Prompting Is All You Need: Multi-view Prompting Large Language Models for Aspect-Based Sentiment Analysis
Pith reviewed 2026-06-29 12:38 UTC · model grok-4.3
The pith
Multi-view prompting with constrained decoding lets LLMs match fine-tuned models on aspect-based sentiment analysis using few examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-MvP adapts the multi-view principle of considering multiple element orderings to LLM prompting for aspect-based sentiment analysis. By combining this with schema-constrained decoding via a context-free grammar and prefix batching, the method achieves performance competitive or superior to fine-tuned approaches on five benchmark datasets while substantially reducing computational overhead.
What carries the argument
LLM-MvP, which applies multi-view prompting (multiple orderings of aspects and opinions) together with schema-constrained decoding and prefix batching.
If this is right
- Few-shot LLM prompting can reach the accuracy level previously requiring hundreds of labeled examples for ABSA.
- Computational cost drops because prefix batching and constrained decoding avoid redundant token generation.
- The same combination of multi-view ordering and grammar constraints works across multiple standard ABSA benchmarks.
Where Pith is reading between the lines
- The method could extend to other structured NLP tasks such as named-entity recognition or relation extraction where output order matters.
- If the ordering principle reduces output variance, similar prompting patterns might stabilize LLM answers in low-data regimes beyond sentiment analysis.
- Prefix batching may combine with other decoding tricks to further lower latency in production settings.
Load-bearing premise
The multi-view principle of trying several element orderings carries over to LLM prompting without creating inconsistencies or forcing dataset-specific tuning that would erase the few-shot benefit.
What would settle it
A head-to-head test on a held-out dataset where LLM-MvP falls below fine-tuned baselines under identical prompting conditions would falsify the performance claim.
Figures

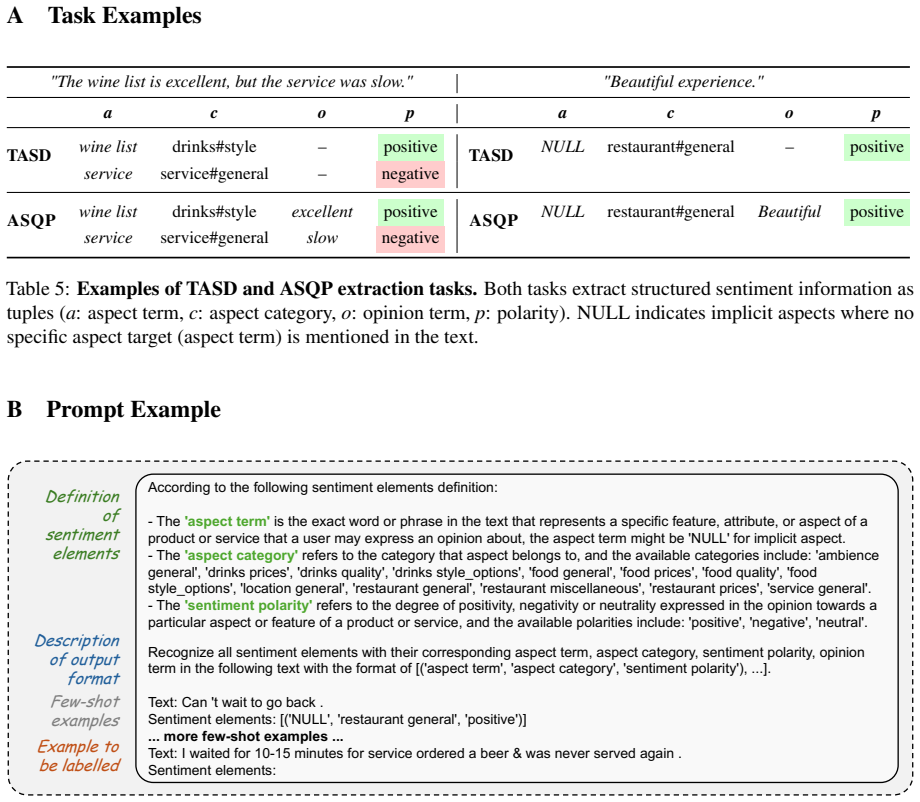

read the original abstract
Recent work explored the capabilities of Large Language Models (LLMs) in Aspect-Based Sentiment Analysis (ABSA) through few-shot prompting, requiring substantially fewer annotated examples while achieving notable improvements over zero-shot baselines. However, a performance gap remained compared to models fine-tuned on hundreds of examples, and the computational costs of LLM inference present practical barriers to deployment. We introduce LLM-based Multi-View Prompting (LLM-MvP), which adapts the multi-view principle of considering multiple element orderings to LLM prompting. By combining schema-constrained decoding with a context-free grammar and prefix batching, LLM-MvP achieves performance competitive or superior to fine-tuned approaches while substantially reducing computational overhead. Extensive experiments across five benchmark datasets demonstrate that LLM-MvP closes the gap between few-shot prompting and fine-tuned models, offering a practical and efficient solution for ABSA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LLM-MvP, an adaptation of multi-view prompting to LLMs for aspect-based sentiment analysis. It combines multi-view element orderings with schema-constrained decoding (via context-free grammar) and prefix batching, claiming this yields performance competitive or superior to fine-tuned models on five benchmarks while lowering inference costs compared to standard LLM prompting.
Significance. If the performance claims are substantiated with quantitative results, statistical tests, and error analysis, the work would be significant for demonstrating that prompting adaptations can close the gap to supervised ABSA models without parameter updates, while addressing computational barriers through constrained decoding and batching.
major comments (1)
- [Method (CFG and constrained decoding description)] Method section on schema-constrained decoding: the construction of the context-free grammar (non-terminals for aspects, polarities, and output schemas) must be shown to be derived uniformly from the task definition rather than hand-specified or tuned per dataset. If the latter, this introduces implicit supervision that undermines the central claim of few-shot generality and no dataset-specific tuning equivalent to fine-tuned baselines.
minor comments (2)
- [Abstract] Abstract and experimental claims: quantitative results, baseline details, statistical significance tests, and error analysis are referenced but not visible in the provided abstract; these must be explicitly summarized with numbers to support the 'competitive or superior' assertion.
- [Introduction or Method] The multi-view principle transfer from non-LLM models to LLM prompting should include a brief discussion of any new inconsistencies introduced by LLM tokenization or generation order.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the method section. We address the concern regarding the context-free grammar construction below and will revise the manuscript to provide the requested clarification.
read point-by-point responses
-
Referee: Method section on schema-constrained decoding: the construction of the context-free grammar (non-terminals for aspects, polarities, and output schemas) must be shown to be derived uniformly from the task definition rather than hand-specified or tuned per dataset. If the latter, this introduces implicit supervision that undermines the central claim of few-shot generality and no dataset-specific tuning equivalent to fine-tuned baselines.
Authors: We agree that explicit demonstration of uniform derivation is necessary. The CFG is constructed directly from the standard ABSA task definition without per-dataset tuning: non-terminals for aspects are defined as arbitrary token sequences drawn from the input sentence (no dataset-specific vocabulary), polarities are fixed to the universal set {positive, negative, neutral} used across all five benchmarks, and output schemas follow the canonical ABSA tuple/quadruple format (aspect, polarity) or (aspect, category, polarity) as defined in the task literature. No hand-crafted rules or dataset-specific adjustments are introduced. In the revision we will add a dedicated subsection with the full grammar specification, a derivation example, and confirmation that the same grammar applies unchanged to all datasets. revision: yes
Circularity Check
Empirical prompting technique with no derivation reducing to inputs by construction.
full rationale
The paper presents LLM-MvP as an empirical adaptation of multi-view prompting to LLMs via schema-constrained decoding, CFG, and prefix batching. No equations, fitted parameters, or mathematical derivations appear in the abstract or description. Claims rest on experimental results across benchmarks rather than any self-referential reduction. No load-bearing self-citations or uniqueness theorems are invoked in the provided text. The method is self-contained against external benchmarks as a prompting approach.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics
Is compound aspect-based sentiment analysis addressed by LLMs? InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8https://www.anthropic.com/claude/sonnet 7836–7861, Miami, Florida, USA. Association for Computational Linguistics. Elisa Bassignana and Barbara Plank. 2022. What do you mean by relation extraction? a survey on data...
2024
-
[2]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A survey on relation extraction.Intelligent Systems with Applications, 19:200244. Hao Dong and Wei Wei. 2025. Pgso: Prompt-based generative sequence optimization network for aspect- based sentiment analysis.Expert Systems with Appli- cations, 265:125933. Yixin Dong, Charlie F. Ruan, Yaxing Cai, Ziyi Xu, Yilong Zhao, Ruihang Lai, and Tianqi Chen. 2025. Xgr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
The wine list is excellent, but the service was slow
SemEval-2016 task 5: Aspect based sentiment analysis. InProceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pages 19–30, San Diego, California. Association for Computational Linguistics. Maria Pontiki, Dimitris Galanis, Haris Papageorgiou, Suresh Manandhar, and Ion Androutsopoulos. 2015. SemEval-2015 task 12: Aspect based...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.