Compute-Budgeted Exploitability Evidence Graphs for Prospective Vulnerability Triage
Pith reviewed 2026-06-26 20:27 UTC · model grok-4.3
The pith
Budgeted selection from temporal evidence graphs raises leakage-safe prospective recall@50 for CVE exploitability from 0.010 to 0.026.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
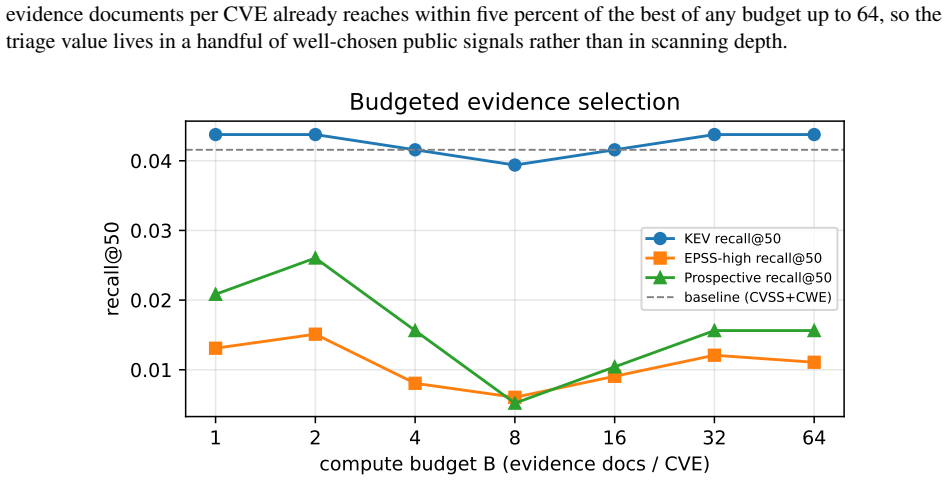
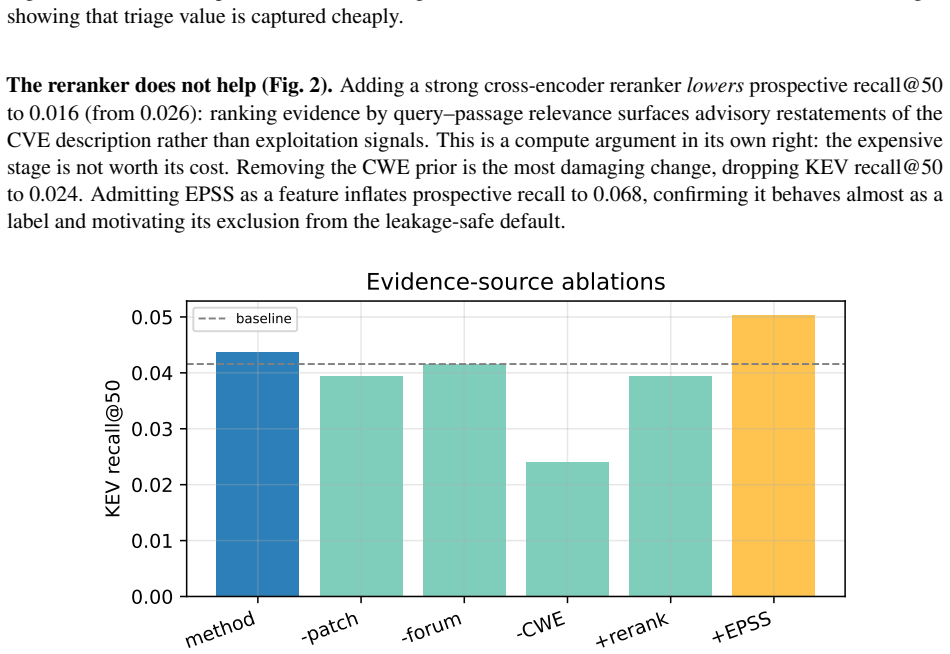
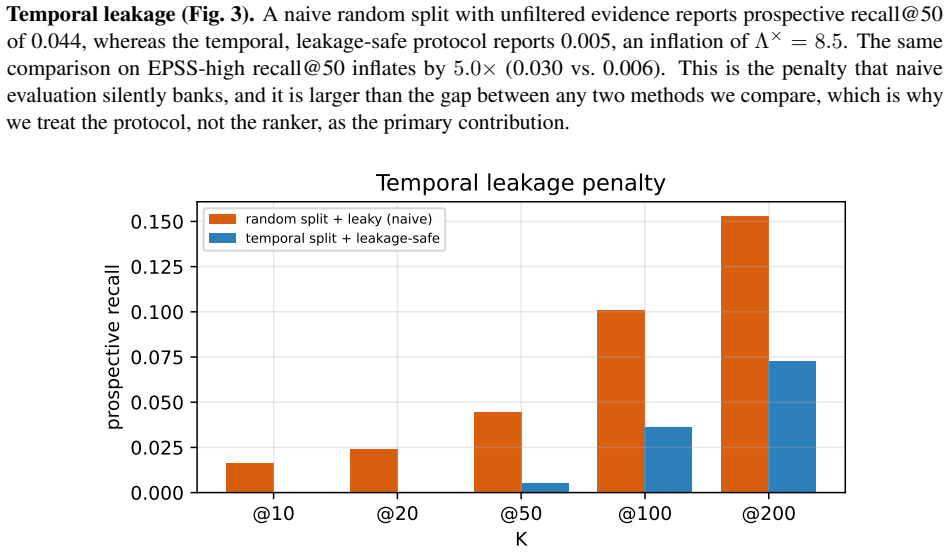
The authors claim that assembling temporal evidence graphs, applying a compute budget to select a small number of supporting documents per CVE, and pairing every score with a certificate that lists supporting signals, timestamps, source layers and leakage flags produces higher leakage-safe prospective recall than severity baselines. On 12012 CVEs the method reaches recall@50 of 0.026 versus 0.010 for severity alone, most value is obtained with two documents, and a semantic reranker drops performance to 0.016. The same protocol shows that unfiltered random splits inflate apparent recall by 8.5 times and EPSS-high recall by 5.0 times.
What carries the argument
Temporal evidence graph with budgeted selector and auditable leakage-safe certificates
If this is right
- Two evidence documents per CVE capture most of the performance gain over the severity baseline.
- Semantic relevance to a CVE is not the same as evidence of exploitation, as shown by the reranker lowering recall.
- Strict temporal constraints are required in evaluation protocols, since unfiltered random splits inflate recall by 8.5 times.
- Auditable certificates enable contestable and reproducible claims about vulnerability prioritization.
Where Pith is reading between the lines
- Vulnerability databases could adopt the certificate format to standardize how prioritization decisions are documented and audited.
- Future selectors might improve further by weighting evidence layers differently rather than treating all documents equally.
- The same budgeted graph approach could be tested on streaming CVE data to support ongoing triage rather than batch evaluation.
- Organizations with internal exploit data might combine the public graph with private signals while preserving the leakage safeguards.
Load-bearing premise
Temporal evidence graphs can be assembled and decision timestamps chosen so that no future information leaks into any CVE score, and the 12012 CVEs form a representative sample of real-world prospective triage.
What would settle it
A replication study on a new cohort of CVEs with every evidence document timestamp strictly before its decision time shows no improvement over the severity baseline of 0.010 or reveals detectable future leakage in the assembled graphs.
Figures
read the original abstract
Defenders cannot patch every newly disclosed vulnerability at once, so exploitability prediction must be evaluated prospectively rather than retrospectively. We study compute-budgeted vulnerability triage in which each CVE is scored only from public evidence visible by a fixed decision time. Advisories, exploit archives, fix commits, and hacker-community discourse are represented as a temporal evidence graph; a budgeted selector admits only a few evidence documents per CVE, and every score is paired with an auditable certificate listing the supporting signals, timestamps, source layers, and leakage flags. On 12012 prospective CVEs from public sources, budgeted evidence selection raises leakage-safe prospective recall@50 from 0.010 for a severity-only baseline to 0.026, while two evidence documents per CVE capture most of the value. A strong cross-encoder reranker lowers prospective recall to 0.016, showing that semantic relevance to a CVE is not the same as evidence of exploitation. Most importantly, a naive random split with unfiltered evidence inflates apparent prospective recall by 8.5x and EPSS-high recall by 5.0x. The main contribution is a leakage-safe evaluation protocol and reproducible evidence certificates for contestable vulnerability-prioritization claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a compute-budgeted framework for prospective exploitability prediction in vulnerability triage. It constructs temporal evidence graphs from public sources (advisories, exploit archives, fix commits, hacker discourse) and applies a selector that limits the number of evidence documents per CVE while recording timestamps, source layers, and leakage flags in auditable certificates. Evaluated on 12012 prospective CVEs, the budgeted selector improves leakage-safe recall@50 from 0.010 (severity-only baseline) to 0.026; two documents per CVE capture most value, a cross-encoder reranker drops performance to 0.016, and naive random splits with unfiltered evidence inflate recall by 8.5x (EPSS-high by 5.0x). The primary contribution is the leakage-safe evaluation protocol and reproducible certificates.
Significance. If the temporal cutoffs are verifiably enforced, the work supplies a concrete, auditable protocol for leakage-free prospective evaluation that directly addresses a known methodological weakness in security ML. The contrast between semantic reranking and exploitation evidence, the demonstration of 8.5x inflation under naive splits, and the emphasis on certificates for contestable claims are all useful contributions. The budgeted approach showing that limited evidence suffices is practically relevant for triage systems.
major comments (2)
- [Abstract and evaluation protocol] Abstract and evaluation protocol: The headline result (recall@50 rising from 0.010 to 0.026 under leakage-safe conditions) and the 8.5x inflation claim both presuppose that every admitted evidence document has a timestamp strictly before its CVE's decision time and that decision times themselves are chosen without reference to later outcomes. The manuscript records leakage flags but supplies no description of the procedure used to fix decision timestamps per CVE or the pipeline steps that enforce the pre-decision cutoff across advisories, commits, and discourse sources for all 12012 CVEs. This detail is load-bearing for the central claim.
- [Dataset construction] § on dataset construction (prospective CVE selection): The 12012 CVEs are described as 'prospective' from public sources, yet no explicit criteria are given for how the decision time is assigned to each CVE or how the sample is ensured to be representative of real triage scenarios without hindsight. Without this, it is impossible to confirm that the reported lift is free of selection bias or post-hoc leakage.
minor comments (2)
- [Methods] The 'budgeted selector' is referenced repeatedly but never given a formal definition, pseudocode, or complexity bound; a short algorithmic description would improve reproducibility.
- [Results] Table or figure reporting the per-CVE evidence counts and leakage-flag statistics is missing; adding one would make the 'two documents capture most value' claim easier to verify.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for explicit, verifiable procedures in our leakage-safe prospective evaluation. The comments correctly note that additional detail on timestamp assignment and CVE selection criteria is required to fully substantiate the central claims. We will revise the manuscript to incorporate these clarifications in the evaluation protocol and dataset construction sections.
read point-by-point responses
-
Referee: [Abstract and evaluation protocol] Abstract and evaluation protocol: The headline result (recall@50 rising from 0.010 to 0.026 under leakage-safe conditions) and the 8.5x inflation claim both presuppose that every admitted evidence document has a timestamp strictly before its CVE's decision time and that decision times themselves are chosen without reference to later outcomes. The manuscript records leakage flags but supplies no description of the procedure used to fix decision timestamps per CVE or the pipeline steps that enforce the pre-decision cutoff across advisories, commits, and discourse sources for all 12012 CVEs. This detail is load-bearing for the central claim.
Authors: We agree that the procedure for fixing decision timestamps and enforcing pre-decision cutoffs must be described in detail for the leakage-safe claims to be verifiable. In the revised manuscript we will add a dedicated subsection under the evaluation protocol that specifies: decision time per CVE is set to the earliest public disclosure timestamp recorded in NVD or the primary vendor advisory; evidence documents are filtered by comparing their source timestamps against this decision time; and the certificate generation step records the outcome of this comparison as a leakage flag. We will also include a high-level pipeline diagram and a worked example for one CVE showing enforcement across all four evidence layers. revision: yes
-
Referee: [Dataset construction] § on dataset construction (prospective CVE selection): The 12012 CVEs are described as 'prospective' from public sources, yet no explicit criteria are given for how the decision time is assigned to each CVE or how the sample is ensured to be representative of real triage scenarios without hindsight. Without this, it is impossible to confirm that the reported lift is free of selection bias or post-hoc leakage.
Authors: The referee is correct that explicit selection criteria and decision-time rules are needed to demonstrate absence of hindsight bias. We will expand the dataset construction section to state that the 12012 CVEs comprise every entry whose NVD publication date falls inside a fixed temporal window chosen prior to any exploit labeling, with decision time defined uniformly as that NVD publication date. No CVE was included or excluded on the basis of later exploit status. We will also add a short discussion of how this sampling approximates operational triage and note remaining limitations on representativeness. revision: yes
Circularity Check
No significant circularity in evaluation protocol or claims
full rationale
The paper reports empirical recall@50 results on a fixed set of 12012 CVEs using a leakage-safe temporal evidence graph protocol. No equations, fitted parameters, self-citations, or ansatzes are described that would make the reported lift (0.010 to 0.026) or the 8.5x inflation factor reduce to the inputs by construction. The evaluation is presented as an independent measurement against baselines and naive splits, with the central contribution being the protocol itself rather than a derived quantity forced by prior steps. The leakage assumption is an external validity concern, not a definitional circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Comparing vulnerability severity and exploits using case-control studies.ACM Transactions on Information and System Security (TISSEC), 17(1):1–20, 2014
Luca Allodi and Fabio Massacci. Comparing vulnerability severity and exploits using case-control studies.ACM Transactions on Information and System Security (TISSEC), 17(1):1–20, 2014
2014
-
[2]
Ampel, Sagar Samtani, Hongyi Zhu, and Hsinchun Chen
Benjamin M. Ampel, Sagar Samtani, Hongyi Zhu, and Hsinchun Chen. Creating proactive cyber threat intelligence with hacker exploit labels: a deep transfer learning approach.MIS Quarterly, 48(1):137–166, 2024
2024
-
[3]
Ampel et al
Benjamin M. Ampel et al. HackerSignal: a large-scale multi-source dataset linking hacker community discourse to the CVE vulnerability lifecycle, 2026
2026
-
[4]
CVEfixes: automated collection of vulnerabilities and their fixes from open-source software
Guru Bhandari, Amara Naseer, and Leon Moonen. CVEfixes: automated collection of vulnerabilities and their fixes from open-source software. InProc. 17th Int. Conf. on Predictive Models and Data Analytics in Software Engineering (PROMISE), pages 30–39, 2021
2021
-
[5]
Saul, Stefan Savage, and Geoffrey M
Mehran Bozorgi, Lawrence K. Saul, Stefan Savage, and Geoffrey M. V oelker. Beyond heuristics: learning to classify vulnerabilities and predict exploits. InProc. 16th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (KDD), pages 105–114, 2010
2010
-
[6]
Reducing the significant risk of known exploited vulnerabilities (binding operational directive 22-01) and the KEV catalog
Cybersecurity and Infrastructure Security Agency (CISA). Reducing the significant risk of known exploited vulnerabilities (binding operational directive 22-01) and the KEV catalog. https://www.cisa.gov/ known-exploited-vulnerabilities-catalog, 2021
2021
-
[7]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProc. 34th Int. Conf. on Machine Learning (ICML), pages 1321–1330, 2017
2017
-
[8]
Emanuele Iannone, Giulia Sellitto, Emanuele Iaccarino, Filomena Ferrucci, Andrea De Lucia, and Fabio Palomba. Early and realistic exploitability prediction of just-disclosed software vulnerabilities: how reliable can it be?ACM Transactions on Software Engineering and Methodology (TOSEM), 33(1):1–41, 2024
2024
-
[9]
Improving vulnerability remediation through better exploit prediction.Journal of Cybersecurity, 6(1):tyaa015, 2020
Jay Jacobs, Sasha Romanosky, Idris Adjerid, and Wade Baker. Improving vulnerability remediation through better exploit prediction.Journal of Cybersecurity, 6(1):tyaa015, 2020
2020
-
[10]
Exploit prediction scoring system (epss).Digital Threats: Research and Practice, 2(3):1–17, 2021
Jay Jacobs, Sasha Romanosky, Benjamin Edwards, Michael Roytman, and Idris Adjerid. Exploit prediction scoring system (epss).Digital Threats: Research and Practice, 2(3):1–17, 2021
2021
-
[11]
Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021
Jeff Johnson, Matthijs Douze, and Herv´e J´egou. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021
2021
-
[12]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas O ˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProc. 2020 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, 2020
2020
-
[13]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459–9474, 2020
2020
-
[14]
Common vulnerability scoring system.IEEE Security & Privacy, 4(6):85–89, 2006
Peter Mell, Karen Scarfone, and Sasha Romanosky. Common vulnerability scoring system.IEEE Security & Privacy, 4(6):85–89, 2006
2006
-
[15]
Common weakness enumeration (CWE).https://cwe.mitre.org/, 2024
MITRE Corporation. Common weakness enumeration (CWE).https://cwe.mitre.org/, 2024. 8
2024
-
[16]
Predicting good probabilities with supervised learning
Alexandru Niculescu-Mizil and Rich Caruana. Predicting good probabilities with supervised learning. InProc. 22nd Int. Conf. on Machine Learning (ICML), pages 625–632, 2005
2005
-
[17]
Passage re-ranking with BERT.arXiv preprint arXiv:1901.04085, 2019
Rodrigo Nogueira and Kyunghyun Cho. Passage re-ranking with BERT.arXiv preprint arXiv:1901.04085, 2019
Pith/arXiv arXiv 1901
-
[18]
TESSER- ACT: eliminating experimental bias in malware classification across space and time
Feargus Pendlebury, Fabio Pierazzi, Roberto Jordaney, Johannes Kinder, and Lorenzo Cavallaro. TESSER- ACT: eliminating experimental bias in malware classification across space and time. In28th USENIX Security Symposium, pages 729–746, 2019
2019
-
[19]
Sentence-BERT: sentence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: sentence embeddings using Siamese BERT-networks. In Proc. 2019 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pages 3982–3992, 2019
2019
-
[20]
Vulnerability disclosure in the age of social media: exploiting Twitter for predicting real-world exploits
Carl Sabottke, Octavian Suciu, and Tudor Dumitras ¸. Vulnerability disclosure in the age of social media: exploiting Twitter for predicting real-world exploits. In24th USENIX Security Symposium, pages 1041–1056, 2015
2015
-
[21]
Expected exploitability: predicting the development of functional vulnerability exploits
Octavian Suciu, Connor Nelson, Zhuoer Lyu, Tiffany Bao, and Tudor Dumitras ¸. Expected exploitability: predicting the development of functional vulnerability exploits. In31st USENIX Security Symposium, pages 377–394, 2022
2022
-
[22]
DarkEmbed: exploit prediction with neural language models
Nazgol Tavabi, Palash Goyal, Mohammed Almukaynizi, Paulo Shakarian, and Kristina Lerman. DarkEmbed: exploit prediction with neural language models. InProc. AAAI Conf. on Artificial Intelligence (IAAI), 2018
2018
-
[23]
Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533, 2022
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533, 2022. A Engineering the Pipeline for Budgeted GPU Throughput This appendix documents the systems issues encountered in making the study tractable on a si...
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.