image Analysis via Fairness-Aware Human-AI Cooperation
Pith reviewed 2026-05-07 16:30 UTC · model grok-4.3
The pith
PecMan uses a dynamic gating mechanism to jointly optimize fairness, accuracy, and clinician workload in medical image analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
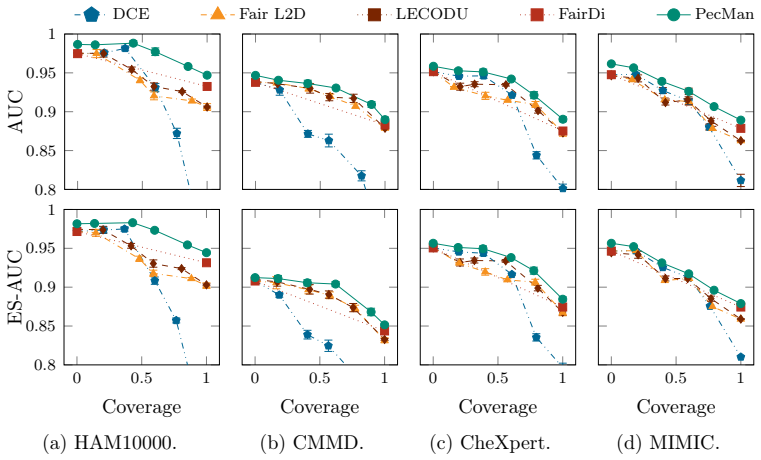
The central discovery is that a people-centred approach to medical image analysis, implemented via PecMan's dynamic gating that routes cases to AI, human clinicians, or joint review while respecting workload limits, achieves better combined performance on accuracy, fairness across diverse populations, and workflow integration than prior separate solutions.
What carries the argument
The dynamic gating mechanism within PecMan, which assigns each medical image case to AI alone, clinician alone, or both, subject to overall clinician availability constraints, while pursuing joint optimization of diagnostic accuracy and fairness.
If this is right
- Performance biases that hinder regulatory approval can be mitigated by explicit fairness optimization.
- Clinician adoption increases when AI does not disrupt established workflows or overload staff.
- Trade-offs between the three goals can be quantified and managed using the FairHAI benchmark.
- The framework demonstrates consistent gains over methods optimizing only subsets of these objectives.
Where Pith is reading between the lines
- Applying similar gating logic could help in other high-stakes domains with scarce expert time.
- Real-world deployment might require adapting the workload model to specific hospital schedules and team structures.
- The benchmark provides a template for testing other human-AI systems on fairness and integration metrics simultaneously.
Load-bearing premise
The assumption that clinician availability can be modeled as a simple dynamic constraint that captures real clinical settings without overlooking workflow disruptions or introducing new barriers.
What would settle it
If a study in an actual clinic finds that using PecMan results in lower overall diagnostic quality or higher clinician burnout than using separate fairness and deferral tools, the joint optimization benefit would be falsified.
Figures







read the original abstract
Machine learning models for medical image analysis often exhibit subgroup-dependent performance, which impacts how decisions should be allocated between automated systems and human experts under limited resources. Prior work on AI fairness and human-AI cooperation, including learning to defer (L2D) and learning to complement (L2C), typically addresses these problems in isolation. We propose People-Centred Medical Image Analysis (PecMan), a framework for fairness-aware human-AI co-operative classification that jointly models subgroup-dependent reliability, decision allocation, and collaborative prediction. PecMan combines subgroup-specialised predictors with a gating and consolidation mechanism that dynamically assigns cases to automated models, human experts, or their combination, without requiring sensitive attributes at test time. We also introduce the FairHAI benchmark for evaluating trade-offs between predictive accuracy, subgroup equity, and human involvement. In addition, we provide a theoretical analysis of multi-agent gating via selection regret and characterise fairness-coverage trade-offs under input-dependent allocation. Experiments across multiple medical imaging datasets demonstrate that PecMan achieves consistently improved trade-offs compared to methods that address fairness or human-AI cooperation separately.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes People-Centred Medical Image Analysis (PecMan), a human-AI framework that jointly optimizes fairness, diagnostic accuracy, and workflow effectiveness through a dynamic gating mechanism that assigns cases to AI, clinicians, or both under clinician workload constraints. It introduces the FairHAI benchmark for evaluating trade-offs between accuracy, fairness, and clinician workload, and reports that experiments show PecMan consistently outperforms existing methods.
Significance. If the results hold and the modeled constraints align with real clinical environments, this work would be significant in advancing clinically viable medical AI by addressing the interdependence of fairness and workflow integration, areas previously studied in isolation. The FairHAI benchmark could serve as a useful tool for future research in human-centred AI.
major comments (1)
- The central claim that PecMan outperforms baselines on FairHAI depends on the dynamic gating jointly optimizing under a modeled clinician availability constraint. However, this treats availability as a clean resource allocation problem, while real clinical settings introduce unmodeled factors including communication costs, decision latency, EHR integration friction, and variable case complexity that could invert the trade-offs. Without validation that the synthetic constraint matches observed clinical logs, the outperformance does not establish clinical viability.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address the major concern point by point below, acknowledging the limitations of our modeled constraints while clarifying the scope of our claims.
read point-by-point responses
-
Referee: The central claim that PecMan outperforms baselines on FairHAI depends on the dynamic gating jointly optimizing under a modeled clinician availability constraint. However, this treats availability as a clean resource allocation problem, while real clinical settings introduce unmodeled factors including communication costs, decision latency, EHR integration friction, and variable case complexity that could invert the trade-offs. Without validation that the synthetic constraint matches observed clinical logs, the outperformance does not establish clinical viability.
Authors: We agree that the clinician availability constraint in PecMan and FairHAI is modeled as a simplified resource allocation problem and does not incorporate additional real-world factors such as communication costs, decision latency, EHR integration friction, and variable case complexity. The FairHAI benchmark is a controlled, synthetic environment intended to isolate and evaluate the effects of joint optimization of fairness, accuracy, and workflow under workload constraints. Our central claim is limited to outperformance within this benchmark; we do not assert that the results establish clinical viability. In the revised manuscript, we will expand the limitations and discussion sections to explicitly address these unmodeled factors, analyze how they could alter the observed trade-offs, and propose directions for empirical validation against clinical logs and real workflow data. revision: yes
Circularity Check
No circularity in derivation chain; framework and benchmark are independently proposed
full rationale
The paper introduces PecMan as a joint optimization framework via dynamic gating under workload constraints and the FairHAI benchmark, with performance claims resting on experimental comparisons rather than any closed-form derivation, fitted parameter renamed as prediction, or self-referential definition. No equations, ansatzes, or uniqueness theorems are presented in the provided text that reduce to inputs by construction. Prior work on L2D/L2C is cited externally without self-citation load-bearing the central claim. The derivation chain is self-contained as a proposal validated by new experiments.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.