IREU: Identity-Related Encoder-Only Unlearning for Customized Portrait Generation
Pith reviewed 2026-06-30 06:28 UTC · model grok-4.3
The pith
Selective offline perturbation of only identity-related features in the image encoder unlearns target identities while preserving fidelity for retained identities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
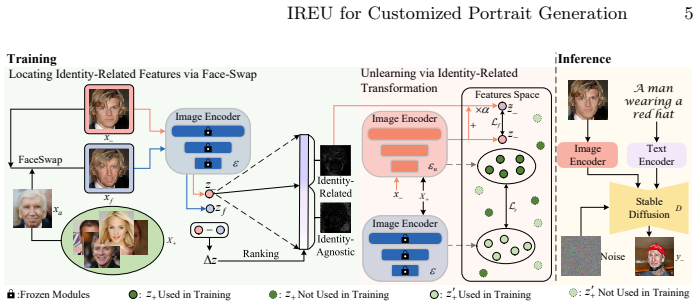
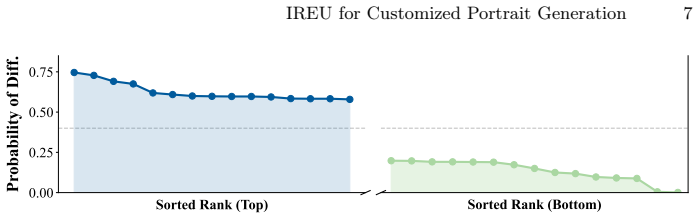
The proposed IREU method first locates identity-related features in an offline manner and then only performs feature perturbations on them. This achieves better identity unlearning performance for target identities to be unlearned, while keeping high fidelity for other identities to be retained. Additionally, the unlearned image encoder is generalizable across different generators with the same encoder without fine-tuning.
What carries the argument
IREU, the offline location of identity-related features followed by selective perturbation restricted to those features in the image encoder.
Load-bearing premise
That identity-related features can be reliably located in an offline manner such that selective perturbation removes the target identity without unintended side effects on retained identities or overall generation quality.
What would settle it
Measuring a statistically significant drop in identity similarity scores for retained identities after IREU is applied, relative to the original encoder, would falsify the preservation claim.
Figures









read the original abstract
Customized Portrait Generation (CPG) technologies have been widely used to generate high-fidelity person images given an input image indicating the identity and a text prompt indicating the required edits. Yet these methods pose significant privacy risks by spreading fake visual information. Against such risks, each public generator should be able to suppress its generation ability for a particular person when requested. Therefore, in this work we investigate the identity unlearning problem for CPG. Since there are no previous methods in this field, we propose a simple baseline that updates the image encoder by minimizing identity similarity between generated and input images for target identities to be unlearned, while maximizing it for identities to be retained. However, we find such a global perturbation in the feature space harms the fidelity of generated images for other identities to be retained. To solve this problem, we propose a novel method IREU, which first locates identity-related features in an offline manner and then only performs feature perturbations on them. The experimental results show that our proposed method IREU achieves better identity unlearning performance for target identities to be unlearned, and also keeps high fidelity for other identities to be retained. In addition, our unlearned image encoder is generalizable across different generators with the same encoder without fine-tuning, which is friendly for deployment in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses privacy risks in Customized Portrait Generation (CPG) by proposing identity unlearning for specific persons. It introduces a baseline that globally updates the image encoder to minimize identity similarity for target identities while maximizing it for retained ones, but observes that this harms fidelity for retained identities. To address this, IREU locates identity-related features offline and applies perturbations selectively to them. The abstract claims that IREU yields better unlearning for targets, preserves high fidelity for retained identities, and produces an encoder generalizable across different generators without fine-tuning.
Significance. If the empirical claims are substantiated, the work would offer a practical encoder-only mechanism for selective identity suppression in generative portrait models, mitigating privacy harms while maintaining utility for non-target identities and enabling deployment across multiple generators.
major comments (2)
- [Abstract] Abstract: The central claim that 'the experimental results show that our proposed method IREU achieves better identity unlearning performance for target identities to be unlearned, and also keeps high fidelity for other identities to be retained' is unsupported by any metrics, datasets, ablation studies, or quantitative comparisons, rendering the performance advantage unverifiable.
- [Abstract] Abstract: The method's core step of locating 'identity-related features in an offline manner' is described only at the level of the claim; no procedure, validation that the located features are identity-specific rather than entangled with generation quality, or ablation isolating the contribution of selective (vs. global) perturbation is provided, which is load-bearing for the argument that IREU solves the fidelity problem identified in the baseline.
minor comments (1)
- [Abstract] The abstract refers to 'each public generator' and 'different generators with the same encoder' without naming any specific CPG architectures or encoders used, which would aid immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will revise the abstract to better substantiate the claims by incorporating key quantitative results and a concise description of the core procedure, while ensuring the full manuscript's experimental details remain the primary support.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the experimental results show that our proposed method IREU achieves better identity unlearning performance for target identities to be unlearned, and also keeps high fidelity for other identities to be retained' is unsupported by any metrics, datasets, ablation studies, or quantitative comparisons, rendering the performance advantage unverifiable.
Authors: The abstract is a concise summary; the full manuscript provides the supporting quantitative evidence, including identity similarity metrics, fidelity scores, dataset details, baseline comparisons, and ablation studies in the experiments section. We will revise the abstract to include specific metrics and dataset references to make the performance claims more directly verifiable. revision: yes
-
Referee: [Abstract] Abstract: The method's core step of locating 'identity-related features in an offline manner' is described only at the level of the claim; no procedure, validation that the located features are identity-specific rather than entangled with generation quality, or ablation isolating the contribution of selective (vs. global) perturbation is provided, which is load-bearing for the argument that IREU solves the fidelity problem identified in the baseline.
Authors: The full manuscript details the offline location procedure, validation experiments confirming identity specificity, and ablations isolating selective perturbation effects in Section 3 and the experiments. We agree the abstract is high-level and will revise it to briefly outline the procedure and reference the supporting analyses. revision: yes
Circularity Check
No significant circularity; empirical method with independent experimental validation
full rationale
The paper describes a baseline global perturbation approach, observes its limitation on retained identities, and proposes IREU as an alternative that performs offline localization followed by selective perturbation. All central claims rest on experimental comparisons rather than any derivation that reduces to fitted inputs, self-definitions, or self-citation chains. No equations or uniqueness theorems are invoked that collapse back to the method's own assumptions by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Identity similarity measured in the image encoder feature space is a reliable proxy for generation behavior.
Reference graph
Works this paper leans on
-
[1]
In: CVPR
Ahmed, S.M., Basaran, U.Y., Raychaudhuri, D.S., Dutta, A., Kundu, R., Niloy, F.F., Guler, B., Roy-Chowdhury, A.K.: Towards source-free machine unlearning. In: CVPR. pp. 4948–4957 (2025)
2025
-
[2]
In: ICCV
Bala, A., Chowdhury, R., Jaiswal, R., Roheda, S.: Dct-shield: A robust frequency domain defense against malicious image editing. In: ICCV. pp. 18876–18884 (2025)
2025
-
[3]
In: CVPR
Chen, M., Gao, W., Liu, G., Peng, K., Wang, C.: Boundary unlearning: Rapid forgetting of deep networks via shifting the decision boundary. In: CVPR. pp. 7766–7775 (2023)
2023
-
[4]
In: CVPRW
Choi, D., Choi, S., Lee, E., Seo, J., Na, D.: Towards efficient machine unlearning with data augmentation: Guided loss-increasing (GLI) to prevent the catastrophic model utility drop. In: CVPRW. pp. 93–102 (2024)
2024
-
[5]
arXiv preprint arXiv:2405.11135 (2024)
Feng, W., Zhou, W., He, J., Zhang, J., Wei, T., Li, G., Zhang, T., Zhang, W., Yu, N.: Aqualora: Toward white-box protection for customized stable diffusion models via watermark lora. arXiv preprint arXiv:2405.11135 (2024)
-
[6]
In: ICLR (2023)
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image gener- ation using textual inversion. In: ICLR (2023)
2023
-
[7]
In: ICCV
Gandikota, R., Materzynska, J., Fiotto-Kaufman, J., Bau, D.: Erasing concepts from diffusion models. In: ICCV. pp. 2426–2436 (2023)
2023
-
[8]
In: WACV
Gandikota, R., Orgad, H., Belinkov, Y., Materzyńska, J., Bau, D.: Unified concept editing in diffusion models. In: WACV. pp. 5111–5120 (2024)
2024
-
[9]
In: CVPR
Gao, G., Huang, H., Fu, C., Li, Z., He, R.: Information bottleneck disentanglement for identity swapping. In: CVPR. pp. 3404–3413 (2021)
2021
-
[10]
In: ICCV
Gao, H., Pang, T., Du, C., Hu, T., Deng, Z., Lin, M.: Meta-unlearning on diffusion models: Preventing relearning unlearned concepts. In: ICCV. pp. 2131–2141 (2025)
2025
-
[11]
In: ECCV
Gong, C., Chen, K., Wei, Z., Chen, J., Jiang, Y.G.: Reliable and efficient concept erasure of text-to-image diffusion models. In: ECCV. pp. 73–88 (2024)
2024
-
[12]
In: NeurIPS
Gu, H., Ong, W.K., Chan, C.S., Fan, L.: Ferrari: Federated feature unlearning via optimizing feature sensitivity. In: NeurIPS. vol. 37, pp. 24150–24180 (2024)
2024
-
[13]
In: NeurIPS
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. In: NeurIPS. vol. 30 (2017)
2017
-
[14]
In: CVPR
Huang, Y., Wang, Y., Tai, Y., Liu, X., Shen, P., Li, S., Li, J., Huang, F.: Curric- ularface: Adaptive curriculum learning loss for deep face recognition. In: CVPR. pp. 5900–5909 (2020)
2020
-
[15]
In: CVPR
Huang,Z.,Chan,K.C.K.,Jiang,Y.,Liu,Z.:Collaborativediffusionformulti-modal face generation and editing. In: CVPR. pp. 6080–6090 (2023)
2023
-
[16]
In: CVPR (2025)
Kang, T., Jeong, S., Jang, H., Choo, J.: Zero-shot head swapping in real-world scenarios. In: CVPR (2025)
2025
-
[17]
In: ICLR (2018)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability, and variation. In: ICLR (2018)
2018
-
[18]
In: CVPR
Khalil, Y.H., Brunswic, L.M., Lamghari, S., Li, X., Beitollahi, M., Chen, X.: Not: Federated unlearning via weight negation. In: CVPR. pp. 25759–25769 (2025)
2025
-
[19]
In: CVPR
Kim, J., Gu, G., Park, M., Park, S., Choo, J.: Stableviton: Learning semantic correspondence with latent diffusion model for virtual try-on. In: CVPR. pp. 8176– 8185 (2024)
2024
-
[20]
In: CVPR
Lee, B.H., Lim, S., Chun, S.Y.: Localized concept erasure for text-to-image diffu- sion models using training-free gated low-rank adaptation. In: CVPR. pp. 18596– 18606 (2025) IREU for Customized Portrait Generation 17
2025
-
[21]
In: NeurIPS
Lee, T.Y., Seo, J., Ko, J.H., Park, G.M.: Perturb a model, not an image: Towards robust privacy protection via anti-personalized diffusion models. In: NeurIPS. vol. 38, pp. 92410–92442 (2025)
2025
-
[22]
arXiv preprint arXiv:2406.15305 (2024)
Li, A., Mo, Y., Li, M., Wang, Y.: Pid: Prompt-independent data protection against latent diffusion models. arXiv preprint arXiv:2406.15305 (2024)
-
[23]
In: CVPR
Li, M., Chen, J., Feng, W., Li, B., Dai, F., Zhao, S., He, Q.: Hyperlora: Parameter- efficient adaptive generation for portrait synthesis. In: CVPR. pp. 13114–13123 (2025)
2025
-
[24]
IEEE Trans
Li, N., Zhou, C., Gao, Y., Chen, H., Zhang, Z., Kuang, B., Fu, A.: Machine un- learning: Taxonomy, metrics, applications, challenges, and prospects. IEEE Trans. Neural Networks Learn. Syst.36(8), 13709–13729 (2025)
2025
-
[25]
In: CVPR
Li, Z., Cao, M., Wang, X., Qi, Z., Cheng, M., Shan, Y.: Photomaker: Customizing realistic human photos via stacked ID embedding. In: CVPR. pp. 8640–8650 (2024)
2024
-
[26]
In: ICCV
Liu, Z., Luo, P., Wang, X., Tang, X.: Deep learning face attributes in the wild. In: ICCV. pp. 3730–3738 (2015)
2015
-
[27]
In: CVPR
Lu, S., Wang, Z., Li, L., Liu, Y., Kong, A.W.K.: Mace: Mass concept erasure in diffusion models. In: CVPR. pp. 6430–6440 (2024)
2024
-
[28]
In: CVPR
Lyu, M., Yang, Y., Hong, H., Chen, H., Jin, X., He, Y., Xue, H., Han, J., Ding, G.: One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. In: CVPR. pp. 7559–7568 (2024)
2024
-
[29]
In: AAAI
Moon, S., Cho, S., Kim, D.: Feature unlearning for pre-trained gans and vaes. In: AAAI. pp. 21420–21428 (2024)
2024
-
[30]
In:ICML.vol.139, pp.8748–8763 (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models fromnatural languagesupervision. In:ICML.vol.139, pp.8748–8763 (2021)
2021
-
[31]
In: CVPR
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. In: CVPR. pp. 22500–22510 (2023)
2023
-
[32]
In: CVPR
Seo, J., Lee, S., Lee, T., Moon, S., Park, G.: Generative unlearning for any identity. In: CVPR. pp. 9151–9161 (2024)
2024
-
[33]
In: CVPR
Shaheryar, M., Lee, J.T., Jung, S.K.: Black hole-driven identity absorbing in dif- fusion models. In: CVPR. pp. 28544–28554 (2025)
2025
-
[34]
Shamshad,F.,Naseer,M.,Nandakumar,K.:Clip2protect:Protectingfacialprivacy usingtext-guidedmakeupviaadversariallatentsearch.In:CVPR.pp.20595–20605 (2023)
2023
-
[35]
In: CVPR
Song, Y., Yang, P., Ci, H., Shou, M.Z.: Idprotector: An adversarial noise encoder to protect against id-preserving image generation. In: CVPR. pp. 3019–3028 (2025)
2025
-
[36]
In: CVPR
Spartalis, C.N., Semertzidis, T., Gavves, E., Daras, P.: Lotus: Large-scale machine unlearning with a taste of uncertainty. In: CVPR. pp. 10046–10055 (2025)
2025
-
[37]
In: ECCV
Tian, L., Wang, Q., Zhang, B., Bo, L.: EMO: emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions. In: ECCV. vol. 15141, pp. 244–260 (2024)
2024
-
[38]
A Practical Guide, 1st Ed., Cham: Springer International Publishing10(3152676), 10–5555 (2017)
Voigt, P., dem Bussche, A.V.: The eu general data protection regulation (gdpr). A Practical Guide, 1st Ed., Cham: Springer International Publishing10(3152676), 10–5555 (2017)
2017
-
[39]
arXiv preprint arXiv:2303.09522 (2023)
Voynov, A., Chu, Q., Cohen-Or, D., Aberman, K.: P+: Extended textual condi- tioning in text-to-image generation. arXiv preprint arXiv:2303.09522 (2023)
-
[40]
Shi et al
Wang, H., Weng, Y., Li, Y., Guo, Z., Du, J., Niu, S., Ma, J., He, S., Wu, X., Hu, Q., Yin, B., Liu, C., Liu, Q.: Emotivetalk: Expressive talking head generation 18 C. Shi et al. through audio information decoupling and emotional video diffusion. In: CVPR. pp. 26212–26221 (2025)
2025
-
[41]
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Wang, Q., Bai, X., Wang, H., Qin, Z., Chen, A.: Instantid: Zero-shot identity- preserving generation in seconds. arXiv preprint arXiv:2401.07519 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
In: CVPR
Wang, Z., Guo, J., Zhu, J., Li, Y., Huang, H., Chen, M., Tu, Z.: Sleepermark: Towards robust watermark against fine-tuning text-to-image diffusion models. In: CVPR. pp. 8213–8224 (2025)
2025
-
[43]
In: CVPR
Wu, J., Le, T., Hayat, M., Harandi, M.: Erasing undesirable influence in diffusion models. In: CVPR. pp. 28263–28273 (2025)
2025
-
[44]
In: AAAI
Wu, Y., Zhou, S., Yang, M., Wang, L., Chang, H., Zhu, W., Hu, X., Zhou, X., Yang, X.: Unlearning concepts in diffusion model via concept domain correction and concept preserving gradient. In: AAAI. pp. 8496–8504 (2025)
2025
-
[45]
Xiao, G., Yin, T., Freeman, W.T., Durand, F., Han, S.: Fastcomposer: Tuning- free multi-subject image generation with localized attention. Int. J. Comput. Vis. 133(3), 1175–1194 (2024)
2024
-
[46]
In: ICML
Yang, J., Wang, Y., Fang, Y., Dai, Y., Huang, F.: Variance as a catalyst: Effi- cient and transferable semantic erasure adversarial attack for customized diffusion models. In: ICML. vol. 267 (2025)
2025
-
[47]
In: CVPR
Zeng, J., Song, D., Nie, W., Tian, H., Wang, T., Liu, A.: CAT-DM: controllable accelerated virtual try-on with diffusion model. In: CVPR. pp. 8372–8382 (2024)
2024
-
[48]
In: CVPRW
Zhang, G., Wang, K., Xu, X., Wang, Z., Shi, H.: Forget-me-not: Learning to forget in text-to-image diffusion models. In: CVPRW. pp. 1755–1764 (2024)
2024
-
[49]
In: NeurIPS
Zhang, Y., Chen, X., Jia, J., Zhang, Y., Fan, C., Liu, J., Hong, M., Ding, K., Liu, S.: Defensive unlearning with adversarial training for robust concept erasure in diffusion models. In: NeurIPS. vol. 37, pp. 36748–36776 (2024)
2024
-
[50]
In: CVPR
Zhong, Z., Bao, W., Wang, J., Zhang, S., Zhou, J., Lyu, L., Lim, W.Y.B.: Unlearn- ing through knowledge overwriting: Reversible federated unlearning via selective sparse adapter. In: CVPR. pp. 30661–30670 (2025)
2025
-
[51]
In: CVPR
Zhou, Y., Zheng, D., Mo, Q., Lu, R., Lin, K.Y., Zheng, W.S.: Decoupled distillation to erase: A general unlearning method for any class-centric tasks. In: CVPR. pp. 20350–20359 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.