3DTMDet: A Dual-Path Synergy Network of Transformer and SSM for 3D Object Detection in Point Clouds
Pith reviewed 2026-05-19 14:15 UTC · model grok-4.3
pith:KAT6LIHW Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{KAT6LIHW}
Prints a linked pith:KAT6LIHW badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A hybrid Transformer and state space model network better detects objects in sparse distant point clouds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
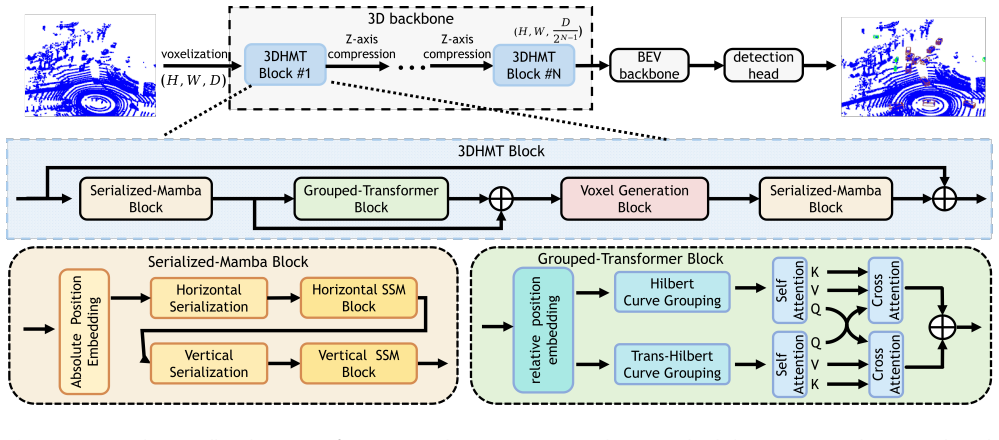
By integrating state space models with Transformers through an SSM-Attention-SSM pipeline in the 3D Hybrid Mamba Transformer block and adding a physics-inspired voxel generation block, the network achieves superior 3D object detection by maintaining local geometric information while capturing global context in sparse point clouds.
What carries the argument
The 3D Hybrid Mamba Transformer block that applies state space model, attention, and state space model in sequence to balance global and local feature processing.
If this is right
- Improved accuracy in detecting small and distant objects due to preserved local details.
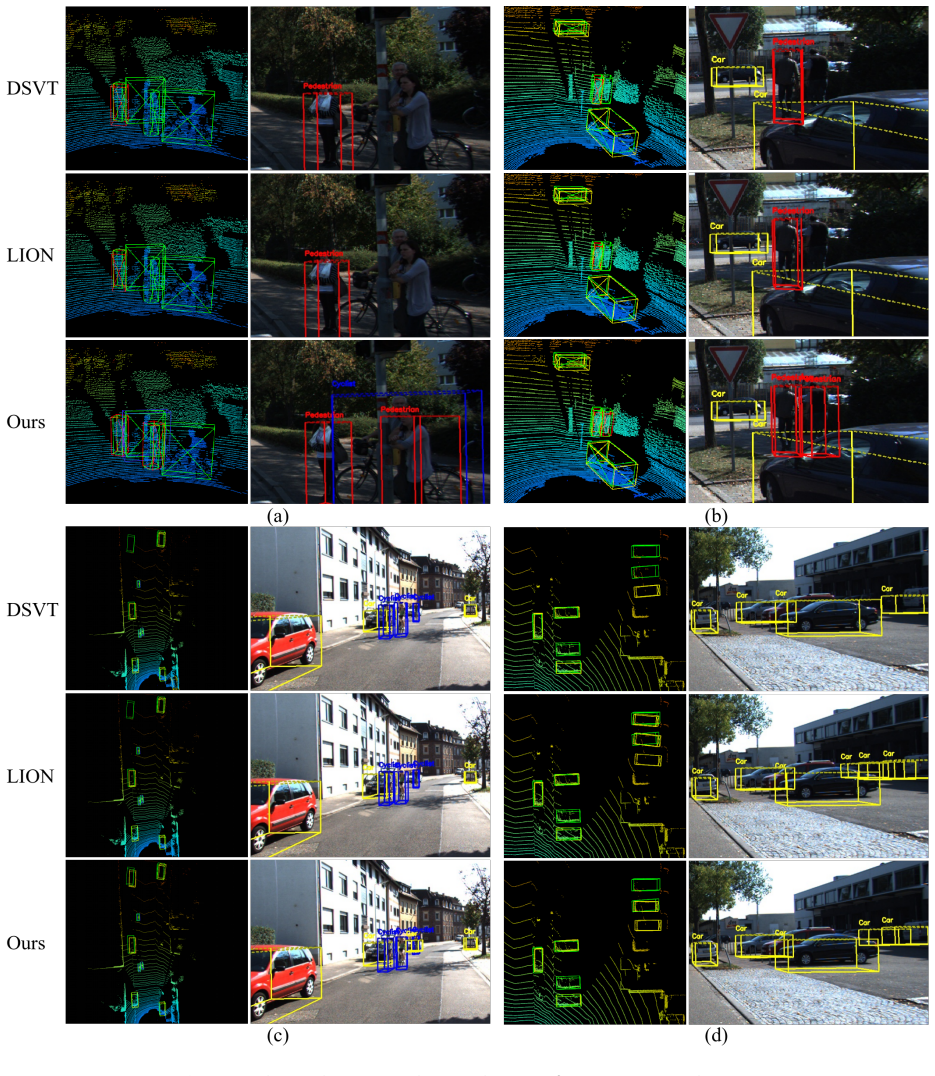
- Outperformance of existing detectors on the KITTI and ONCE benchmarks.
- Effective handling of occlusions through feature diffusion along observation directions.
- Linear complexity global modeling that scales better than pure attention mechanisms for large point sets.
Where Pith is reading between the lines
- This suggests hybrid architectures may be useful for other tasks with sparse 3D data such as scene reconstruction.
- Testing the method on additional datasets or real-world LiDAR streams could validate broader applicability.
- The approach opens questions about optimal ordering in SSM-attention hybrids for different data densities.
Load-bearing premise
The SSM-Attention-SSM pipeline balances global context understanding with preservation of fine-grained local geometric structures in sparse distant point sets.
What would settle it
Demonstrating no improvement in distant object detection precision on the ONCE dataset relative to prior methods would contradict the effectiveness of the proposed synergy.
Figures






read the original abstract
A fundamental challenge in point cloud object detection lies in the conflict between the extreme sparsity of distant points and the need for remote context understanding. The existing methods typically use 1D serialization to expand the receptive field, which inevitably discards already scarce local geometric details and reduces detection of distant and small objects. To address this issue, we propose 3DTMDet, a novel detection network that synergistically combines state space models (Mamba) with Transformers. The core idea is to utilize SSM's linear complexity and advantages in long sequence modeling to effectively capture global interactions between sparse and distant points, while using Transformer modules with local attention to encode fine-grained geometric structures in local point sets, preserving accurate shape information. We propose the 3D Hybrid Mamba Transformer (3DHMT) block, which uses an SSM-Attention-SSM pipeline to balance global context understanding and local detail preservation, effectively alleviating the tension between receptive field enlargement and geometric preservation in remote detection. In addition, we introduced a voxel generation block inspired by LiDAR physics, which diffuses features along the sensor observation direction to reconstruct the complete object structure of occlusion and distant areas. Extensive experiments conducted on the KITTI and ONCE datasets have shown that 3DTMDet outperforms state-of-the-art detectors. The code is available at https://github.com/QiuBingwen/3DTMDet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes 3DTMDet, a dual-path synergy network combining Transformers and state space models (Mamba/SSM) for 3D object detection in point clouds. It introduces the 3D Hybrid Mamba Transformer (3DHMT) block with an SSM-Attention-SSM pipeline to capture global context among sparse distant points while preserving local geometric details via attention, along with a voxel generation block that diffuses features along the LiDAR observation direction to reconstruct occluded or distant structures. The central claim is that this architecture outperforms state-of-the-art detectors on the KITTI and ONCE datasets.
Significance. If the empirical gains are shown to be robust and isolated to the proposed components, the work could meaningfully advance point-cloud detection by mitigating the receptive-field versus local-detail trade-off that limits performance on small and far objects. The hybrid SSM-Transformer design leverages Mamba's linear scaling for long-range modeling in a domain where quadratic attention is costly, and the physics-inspired voxel block offers a targeted way to handle sparsity.
major comments (3)
- [§4 Experiments] §4 (Experiments): The abstract states that 'extensive experiments... have shown that 3DTMDet outperforms state-of-the-art detectors' on KITTI and ONCE, yet no quantitative mAP values, baseline comparisons, error bars, or ablation tables are referenced in the provided description. Without explicit numbers and controls, the headline claim cannot be evaluated and remains load-bearing for the paper's contribution.
- [§3.2 3DHMT block] §3.2 (3DHMT block description): The claim that the SSM-Attention-SSM pipeline 'effectively balance[s] global context understanding and local detail preservation' is presented as the solution to the sparsity-receptive-field tension, but no ablation isolating the attention module versus pure SSM or pure Transformer variants is described. This leaves the central architectural assumption untested and risks confounding the reported gains with other factors.
- [§4 Experiments] §4 (Training protocol): No statement is given that all compared baselines were re-implemented and re-trained under identical optimizer, augmentation, and voxelization settings using the authors' codebase. In point-cloud detection, protocol mismatches routinely produce 1-3% mAP differences; without this control the attribution of gains to the 3DHMT block or voxel generation remains ambiguous.
minor comments (2)
- [Abstract] Abstract: The phrase 'diffuses features along the sensor observation direction' is introduced without a supporting equation or diagram reference, making the voxel generation block's mechanics hard to reconstruct from text alone.
- [§3 Method] Notation: The paper introduces '3D Hybrid Mamba Transformer (3DHMT) block' and 'voxel generation block' as new entities; a short table summarizing their input/output tensors and complexity would improve clarity.
Simulated Author's Rebuttal
We are grateful to the referee for the thoughtful and constructive feedback on our manuscript. We have carefully considered each comment and provide detailed responses below. Where appropriate, we have revised the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [§4 Experiments] §4 (Experiments): The abstract states that 'extensive experiments... have shown that 3DTMDet outperforms state-of-the-art detectors' on KITTI and ONCE, yet no quantitative mAP values, baseline comparisons, error bars, or ablation tables are referenced in the provided description. Without explicit numbers and controls, the headline claim cannot be evaluated and remains load-bearing for the paper's contribution.
Authors: We appreciate this observation. The abstract is intended as a concise summary and typically does not include detailed numerical results to maintain readability. However, the full manuscript in Section 4 provides extensive quantitative evaluations, including mAP values on both KITTI and ONCE datasets, comparisons with state-of-the-art methods, and ablation studies. To strengthen the abstract, we will revise it to include key performance highlights, such as the mAP improvements achieved. Additionally, we will ensure that all experimental results are clearly cross-referenced in the text. revision: yes
-
Referee: [§3.2 3DHMT block] §3.2 (3DHMT block description): The claim that the SSM-Attention-SSM pipeline 'effectively balance[s] global context understanding and local detail preservation' is presented as the solution to the sparsity-receptive-field tension, but no ablation isolating the attention module versus pure SSM or pure Transformer variants is described. This leaves the central architectural assumption untested and risks confounding the reported gains with other factors.
Authors: We thank the referee for highlighting the need for more targeted ablations. In the original manuscript, we included ablations on the overall 3DHMT block and its components. To directly address this, we will add a new ablation study that compares the full hybrid SSM-Attention-SSM pipeline against pure SSM and pure Transformer variants within the same framework. This will help isolate the contribution of the attention module in balancing global and local features. The revised manuscript will include this analysis in Section 4. revision: yes
-
Referee: [§4 Experiments] §4 (Training protocol): No statement is given that all compared baselines were re-implemented and re-trained under identical optimizer, augmentation, and voxelization settings using the authors' codebase. In point-cloud detection, protocol mismatches routinely produce 1-3% mAP differences; without this control the attribution of gains to the 3DHMT block or voxel generation remains ambiguous.
Authors: We agree that ensuring identical training protocols is crucial for fair comparisons. All baselines were indeed re-implemented and re-trained using the same settings in our codebase, including optimizer, data augmentation, and voxelization parameters. We will add an explicit statement in Section 4 (Experiments) detailing the training protocol and confirming that all methods were evaluated under identical conditions to eliminate any ambiguity in attributing performance gains. revision: yes
Circularity Check
No circularity: empirical architecture proposal validated on external benchmarks
full rationale
The paper introduces 3DTMDet as a novel network design combining SSM (Mamba) and Transformer modules in a 3DHMT block plus a physics-inspired voxel generation block. All load-bearing claims rest on experimental outperformance on the public KITTI and ONCE datasets rather than any closed-form derivation, uniqueness theorem, or parameter fit that is then re-labeled as a prediction. No equations are presented that reduce by construction to the inputs; the SSM-Attention-SSM pipeline is motivated by stated desiderata (global context vs. local geometry) and evaluated empirically. Self-citations, if present, are not load-bearing for the central result. The work is therefore self-contained against external benchmarks with no detectable circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- network hyperparameters and training settings
axioms (2)
- domain assumption State space models provide linear-complexity long-sequence modeling suitable for global point interactions
- domain assumption Local Transformer attention preserves geometric details better than serialization
invented entities (2)
-
3D Hybrid Mamba Transformer (3DHMT) block
no independent evidence
-
voxel generation block
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on deep-learning-based lidar 3d object detection for autonomous driving
Alaba, S.Y., Ball, J.E., 2022. A survey on deep-learning-based lidar 3d object detection for autonomous driving. Sensors (Basel, Switzerland) 22. URL:https://api.semanticscholar.org/CorpusID: 254429128
work page 2022
-
[2]
Ao, L., Wan, W., Ouyang, N., Li, J., Li, Q., Gong, M., Sheng, K., 2026.Svp:stratifiedverticalpriorsforlidar-based3dobjectdetection. Neurocomputing 659, 131737. URL:https://www.sciencedirect. com/science/article/pii/S0925231225024099,doi:https://doi.org/10. 1016/j.neucom.2025.131737
-
[3]
Dstr: Dual scenes transformer for cross-modal fusion in 3d object detection
Cai, H., Yin, D., Yu, F.R., Xiong, S., 2025. Dstr: Dual scenes transformer for cross-modal fusion in 3d object detection. 2025 IEEE/CVF Winter Conference on Applications of Computer Vi- sion (WACV) , 3064–3073URL:https://api.semanticscholar.org/ CorpusID:277218349
work page 2025
-
[4]
Kptr:Key point transformer for lidar-based 3d object detection
Cao,J.,Peng,Y.,Wei,H.,Mo,L.,Fan,L.,Wang,L.,2025. Kptr:Key point transformer for lidar-based 3d object detection. Measurement 242,115820. URL:https://www.sciencedirect.com/science/article/ pii/S0263224124017056, doi:https://doi.org/10.1016/j.measurement. 2024.115820
-
[5]
Eb-lg module for 3d point cloud classification and segmentation
Chen, J., Zhang, Y., Ma, F., Tan, Z., 2023. Eb-lg module for 3d point cloud classification and segmentation. IEEE Robotics and AutomationLetters8,160–167. URL:https://api.semanticscholar. org/CorpusID:253791066
work page 2023
-
[7]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A., Dao, T., 2023. Mamba: Linear-time sequence modeling with selective state spaces. ArXiv abs/2312.00752. URL:https: //api.semanticscholar.org/CorpusID:265551773
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
M3detr: Multi-representation, multi-scale, mutual-relation 3d object detection with transformers
Guan, T., Wang, J., Lan, S., Chandra, R., Wu, Z., Davis, L.S., Manocha, D., 2021. M3detr: Multi-representation, multi-scale, mutual-relation 3d object detection with transformers. 2022 IEEE/CVF Winter Conference on Applications of Computer Vi- sion (WACV) , 2293–2303URL:https://api.semanticscholar.org/ CorpusID:233394223
work page 2021
-
[9]
Mambatron: Efficient cross- modalpointcloudenhancementusingaggregateselectivestatespace modeling
Inaganti, S.T., Petrenko, G., 2025. Mambatron: Efficient cross- modalpointcloudenhancementusingaggregateselectivestatespace modeling. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW) , 180–190URL:https:// api.semanticscholar.org/CorpusID:275932593
work page 2025
-
[10]
Jung, K.S., Lee, D.K., 2025. Analysis of object detection accu- racy based on the density of 3d point clouds for deep learning- based shipyard datasets. International Journal of Naval Architec- tureandOceanEngineeringURL:https://api.semanticscholar.org/ CorpusID:276457968
work page 2025
-
[11]
Pointpillars: Fast encoders for object detection from point clouds
Lang, A.H., Vora, S., Caesar, H., Zhou, L., Yang, J., Beijbom, O., 2018. Pointpillars: Fast encoders for object detection from point clouds. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 12689–12697URL:https://api. semanticscholar.org/CorpusID:55701967
work page 2018
-
[12]
Li, M., Yuan, J., Chen, S., Zhang, L., Zhu, A., Chen, X., Chen, T.,
-
[13]
(Eds.), Advances in Neural InformationProcessingSystems,CurranAssociates,Inc..pp.47242– 47260
3det-mamba: Causal sequence modelling for end-to-end 3d object detection, in: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (Eds.), Advances in Neural InformationProcessingSystems,CurranAssociates,Inc..pp.47242– 47260. URL:https://proceedings.neurips.cc/paper_files/paper/ 2024/file/547108084f0c2af39b956f8eadb75d1b-Pa...
-
[14]
Pdm-ssd: Single-stage 3d object detector with point dilation mecha- nism
Liang, A., Hua, H., Fang, J., Chen, W., Zhao, H., Wang, G., 2024a. Pdm-ssd: Single-stage 3d object detector with point dilation mecha- nism. ArXiv abs/2406.00714. doi:10.2139/ssrn.4687799
-
[15]
Liang, A., Hua, H., Fang, J., Zhao, H., Liu, T., 2024b. Boosting 3d point-based object detection by reducing information loss caused by discontinuous receptive fields. Int. J. Appl. Earth Obs. Geoinforma- tion 132, 104049. URL:https://api.semanticscholar.org/CorpusID: 271730018
-
[16]
Pointmamba:Asimplestatespacemodelforpointcloudanal- ysis
Liang,D.,Zhou,X.,Xu,W.,Zhu,X.,Zou,Z.,Ye,X.,Tan,X.,Bai,X., 2024c. Pointmamba:Asimplestatespacemodelforpointcloudanal- ysis. ArXiv abs/2402.10739. URL:https://api.semanticscholar. org/CorpusID:267740688
-
[17]
Hypermamba: A spectral-spatial adaptive mamba for hyperspectral image classifi- cation
Liu, Q., Yue, J., Fang, Y., Xia, S., Fang, L., 2024a. Hypermamba: A spectral-spatial adaptive mamba for hyperspectral image classifi- cation. IEEE Transactions on Geoscience and Remote Sensing 62, 1–14. doi:10.1109/TGRS.2024.3482473
-
[18]
A unified voxel diffusion module for point cloud 3d object detection
Liu, Q., Zhao, D., Dong, Y., Shang, L., Xiao, L., Wang, J., Zhao, K., Lu, D., Zhu, Q., 2025a. A unified voxel diffusion module for point cloud 3d object detection. ArXiv abs/2508.16069. URL: https://api.semanticscholar.org/CorpusID:280708543
-
[19]
Hyperspectral image super-resolution based on mamba and bidirec- tionalfeaturefusionnetwork
Liu, T., Pu, X., Shi, Y., Liu, Y., Chen, G., Sui, X., Chen, Q., 2025b. Hyperspectral image super-resolution based on mamba and bidirec- tionalfeaturefusionnetwork. ExpertSystemswithApplications285, 127905. URL:https://www.sciencedirect.com/science/article/pii/ S0957417425015271, doi:https://doi.org/10.1016/j.eswa.2025.127905
-
[20]
Lion:Lineargrouprnnfor3dobjectdetectioninpointclouds
Liu,Z.,Hou,J.,Wang,X.,Ye,X.,Wang,J.,Zhao,H.,Bai,X.,2024b. Lion:Lineargrouprnnfor3dobjectdetectioninpointclouds. ArXiv abs/2407.18232. URL:https://api.semanticscholar.org/CorpusID: 271431965
-
[21]
Group-free 3d object detection via transformers
Liu, Z., Zhang, Z., Cao, Y., Hu, H., Tong, X., 2021. Group-free 3d object detection via transformers. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) , 2929–2938URL:https: //api.semanticscholar.org/CorpusID:232478413
work page 2021
-
[22]
Exploring token serialization for mamba-based lidar point cloud segmentation
Lu, D., Gao, K., Li, J., Zhang, D., Xu, L., 2025. Exploring token serialization for mamba-based lidar point cloud segmentation. IEEE Transactions on Geoscience and Remote Sensing 63, 1–14. URL: https://api.semanticscholar.org/CorpusID:281127906
work page 2025
-
[23]
Mao,J.,Xue,Y.,Niu,M.,Bai,H.,Feng,J.,Liang,X.,Xu,H.,Xu,C.,
-
[24]
Voxel transformer for 3d object detection. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) , 3144– 3153URL:https://api.semanticscholar.org/CorpusID:237421262
work page 2021
-
[25]
Mambafusion: State- space model-driven object-scene fusion for multi-modal 3d object detection
Ning, T., Lu, K., Jiang, X., Xue, J., 2025. Mambafusion: State- space model-driven object-scene fusion for multi-modal 3d object detection. Pattern Recognition URL:https://api.semanticscholar. org/CorpusID:283485417
work page 2025
-
[26]
Ensemble deep learning-enabled single-shot composite structured illumination mi- croscopy (edl-csim)
Qian, J., Wang, C., Wu, H., Chen, Q., Zuo, C., 2024. Ensemble deep learning-enabled single-shot composite structured illumination mi- croscopy (edl-csim). PhotoniX 1 1. doi:10.1186/s43074-024-00139-2
-
[27]
Center- point transformer for bev object detection with automotive radar
Saini, L., Su, Y., Tercan, H., Meisen, T., 2024. Center- point transformer for bev object detection with automotive radar. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , 4451–4460URL:https://api. semanticscholar.org/CorpusID:272915648
work page 2024
-
[28]
Pv-rcnn: Point-voxel feature set abstraction for 3d object detection
Shi, S., Guo, C., Jiang, L., Wang, Z., Shi, J., Wang, X., Li, H., 2019. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. 2020IEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR) , 10526–10535URL:https://api.semanticscholar. org/CorpusID:209516193
work page 2019
-
[29]
Pointrcnn:3dobjectproposalgenera- tion and detection from point cloud
Shi,S.,Wang,X.,Li,H.,2018. Pointrcnn:3dobjectproposalgenera- tion and detection from point cloud. 2019 IEEE/CVF Conference on Page 10 of 11 Computer Vision and Pattern Recognition (CVPR) , 770–779URL: https://api.semanticscholar.org/CorpusID:54607410
work page 2018
-
[30]
Team, O.D., 2020. Openpcdet: An open-source toolbox for 3d object detection from point clouds.https://github.com/open-mmlab/ OpenPCDet
work page 2020
-
[31]
Tian, Y., Bai, S., Luo, Z., Wang, Y., Lv, Y., Wang, F.Y., 2024. Mam- baocc: Visual state space model for bev-based occupancy prediction with local adaptive reordering. ArXiv abs/2408.11464. URL:https: //api.semanticscholar.org/CorpusID:271916087
-
[32]
Pointpainting: Sequential fusion for 3d object detection
Vora, S., Lang, A.H., Helou, B., Beijbom, O., 2019. Pointpainting: Sequential fusion for 3d object detection. 2020 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) , 4603– 4611URL:https://api.semanticscholar.org/CorpusID:208248084
work page 2019
-
[33]
Wan, R., Meng, W., Zhao, T., Lu, W., 2026. Bridging cross- modal sparsity via adaptive pillar propagation and hierarchical multi-granularity feature distillation for 3d object detection. Neu- rocomputing 665, 132195. URL:https://www.sciencedirect. com/science/article/pii/S092523122502867X,doi:https://doi.org/10. 1016/j.neucom.2025.132195
-
[34]
Dsvt: Dynamic sparse voxel transformer with rotated sets
Wang, H., Shi, C., Shi, S., Lei, M., Wang, S., He, D., Schiele, B., Wang, L., 2023a. Dsvt: Dynamic sparse voxel transformer with rotated sets. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 13520–13529URL:https://api. semanticscholar.org/CorpusID:255942736
work page 2023
-
[35]
Wang, X., Chen, X., Han, J., Zhang, Y., Zheng, D., 2023b. Local-to- global structure prior guided high-precision point cloud registration framework based on fpp. Measurement 214, 112840. URL:https: //www.sciencedirect.com/science/article/pii/S0263224123004049, doi:https://doi.org/10.1016/j.measurement.2023.112840
-
[36]
Hybrid transformer- mambamodelfor3dsemanticsegmentation
Wang, X., Hou, J., Liu, Z., Zhu, Y., 2025. Hybrid transformer- mambamodelfor3dsemanticsegmentation. 2025IEEE/RSJInterna- tional Conference on Intelligent Robots and Systems (IROS) , 2217– 2223URL:https://api.semanticscholar.org/CorpusID:280018036
work page 2025
-
[37]
Pointramba: A hybrid transformer-mamba framework for point cloud analysis
Wang, Z., Chen, Z., Wu, Y., Zhao, Z., Zhou, L., Xu, D., 2024. Pointramba: A hybrid transformer-mamba framework for point cloud analysis. ArXiv abs/2405.15463. URL:https://api. semanticscholar.org/CorpusID:270045264
-
[38]
Wu, D., Yang, F., Xu, B., Liao, P., Liu, B., 2024. A survey of deep learning based radar and vision fusion for 3d object detection in autonomous driving. ArXiv abs/2406.00714. URL:https://api. semanticscholar.org/CorpusID:270217797
-
[39]
Xie, Z., Zhao, Y., Zhang, F., Luo, B., Hu, W., Qiu, T., 2025. Mine-ssd: Dual-threshold set abstraction and radius-adaptive group- ing for 3d object detection in open-pit mines. Neurocomputing 657,131507. URL:https://www.sciencedirect.com/science/article/ pii/S0925231225021794, doi:https://doi.org/10.1016/j.neucom.2025. 131507
-
[40]
Second: Sparsely embedded convo- lutional detection
Yan, Y., Mao, Y., Li, B., 2018. Second: Sparsely embedded convo- lutional detection. Sensors (Basel, Switzerland) 18. URL:https: //api.semanticscholar.org/CorpusID:52957856
work page 2018
-
[41]
Yang, Z., Sun, Y., Liu, S., Jia, J., 2020. 3dssd: Point-based 3d single stage object detector, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11037–11045. doi:10. 1109/CVPR42600.2020.01105
-
[42]
Voxel mamba: Group-free state space models for point cloud based 3d object detection
Zhang, G., Fan, L., He, C., Lei, Z., Zhang, Z., Zhang, L., 2024. Voxel mamba: Group-free state space models for point cloud based 3d object detection. ArXiv abs/2406.10700. URL:https://api. semanticscholar.org/CorpusID:270559452
-
[43]
Zhang, G., Ji, X., Qiu, B., Cai, Y., Liu, Y., Sui, X., Chen, Q., 2025a. Sfnet: A dual-enhanced rgbt tracker via global-local modality refine- ment and frequency-spatial cross-modal fusion. Optics and Lasers in Engineering 194, 109201. URL:https://www.sciencedirect. com/science/article/pii/S0143816625003860,doi:https://doi.org/10. 1016/j.optlaseng.2025.109201
-
[44]
As- cformer: An adaptive strucure-aware cascaded transformer for 3d object detection
Zhang, X., Li, X., Zhou, M., Gan, M., Chen, C.L.P., 2025b. As- cformer: An adaptive strucure-aware cascaded transformer for 3d object detection. IEEE Transactions on Circuits and Systems for VideoTechnologyURL:https://api.semanticscholar.org/CorpusID: 281498966
-
[45]
Enhanc- ing point cloud feature utilization for 3d object detection
Zhou, G., Jiang, F., Dong, R., Wang, M., Xu, P., 2025. Enhanc- ing point cloud feature utilization for 3d object detection. IEEE Signal Processing Letters 32, 4254–4258. URL:https://api. semanticscholar.org/CorpusID:282634331. Page 11 of 11
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.