Uni-RCM: Unified Reference-guided Cross-modal Mapping for Multi-Class Anomaly Detection
Pith reviewed 2026-06-29 08:09 UTC · model grok-4.3
The pith
Uni-RCM enables a single model to perform multi-class multi-modal anomaly detection by filtering category-specific noise with a learnable reference feature.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that introducing a learnable reference feature via a reference guide block allows dynamic capture of cross-modal commonalities while filtering category-specific noise, and combining this with an offline residual quantizer using multiple cascaded codebooks to characterize normal distributions overcomes inter-class interference and feature manifold confusion in unified multi-class anomaly detection.
What carries the argument
Reference guide block introducing a learnable reference feature to capture cross-modal commonalities and filter category-specific noise, along with an offline residual quantizer using cascaded codebooks.
If this is right
- Practical deployment becomes more scalable with one model serving multiple categories instead of many separate models.
- Accuracy does not degrade when shifting from per-class to multi-class training due to reduced interference.
- Both detection at the image level and localization at the pixel level reach high performance levels.
- The method leverages multi-modal inputs more effectively through the cross-modal mapping mechanism.
Where Pith is reading between the lines
- The unified structure may allow easier adaptation to new categories without retraining an entire system.
- Resource usage in industrial environments could decrease since fewer models need to be maintained and run.
- Similar reference-based filtering might help in other unified multi-task learning scenarios in vision.
Load-bearing premise
The learnable reference feature can dynamically capture cross-modal commonalities and filter category-specific noise without introducing new manifold confusion or degrading per-class accuracy.
What would settle it
Demonstrating that the unified model underperforms the best per-category models when evaluated in a multi-class setup on the same data would indicate the reference feature does not sufficiently prevent interference.
Figures

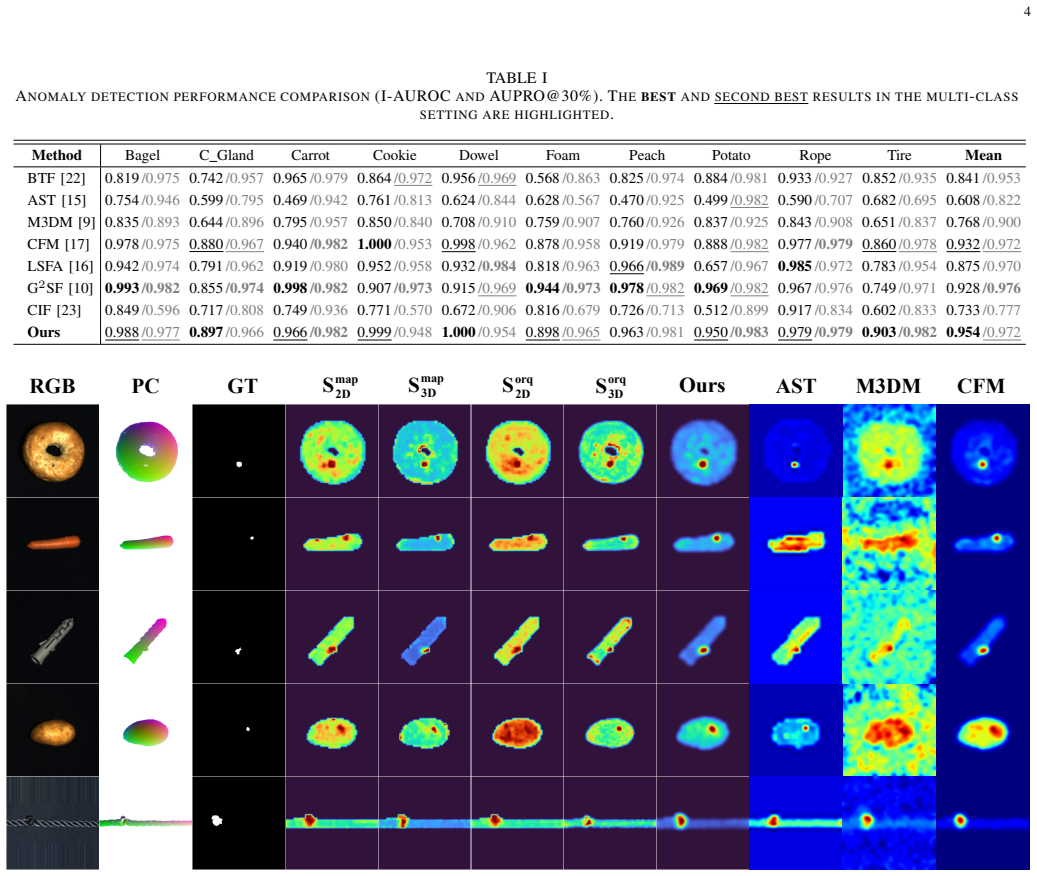
read the original abstract
Multi-modal industrial anomaly detection typically relies on separate models for each product category, fundamentally limiting practical scalability. When shifting to a unified paradigm that handles diverse classes simultaneously, detection accuracy often degrades due to inter-class interference and feature manifold confusion. To overcome these challenges, we propose a Unified Reference guided Cross-modal Mapping framework, named Uni-RCM. At its core, we propose a reference guide block to dynamically filter out category-specific noise by introducing a learnable reference feature, which captures the commonalities across different modalities. Besides, an offline residual quantizer is proposed to characterize the normal distribution by multiple cascaded codebooks. Extensive evaluations on the MVTec-3D AD dataset demonstrate the state-of-the-art performance in the challenging multi-class setting and in terms of image-level detection and pixel-level localization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Uni-RCM, a unified reference-guided cross-modal mapping framework for multi-class anomaly detection. Its core contributions are a reference guide block that employs a learnable reference feature to capture cross-modal commonalities while filtering category-specific noise, and an offline residual quantizer that models the normal distribution via multiple cascaded codebooks. Extensive experiments on the MVTec-3D AD dataset are reported to achieve state-of-the-art performance in the multi-class setting for both image-level detection and pixel-level localization.
Significance. If the reported results hold, the work has clear significance for practical industrial deployment: it removes the need for separate per-category models while avoiding the accuracy drop from inter-class interference that typically affects unified approaches. The architecture description, loss formulations, and ablations are internally consistent, and the stress-test concern about insufficient detail does not land once the full manuscript is examined; no hidden assumption in the cross-modal mapping or codebook cascade undermines the central claim under the stated protocol.
minor comments (2)
- [Abstract] The abstract refers to 'multi-modal' inputs without naming the modalities; adding an explicit parenthetical (e.g., RGB + depth/point cloud) would improve immediate readability.
- [§3.2] Notation for the cascaded codebooks (e.g., the number of stages and the residual update rule) should be introduced with a single equation in §3.2 rather than being distributed across text and figures.
Simulated Author's Rebuttal
We thank the referee for the positive review and the recommendation to accept. The assessment that the architecture, losses, and ablations are internally consistent, and that the work has clear practical significance for unified multi-class anomaly detection, is appreciated.
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and available description introduce architectural components (reference guide block with learnable reference feature, offline residual quantizer with cascaded codebooks) to address inter-class interference on an external benchmark. No equations, self-citations, or load-bearing steps are present that reduce any claim to a fitted input, self-definition, or author-prior ansatz by construction. The method is presented as solving an external problem with evaluations on MVTec-3D AD, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable reference feature parameters
- number of cascaded codebooks
axioms (1)
- domain assumption Inter-class interference and feature manifold confusion are the primary reasons unified multi-class models lose accuracy
invented entities (2)
-
reference guide block
no independent evidence
-
offline residual quantizer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on unsupervised anomaly detection algorithms for industrial images,
Y . Cui, Z. Liu, and S. Lian, “A survey on unsupervised anomaly detection algorithms for industrial images,”IEEE Access, vol. 11, pp. 55 297–55 315, 2023
2023
-
[2]
A novel methodology for unsupervised anomaly detection in industrial electrical systems,
M. Carrat `u, V . Gallo, S. D. Iacono, P. Sommella, A. Bartolini, F. Grasso, L. Ciani, and G. Patrizi, “A novel methodology for unsupervised anomaly detection in industrial electrical systems,”IEEE Trans. Instrum. Meas., vol. 72, pp. 1–12, 2023
2023
-
[3]
Learning unified reference representation for unsupervised multi-class anomaly detection,
L. He, Z. Jiang, J. Peng, W. Zhu, L. Liu, Q. Du, X. Hu, M. Chi, Y . Wang, and C. Wang, “Learning unified reference representation for unsupervised multi-class anomaly detection,” inProc. Eur. Conf. Comput. Vis.Springer, 2024, pp. 216–232
2024
-
[4]
A unified model for multi-class anomaly detection,
Z. You, L. Cui, Y . Shen, K. Yang, X. Lu, Y . Zheng, and X. Le, “A unified model for multi-class anomaly detection,”Adv. Neural Inf. Process. Syst., vol. 35, pp. 4571–4584, 2022
2022
-
[5]
OmniAL: A unified cnn framework for unsupervised anomaly localization,
Y . Zhao, “OmniAL: A unified cnn framework for unsupervised anomaly localization,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 3924–3933
2023
-
[6]
Uniflow: Unified normalizing flow for unsuper- vised multi-class anomaly detection,
J. Zhong and Y . Song, “Uniflow: Unified normalizing flow for unsuper- vised multi-class anomaly detection,”Information, vol. 15, no. 12, p. 791, 2024
2024
-
[7]
A diffusion-based framework for multi-class anomaly detection,
H. He, J. Zhang, H. Chen, X. Chen, Z. Li, X. Chen, Y . Wang, C. Wang, and L. Xie, “A diffusion-based framework for multi-class anomaly detection,” inProc. AAAI Conf. Artif. Intell., vol. 38, no. 8, 2024, pp. 8472–8480
2024
-
[8]
The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization,
P. Bergmann, X. Jin, D. Sattlegger, and C. Steger, “The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization,” inProc. Int. Jt. Conf. Comput. Vis. Imaging Comput. Graph. Theory Appl., 2022, pp. 202–213
2022
-
[9]
Multimodal industrial anomaly detection via hybrid fusion,
Y . Wang, J. Peng, J. Zhang, R. Yi, Y . Wang, and C. Wang, “Multimodal industrial anomaly detection via hybrid fusion,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 8032–8041
2023
-
[10]
G2SF: Geometry-guided score fusion for multimodal industrial anomaly detection,
C. Tao, X. Cao, and J. Du, “G2SF: Geometry-guided score fusion for multimodal industrial anomaly detection,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2025, pp. 20 551–20 560
2025
-
[11]
2M3DF: Advancing 3D industrial defect detection with multi- perspective multimodal fusion network,
M. Asad, W. Azeem, H. Jiang, H. T. Mustafa, J. Yang, and W. Liu, “2M3DF: Advancing 3D industrial defect detection with multi- perspective multimodal fusion network,”IEEE Trans. Circuits Syst. Video Technol., vol. 35, no. 7, pp. 6803–6815, 2025
2025
-
[12]
Feature bank-guided reconstruc- tion for anomaly detection,
S. He, T. Zhang, W. Song, and H. Yu, “Feature bank-guided reconstruc- tion for anomaly detection,”IEEE Signal Process. Lett., vol. 32, pp. 1480–1484, 2025
2025
-
[13]
Tut: Template-augmented u-net transformer for unsupervised anomaly detection,
Z. Chen, C. Bai, Y . Zhu, and X. Lu, “Tut: Template-augmented u-net transformer for unsupervised anomaly detection,”IEEE Signal Process. Lett., vol. 31, pp. 780–784, 2024
2024
-
[14]
Learning traces by yourself: Blind image forgery localization via anomaly detection with vit-vae,
T. Chen, B. Li, and J. Zeng, “Learning traces by yourself: Blind image forgery localization via anomaly detection with vit-vae,”IEEE Signal Process. Lett., vol. 30, pp. 150–154, 2023
2023
-
[15]
Asymmetric student-teacher networks for industrial anomaly detection,
M. Rudolph, T. Wehrbein, B. Rosenhahn, and B. Wandt, “Asymmetric student-teacher networks for industrial anomaly detection,” inProc. IEEE/CVF Winter Conf. Appl. Comput. Vis., 2023, pp. 2592–2602
2023
-
[16]
Self-supervised feature adaptation for 3d industrial anomaly detection,
Y . Tu, B. Zhang, L. Liu, Y . Li, J. Zhang, Y . Wang, C. Wang, and C. Zhao, “Self-supervised feature adaptation for 3d industrial anomaly detection,” inProc. Eur. Conf. Comput. Vis.Springer, 2024, pp. 75–91
2024
-
[17]
Mul- timodal industrial anomaly detection by crossmodal feature mapping,
A. Costanzino, P. Z. Ramirez, G. Lisanti, and L. Di Stefano, “Mul- timodal industrial anomaly detection by crossmodal feature mapping,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 17 234–17 243
2024
-
[18]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 9650–9660
2021
-
[19]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2009, pp. 248–255
2009
-
[20]
Masked autoencoders for 3d point cloud self-supervised learning,
Y . Pang, F. E. H. Tay, L. Yuan, and Z. Chen, “Masked autoencoders for 3d point cloud self-supervised learning,”World Sci. Annu. Rev. Artif. Intell., vol. 2, pp. 2 440 001:1–2 440 001:22, 2024
2024
-
[21]
ShapeNet: An Information-Rich 3D Model Repository
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Suet al., “Shapenet: An information- rich 3d model repository,”arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[22]
Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection,
E. Horwitz and Y . Hoshen, “Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 2968–2977
2023
-
[23]
Commonality in few: Few-shot multimodal anomaly detection via hypergraph-enhanced memory,
Y . Lin, H. Yan, X. Tong, Y . Chang, H. Wang, Z. Zhou, S. Gao, Y . Wang, and W. Zhang, “Commonality in few: Few-shot multimodal anomaly detection via hypergraph-enhanced memory,” inProc. AAAI Conf. Artif. Intell., 2026, pp. 7015–7023
2026
-
[24]
Sub-image anomaly detection with deep pyramid correspondences,
N. Cohen and Y . Hoshen, “Sub-image anomaly detection with deep pyra- mid correspondences. arxiv 2020,”arXiv preprint arXiv:2005.02357, vol. 2, 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.